【强化学习】第四章:动态规划(DP)
在完备的马尔可夫决策过程中,DP可用于计算价值函数,有了价值函数就可以得到动作价值,有了动作价值就可以得到智能体的策略。但是强化学习的最终目标是找到最优策略,所以基于动态规划的强化学习可以分两种方法寻找最优策略:策略迭代(policy Iteration)和价值迭代(Value Iteration)。下面针对这两种方法分别来讲。
【强化学习】第四章:动态规划(DP)
说明:学习本篇时一定一定要认真学完 https://blog.csdn.net/friday1203/article/details/155533020?spm=1001.2014.3001.5501 ,因为动态规划就是为了求解MDP问题的。所以你首先要非常清晰什么是MDP、MDP框架、贝尔曼期望方程、状态价值、动作价值等概念和它们之间的数学推导关系。
其实在第三章的最后,我已经完整的展示了学生例子的解是如何计算的。但是那种是显式地列出联立方程并直接求解的方法,这种方法只对小问题有效。在实际问题中,当状态和行动模式的数量非常多时,联立很多方程就不太可行,此时就需要动态规划法(dynamic programming, DP)来求解。本章介绍动态规划法。
类似梯度下降算法就是为了求解损失函数的最小值一样,动态规划法也只是求解价值函数的一种方法,所以本篇重点讲怎么用动态规划求解价值函数,而非动态规划法背后的理论和数学推导。
一、动态规划简介
1、什么是动态规划
动态规划(Dynamic Programming, DP)是一类优化算法。动态规划将待求解问题分解成若干子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。
2、动态规划的核心特点
(1)最优子结构————子问题的最优解是可以得到的。如果子问题都没有最优解,那就别谈下文了。
(2)重复子问题————子问题的解决方案可以存储和重用。
3、动态规划与强化学习之间的关系
在完备的马尔可夫决策过程中,DP可用于计算价值函数,有了价值函数就可以得到动作价值,有了动作价值就可以得到智能体的策略。但是强化学习的最终目标是找到最优策略,所以还得用贪婪方式提升策略。
所以,基于动态规划的强化学习是分两种方法寻找最优策略的:策略迭代(policy Iteration)和价值迭代(Value Iteration)。下面针对这两种方法分别来讲。
二、策略迭代(Policy Iteration)
1、策略评估(Policy Evaluation)
前后说过,动态规划是实现对价值函数的评估的一种方法。所以这里的小标题策略评估指的就是如何解出策略π下的系统状态价值。
那具体是如何解的呢?这里我先不绕理论和罗列数学推导,我先用上一篇中的学生例子为例,给大家展示一下是如何评估价值函数,让大家先有一个直观的认识: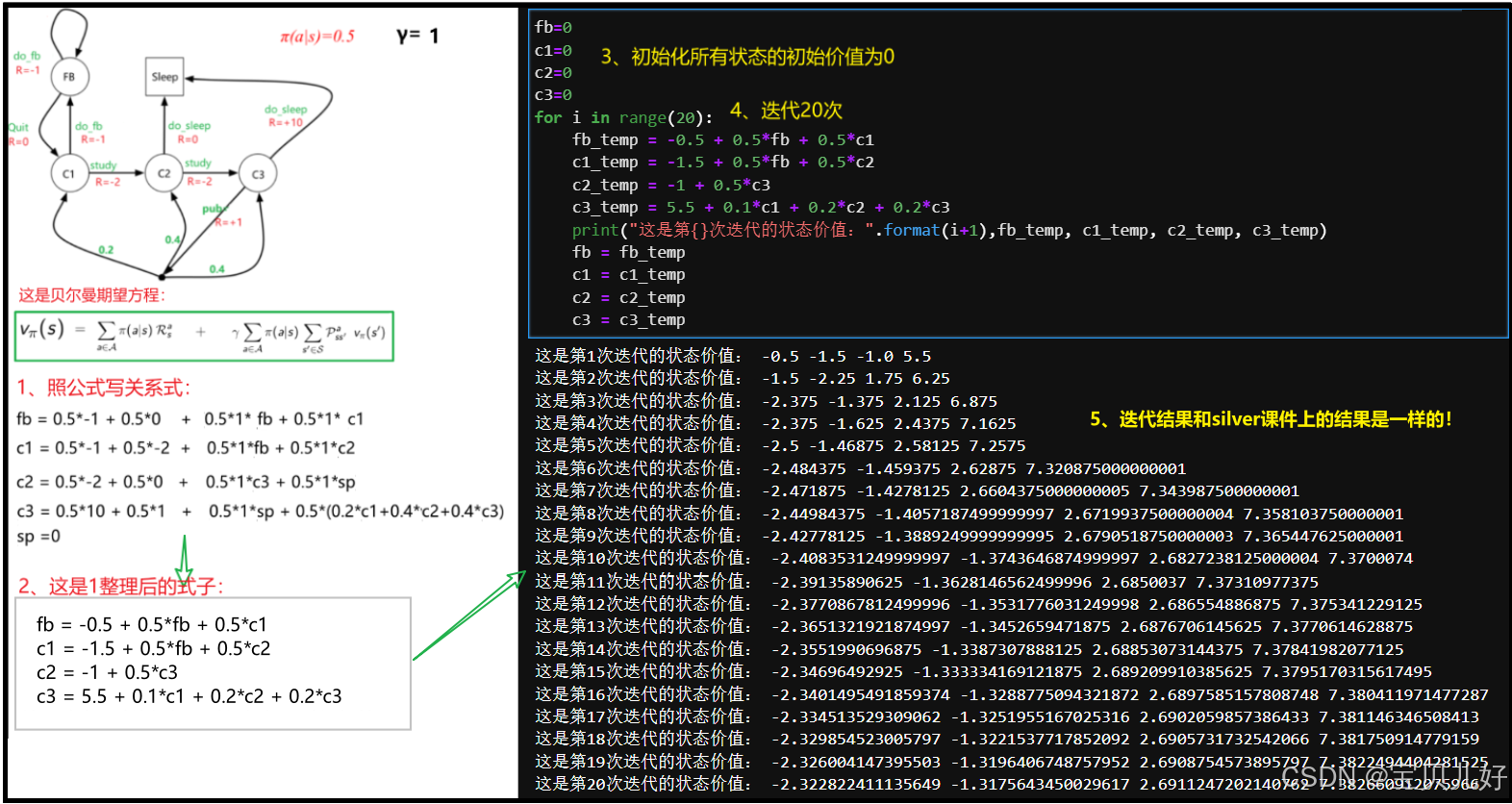
就是这么简单!先初始化一组状态价值,然后根据贝尔曼期望方程,一轮轮的迭代,最后就能收敛到策略π下的状态价值。策略π下的状态价值是指,这组价值可以使系统在策略π下满足贝尔曼期望方程。或者说这组价值就是贝尔曼期望方程组的解。这就是动态规划。简单理解就是通过迭代求出系统所有状态的价值。这个结果和silver课件中的结果是一样的,说明迭代结果是正确的。
很多资料是这样写的:DP方法是从贝尔曼期望方程衍生出来的,其思路是将贝尔曼期望方程变形为"更新式",用第k次的状态价值函数,更新第k+1次迭代的状态价值函数,这个过程叫自举法bootstrapping方法,也有说这是高斯-赛德尔迭代算法的求解过程。anyway,不管怎样,它就是一种求解线性方程组的一种方法。我们只要知道对于系统状态和行动模型的数量较大的一些场景,这种方法是可以高效求解的即可。
同步更新和异步更新
上面求解状态价值的过程,在算法的工程实现上叫同步更新(同步DP),意思就是迭代一轮,就更新一次全部的状态价值。下一轮迭代时,就依据这次的结果重新更新全部的状态价值。
由于同步更新效率有点低,所以在工程实现上,还有一种更新方式叫就地更新,也叫异步更新(异步DP),就是本轮迭代中,只要算出了某个状态价值,就地就直接更新了这个状态的价值,当其他方程中用到这个状态的价值值,就采用前面方程中已经更新了的新值来计算。这就是就地更新,就地更新效率会更高一些。Sutton强化学习书中用的就是就地更新。 异步更新的缺点是对状态的顺序比较敏感,因为顺序不一样更新的结果当然会不一样喽。所以容易导致结算结果不一致的情况。
下面我也用代码展示一下异步DP: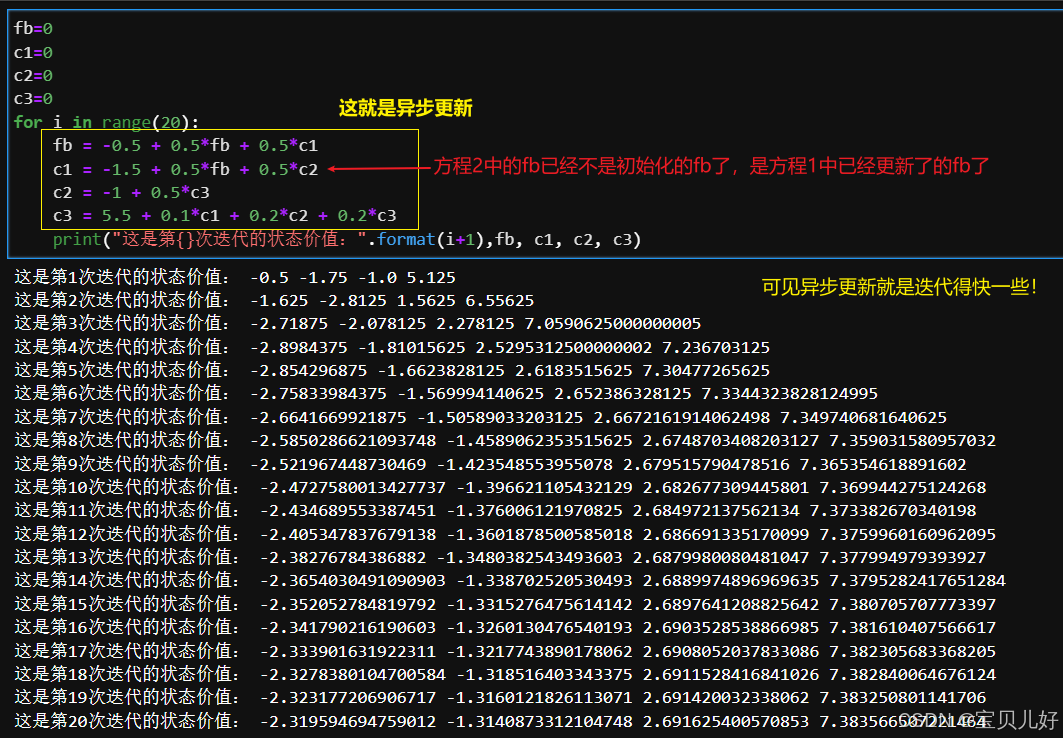
在强化学习中,上面的用DP求解状态价值的过程叫策略评估。silver课件中叫迭代策略评估算法。现在回看,它就是一个求解价值函数Vπ的迭代过程嘛。有了Vπ就可以得到Qπ,有了Qπ就知道了策略π,我想这就是为什么叫策略评估吧,又因为它是通过迭代实现的,所以叫迭代策略评估算法吧。
2、策略提升(Policy Improvement)
然而强化学习的最终目的是找到最优策略π*,所以还得进行策略提升(policy improvement)。策略提升有的地方叫策略控制(policy control),就是控制策略并将其调整为最优策略。有的地方叫策略改进。anyway,不管怎么叫,都是指如何寻找最优策略π*。而寻找最优策略π*也是通过迭代来实现的,所以本方法叫策略迭代(policy Iteration)。
第三章讲最优策略时,我们知道:对所有的s,如果vπ1(s)< vπ2(s)< vπ3(s)<...,那么策略π2就比策略π1好,策略π3就比策略π2好...所以策略提升(策略控制、策略改进、策略迭代)就是通过当已知当前策略π的价值函数时,在每个状态采用贪婪方法来对当前策略进行改进,用数学语言就是: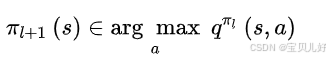
公式中的argmax a表示从局部候选行动中选择最佳行动,来更新策略,这种更新策略的做法叫“贪婪化”,就是只看眼前,眼前最优的动作是什么,那我下次就按这个动作来计算新一轮的状态价值,在新一轮的状态价值中我再找当下眼前的最优动作,计算新新轮的状态价值...如此循环,直到策略不会再被改进(或更新),那么这个策略就是最优策略。这种方法得到的策略也被称为贪婪策略,如下图所示: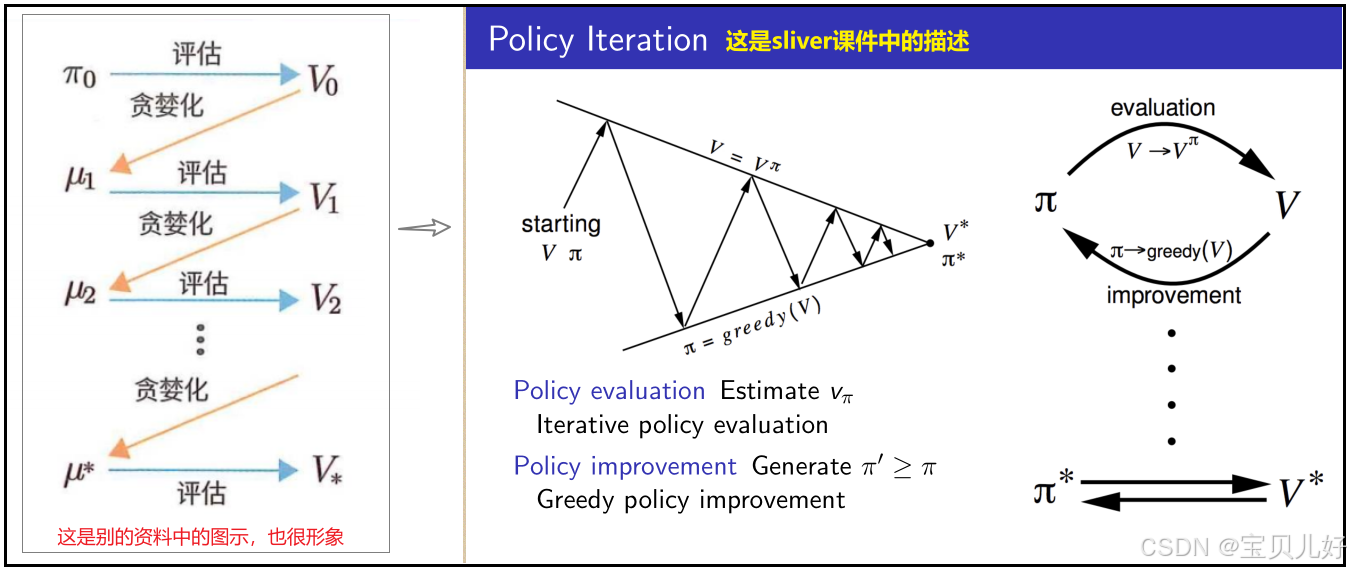
至此我们就得到策略迭代的基本范式、计算公式、算法实现:
小结:
策略迭代算法(policy Iteration)包括策略评估和策略改进两个步骤。在策略评估中,给定策略π1,用高斯-赛德尔迭代算法迭代计算π1策略下每个状态的价值函数vπ1-->由vπ1算得qπ1-->策略改进:用贪婪方法找到当下最好的qπ1(就是argmax a)-->当下最好的qπ1又对应着新策略π2-->用高斯-赛德尔迭代算法迭代计算π2策略下每个状态的价值函数vπ2->qπ2->贪婪化选择最好的qπ2->策略π3->....如此循环下去,就是一个策略收敛的过程。直到价值函数不变、策略不变,这个策略就是最优策略π*。上述迭代过程一般都能收敛到最优策略。至于为什么能收敛的数学证明大家可以自己查找资料,我个人没有查找。
下面我用代码继续展示学生的例子,直观理解如何用策略迭代法得到最优策略:
π = [[0.5, 0.5], [0.5, 0.5], [0.5, 0.5], [0.5, 0.5]] #这是初始化的策略π
fb=0 #这是初始化的状态价值
c1=0
c2=0
c3=0
for policy in range(5): #迭代5次策略
for i in range(20): #每个策略下循环20次寻找状态价值
fb = π[0][0]*-1 + π[0][1]*0 + π[0][0]*1*fb + π[0][1]*1*c1
c1 = π[1][0]*-1 + π[1][1]*-2 + π[1][0]*1*fb + π[1][1]*1*c2
c2 = π[2][0]*0 + π[2][1]*-2 + π[2][1]*1*c3
c3 = π[3][0]*10 + π[3][1]*1 + π[3][1]*0.2*c1 + π[3][1]*0.4*c2 + π[3][1]*0.4*c3
print("第{}个策略下的状态价值: ".format(policy+1), fb, c1, c2, c3)
#计算动作价值
fb_dofb = -1 + fb
fb_quit = c1
c1_dofb = -1 + fb
c1_study = -2 + c2
c2_dosp = 0
c2_study = -2 + c3
c3_dosp = 10
c3_pub = 1 + (0.2*c1 + 0.4*c2 + 0.4*c3)
print("第{}个策略下的动作价值:".format(policy+1),fb_dofb, fb_quit, c1_dofb, c1_study, c2_dosp, c2_study, c3_dosp, c3_pub)
#贪婪化提升策略
π[0] = ([1, 0] if fb_dofb >= fb_quit else [0, 1])
π[1] = ([1, 0] if c1_dofb >= c1_study else [0, 1])
π[2] = ([1, 0] if c2_dosp >= c2_study else [0, 1])
π[3] = ([1, 0] if c3_dosp >= c3_pub else [0, 1])
print("第{}个策略是:".format(policy+1), π)
print("--------------------")
从上面的运行结果看,其实只需要迭代2轮策略,就已经找到最优策略了。下面我重新设置一组初始化条件,看看能不能迭代到最优:
π = [[0.2, 0.8], [0.1, 0.9], [0.3, 0.7], [0.1, 0.9]] #策略重新初始化
fb=10 #状态价值也重新初始化
c1=9
c2=8
c3=9
for policy in range(5): #迭代5次策略
for i in range(20): #每个策略下循环20次寻找状态价值
fb = π[0][0]*-1 + π[0][1]*0 + π[0][0]*1*fb + π[0][1]*1*c1
c1 = π[1][0]*-1 + π[1][1]*-2 + π[1][0]*1*fb + π[1][1]*1*c2
c2 = π[2][0]*0 + π[2][1]*-2 + π[2][1]*1*c3
c3 = π[3][0]*10 + π[3][1]*1 + π[3][1]*0.2*c1 + π[3][1]*0.4*c2 + π[3][1]*0.4*c3
print("第{}个策略下的状态价值: ".format(policy+1), fb, c1, c2, c3)
#计算动作价值
fb_dofb = -1 + fb
fb_quit = c1
c1_dofb = -1 + fb
c1_study = -2 + c2
c2_dosp = 0
c2_study = -2 + c3
c3_dosp = 10
c3_pub = 1 + (0.2*c1 + 0.4*c2 + 0.4*c3)
print("第{}个策略下的动作价值:".format(policy+1),fb_dofb, fb_quit, c1_dofb, c1_study, c2_dosp, c2_study, c3_dosp, c3_pub)
#贪婪化改进策略
π[0] = ([1, 0] if fb_dofb >= fb_quit else [0, 1])
π[1] = ([1, 0] if c1_dofb >= c1_study else [0, 1])
π[2] = ([1, 0] if c2_dosp >= c2_study else [0, 1])
π[3] = ([1, 0] if c3_dosp >= c3_pub else [0, 1])
print("第{}个策略是:".format(policy+1), π)
print("--------------------")
同样只需要迭代2次,状态价值、动作价值、策略三个指标就都迭代到最优了。
重点(也是经验之谈):
其实很多时候我们不需要状态价值函数已经收敛了,才去贪婪化的提升策略,很多时候我们只要观察策略已经不更新了,就不用管价值函数是否也收敛,直接就认为这个策略是当下的最优策略,然后继续循环策略也是可以的。这样在工程上可以节省大量的算力。
对照上面的代码就是,内部的i循环(也就是策略评估)可以不用达到收敛,就可以开始贪婪化的提升策略了,但是外部的policy循环是必须要达到收敛,才能得到最优策略的。这样在工程上可以节省内部循环的计算量。
三、价值迭代(Value Iteration)
价值迭代可以看作是策略迭代的一种特殊情况,因为价值迭代是直接用贝尔曼最优方程,来求解最优策略的。因为能满足贝尔曼最优方程的策略一定是最优策略,所以利用贝尔曼最优方程进行价值迭代时,我们是可以不用管策略,只迭代最优价值函数即可,所以有时价值迭代的效率会比策略迭代高一些。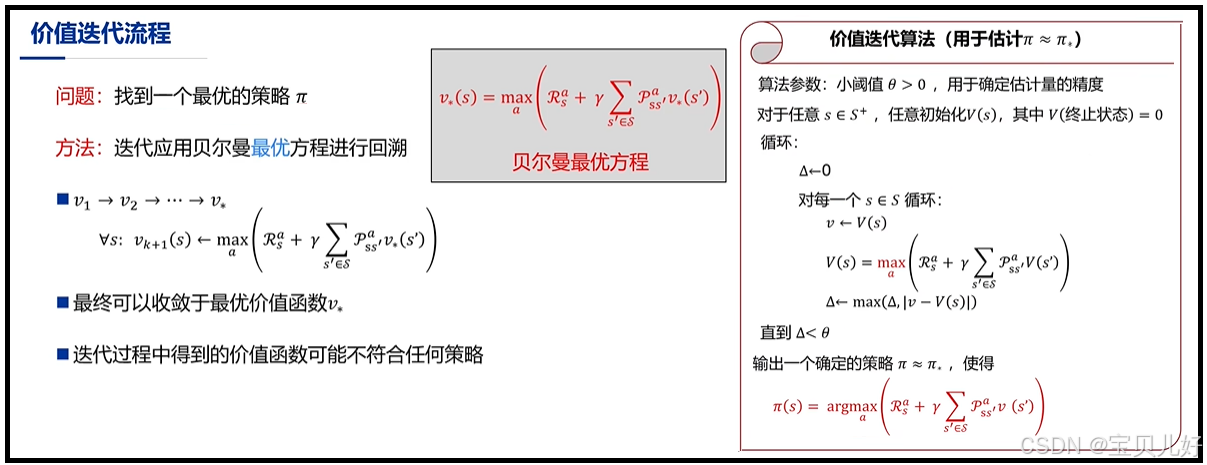
可见,价值迭代其实是在迭代计算状态价值时,就已经通过max操作进行了策略提升了。所以价值迭代是把策略评估和策略改进糅合到一起操作了,也所以价值迭代是策略迭代的一种特殊情况。
也所以上面的“经验之谈”中提到的,其实我们不必让价值迭代收敛后再改进策略。在价值迭代中,就是价值函数只迭代1次就提升一次策略(就是max操作嘛)。因为我们的目标只是寻找最优策略嘛,所以价值函数是否收敛就不那么重要了。
至于具体如何实现价值迭代,我这里就不重复写了,详情见第三章 https://blog.csdn.net/friday1203/article/details/155533020?spm=1001.2014.3001.5501 中的五-3:贝尔曼最优方程的求解。
本篇总结:
动态规划基本就是这些内容了,重点和难点还是在第三章,需要对第三章的深刻理解,这里只是数学上的求解技巧而已。
最后再说一下:本章的DP算法是传统的DP算法,也就是只针对完备的MDP,就是假设环境模型是完备的,此外计算复杂度也比较高。所以本章的DP算法作用是有限的,但我们还是得好好去学一下,因为它提供了必要的基础,就是给我们了一个完整的解决方案。所有此后的其他方法都是对DP的近似,其他方法要么是降低了计算复杂度,要么是减弱对环境模型完备性的假设。
四、计算silver课件中动态规划部分的例子:
我一直认为动态规划非常难,没想到被我这么简单就解读完了,有点不可思议。以防理解偏差,我再复现一下silver课件中的例子,因为有答案,所以可以核实一下自己理解的是否正确。
1、小型网格世界中的随机策略评估
简单解读这个网格游戏就是:
上面的4行4列格子中,左上角和右下角格子是逃生门。意思就是一个agent被放置在这个小型网格中,如果这个agent移动到这左上和右下格子中就逃生了,游戏就结束了。所以左上和右下格子就是终止状态格子。
标号1-14的格子是agent可以走的格子,每个格子都有四个方向可以走,每个方向走的概率初始化为0.25。只要走一步系统就奖励-1分。
位于边上的格子,比如1、2号格子,如果agent往上走,那它就还在原地,但是要得到-1分的系统奖励。意思就是你不仅没走出逃生,反而浪费了一次机会。再比如agent如果再3号格子,那agent如果往右和往上两个方向走,都是还是继续呆着3号格子中,同时得到-1分的系统奖励。意思是只要agent走了一步,就得-1分。只要agent走到左上和右下格子中游戏就结束。
这个系统的目标是agent如何最快逃生? 也就是agent如何获得最多的系统奖励并成功逃生?
至于上面A处鲁鹏老师课件翻译的问题,我下面用代码来说明。
import numpy as np
v = np.zeros((4,4)) #初始化的状态价值都是0
for k in range(100): #迭代100次价值函数
#贝尔曼期望方程按照上-下-左-右的顺序写 #这里我们用同步DP算法
v01 = 0.25*(-1-1-1-1) + 0.25*(v[0][1]+v[1][1]+0+v[0][2])
v02 = 0.25*(-1-1-1-1) + 0.25*(v[0][2]+v[1][2]+v[0][1]+v[0][3])
v03 = 0.25*(-1-1-1-1) + 0.25*(v[0][3]+v[1][3]+v[0][2]+v[0][3])
v10 = 0.25*(-1-1-1-1) + 0.25*(0+v[2][0]+v[1][0]+v[1][1])
v11 = 0.25*(-1-1-1-1) + 0.25*(v[0][1]+v[2][1]+v[1][0]+v[1][2])
v12 = 0.25*(-1-1-1-1) + 0.25*(v[0][2]+v[2][2]+v[1][1]+v[1][3])
v13 = 0.25*(-1-1-1-1) + 0.25*(v[0][3]+v[2][3]+v[1][2]+v[1][3])
v20 = 0.25*(-1-1-1-1) + 0.25*(v[1][0]+v[3][0]+v[2][0]+v[2][1])
v21 = 0.25*(-1-1-1-1) + 0.25*(v[1][1]+v[3][1]+v[2][0]+v[2][2])
v22 = 0.25*(-1-1-1-1) + 0.25*(v[1][2]+v[3][2]+v[2][1]+v[2][3])
v23 = 0.25*(-1-1-1-1) + 0.25*(v[1][3]+0+v[2][2]+v[2][3])
v30 = 0.25*(-1-1-1-1) + 0.25*(v[2][0]+v[3][0]+v[3][0]+v[3][1])
v31 = 0.25*(-1-1-1-1) + 0.25*(v[2][1]+v[3][1]+v[3][0]+v[3][2])
v32 = 0.25*(-1-1-1-1) + 0.25*(v[2][2]+v[3][2]+v[3][1]+0)
#更新状态价值
v[0][1] = v01
v[0][2] = v02
v[0][3] = v03
v[1][0] = v10
v[1][1] = v11
v[1][2] = v12
v[1][3] = v13
v[2][0] = v20
v[2][1] = v21
v[2][2] = v22
v[2][3] = v23
v[3][0] = v30
v[3][1] = v31
v[3][2] = v32
print("第{}次迭代的状态价值:\n".format(k+1),v)
大家可以自行运行一下这个代码,结果和silver课件上的答案是一样的!
这就是使用同步DP算法进行策略评估,也叫迭代策略评估算法。
2、异步DP算法迭代策略评估
import numpy as np
v = np.zeros((4,4)) #初始化的状态价值都是0
for k in range(100): #迭代100次价值函数
#贝尔曼期望方程按照上-下-左-右的顺序写 #这里我们用异步DP算法
v[0][1] = 0.25*(-1-1-1-1) + 0.25*(v[0][1]+v[1][1]+0+v[0][2])
v[0][2] = 0.25*(-1-1-1-1) + 0.25*(v[0][2]+v[1][2]+v[0][1]+v[0][3])
v[0][3] = 0.25*(-1-1-1-1) + 0.25*(v[0][3]+v[1][3]+v[0][2]+v[0][3])
v[1][0] = 0.25*(-1-1-1-1) + 0.25*(0+v[2][0]+v[1][0]+v[1][1])
v[1][1] = 0.25*(-1-1-1-1) + 0.25*(v[0][1]+v[2][1]+v[1][0]+v[1][2])
v[1][2] = 0.25*(-1-1-1-1) + 0.25*(v[0][2]+v[2][2]+v[1][1]+v[1][3])
v[1][3] = 0.25*(-1-1-1-1) + 0.25*(v[0][3]+v[2][3]+v[1][2]+v[1][3])
v[2][0] = 0.25*(-1-1-1-1) + 0.25*(v[1][0]+v[3][0]+v[2][0]+v[2][1])
v[2][1] = 0.25*(-1-1-1-1) + 0.25*(v[1][1]+v[3][1]+v[2][0]+v[2][2])
v[2][2] = 0.25*(-1-1-1-1) + 0.25*(v[1][2]+v[3][2]+v[2][1]+v[2][3])
v[2][3] = 0.25*(-1-1-1-1) + 0.25*(v[1][3]+0+v[2][2]+v[2][3])
v[3][0] = 0.25*(-1-1-1-1) + 0.25*(v[2][0]+v[3][0]+v[3][0]+v[3][1])
v[3][1] = 0.25*(-1-1-1-1) + 0.25*(v[2][1]+v[3][1]+v[3][0]+v[3][2])
v[3][2] = 0.25*(-1-1-1-1) + 0.25*(v[2][2]+v[3][2]+v[3][1]+0)
print("第{}次迭代的状态价值:\n".format(k+1),v)3、如果按照鲁鹏老师的课件,agent到达终止状态时,系统奖励是0的结果:
import numpy as np
v = np.zeros((4,4)) #初始化的状态价值都是0
for k in range(100): #迭代100次价值函数
#贝尔曼期望方程按照上-下-左-右的顺序写 #这里我们用异步DP算法
v[0][1] = 0.25*(-1-1+0-1) + 0.25*(v[0][1]+v[1][1]+0+v[0][2])
v[0][2] = 0.25*(-1-1-1-1) + 0.25*(v[0][2]+v[1][2]+v[0][1]+v[0][3])
v[0][3] = 0.25*(-1-1-1-1) + 0.25*(v[0][3]+v[1][3]+v[0][2]+v[0][3])
v[1][0] = 0.25*(0-1-1-1) + 0.25*(0+v[2][0]+v[1][0]+v[1][1])
v[1][1] = 0.25*(-1-1-1-1) + 0.25*(v[0][1]+v[2][1]+v[1][0]+v[1][2])
v[1][2] = 0.25*(-1-1-1-1) + 0.25*(v[0][2]+v[2][2]+v[1][1]+v[1][3])
v[1][3] = 0.25*(-1-1-1-1) + 0.25*(v[0][3]+v[2][3]+v[1][2]+v[1][3])
v[2][0] = 0.25*(-1-1-1-1) + 0.25*(v[1][0]+v[3][0]+v[2][0]+v[2][1])
v[2][1] = 0.25*(-1-1-1-1) + 0.25*(v[1][1]+v[3][1]+v[2][0]+v[2][2])
v[2][2] = 0.25*(-1-1-1-1) + 0.25*(v[1][2]+v[3][2]+v[2][1]+v[2][3])
v[2][3] = 0.25*(-1+0-1-1) + 0.25*(v[1][3]+0+v[2][2]+v[2][3])
v[3][0] = 0.25*(-1-1-1-1) + 0.25*(v[2][0]+v[3][0]+v[3][0]+v[3][1])
v[3][1] = 0.25*(-1-1-1-1) + 0.25*(v[2][1]+v[3][1]+v[3][0]+v[3][2])
v[3][2] = 0.25*(-1-1-1+0) + 0.25*(v[2][2]+v[3][2]+v[3][1]+0)
print("第{}次迭代的状态价值:\n".format(k+1),v)可见,系统奖励不一样,最后计算出来收敛的价值值也是不一样的!
4、价值迭代算法实现
import numpy as np
v = np.zeros((4,4)) #初始化的状态价值都是0
for k in range(100): #迭代100次价值函数
#贝尔曼期望方程按照上-下-左-右的顺序写 #这里我们用异步DP算法
v[0][1] = max(-1+v[0][1], -1+v[1][1], -1+0, -1+v[0][2])
v[0][2] = max(-1+v[0][2], -1+v[1][2], -1+v[0][1], -1+v[0][3])
v[0][3] = max(-1+v[0][3], -1+v[1][3], -1+v[0][2], -1+v[0][3])
v[1][0] = max(-1+0, -1+v[2][0], -1+v[1][0], -1+v[1][1])
v[1][1] = max(-1+v[0][1], -1+v[2][1], -1+v[1][0], -1+v[1][2])
v[1][2] = max(-1+v[0][2], -1+v[2][2], -1+v[1][1], -1+v[1][3])
v[1][3] = max(-1+v[0][3], -1+v[2][3], -1+v[1][2], -1+v[1][3])
v[2][0] = max(-1+v[1][0], -1+v[3][0], -1+v[2][0], -1+v[2][1])
v[2][1] = max(-1+v[1][1], -1+v[3][1], -1+v[2][0], -1+v[2][2])
v[2][2] = max(-1+v[1][2], -1+v[3][2], -1+v[2][1], -1+v[2][3])
v[2][3] = max(-1+v[1][3], -1+0, -1+v[2][2], -1+v[2][3])
v[3][0] = max(-1+v[2][0], -1+v[3][0], -1+v[3][0], -1+v[3][1])
v[3][1] = max(-1+v[2][1], -1+v[3][1], -1+v[3][0], -1+v[3][2])
v[3][2] = max(-1+v[2][2], -1+v[3][2], -1+v[3][1], -1+0)
print("第{}次迭代的状态价值:\n".format(k+1),v)
从结果看,使用价值迭代算法,只迭代了2次,策略就已经收敛了,导致max结果一直不变,也就是该算法我们也能得到最优策略,但是已经无法得到收敛的价值函数了,后面的98次迭代,由于策略已经是最优了,策略一直不变,所以通过max计算出来的价值就一直不变。但是这个状态价值不是收敛的状态价值,它不满足贝尔曼期望方程,这个价值不是最优策略的价值:
如果上图你看不懂,那说明你第三章的内容没有完全弄明白,需要回看第三章:https://blog.csdn.net/friday1203/article/details/155533020?spm=1001.2014.3001.5501
本篇章完。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)