AI学习笔记整理(32)—— 视觉基础模型及视觉大模型分类
基于Transformer的通用视觉模型:这类模型以视觉Transformer(ViT)为基础架构,通过自监督或对比学习预训练,适用于图像分类、检测和分割等任务。视觉-语言预训练模型:这类模型联合学习图像和文本表示,支持图文检索、开放词汇检测等任务。视觉语言模型(VLM):这类模型联合学习图像和文本的表示,支持图文理解、视觉问答、图像描述生成等任务。多模态与新兴模型:扩展至视频、3D等场景
将CV(Computer Vision)分为四类:
- 传统模型:只有图像输入,使用Transformer架构和自监督学习方法。
- 文本提示模型/视觉语言模型(VLMs):接受图像和文本输入,如OpenAI的CLIP和Flamingo模型。
- 视觉提示模型:需要图像和视觉提示(如边界框或点)或文本提示,例如Segment Anything Model(SAM)。
- 异构模型:可以接受多种类型输入并生成多种类型输出的模型。
参考链接:https://cloud.tencent.com/developer/article/2431943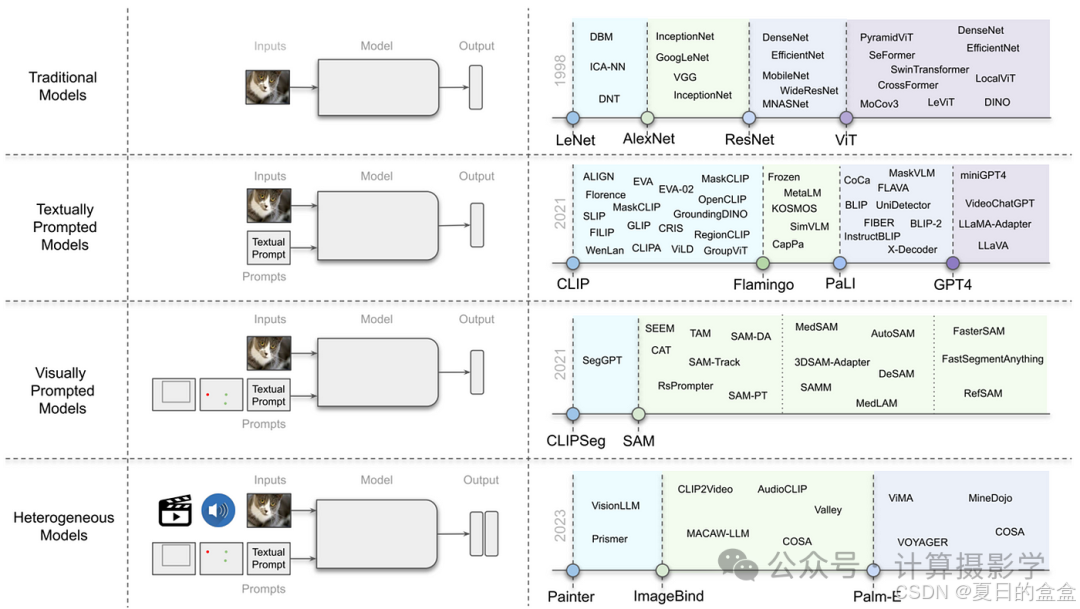
视觉基础模型
视觉基础模型(Vision Foundation Models)是计算机视觉领域的重要范式,通常通过大规模数据预训练获得通用视觉理解能力,并可适配多种下游任务。以下分类基于模型的核心架构、训练目标或应用场景进行归纳。
-
基于Transformer的通用视觉模型:这类模型以视觉Transformer(ViT)为基础架构,通过自监督或对比学习预训练,适用于图像分类、检测和分割等任务。代表性模型包括Masked Autoencoders(MAE)、DINO及其变体(如Mask DINO),以及ImageBind,后者通过统一嵌入空间对齐多种模态。ConvNeXt等基于卷积的架构在监督预训练下也表现优异,尤其在数据量充足时
-
视觉-语言预训练模型:这类模型联合学习图像和文本表示,支持图文检索、开放词汇检测等任务。CLIP及其改进版本(如CoCa、FLAVA)通过对比学习对齐视觉和语言特征;BLIP-2和InstructBLIP则通过冻结视觉编码器与语言模型结合,提升指令遵循能力。Segment Anything Model(SAM)专注于图像分割,支持零样本泛化。
-
生成型视觉语言模型:以生成任务为核心,能够根据图像或文本输入进行描述、编辑或创作。MiniGPT-4和Visual ChatGPT结合视觉编码器与大语言模型,实现对话式视觉理解;Caption Anything支持交互式图像描述生成。G²VLM通过几何与语义专家协作,增强三维空间推理能力。
-
特定任务基础模型:针对检测、分割等具体任务设计,通常基于通用模型微调。Grounding DINO支持参考表达检测;OVSeg和FC-CLIP处理开放词汇分割;Track Anything将SAM扩展至视频跟踪。PaLI和PaLM-E则面向多语言或具身任务,整合视觉与语言理解。
-
多模态与新兴模型:扩展至视频、3D等场景,如InternVideo用于视频基础建模,GPT-4V支持视觉-语言推理。这些模型常采用统一接口处理异构输入,推动通用视觉智能发展。
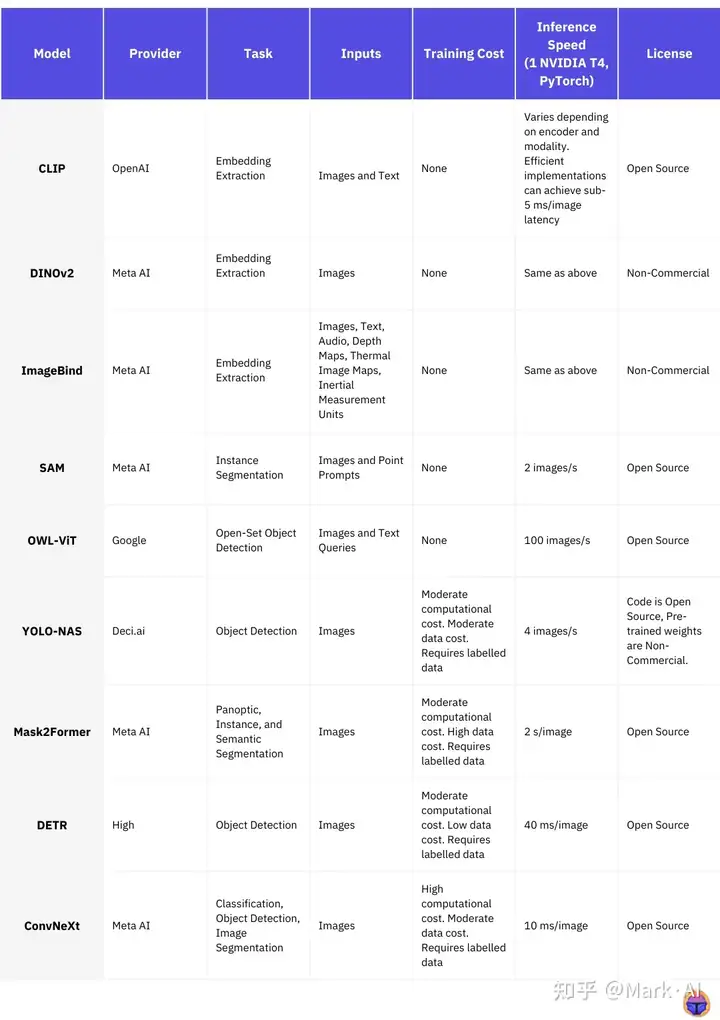
参考链接:https://zhuanlan.zhihu.com/p/648642099
视觉大模型
视觉大模型主要分为以下几类,涵盖不同技术路径和应用场景:
-
视觉语言模型(VLM):这类模型联合学习图像和文本的表示,支持图文理解、视觉问答、图像描述生成等任务。例如,CLIP通过对比学习对齐视觉和语言特征,而GLIP进一步引入掩码-描述数据提升零样本泛化能力。近期模型如Griffon-G致力于统一视觉语言和以视觉为中心的任务,并通过渐进式学习策略优化多任务性能。
-
分割模型:专注于像素级图像理解,包括图像分割和视频分割。Segment Anything Model 2(SAM2)支持可提示视觉分割,能处理图像和视频中的任意对象分割,并通过记忆机制改进时空一致性。其他模型如ReferDINO则针对视频对象分割,利用跨模态特征实现帧间目标交互。
-
生成模型:以图像或视频生成为核心,分为文生图、图生图、视频生成等方向。豆包文生图模型擅长精准理解文字需求并生成高质量图像,尤其注重中国文化元素;图生图模型支持风格迁移、扩图等操作。在视频生成方面,豆包视频生成模型可实现多镜头叙事和1080p高清输出,适用于短视频创作。
-
检索与嵌入模型:用于视觉内容的高效检索和向量化表示。VLM2Vec利用预训练视觉语言模型进行大规模多模态嵌入任务,在分类、检索等元任务上表现优异。GME模型则专注于通用多模态检索,支持单模态、跨模态和融合模态检索。
-
专用与垂直领域模型:针对特定场景优化,如美图视觉大模型3.0强化“智能脑补”和精准修图能力,降低绘图操作门槛;豆包向量化模型则聚焦向量检索,支持亿级数据快速匹配,适用于企业知识库构建。
视觉大模型的关键挑战
尽管VLM取得了显著进展,但仍面临以下关键挑战:
- 幻觉(Hallucination):模型可能生成虚假或不准确的信息,尤其是在处理复杂视觉和语言任务时。例如,模型可能在图像描述中添加不存在的细节。
- 对齐(Alignment):确保模型的行为符合人类的意图和价值观,避免生成有害或偏见的内容。这需要改进训练数据和对齐算法。
- 公平性(Fairness):模型可能在处理不同群体或场景时表现出偏见,例如在图像识别中对某些人群的表示不足。
- 安全性(Safety):在实际应用中,模型需要处理敏感信息并避免被滥用,例如防止生成不当内容。
这些挑战需要通过改进数据集质量、开发新的训练方法和设计更严格的评估指标来解决。
2025年是VLM研究的一个重要年份,涌现出多个新模型和技术,显著提升了模型性能和应用范围。以下是2025年发布的一些关键VLM模型及其主要特性:
参考链接:https://zhuanlan.zhihu.com/p/1923438673086649859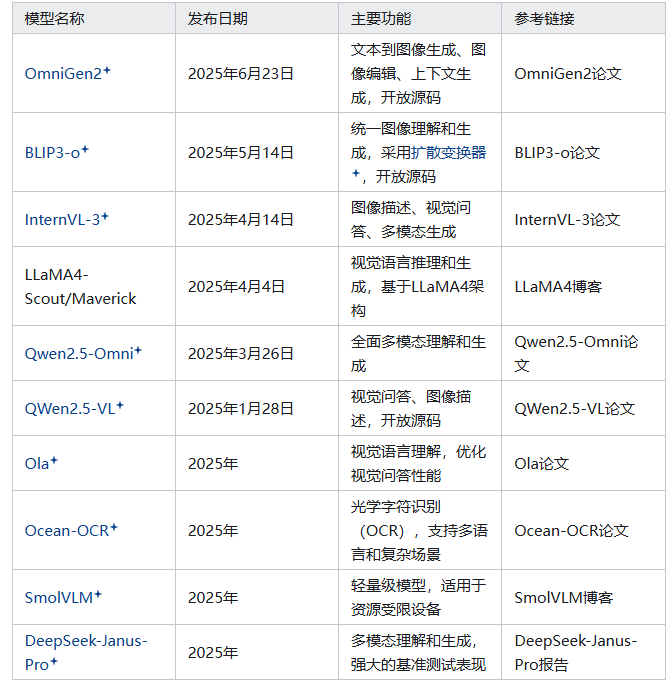
-
OmniGen2是一个通用的开放源码生成模型,支持文本到图像生成、图像编辑和上下文生成(也称为主题驱动任务)。它采用两种独立的解码路径分别处理文本和图像模态,基于现有多模态理解模型构建,保留了原有的文本生成能力。
OmniGen2在多项基准测试中表现出色,尤其是在新提出的OmniContext基准测试中,展示了上下文生成的一致性。此外,它开发了专门的图像编辑和上下文生成数据构建管道,并引入了针对图像生成任务的反思机制(Reflection Mechanism)。其开源特性(包括模型、训练代码和数据集)为未来研究提供了重要支持。 -
BLIP3-o是一个全开放的统一多模态模型,专注于图像理解和生成的统一。它采用扩散变换器(Diffusion Transformer)生成语义丰富的CLIP图像特征,相比传统的变分自编码器(VAE)方法,提高了训练效率和生成质量。BLIP3-o使用顺序预训练策略:先进行图像理解训练,再进行图像生成训练,从而在保持理解能力的同时发展生成能力。它还创建了高质量的指令调整数据集BLIP3o-60k,由GPT-4o生成多样化的图像描述。BLIP3-o在图像理解和生成任务的多个基准测试中表现出色,并完全开源,包括代码、模型权重和数据集。
-
InternVL-3:进一步优化了视觉语言理解和生成能力,特别是在图像描述和视觉问答任务中表现出色。
-
LLaMA4-Scout/Maverick:基于Meta AI的LLaMA4架构,专注于视觉语言推理和生成任务。
-
Qwen2.5-Omni和QWen2.5-VL:Qwen系列模型的最新版本,支持全面的多模态任务,提供了强大的性能和开源资源。
-
SmolVLM:轻量级模型,适合在资源受限的设备上运行,保持了较高的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)