A Self-supervised Motion Representation for PortraitVideo Generation用于人像视频生成的自监督运动表示
肖像视频生成在游戏、影视、教育等领域应用广泛,当前行业对更真实的动画效果和更快的生成速度需求日益迫切。现有方法主要存在两大路径局限:一呢,依赖3DMM、人脸关键点等人工设计的显示运动表征(容易丢失细颗粒度运动,场景适应度差,仅仅适用于特定面部场景);二是基于预训练视频生成模型做适配(时空注意力计算量大、多步去噪流程导致推理效率低,形成生成瓶颈)。本文从“视频运动存在大量冗余可以压缩”和“自监督表征
1.1引言
肖像视频生成在游戏、影视、教育等领域应用广泛,当前行业对更真实的动画效果和更快的生成速度需求日益迫切。现有方法主要存在两大路径局限:一呢,依赖3DMM、人脸关键点等人工设计的显示运动表征(容易丢失细颗粒度运动,场景适应度差,仅仅适用于特定面部场景);二是基于预训练视频生成模型做适配(时空注意力计算量大、多步去噪流程导致推理效率低,形成生成瓶颈)。
本文从“视频运动存在大量冗余可以压缩”和“自监督表征优于人工先验”两大洞察出发,提出SeMo框架,无需人工先验和预训练视频模型,通过自监督学习将运行抽象为紧凑的1D token,实现高效推理与高真实感生成的平衡。
1.2核心方法
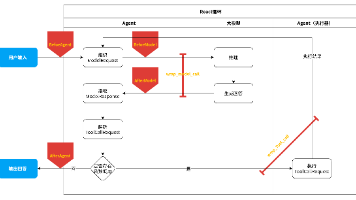
整体框架
SeMo 遵循“抽象->推理->生成”的三步核心范式,采用两阶段自监督训练架构:第一阶段 训练运动自编码器(motion autoEncoder),通过随机掩码策略将视频帧的运动信息抽象为1D token(紧凑令牌),并且基于 rectified flow 整流流解码器完成视频重建,强制学习核心运动语义;第二阶段冻结自编码器,训练 Motion Generator(运动生成器),从音频信号和历史运动令牌中推理后续运动序列最终引导解码器生成时序一致的目标视频。核心思路是将高维复杂运动压缩为低维语义token,以token为中心桥梁实现音频到视频的高效、精准映射。
关键模块
1、Masked Motion Encoder(运动抽象模块):输入视频帧先通过一个 pre-trained stable diffusion VAE encoder 压缩为latent 特征,然后embed each latent into non-overlapping patches, and apply random masking with ratios uniformly sampled from 0% to 90%. (低掩码率保留关键的细节,高掩码率强制模型忽略冗余、聚焦核心运动)
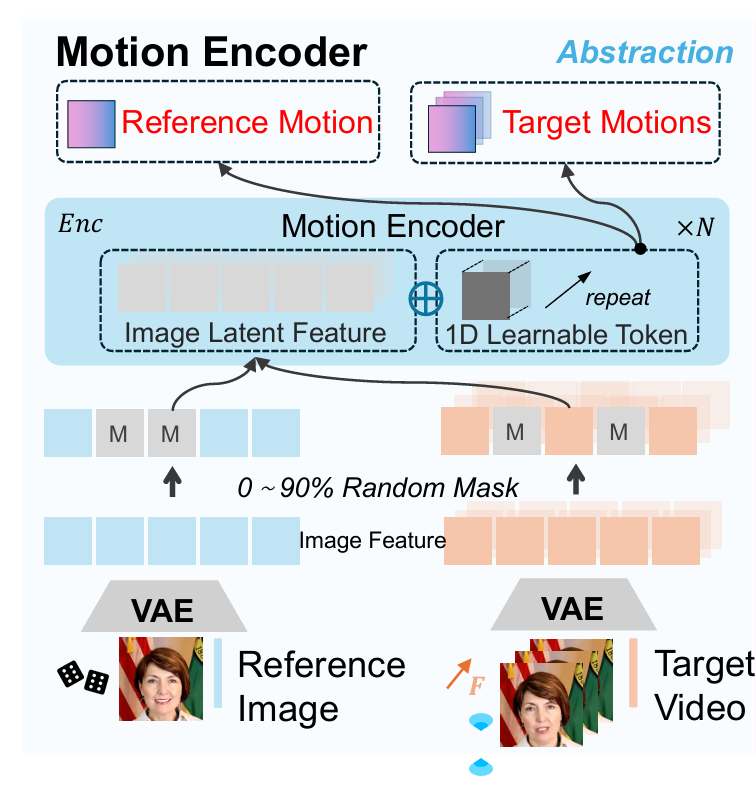
然后将掩码后的特征与1D Learnable Token 拼接,经ViT编码器处理后,输出1个令牌 + 512 维通道的紧凑运动表征,实现运动信息的高效压缩与语义提炼。
2、Motion Decoder(视频生成模块):这里包含两大核心,子模块:①motion control module:将参考图特征,带噪声的目标图特征,参考 motion token 和目标运动令牌拼接,通过自注意力和前馈网络,引导生成初步目标帧特征;② Temporal Align Module:将多帧初步特征沿着时间维度拼接,世家时序自注意力,对齐眨眼、唇部运动等高频细节,解决帧间不一致问题。整个解码的的过程基于rectified flow 整流流框架,通过噪声调度实现从粗到细的生成。
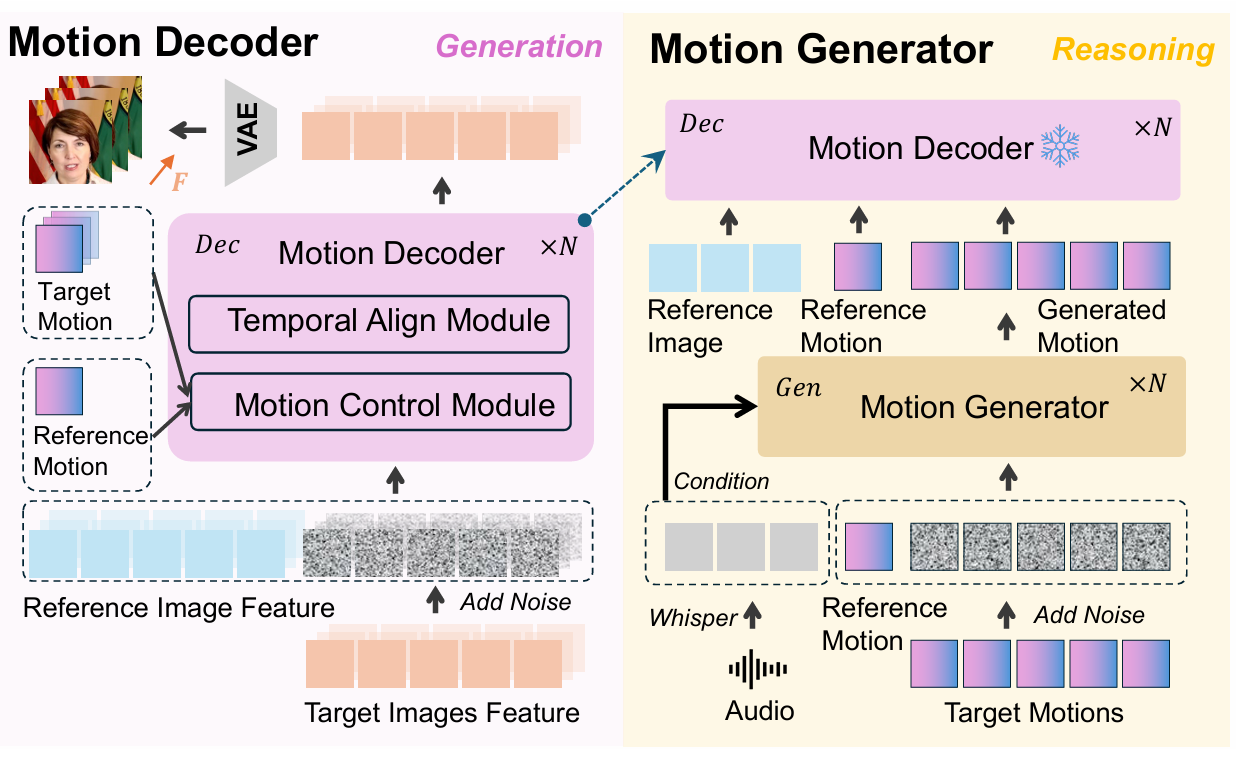
3、Motion Genereator(运动推理模块):以 Whisper 编码的音频信号、历史运动令牌、带噪声的目标运动令牌为输入,通过自注意力建模运动时序依赖、跨注意力实现音视频对齐,高效生成后续运动序列。该模块训练时受益于第一阶段的掩码策略,运动 latent 分布更优,收敛速度和生成性能均得到提升。
训练目标
第一阶段(运动自编码器训练):优化整流流 velocity 预测损失,使解码器能基于参考图和运动令牌,精准重建目标视频帧,损失函数如下:
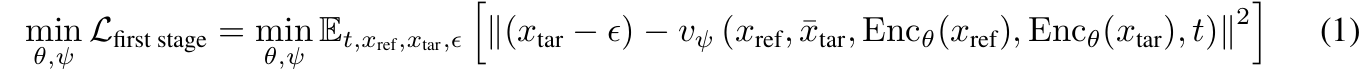
第二阶段(运动生成器训练):同样基于整流流框架,优化运动序列生成损失,使模型能从音频和历史运动中推理出精准的目标运动,损失函数如下:
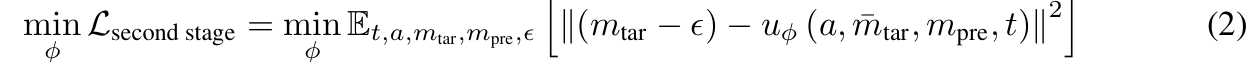
1.3实验结果
数据集与指标
①训练数据集:DH-FaceVid-1K(高质量多种族肖像视频)、HDTF(高分辨率肖像视频)、MEAD(情感肖像数据集),视频统一 resize 为 256×256 分辨率,剔除人脸检测失败样本;
②测试指标:视频质量(FID、FVD)、感知相似度(LPIPS)、重建精度(PSNR、SSIM)、音视频同步性(Sync-C、Sync-D),同时通过 50 名参与者的用户研究,从真实感、唇同步、流畅度、整体质量 4 个维度评估生成效果;
③对比基线:视频重建任务对比 FOMM、MRAA、TPSMM 等方法;音频驱动生成任务对比 Aniportrait、Hallo2、SadTalker 等 SOTA 方法。
核心结果
①视频重建任务:在 HDTF 数据集上,SeMo 实现 FID 21.431、FVD 136.738、LPIPS 0.043,显著优于 Liveportrait(FID 22.469)、TPSMM(FID 26.556)等方法;在 MEAD 数据集上,FID 低至 23.546,PSNR 达 36.233,且能捕捉耳环摆动、头发飘动等细粒度运动,还能自动补全头部运动导致的细节缺失。

②音频驱动生成任务:在 HDTF 数据集上,FID 26.860 超越 SOTA 方法 Hallo2(FID 27.447),Sync-C 达 6.147、Sync-D 8.574,音视频同步性表现优异;用户研究中真实感赢率达 81%,在近距离、侧脸、部分人脸、头部转动等无约束场景中表现稳定,而传统方法易出现细节缺失或生成不自然。

③效率对比:每帧运动表征仅为 1 个 512 维令牌,比特数远低于传统方法(图 6a),推理效率更高,实现质量与效率的平衡。
1.4 优缺点分析
优点
①无先验依赖:无需 3DMM、人脸关键点等人工设计表征,通过自监督学习自动捕捉人脸、饰品、头发等多部位复杂运动,场景适应性强,无需复杂数据预处理。
②紧凑高效:1D 运动令牌大幅降低存储和计算开销,运动生成与视频解码流程简洁,推理速度快,兼顾部署需求。
③真实感与一致性强:整流流解码器保证细粒度运动生成质量(如沉默时眨眼、感叹词对应的唇部动态),时序对齐模块解决帧间不一致问题,用户真实感评分领先。
⑥泛化性优异:随机掩码策略增强模型对无约束场景(侧脸、远距离、部分人脸)的适应能力, ablation 实验证明掩码能提升模型泛化性并加速收敛。
缺点
①分辨率受限:当前仅支持 256×256 分辨率,下采样和 VAE 压缩会导致牙齿模糊、胡须闪烁等高频细节丢失问题。
②复杂场景适配不足:在多主体、复杂运动场景中可能出现拖影 artifacts,暂未充分验证其在广义视频生成任务中的适用性。
③令牌容量上限:单一 1D 令牌对极端复杂运动(如快速舞蹈、多部位同步剧烈运动)的表征能力可能不足,需进一步优化令牌设计。
3.5 个人思考与启发
这篇文献的核心价值在于打破了 “肖像视频生成依赖人工先验或预训练大模型” 的固有思路,证明了 “自监督紧凑令牌 + 整流流生成” 是平衡质量与效率的有效范式 —— 肖像视频的运动冗余不是负担,而是可利用的资源,通过随机掩码和语义压缩,能将高维运动转化为低维可解释的令牌,大幅降低生成难度。
从应用角度看,SeMo 的无约束场景适应性和高效推理特性,特别适合实时虚拟人驱动、短视频创作、在线教育等场景。但仍有优化空间:若引入多令牌或动态令牌设计,可进一步提升对复杂运动的表征能力;结合面部语义分割信息设计针对性掩码策略,或许能缓解高频细节丢失问题;未来可探索更高分辨率生成,同时扩展至更广义的视频生成任务(如物体运动生成)。
论文中展示了不同掩码比例的重建效果,即使遮除 90% 内容,模型仍能还原合理运动,直观验证了肖像视频运动的高冗余特性,为 “紧凑令牌表征” 的设计提供了关键数据支撑;而注意力图可视化也显示,模型重点关注眼睛、嘴巴等运动显著区域及耳环等易动饰品,证明运动令牌确实捕捉了核心运动语义。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)