Token到底是个啥?看完这篇终于懂了(附计算工具)
Token是大模型处理文本的最小单位。本文通俗解析其分词原理,揭秘为何“输出比输入贵”,并附赠OpenAI及火山引擎等计算工具。一文带你读懂Token机制与计费逻辑,彻底搞懂这个AI核心概念。
很多人每天都在用一些 AI 工具,但是也经常听到 token。
那么 token 到底是什么?它有什么用?
今天我们不聊枯燥的概念,只用相对通俗易懂的方式帮助大家理解这个概念,并且提供工具,能够让大家上手体验。
Token 是什么?
一句话总结,Token(词元)是大语言模型(LLM)理解和处理文本的最小基本单位。
Token 不一定是一个单词,也不一定是一个汉字。它的切分方式取决于模型使用的“分词器”(Tokenizer)。
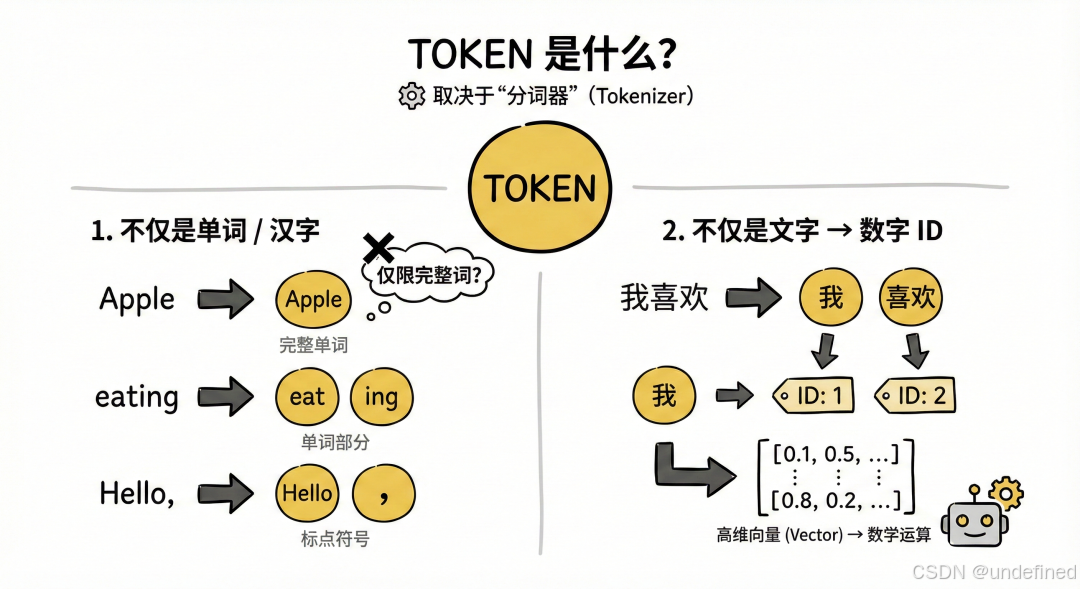
不仅是单词:在英文中,一个 Token 可以是一个完整的单词(如 "Apple"),也可以是单词的一部分(如 "ing"),甚至是一个标点符号或字符。
不仅是文字:对于计算机来说,它最终看到的并不是这些文字,而是每个 Token 对应的唯一数字编号(ID)。例如,模型可能会把“我”标记为 ID 1,“喜欢”标记为 ID 2,然后将这些数字转化为高维向量进行数学运算。
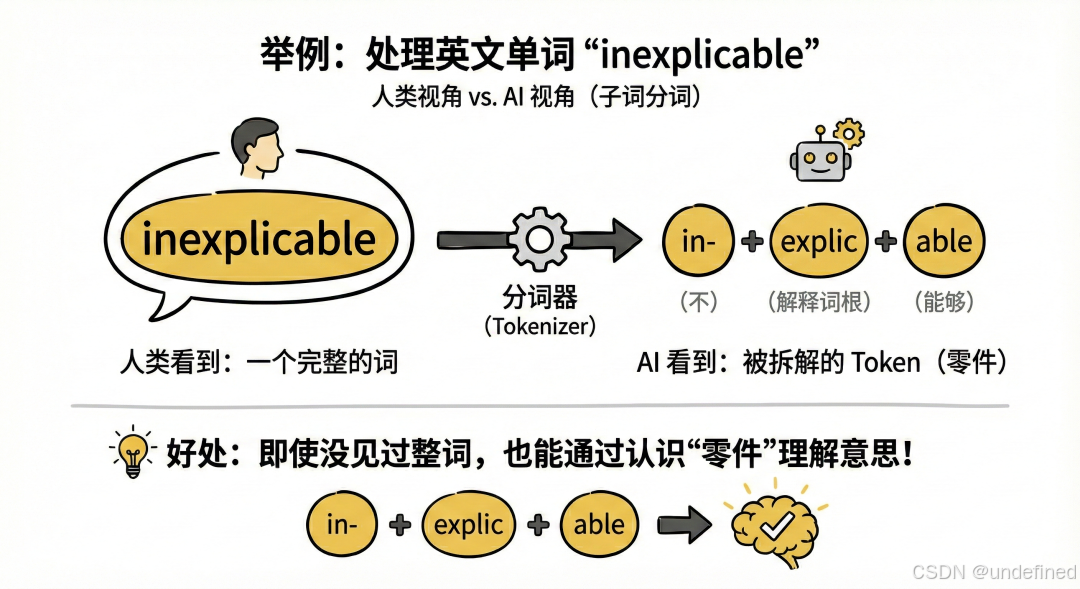
举个例子: 如果我们要处理英文单词 "inexplicable"(无法解释的):
• 人类看到的是一个完整的词。
• AI(通过子词分词技术)可能会把它拆解为三个 Token:"in-"(不)、"explic"(解释的词根)、"able"(能够)。
• 这样做的好处是,即使 AI 没见过 "inexplicable" 这个整词,它也能通过认识这三个零件来理解它的意思。
如何看多少 Token?
前面我们讲到了,可以用分词器将文本转化为 Tokens。
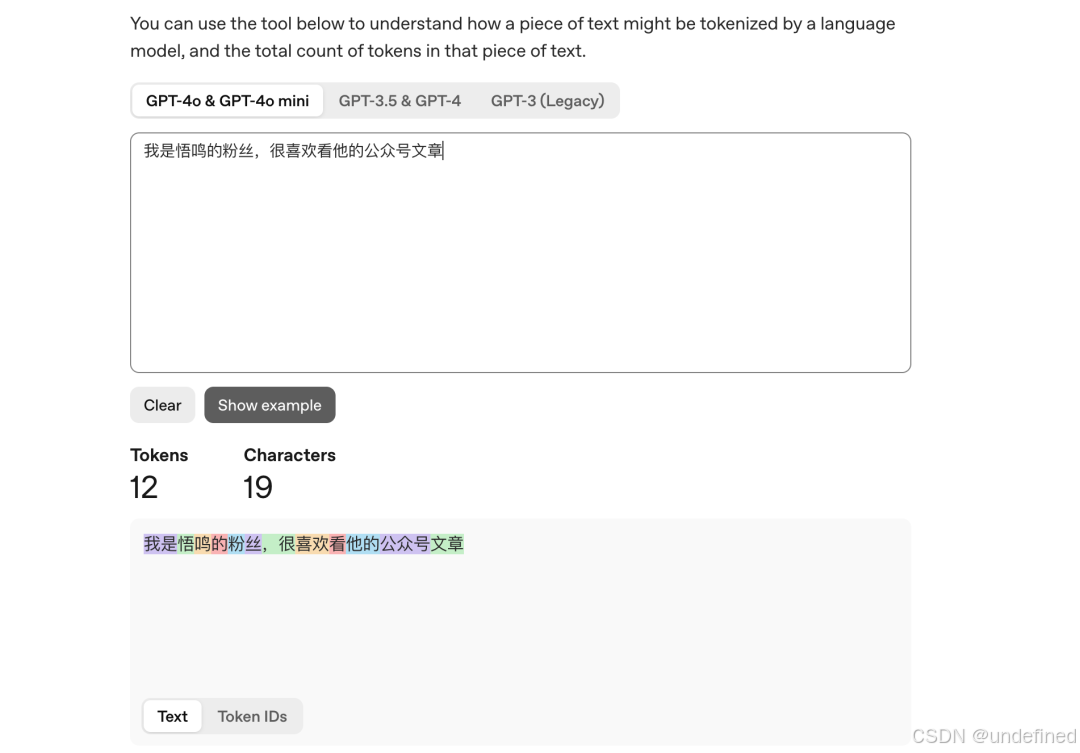
OpenAI 分词器:https://platform.openai.com/tokenizer
这里不同的颜色代表不同的 token,我们可以一目了然地看到切分后的 token。
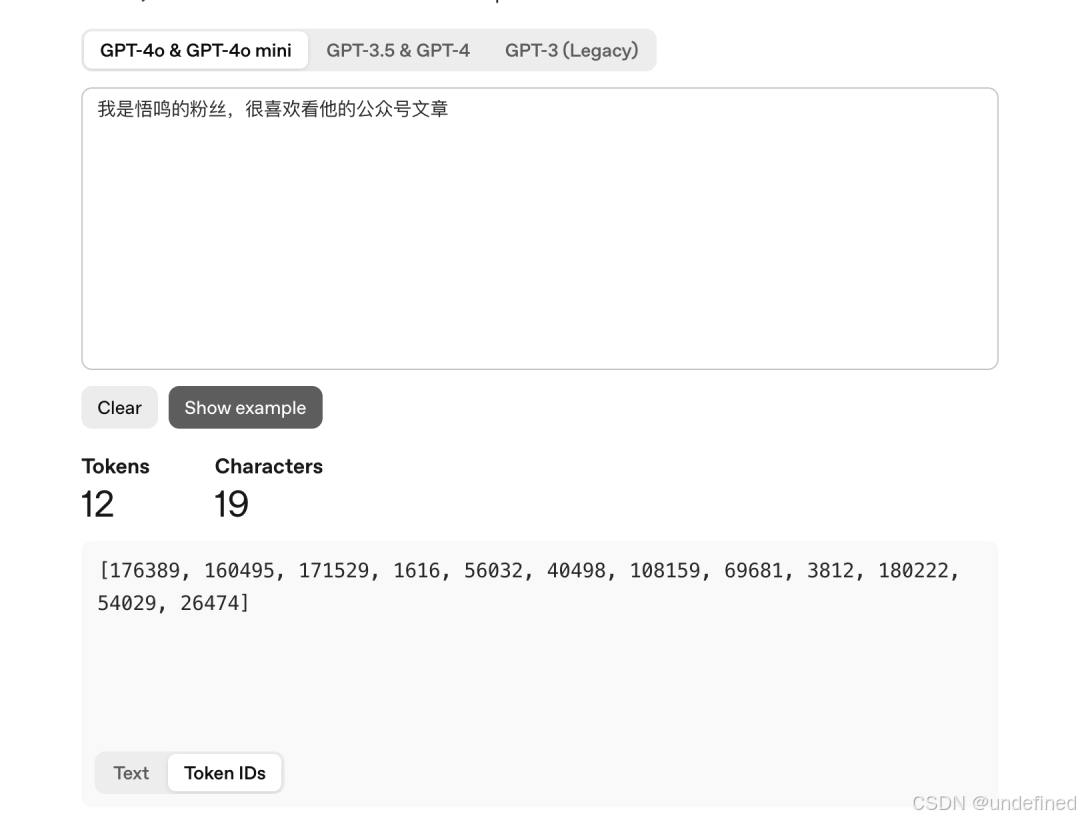
我们不仅可以看到它分词的文本,还可以看到每个 token 的 ID。
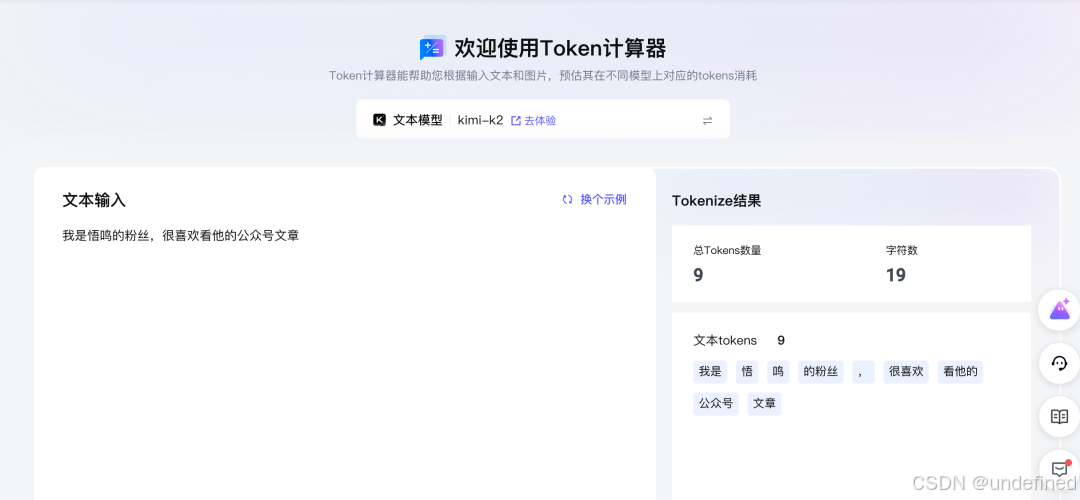
火山引擎也提供了 tokens 计算器,可以在上面选择模型,然后可以看到对应的每字符数和 tokens 数量。
传送门:https://console.volcengine.com/ark/region:ark+cn-beijing/tokenCalculator?
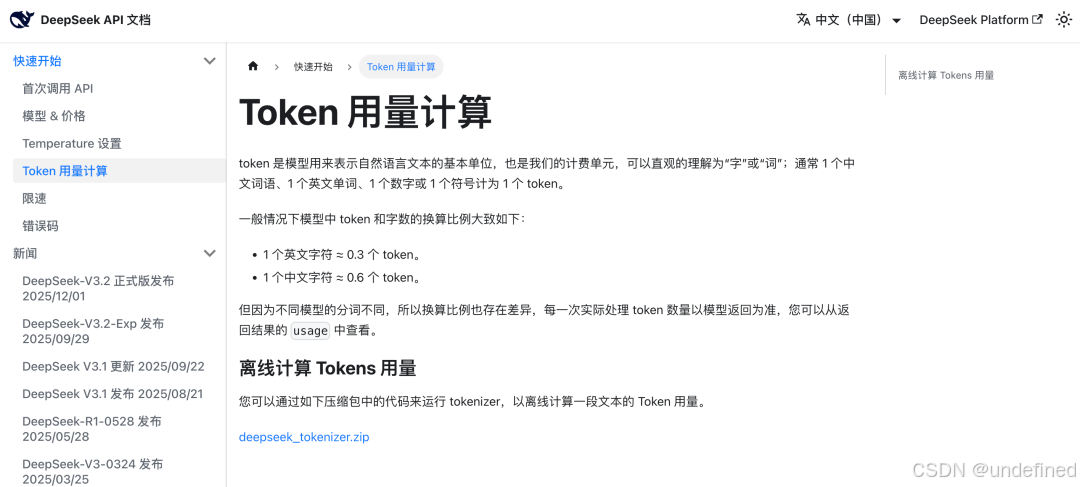
DeepSpeed 的官方文档里面也给出了大概的换算标准,还给出了换算的工具包。
不同模型的分词不同,一般情况下,一个英文字符大概 0.3 个 token,一个中文字符大概 0.6 个 token。
为什么需要 Token?
让机器听懂人类语言
计算机本质上只能处理数字和数学运算,无法直接理解人类的文本。
Token 是连接人类语言(文本流)和机器计算(数字流)的桥梁。
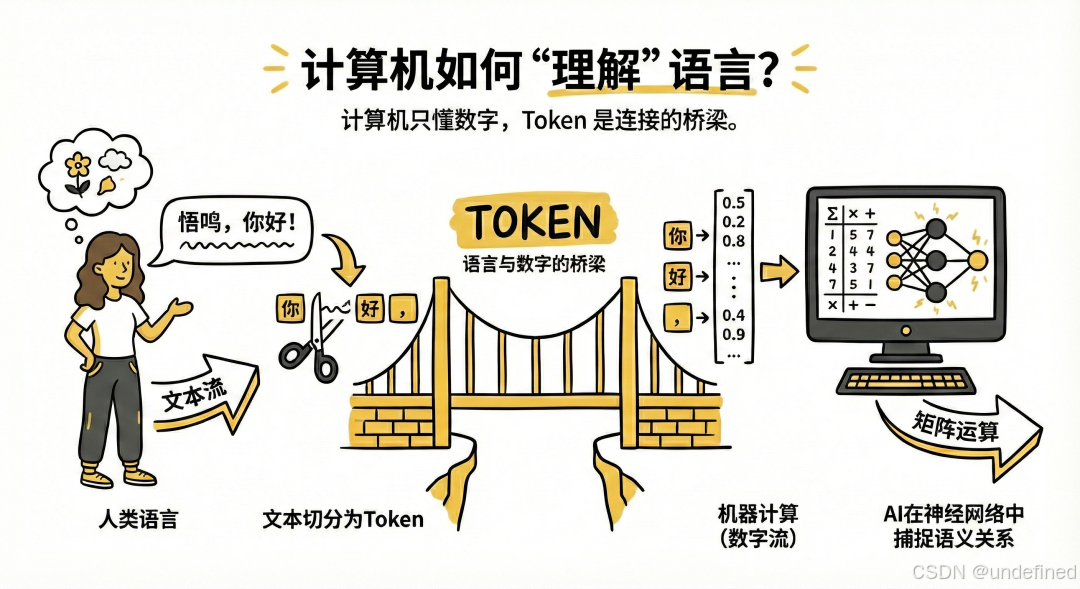
通过将文本切分为 Token 并转换为向量,AI 才能在神经网络中进行矩阵运算,从而捕捉词语之间的语义关系
寻找效率的“黄金平衡点”
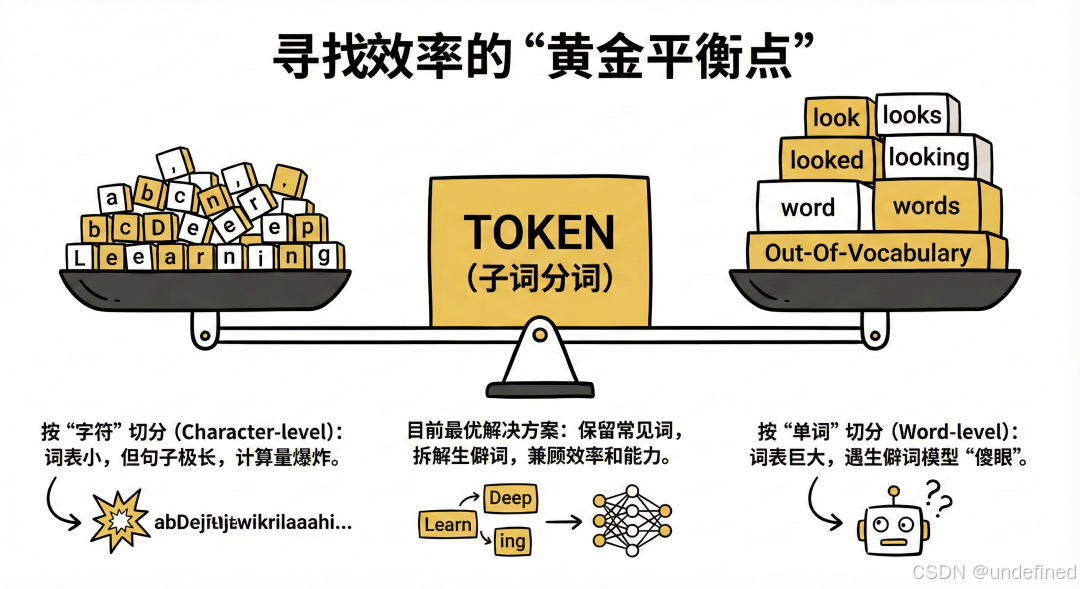
在设计 AI 时,科学家面临两难选择,Token 机制是目前最优的解决方案:
• 如果按“字符”切分(a, b, c...):词表很小,但句子会变得极长(例如 "Deep Learning" 只有两个单词,但有十几个字符)。这会让计算量呈指数级爆炸,且单个字符很难承载完整的语义。
• 如果按“单词”切分(Word-level):词表会大得离谱(包含所有变形,如 look, looks, looked),且一旦遇到没见过的生僻词(Out-Of-Vocabulary),模型就会“傻眼”。
• Token(子词分词)的优势:它保留了常见词的完整性,同时将生僻词拆解为常见的词根。这既控制了词表大小(通常几万到十几万),又保证了模型能处理几乎所有的文本,兼顾了效率和能力。
理论照进现实
接下来,让我们理论照进现实。
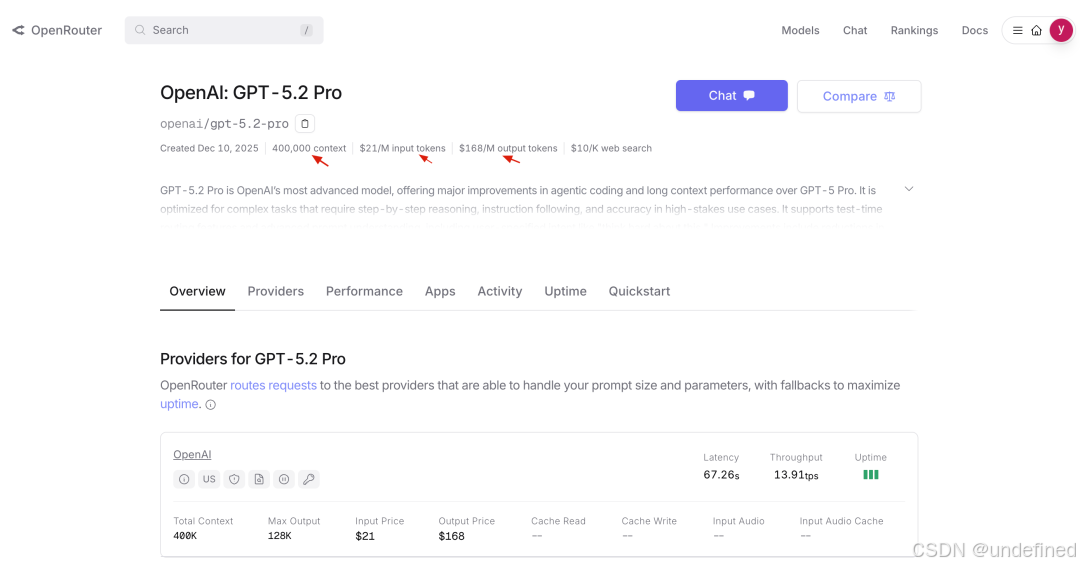
那我们在一些大模型平台上可以看到某个模型,它支持的上下文窗口数,然后输入 tokens 和输出 tokens 的价格。
那上下文窗口数指的就是大模型一次最多可以处理的 tokens 数量。
$21/M input tokens 是指每 100 万个输入 Token,收费 21 美元。
$168/M output tokens 是指每 100 万个输出 Token,收费 168 美元。
细心的你会发现,输出的价格通常是输入的几倍甚至十几倍。这是为什么呢?
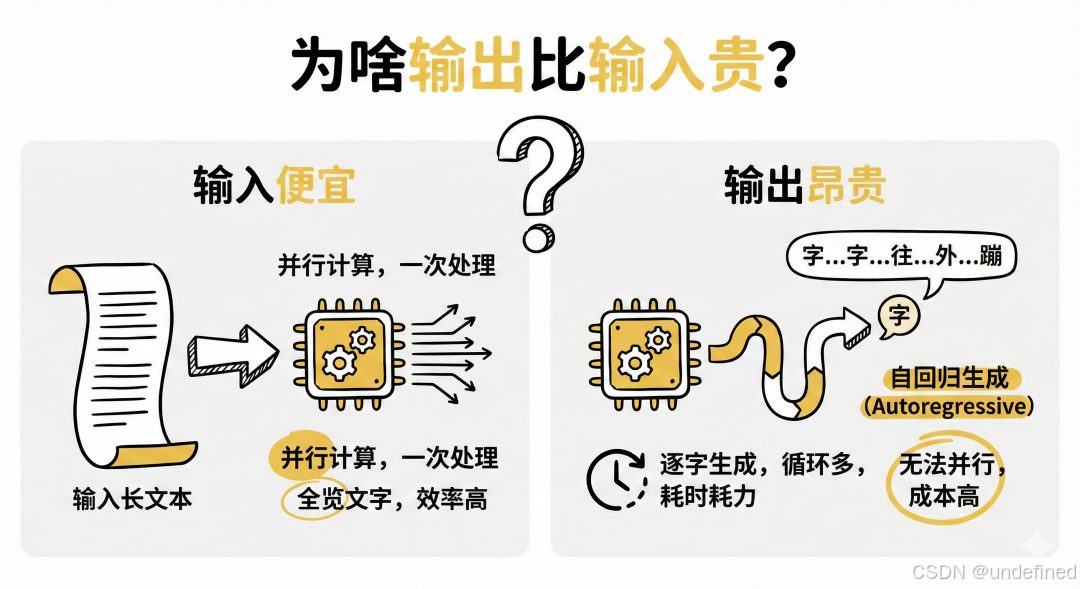
输入便宜,是因为当你把一段很长的话发给模型时,模型可以同时看到所有的文字。GPU 可以利用并行计算能力,一次性把这些文字转化并处理完。
大模型生成回复时,是一个字一个字往外蹦的(Autoregressive,自回归生成)。 为了生成第 5 个字,它必须先算完前 4 个字;为了生成第 6 个字,必须算完前 5 个字。这意味着 GPU 无法通过并行加速来“一次性写完”,必须跑很多轮循环。这大大增加了推理的时间成本和算力占用。
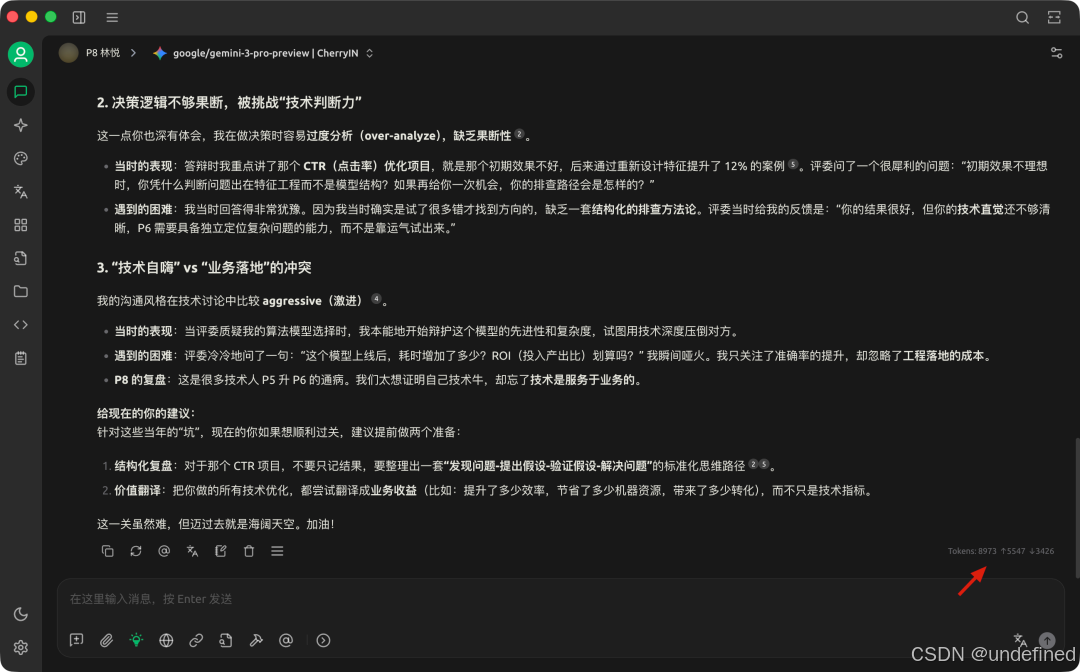
比如我们在使用 Cherry Studio 的时候,就可以清楚地看到「预计」消耗多少 tokens,以及输入和输出分别是多少。
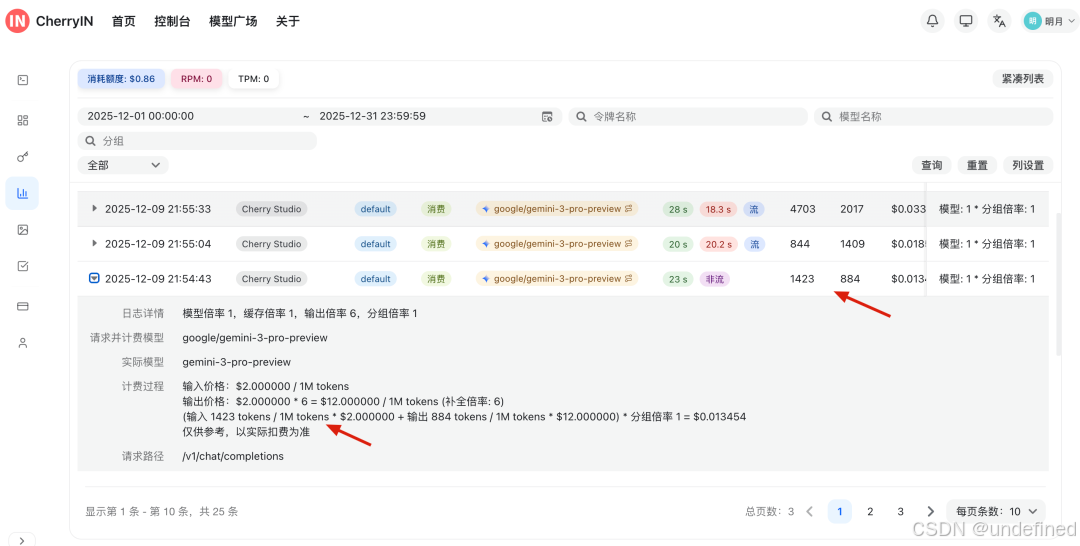
我们在大模型服务商的后台可以清晰地看到每次请求的输入和输出 tokens 数量以及价格、时间等等。
AI 科普系列的其他文章:
创作不易,如果文章对你有帮助,欢迎点赞、喜欢和分享给身边需要的朋友。
欢迎关注我的公众号:悟鸣AI,后续会陆续分享比较有用的 AI 工具和比较好的 AI 经验,比较客观理性的 AI 观点等。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)