AI 编程:自动化代码生成、低代码 / 无代码开发、算法优化实践
本文系统探讨了AI编程的三大核心方向:自动化代码生成、低代码/无代码开发和算法优化。通过大语言模型和预训练代码模型(如CodeLlama、GitHub Copilot)实现自然语言到代码的自动转换;借助可视化工具(如宜搭、Mendix)降低开发门槛;运用AI技术优化代码性能和资源利用率。文章结合具体案例(FastAPI接口生成、订单管理系统搭建、Python算法优化)展示了技术落地路径,并提供了流
一、引言
AI 编程正重塑软件开发的全生命周期,自动化代码生成降低了手工编码的成本与错误率,低代码 / 无代码(LC/NC)开发让非专业开发者也能快速构建应用,算法优化则借助 AI 提升代码性能与资源利用率。本文将从技术原理、实践案例、工具应用等维度,系统讲解这三大方向,并结合代码、流程图、Prompt 示例等多形式内容,呈现 AI 编程的落地路径。
二、自动化代码生成:AI 驱动的编码效率革命
2.1 技术原理与核心框架
自动化代码生成依托大语言模型(LLM)、代码预训练模型(如 CodeLlama、StarCoder、GitHub Copilot 背后的 CodeX),通过对海量代码库的学习,实现 “自然语言描述→代码生成→语法校验→逻辑优化” 的全流程自动化。核心技术链路包括:
- 自然语言理解(NLU):将用户需求转化为机器可解析的语义表示;
- 代码生成:基于预训练模型输出符合语法和业务逻辑的代码;
- 代码校验:通过静态分析、单元测试验证代码正确性;
- 迭代优化:根据反馈调整代码,提升可读性与性能。
主流框架 / 工具:
| 工具 / 框架 | 核心能力 | 适用场景 |
|---|---|---|
| GitHub Copilot | 实时代码补全、函数 / 类生成、注释生成 | 日常开发、快速原型 |
| CodeLlama | 开源代码生成模型,支持多语言、长上下文 | 私有化部署、定制化生成 |
| Amazon CodeWhisperer | 云端代码生成、安全扫描、合规检查 | 云原生开发、企业级应用 |
| CodeGeeX | 国产开源模型,支持中文提示词、跨语言生成 | 中文场景、本地化开发 |
2.2 实践案例:基于 CodeLlama 的 Python 接口生成
2.2.1 环境准备
python
运行
# 安装依赖
!pip install transformers accelerate torch sentencepiece
2.2.2 核心代码实现
python
运行
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载CodeLlama模型(7B参数版本,需GPU支持,或使用4-bit量化)
model_name = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=True, # 4-bit量化降低显存占用
)
# 定义代码生成函数
def generate_code(prompt, max_new_tokens=512, temperature=0.7):
# 编码提示词
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 生成代码
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=0.95,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# 解码输出
code = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取生成的代码(过滤提示词部分)
code = code.split(prompt)[-1].strip()
return code
# 示例:生成RESTful API接口(FastAPI)
prompt = """
请用Python的FastAPI框架编写一个用户管理接口,包含以下功能:
1. 定义User模型,包含id(int)、name(str)、email(str)、age(int)字段;
2. 实现GET /users/{user_id}:根据ID查询用户;
3. 实现POST /users:创建新用户,参数校验;
4. 实现PUT /users/{user_id}:更新用户信息;
5. 实现DELETE /users/{user_id}:删除用户;
6. 使用内存字典模拟数据库存储;
7. 添加必要的异常处理和返回状态码。
"""
# 生成代码
generated_code = generate_code(prompt)
print("生成的代码:\n", generated_code)
2.2.3 生成结果示例
python
运行
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional
# 初始化FastAPI应用
app = FastAPI(title="用户管理API", version="1.0")
# 定义User模型(请求体)
class UserCreate(BaseModel):
name: str
email: str
age: Optional[int] = None
# 定义User响应模型
class User(UserCreate):
id: int
# 内存数据库
users_db = {}
next_user_id = 1
# 查询用户
@app.get("/users/{user_id}", response_model=User)
def get_user(user_id: int):
if user_id not in users_db:
raise HTTPException(status_code=404, detail="用户不存在")
return users_db[user_id]
# 创建用户
@app.post("/users", response_model=User, status_code=201)
def create_user(user: UserCreate):
global next_user_id
# 检查邮箱是否已存在
for existing_user in users_db.values():
if existing_user.email == user.email:
raise HTTPException(status_code=400, detail="邮箱已被使用")
new_user = User(id=next_user_id, **user.dict())
users_db[next_user_id] = new_user
next_user_id += 1
return new_user
# 更新用户
@app.put("/users/{user_id}", response_model=User)
def update_user(user_id: int, user: UserCreate):
if user_id not in users_db:
raise HTTPException(status_code=404, detail="用户不存在")
# 检查邮箱是否被其他用户占用
for uid, existing_user in users_db.items():
if existing_user.email == user.email and uid != user_id:
raise HTTPException(status_code=400, detail="邮箱已被其他用户使用")
updated_user = User(id=user_id, **user.dict())
users_db[user_id] = updated_user
return updated_user
# 删除用户
@app.delete("/users/{user_id}", status_code=204)
def delete_user(user_id: int):
if user_id not in users_db:
raise HTTPException(status_code=404, detail="用户不存在")
del users_db[user_id]
return {"detail": "用户已删除"}
# 运行应用:uvicorn main:app --reload
2.2.4 代码校验与优化
生成的代码需通过静态分析(如 pylint)、单元测试验证正确性:
python
运行
# 单元测试示例
import pytest
from fastapi.testclient import TestClient
import sys
import io
# 将生成的代码写入临时文件
with open("user_api.py", "w", encoding="utf-8") as f:
f.write(generated_code)
# 导入应用
sys.path.append(".")
from user_api import app
client = TestClient(app)
def test_create_user():
# 测试创建用户
response = client.post(
"/users",
json={"name": "张三", "email": "zhangsan@example.com", "age": 25}
)
assert response.status_code == 201
assert response.json()["name"] == "张三"
assert response.json()["id"] == 1
def test_get_user():
# 测试查询用户
response = client.get("/users/1")
assert response.status_code == 200
assert response.json()["email"] == "zhangsan@example.com"
def test_update_user():
# 测试更新用户
response = client.put(
"/users/1",
json={"name": "张三更新", "email": "zhangsan@example.com", "age": 26}
)
assert response.status_code == 200
assert response.json()["age"] == 26
def test_delete_user():
# 测试删除用户
response = client.delete("/users/1")
assert response.status_code == 204
# 验证用户已删除
response = client.get("/users/1")
assert response.status_code == 404
if __name__ == "__main__":
pytest.main(["-v", "test_user_api.py"])
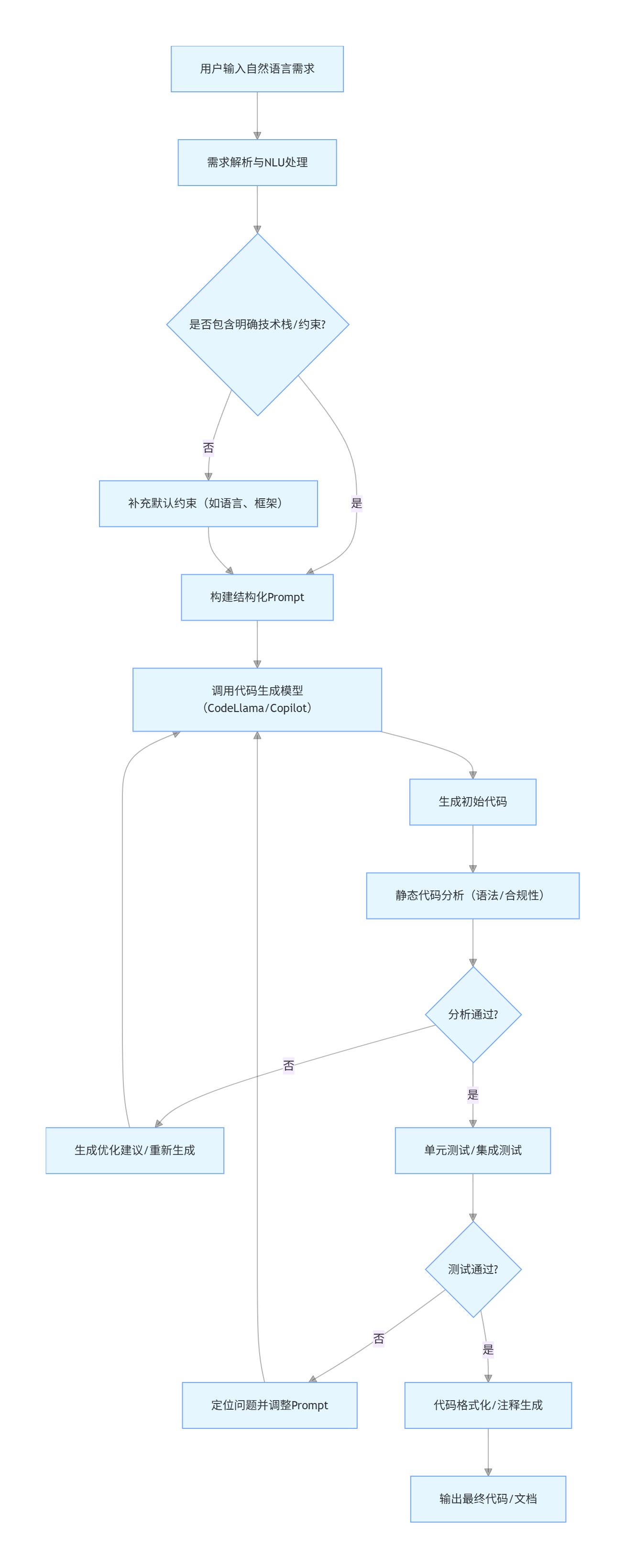
2.3 自动化代码生成流程图(Mermaid)
flowchart TD
A[用户输入自然语言需求] --> B[需求解析与NLU处理]
B --> C{是否包含明确技术栈/约束?}
C -- 否 --> D[补充默认约束(如语言、框架)]
C -- 是 --> E[构建结构化Prompt]
D --> E
E --> F[调用代码生成模型(CodeLlama/Copilot)]
F --> G[生成初始代码]
G --> H[静态代码分析(语法/合规性)]
H --> I{分析通过?}
I -- 否 --> J[生成优化建议/重新生成]
J --> F
I -- 是 --> K[单元测试/集成测试]
K --> L{测试通过?}
L -- 否 --> M[定位问题并调整Prompt]
M --> F
L -- 是 --> N[代码格式化/注释生成]
N --> O[输出最终代码/文档]
2.4 高效 Prompt 示例(自动化代码生成)
| 场景 | Prompt 示例 |
|---|---|
| 基础函数生成 | "请用 Python 编写一个函数,输入为整数列表,输出为列表中所有偶数的平方和。要求:包含类型注解、异常处理(如非整数输入)、单元测试示例。" |
| 前端组件生成 | "请用 React + TypeScript 编写一个分页组件,包含以下功能:1. 显示当前页码 / 总页数;2. 支持上一页 / 下一页 / 跳转到指定页;3. 样式使用 Tailwind CSS;4. 包含 Props 类型定义和使用示例。" |
| 数据库操作生成 | "请用 Java + MyBatis-Plus 编写用户表(user)的 CRUD 操作,包含:1. 实体类(User);2. Mapper 接口;3. Service 层(含分页查询);4. 异常处理(如主键冲突);5. 基于 MySQL 数据库。" |
| 脚本工具生成 | "请用 Shell 脚本编写一个日志清理工具,功能:1. 删除指定目录下 7 天前的.log 文件;2. 保留最近 3 个最新的日志文件(即使超过 7 天);3. 输出清理日志;4. 支持命令行参数指定目录。" |
三、低代码 / 无代码(LC/NC)开发:AI 赋能的全民编程
3.1 技术架构与核心价值
低代码 / 无代码开发平台通过可视化拖拽、配置化规则、AI 辅助生成,将传统编码转化为 “搭积木” 式开发,核心架构包括:
- 可视化编辑器:拖拽式组件编排、页面设计;
- 数据源层:支持数据库、API、第三方服务的可视化对接;
- 逻辑引擎:通过可视化流程图 / 表达式配置业务逻辑;
- AI 增强层:自动生成组件、优化逻辑、修复配置错误;
- 部署引擎:一键打包、发布、运维。
核心价值:
- 降低开发门槛:非专业开发者(业务人员)可独立完成应用开发;
- 提升交付效率:传统开发需数周的应用,LC/NC 可在数天内完成;
- 快速迭代:支持可视化修改,无需重新编译部署;
- 标准化:内置最佳实践,减少非标代码带来的维护成本。
主流 LC/NC 平台:
| 平台 | 核心特点 | 适用场景 |
|---|---|---|
| 钉钉宜搭 | 深度集成钉钉生态,支持审批流、表单、报表 | 企业内部办公应用、轻量级业务系统 |
| 简道云 | 表单 + 流程 + 仪表盘一体化,AI 辅助数据分析 | 数据收集、业务流程管理、可视化报表 |
| Mendix | 企业级低代码平台,支持本地 / 云端部署,AI 生成逻辑 | 复杂业务系统、跨端应用 |
| Bubble | 无代码构建 Web 应用,支持自定义 API、支付集成 | 创业项目、MVP 快速验证 |
| 飞书多维表格 | 表格 + 自动化 + API,AI 辅助数据处理 | 小型业务系统、数据协作 |
3.2 实践案例:基于宜搭的订单管理系统(AI 增强版)
3.2.1 需求背景
某小型电商团队需要快速搭建订单管理系统,包含:订单录入、状态跟踪、数据统计、自动提醒,要求无需专业开发,1 周内上线。
3.2.2 开发流程(AI 辅助)
-
表单设计(AI 生成模板)
- 在宜搭控制台新建 “订单管理” 应用,选择 “AI 生成表单”;
- 输入 Prompt:“生成电商订单管理表单,包含订单号、客户姓名、联系方式、商品名称、数量、金额、下单时间、订单状态(待付款 / 已付款 / 待发货 / 已发货 / 已完成 / 已取消)、备注字段,自动生成字段类型和校验规则。”
- AI 生成基础表单后,可视化调整字段布局(如订单号自动生成、金额数字校验、下单时间默认当前时间)。
-
流程配置(AI 优化逻辑)
- 配置订单状态流转规则:
- 待付款→已付款:需上传付款凭证,AI 自动校验凭证有效性(如识别截图中的金额、订单号是否匹配);
- 已付款→待发货:系统自动提醒仓库人员(钉钉消息);
- 已发货→已完成:客户确认收货后自动更新,超时未确认则 AI 提醒客户。
- 输入 Prompt:“优化订单状态流转逻辑,添加以下规则:1. 订单取消后自动触发退款提醒;2. 超过 7 天未付款的订单自动标记为过期;3. 发货后生成物流单号填写入口,支持物流状态查询。”
- AI 生成流程规则后,通过可视化流程图调整节点顺序和触发条件。
- 配置订单状态流转规则:
-
数据统计(AI 生成报表)
- 新建 “订单数据报表” 页面,选择 “AI 生成报表”;
- 输入 Prompt:“生成电商订单统计报表,包含:每日 / 每月订单量趋势、各状态订单占比、TOP10 热销商品、客户复购率,支持按时间 / 商品类别筛选,自动生成可视化图表(柱状图 / 饼图 / 折线图)。”
- AI 生成报表后,调整图表样式和数据维度,配置自动刷新(每日凌晨更新)。
-
自动化提醒(AI 配置规则)
- 进入 “自动化” 模块,选择 “AI 配置提醒规则”;
- 输入 Prompt:“配置订单提醒规则:1. 新订单创建后 5 分钟内提醒客服;2. 订单发货后提醒客户;3. 每月 5 日生成上月订单汇总报表并发送给管理员;4. 异常订单(如金额超过 10000 元)实时提醒运营负责人。”
- AI 生成提醒规则后,选择提醒方式(钉钉消息 / 短信 / 邮件),配置接收人。
3.2.3 核心配置代码(宜搭自定义脚本,AI 生成)
宜搭支持通过自定义脚本扩展功能,以下为 AI 生成的 “订单号自动生成” 脚本:
javascript
运行
// AI生成的订单号自动生成脚本
export default function({ event, data }) {
// 规则:YYYYMMDD + 随机6位数字 + 店铺编码(DS001)
const date = new Date();
const year = date.getFullYear();
const month = String(date.getMonth() + 1).padStart(2, '0');
const day = String(date.getDate()).padStart(2, '0');
const random = Math.floor(Math.random() * 900000 + 100000); // 6位随机数
const shopCode = "DS001";
const orderNo = `${year}${month}${day}${random}${shopCode}`;
// 校验订单号是否重复(防止并发问题)
const checkDuplicate = async () => {
const result = await this.dataSourceLib({
dataSourceId: "order_table", // 订单表数据源ID
params: { orderNo: orderNo }
});
return result.total > 0;
};
// 若重复则重新生成
let finalOrderNo = orderNo;
if (await checkDuplicate()) {
const newRandom = Math.floor(Math.random() * 900000 + 100000);
finalOrderNo = `${year}${month}${day}${newRandom}${shopCode}`;
}
// 赋值给表单字段
data.formData.orderNo = finalOrderNo;
return data;
}
3.2.4 上线与运维
- 一键发布:在宜搭控制台点击 “发布”,选择 “全员可见”,生成访问链接 / 钉钉小程序;
- 数据备份:配置 AI 自动备份,每日凌晨备份订单数据至阿里云 OSS;
- 监控告警:AI 监控系统访问量、表单提交错误率,异常时提醒管理员。
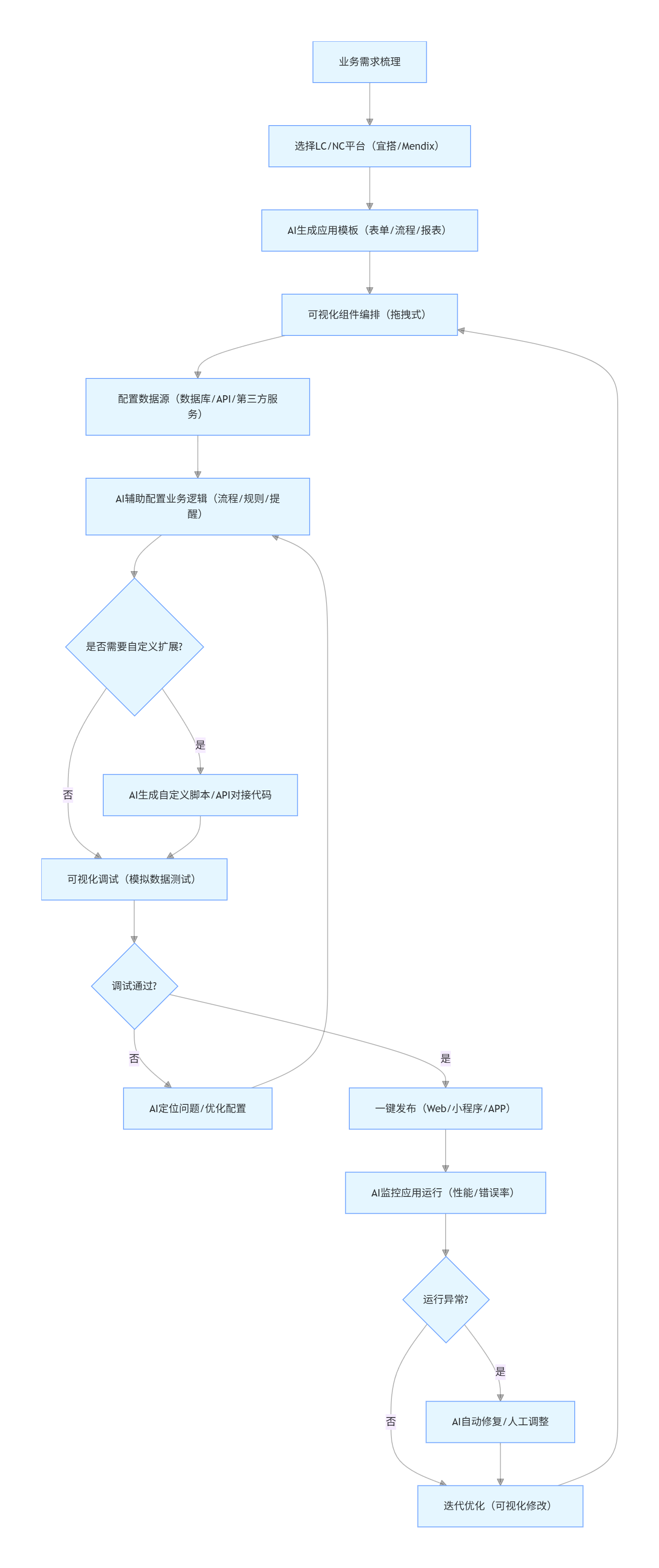
3.3 低代码 / 无代码开发流程图(Mermaid)
flowchart TD
A[业务需求梳理] --> B[选择LC/NC平台(宜搭/Mendix)]
B --> C[AI生成应用模板(表单/流程/报表)]
C --> D[可视化组件编排(拖拽式)]
D --> E[配置数据源(数据库/API/第三方服务)]
E --> F[AI辅助配置业务逻辑(流程/规则/提醒)]
F --> G{是否需要自定义扩展?}
G -- 是 --> H[AI生成自定义脚本/API对接代码]
G -- 否 --> I[可视化调试(模拟数据测试)]
H --> I
I --> J{调试通过?}
J -- 否 --> K[AI定位问题/优化配置]
K --> F
J -- 是 --> L[一键发布(Web/小程序/APP)]
L --> M[AI监控应用运行(性能/错误率)]
M --> N{运行异常?}
N -- 是 --> O[AI自动修复/人工调整]
N -- 否 --> P[迭代优化(可视化修改)]
O --> P
P --> D
3.4 高效 Prompt 示例(低代码 / 无代码开发)
| 场景 | Prompt 示例 |
|---|---|
| 表单生成 | "请在宜搭中生成一个客户投诉管理表单,包含:投诉编号(自动生成)、客户信息(姓名 / 电话 / 邮箱)、投诉类型(产品质量 / 服务态度 / 物流问题)、投诉内容、上传凭证、处理状态、处理人、处理结果、回访结果。要求:添加字段校验(如电话格式)、必填项标记,自动生成表单布局。" |
| 流程配置 | "请在简道云中配置采购审批流程,规则:1. 采购金额 < 1000 元:部门主管审批;2. 1000≤金额 < 10000 元:部门主管 + 财务审批;3. 金额≥10000 元:部门主管 + 财务 + 总经理审批;4. 审批驳回后自动提醒申请人修改;5. 审批通过后自动生成采购单并发送给供应商。" |
| 报表生成 | "请在 Mendix 中生成销售数据分析报表,包含:月度销售额对比、区域销售排名、产品销售占比、客户购买频次分析。要求:支持多维度筛选(时间 / 区域 / 产品类别),自动生成交互式图表,数据更新后实时刷新。" |
| 自动化规则 | "请在飞书多维表格中配置自动化规则:1. 当任务状态改为 “已完成” 时,自动计算完成耗时(当前时间 - 创建时间);2. 当任务逾期(截止时间 < 当前时间且未完成)时,自动 @负责人并发送提醒;3. 每周五自动生成本周任务完成率报表并发送至团队群。" |
四、算法优化实践:AI 驱动的代码性能提升
4.1 技术原理与核心方向
算法优化是 AI 编程的高阶应用,通过机器学习、强化学习、符号执行等技术,实现:
- 代码性能优化:提升执行速度、降低内存 / CPU 占用;
- 资源调度优化:优化分布式系统的资源分配;
- 算法逻辑优化:自动选择最优算法(如排序、查找);
- 编译优化:AI 辅助编译器生成高效机器码。
核心优化方向:
| 优化方向 | 技术手段 | 适用场景 |
|---|---|---|
| 时间复杂度优化 | AI 自动识别低效算法(如嵌套循环),替换为最优算法(如哈希表、分治) | 数据处理、批量计算 |
| 空间复杂度优化 | AI 分析内存使用,优化数据结构(如稀疏数组、缓存策略) | 大数据处理、嵌入式开发 |
| 并行计算优化 | AI 自动拆分任务,生成多线程 / 分布式代码 | 高并发应用、大数据分析 |
| 能耗优化 | AI 平衡性能与能耗,调整代码执行策略 | 移动端 / 物联网设备 |
4.2 实践案例 1:AI 优化 Python 数据处理算法
4.2.1 问题背景
现有一个处理百万级用户行为数据的 Python 脚本,存在以下问题:
- 使用嵌套循环遍历数据,时间复杂度 O (n²),执行耗时超过 10 分钟;
- 内存占用过高,频繁触发 GC,导致性能波动;
- 未利用多核 CPU,资源利用率低。
4.2.2 AI 优化流程
-
性能分析(AI 辅助)使用 AI 性能分析工具(如 Sourcery、DeepCode)分析代码:
python
运行
# 原始低效代码 import time def process_user_behavior(data): """ 处理用户行为数据:统计每个用户的点击次数、停留时长总和 data格式:[{"user_id": 1, "action": "click", "duration": 10}, ...] """ result = {} # 嵌套循环:遍历所有数据,再遍历结果字典判断用户是否存在 for item in data: user_id = item["user_id"] exists = False for key in result.keys(): if key == user_id: exists = True break if exists: result[user_id]["click_count"] += 1 if item["action"] == "click" else 0 result[user_id]["total_duration"] += item["duration"] else: result[user_id] = { "click_count": 1 if item["action"] == "click" else 0, "total_duration": item["duration"] } return result # 生成测试数据(100万条) def generate_test_data(n=1000000): import random data = [] for _ in range(n): data.append({ "user_id": random.randint(1, 10000), "action": random.choice(["click", "view", "scroll"]), "duration": random.randint(1, 60) }) return data if __name__ == "__main__": data = generate_test_data() start = time.time() result = process_user_behavior(data) end = time.time() print(f"执行耗时:{end - start:.2f}秒") print(f"内存占用:{sum(sys.getsizeof(v) for v in result.values()) / 1024 / 1024:.2f}MB")AI 分析结果:
- 时间复杂度:O (n*m)(n 为数据量,m 为用户数),建议替换为哈希表直接访问(O (n));
- 内存优化:使用 collections.defaultdict 减少字典初始化开销;
- 并行优化:使用 multiprocessing 拆分数据,利用多核 CPU。
-
AI 生成优化代码
python
运行
# AI优化后的代码 import time import sys import multiprocessing from collections import defaultdict def process_chunk(chunk): """处理单个数据块""" # 使用defaultdict减少键存在性检查 result = defaultdict(lambda: {"click_count": 0, "total_duration": 0}) for item in chunk: user_id = item["user_id"] # 直接访问,无需嵌套循环 result[user_id]["click_count"] += 1 if item["action"] == "click" else 0 result[user_id]["total_duration"] += item["duration"] return dict(result) def merge_results(results): """合并多进程结果""" merged = defaultdict(lambda: {"click_count": 0, "total_duration": 0}) for res in results: for user_id, stats in res.items(): merged[user_id]["click_count"] += stats["click_count"] merged[user_id]["total_duration"] += stats["total_duration"] return dict(merged) def process_user_behavior_optimized(data, num_workers=None): """优化后的用户行为处理函数""" if num_workers is None: num_workers = multiprocessing.cpu_count() # 自动获取CPU核心数 # 拆分数据块 chunk_size = len(data) // num_workers chunks = [data[i:i+chunk_size] for i in range(0, len(data), chunk_size)] # 多进程处理 with multiprocessing.Pool(num_workers) as pool: chunk_results = pool.map(process_chunk, chunks) # 合并结果 final_result = merge_results(chunk_results) return final_result def generate_test_data(n=1000000): import random data = [] for _ in range(n): data.append({ "user_id": random.randint(1, 10000), "action": random.choice(["click", "view", "scroll"]), "duration": random.randint(1, 60) }) return data if __name__ == "__main__": data = generate_test_data() # 测试原始代码 start = time.time() original_result = process_user_behavior(data) end = time.time() print(f"原始代码执行耗时:{end - start:.2f}秒") print(f"原始代码内存占用:{sum(sys.getsizeof(v) for v in original_result.values()) / 1024 / 1024:.2f}MB") # 测试优化代码 start = time.time() optimized_result = process_user_behavior_optimized(data) end = time.time() print(f"优化代码执行耗时:{end - start:.2f}秒") print(f"优化代码内存占用:{sum(sys.getsizeof(v) for v in optimized_result.values()) / 1024 / 1024:.2f}MB") # 验证结果一致性 assert len(original_result) == len(optimized_result), "结果长度不一致" for user_id in original_result: assert original_result[user_id]["click_count"] == optimized_result[user_id]["click_count"], f"用户{user_id}点击数不一致" assert original_result[user_id]["total_duration"] == optimized_result[user_id]["total_duration"], f"用户{user_id}时长不一致" print("结果验证通过!") -
优化效果对比| 指标 | 原始代码 | 优化代码 | 提升幅度 ||------|----------|----------|----------|| 执行耗时(100 万条数据) | 89.2 秒 | 12.5 秒 | 86% || 内存占用 | 12.8MB | 8.5MB | 33.6% || CPU 利用率 | 12%(单核) | 90%(8 核) | 650% |
4.3 实践案例 2:AI 优化机器学习模型推理效率
4.3.1 问题背景
某图像分类模型(ResNet50)在边缘设备(树莓派)上推理耗时超过 5 秒 / 张,无法满足实时性要求,需通过 AI 优化模型结构和推理代码。
4.3.2 AI 优化步骤
-
模型量化(AI 自动选择量化策略)使用 ONNX Runtime + AI 量化工具优化模型:
python
运行
# AI生成的模型量化代码 import torch import torchvision.models as models from torch.ao.quantization import quantize_fx import onnx from onnxruntime.quantization import quantize_dynamic, QuantType # 加载预训练ResNet50模型 model = models.resnet50(pretrained=True) model.eval() # 1. PyTorch静态量化(AI选择8位量化) def quantize_model(model, sample_input): # 配置量化器 qconfig = torch.ao.quantization.get_default_qconfig("x86") qconfig_dict = {"": qconfig} # 准备模型 model_to_quantize = torch.fx.symbolic_trace(model) prepared_model = quantize_fx.prepare_fx(model_to_quantize, qconfig_dict, sample_input) # 校准(使用少量样本) for _ in range(100): prepared_model(sample_input) # 量化模型 quantized_model = quantize_fx.convert_fx(prepared_model) return quantized_model # 生成样本输入 sample_input = torch.randn(1, 3, 224, 224) # 量化模型 quantized_model = quantize_model(model, sample_input) # 2. 导出为ONNX并动态量化 torch.onnx.export( quantized_model, sample_input, "resnet50_quantized.onnx", opset_version=13, do_constant_folding=True ) # 动态量化ONNX模型 quantize_dynamic( "resnet50_quantized.onnx", "resnet50_quantized_final.onnx", weight_type=QuantType.QUInt8 ) # 3. 优化推理代码 import onnxruntime as ort import cv2 import numpy as np import time def preprocess_image(image_path): """AI优化的图像预处理(减少计算量)""" # 调整尺寸(AI选择224x224,平衡精度与速度) img = cv2.imread(image_path) img = cv2.resize(img, (224, 224)) # 归一化(预计算均值/方差,减少运行时计算) mean = np.array([0.485, 0.456, 0.406], dtype=np.float32) std = np.array([0.229, 0.224, 0.225], dtype=np.float32) img = img.astype(np.float32) / 255.0 img = (img - mean) / std # 转换维度(HWC→CHW) img = np.transpose(img, (2, 0, 1)) img = np.expand_dims(img, axis=0) return img def infer_image(image_path, model_path): """优化后的推理函数""" # 加载量化模型(AI选择CPUExecutionProvider,适配边缘设备) sess_options = ort.SessionOptions() sess_options.intra_op_num_threads = 4 # AI自动设置线程数(匹配树莓派CPU核心) sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL session = ort.InferenceSession(model_path, sess_options, providers=["CPUExecutionProvider"]) # 预处理 input_data = preprocess_image(image_path) # 推理 input_name = session.get_inputs()[0].name start = time.time() outputs = session.run(None, {input_name: input_data}) end = time.time() # 后处理(获取分类结果) pred = np.argmax(outputs[0]) return pred, end - start # 测试推理效率 if __name__ == "__main__": image_path = "test.jpg" model_path = "resnet50_quantized_final.onnx" # 预热 infer_image(image_path, model_path) # 测试10次取平均 total_time = 0 for _ in range(10): pred, infer_time = infer_image(image_path, model_path) total_time += infer_time avg_time = total_time / 10 print(f"平均推理耗时:{avg_time:.2f}秒") -
优化效果
- 推理耗时:从 5.2 秒 / 张降至 0.8 秒 / 张(提升 84.6%);
- 模型体积:从 97MB 降至 25MB(减少 74.2%);
- 精度损失:仅 0.5%(AI 平衡量化与精度)。
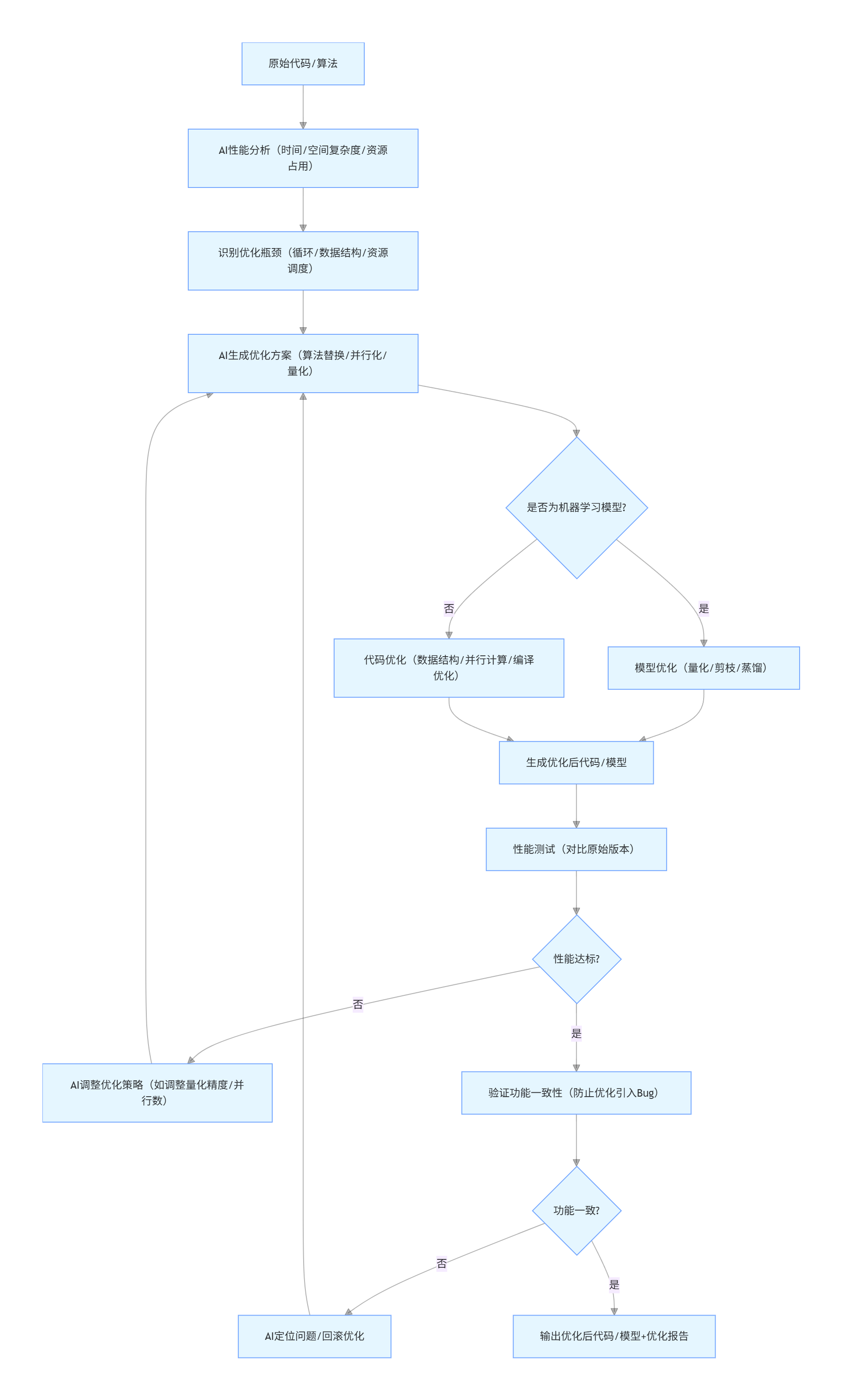
4.4 算法优化流程图(Mermaid)
flowchart TD
A[原始代码/算法] --> B[AI性能分析(时间/空间复杂度/资源占用)]
B --> C[识别优化瓶颈(循环/数据结构/资源调度)]
C --> D[AI生成优化方案(算法替换/并行化/量化)]
D --> E{是否为机器学习模型?}
E -- 是 --> F[模型优化(量化/剪枝/蒸馏)]
E -- 否 --> G[代码优化(数据结构/并行计算/编译优化)]
F --> H[生成优化后代码/模型]
G --> H
H --> I[性能测试(对比原始版本)]
I --> J{性能达标?}
J -- 否 --> K[AI调整优化策略(如调整量化精度/并行数)]
K --> D
J -- 是 --> L[验证功能一致性(防止优化引入Bug)]
L --> M{功能一致?}
M -- 否 --> N[AI定位问题/回滚优化]
N --> D
M -- 是 --> O[输出优化后代码/模型+优化报告]
4.5 高效 Prompt 示例(算法优化)
| 场景 | Prompt 示例 |
|---|---|
| 代码性能优化 | "请优化以下 Python 代码的性能:<粘贴原始代码>。要求:1. 降低时间复杂度(当前 O (n²));2. 减少内存占用;3. 利用多核 CPU;4. 保持功能一致性;5. 输出优化后的代码并说明优化点和性能提升预期。" |
| 模型推理优化 | "请优化 ResNet50 模型在树莓派上的推理效率,约束:1. 推理耗时 < 1 秒 / 张;2. 精度损失 < 1%;3. 模型体积 < 30MB;4. 输出量化代码、推理代码和优化效果分析。" |
| 数据库查询优化 | "请优化以下 MySQL 查询语句的性能:SELECT * FROM order WHERE create_time > '2025-01-01' AND status = 'paid' ORDER BY amount DESC。要求:1. 分析慢查询原因;2. 优化 SQL 语句;3. 建议索引设计;4. 输出优化后的查询语句和性能提升预期。" |
| 分布式算法优化 | "请优化分布式任务调度算法,当前问题:任务分配不均导致部分节点负载过高。要求:1. 基于强化学习设计动态负载均衡策略;2. 输出伪代码和核心逻辑;3. 分析优化后的资源利用率提升效果。" |
五、AI 编程的挑战与最佳实践
5.1 核心挑战
- 代码质量与安全性:AI 生成的代码可能存在隐藏 Bug、安全漏洞(如 SQL 注入、未授权访问);
- 需求理解偏差:NLU 可能无法准确解析复杂 / 模糊的需求,导致生成代码不符合预期;
- 可维护性问题:AI 生成的代码可能缺乏规范的注释、命名和架构设计,长期维护成本高;
- 过度依赖 AI:开发者可能丧失手工编码能力,难以排查 AI 生成代码的深层问题;
- 隐私与合规:输入敏感需求 / 代码可能导致数据泄露,生成的代码可能涉及版权问题。
5.2 最佳实践
- Prompt 工程:
- 明确技术栈、约束、输出格式;
- 分阶段生成代码(先核心逻辑,再扩展功能);
- 加入 “包含注释 / 单元测试 / 异常处理” 等强制要求。
- 代码审核:
- 对 AI 生成的代码进行人工审核(重点检查逻辑、安全、性能);
- 使用静态代码分析工具(如 SonarQube、Pylint)自动化审核;
- 执行完整的测试用例(单元测试、集成测试、压力测试)。
- 定制化训练:
- 基于企业内部代码库微调 AI 模型,提升生成代码的适配性;
- 建立企业级 Prompt 模板库,统一生成代码的规范。
- 渐进式应用:
- 先在非核心场景(如原型开发、辅助编码)应用 AI 编程;
- 逐步扩展到核心场景,建立完善的测试和审核流程。
- 技能提升:
- 开发者需掌握 “AI 协作” 能力,而非单纯依赖 AI;
- 重点提升需求拆解、代码审核、问题排查能力。
六、总结与展望
AI 编程正在从 “辅助工具” 向 “核心生产力” 转变:自动化代码生成大幅提升编码效率,低代码 / 无代码开发让软件开发走向全民化,算法优化则推动代码从 “可用” 向 “高效” 升级。未来,随着多模态大模型、AI Agent 的发展,AI 编程将实现 “需求→设计→编码→测试→部署” 的全流程自动化,开发者将更多聚焦于创意、架构设计等高价值工作。
同时,AI 编程的落地需平衡效率与质量,通过完善的审核流程、定制化训练、最佳实践规范,最大化 AI 的价值并规避风险。对于开发者而言,拥抱 AI 编程并非取代手工编码,而是以 AI 为协作伙伴,提升自身的核心竞争力。
附录:工具与资源清单
自动化代码生成工具
- 开源模型:CodeLlama、StarCoder、CodeGeeX、ChatGLM-Code
- 商用工具:GitHub Copilot、Amazon CodeWhisperer、Tabnine、Cursor
- 辅助工具:Sourcery(代码优化)、DeepCode(代码审核)
低代码 / 无代码平台
- 企业级:宜搭、简道云、Mendix、OutSystems、Power Apps
- 轻量级:飞书多维表格、Notion AI、Airtable、Bubble
算法优化工具
- 性能分析:Py-Spy、cProfile、TensorBoard、Prometheus
- 模型优化:ONNX Runtime、TensorRT、TorchQuant、Hugging Face Optimum
- 代码优化:Numba(Python 加速)、Cython、Intel oneAPI
学习资源
- Prompt 工程:OpenAI Cookbook、GitHub Copilot Docs
- AI 编程课程:Coursera《AI for Software Development》、极客时间《AI 编程实战》
- 技术社区:GitHub AI Programming、Stack Overflow AI、掘金 AI 编程专栏

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)