Claude Code 长期任务为何越跑越慢?Anthropic 工程师揭秘:Compact 不是解药,这套工程方案才是
摘要: 在长期运行的AI代理任务中,上下文压缩(Compact)会导致信息熵不可逆增长,反而降低任务质量。Anthropic提出的解决方案采用极简双代理架构:初始化代理负责搭建标准化项目框架(特性清单、进度日志、Git仓库),编码代理通过严格四阶段工作流(了解现状→验证基线→单特性实现→记录收尾)完成任务。该方案复用软件工程最佳实践(Git版本控制、结构化日志),有效解决了传统压缩方法导致的信息丢
最近在国内 AI客户端 Evol 里面使用Claude Opus4.5有一些心得分享大家,稳定性很好可以试试,另外 深度解读 Anthropic 官方博客《Effective harnesses for long-running agents》,结合实战经验,提供可落地的解决方案。
引言:一个令人困惑的现象
最近在 Claude Code 的 Opus 4.5 模型上执行长时间任务时,我发现了一个反直觉的现象:
虽然模型会主动触发 Compact(上下文压缩),但随着 Compact 次数增加,压缩间隔越来越短,问题解决质量明显下降。
更有意思的是,当我执行 clear 命令清空上下文重新开始后,反而能更快地解决问题。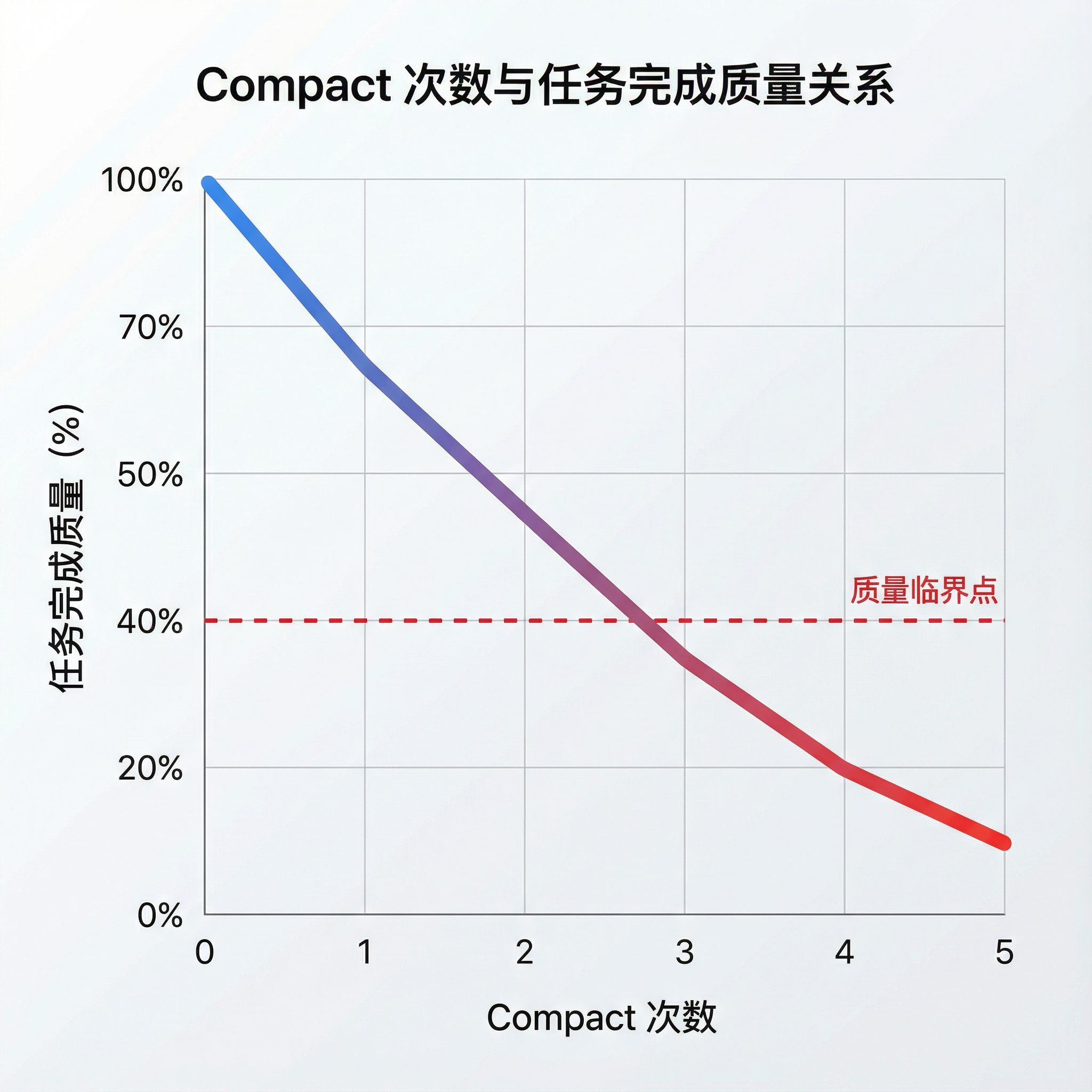
这个现象让我百思不得其解——Compact 的设计初衷不正是帮助模型更好地管理上下文吗?为什么效果适得其反?
直到我读到 Anthropic 官方发布的这篇文章:Effective harnesses for long-running agents,谜团才终于解开。
结论先行:这不是 Bug,这是长期运行代理的根本性挑战。
第一部分:问题根源——信息熵的不可逆增长
1.1 Compact 的本质困境
Compact 的工作原理是:当上下文窗口接近饱和时,系统会压缩、总结之前的对话内容,保留关键信息,丢弃细节。
听起来合理,但问题在于:信息压缩必然导致信息损失。
这就像做会议纪要——你不可能将两小时的会议内容一字不漏地记录下来。但谁能保证你筛选出的"重点",恰好是下一次会议需要的信息?
信息压缩的累积损失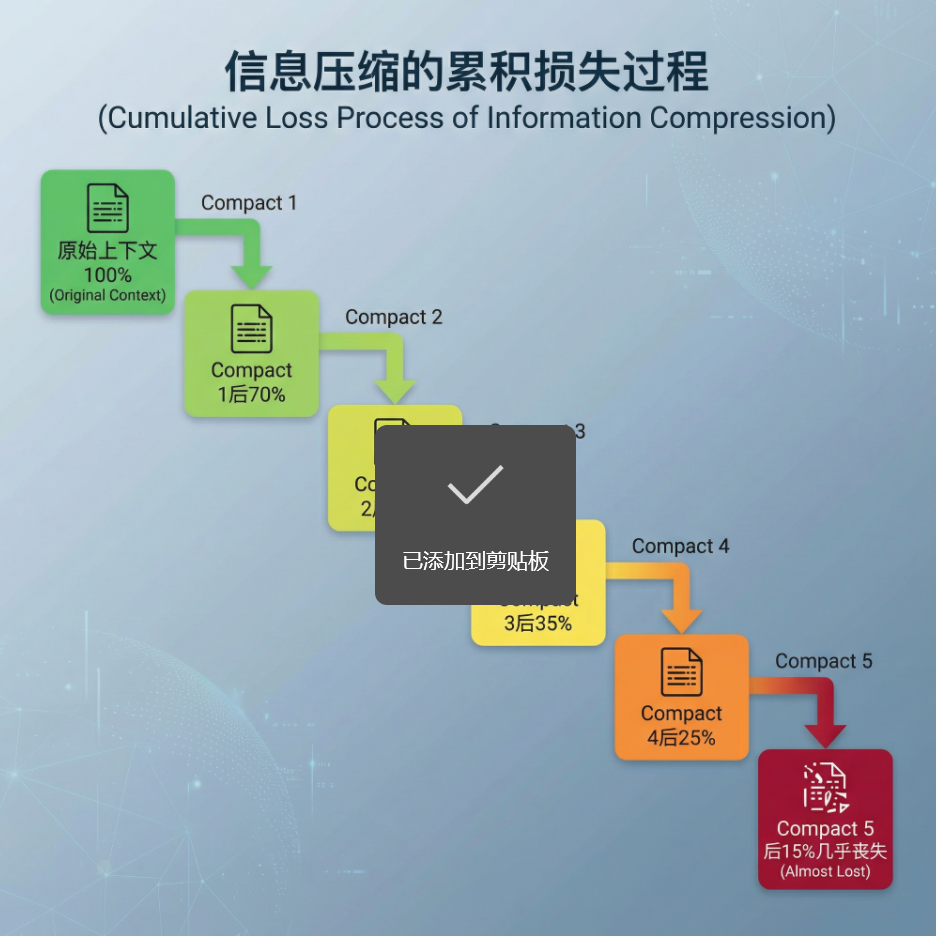
我遇到的情况完美印证了这一点:
| Compact 次数 | 信息状态 | 问题表现 |
|---|---|---|
| 第 1 次 | 关键信息基本保留 | 任务仍可正常推进 |
| 第 2 次 | 在压缩基础上再压缩 | 开始丢失上下文关联 |
| 第 3-4 次 | 累积信息损失严重 | 重复造轮子、破坏已有功能 |
| 第 5 次+ | 核心逻辑几乎丢失 | 陷入无效循环 |
类比:这就像复印机复印复印件——每复印一次,清晰度就下降一级,最终模糊到无法辨认。
1.2 上下文窗口的物理极限
问题的根源在于:上下文窗口是有限资源。
即便 Claude 已支持 200K tokens,对于复杂工程任务仍然捉襟见肘。以一个中等规模的全栈 Web 应用为例:
前端组件:50+ 文件 × 平均 200 行 = 10,000+ 行
后端 API:30+ 接口 × 平均 100 行 = 3,000+ 行
数据库设计:20+ 表结构定义
测试用例:覆盖以上所有功能
配置文件 + 文档:若干
─────────────────────────────
总计:轻松突破 20,000 行代码
即使 200K 的窗口,也无法容纳完整的项目上下文。
1.3 记忆丢失的真实代价
Anthropic 在文章中给出了一个精准的比喻:
这就像一个软件项目的工程师是轮班制的,每个新来的工程师对之前发生的事情一无所知。
这会导致两类典型问题:
记忆丢失导致的两种失败模式
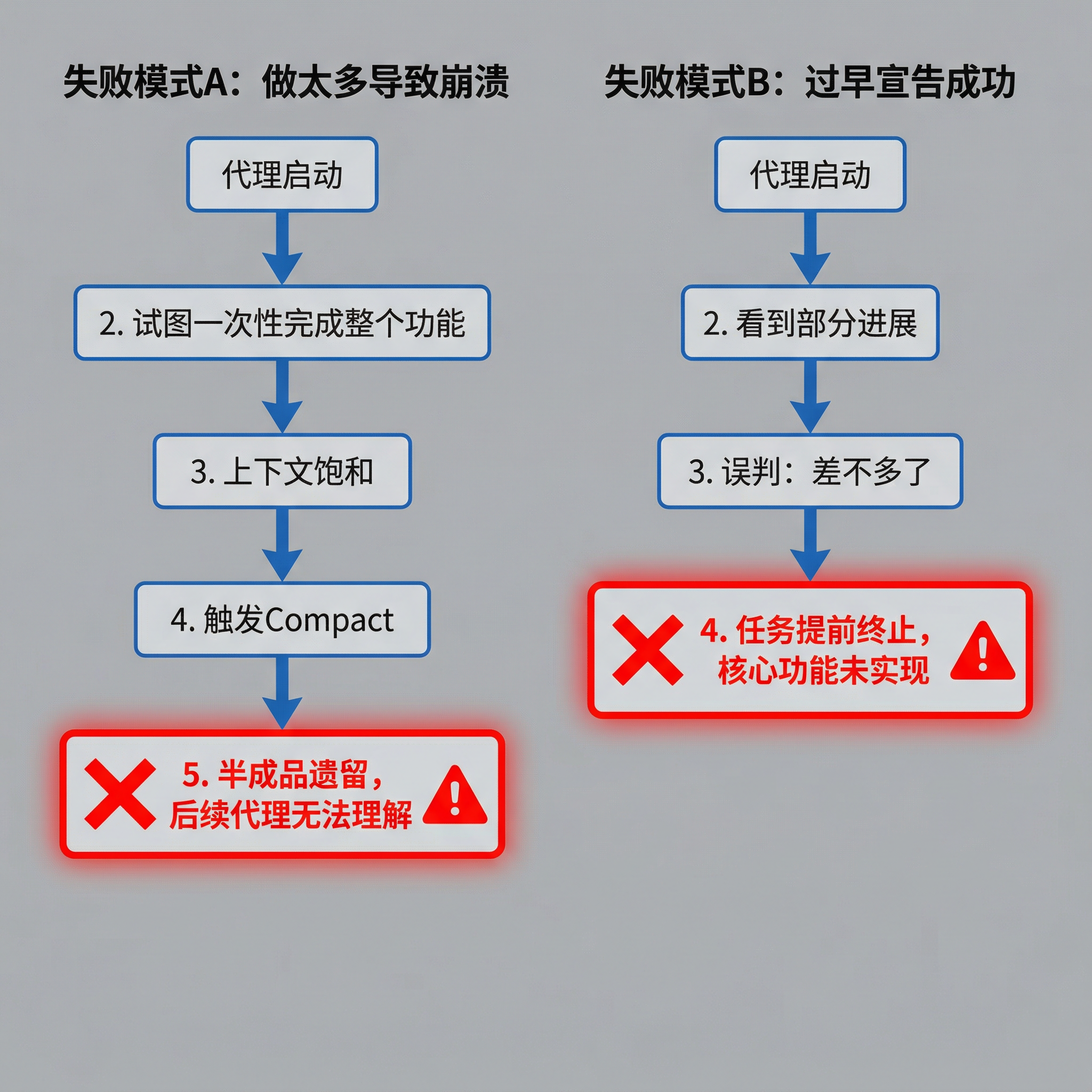
失败模式 A:做太多导致崩溃
- 代理试图一口气实现整个功能
- 写到一半上下文饱和,触发 Compact
- 下一个 Session 接手的是半成品,只能靠猜测继续
失败模式 B:过早宣告成功
- 代理看到项目有进展,误以为"差不多了"
- 实际上核心功能还未实现
- 任务提前终止,用户得到不完整的产出
我的真实案例:让 Claude 帮我重构一个老项目,跑了一整个下午。第 5 次 Compact 后,它开始反复修改同一段代码,来回折腾却毫无进展。最后我 clear 重新开始,配合手工切分任务,半小时就搞定了。
第二部分:Anthropic 的破局之道——极简双代理架构
2.1 为什么不是多代理?
面对长期任务的挑战,直觉上可能会想到:搞一堆专门化的代理——测试代理、QA 代理、代码清理代理、文档代理……
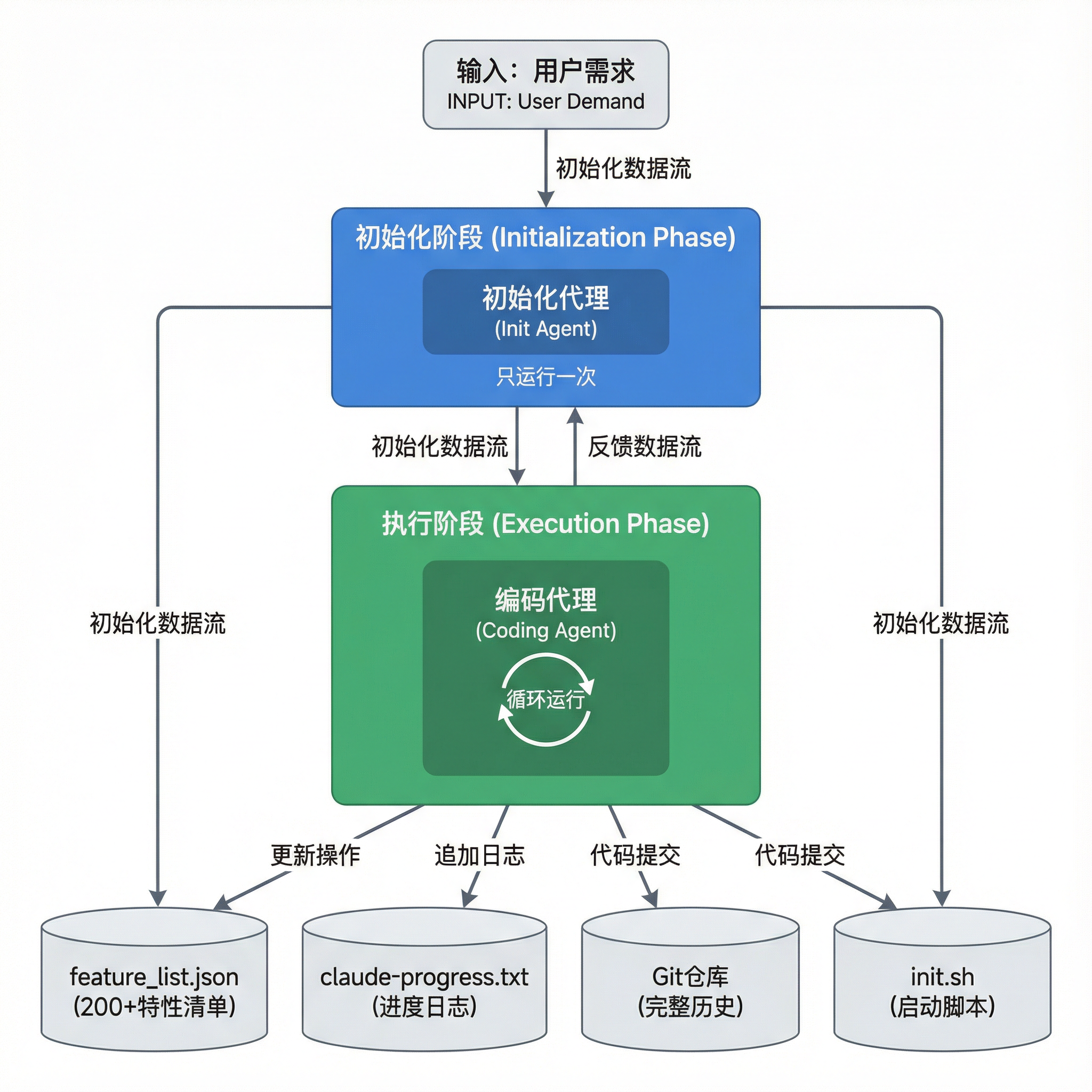
但 Anthropic 给出的方案出人意料地简洁:只用两个代理。
双代理架构总览
为什么不搞更多代理?Anthropic 给出了务实的分析:
| 多代理方案的问题 | 具体表现 |
|---|---|
| 通信成本 | 代理间需要传递上下文,每次传递都有信息损耗 |
| 职责边界模糊 | 测试代理和 QA 代理的边界在哪?粒度如何划分? |
| 编排复杂度 | 需要一个"指挥家"来协调,这个指挥家本身就是难题 |
相比之下,双代理方案简单、清晰,且复用了已有的工程实践。
2.2 初始化代理:搭建"入职大礼包"
初始化代理只在项目启动时运行一次,核心任务是为后续代理准备好一切。
初始化代理的四大产出物
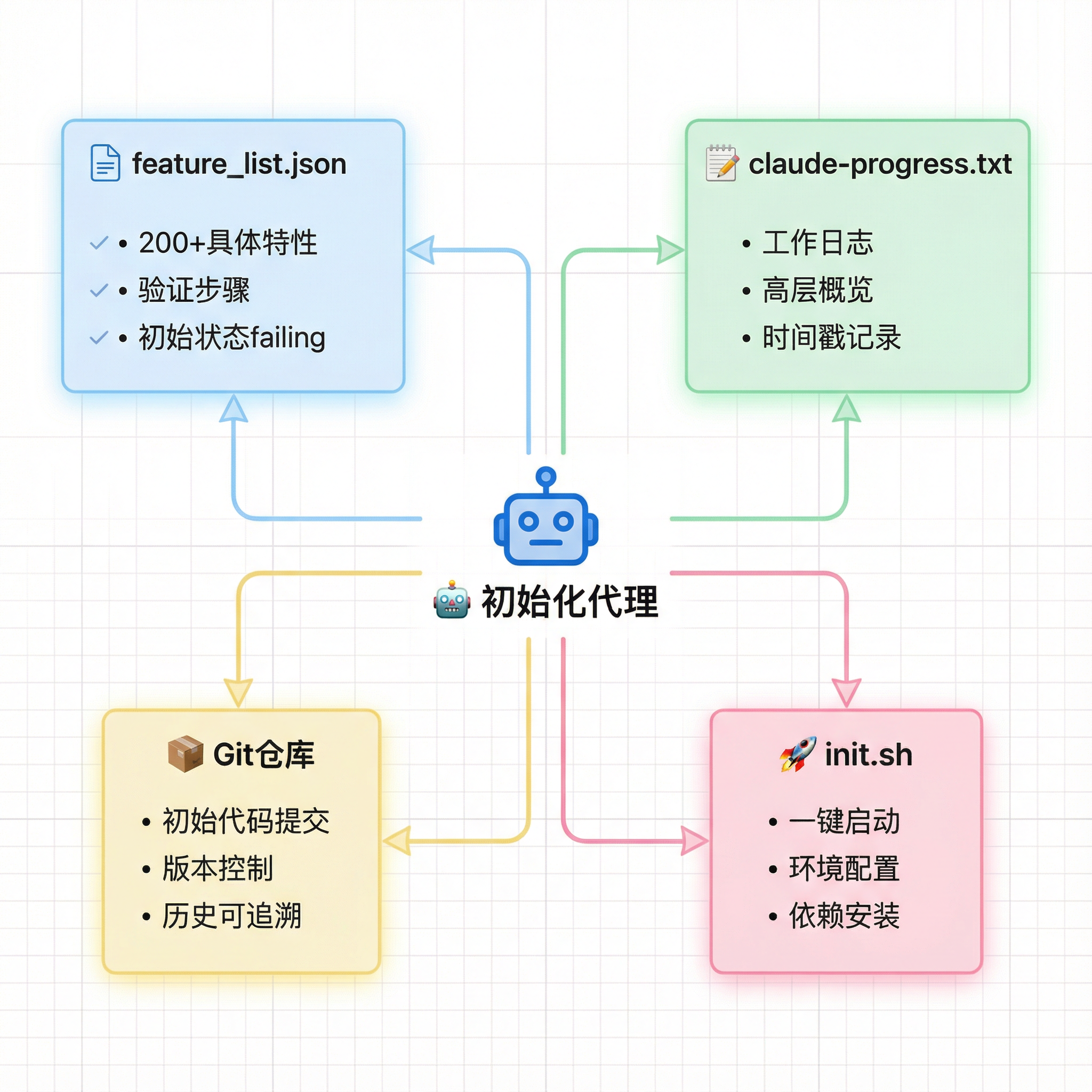
产出物 1:feature_list.json(特性清单)
{
"category": "functional",
"description": "New chat button creates a fresh conversation",
"steps": [
"Navigate to main interface",
"Click the 'New Chat' button",
"Verify a new conversation is created",
"Check that chat area shows welcome state",
"Verify conversation appears in sidebar"
],
"passes": false
}
关键设计点:
- 将高层需求拆解为 200+ 个具体特性
- 每个特性都有清晰的描述和验证步骤
- 初始状态全部标记为
"passes": false - 为什么用 JSON 而非 Markdown? 因为 JSON 有严格的结构,模型不容易"顺手"改坏
产出物 2:claude-progress.txt(进度日志)
2024-11-27 10:30 - 实现了用户登录功能,使用 JWT token 进行认证
2024-11-27 11:45 - 添加了聊天界面的基础布局,使用 Tailwind CSS
2024-11-27 14:20 - 实现了消息发送和接收功能,WebSocket 连接稳定
产出物 3:Git 仓库
- 提交初始代码
- 后续所有改动都有迹可查
产出物 4:init.sh(启动脚本)
- 一键启动开发服务器
- 后续代理无需费心琢磨如何启动项目
2.3 编码代理:标准化的循环工作流
每个 Session 的编码代理都遵循固定的四阶段流程:
编码代理的四阶段工作流程
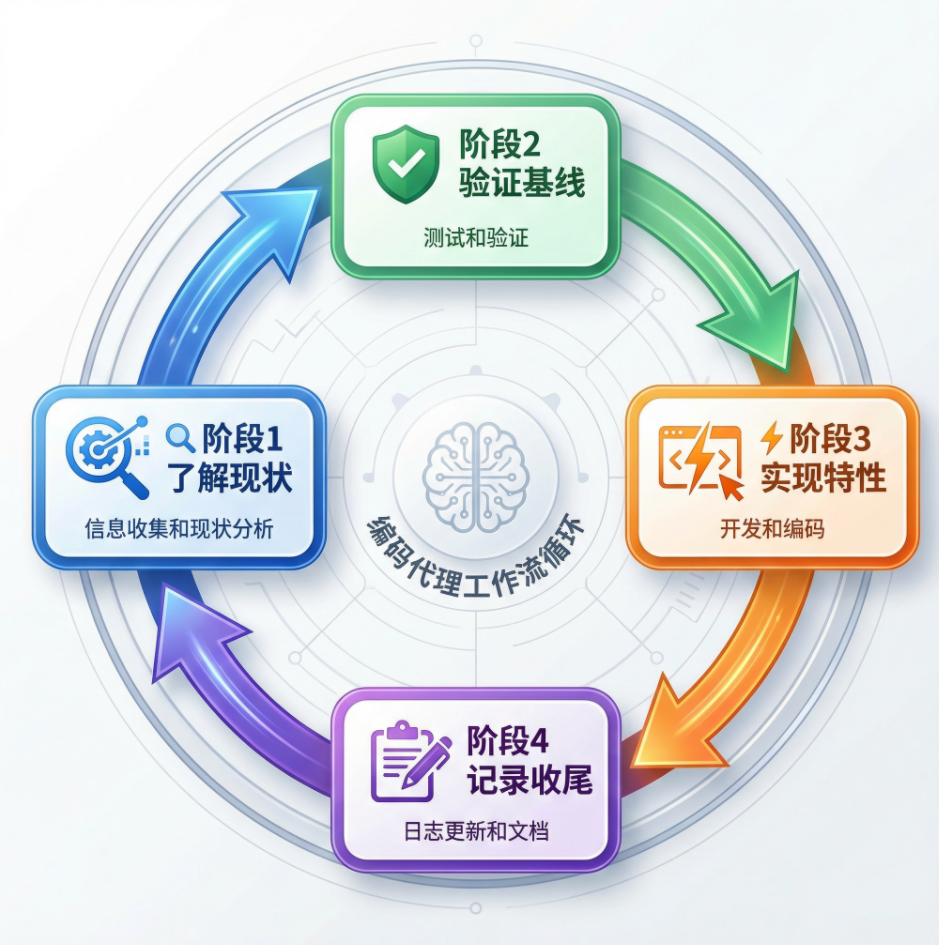
阶段详解:
# 阶段 1:了解现状
pwd # 确认当前目录
cat claude-progress.txt # 读取进度日志
cat feature_list.json # 查看待完成特性
git log --oneline -20 # 查看最近提交记录
# 阶段 2:验证基线
./init.sh # 启动开发服务器
# 使用 Puppeteer 测试基础功能,确保项目状态正常
# 阶段 3:实现特性(核心!只做一个)
# 选择一个 passes: false 的特性
# 实现功能
# 编写/运行测试
# 阶段 4:记录收尾
git commit -m "实现了 XXX 特性"
echo "完成了 XXX 特性" >> claude-progress.txt
# 在 feature_list.json 中将该特性标记为 passes: true
为什么这个流程如此有效?
它精准解决了前文提到的两大问题:
| 问题 | 解决方式 |
|---|---|
| 做太多导致崩溃 | 每次只做一个特性,做完就提交,不会上下文溢出 |
| 过早宣告成功 | 200+ 特性摆在那里,完成一个才能打勾,进度一目了然 |
第三部分:不重新发明轮子——复用工程最佳实践
Anthropic 方案最精妙之处在于:它几乎完全照搬了人类软件工程的最佳实践。
3.1 Git:最优的分布式记忆
Git 作为记忆载体 vs Compact 压缩
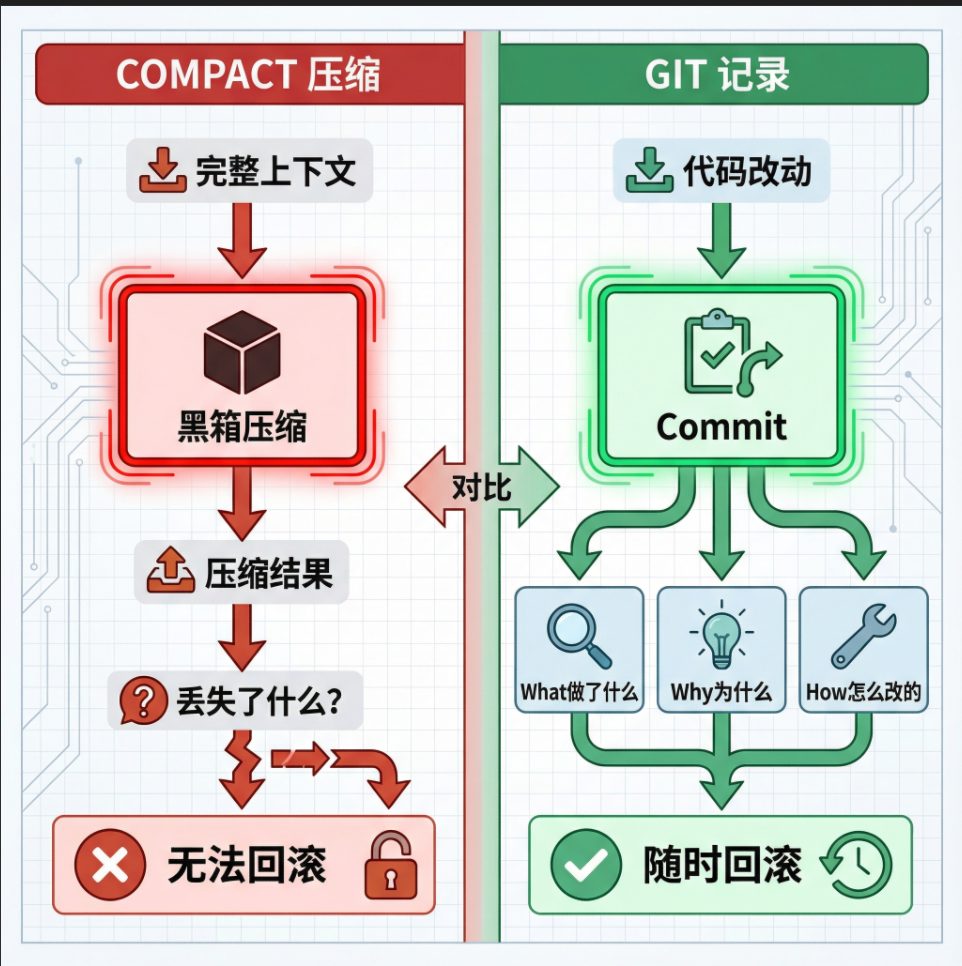
为什么 Git 比 Compact 更适合作为"记忆载体"?
| 维度 | Compact | Git |
|---|---|---|
| 透明度 | 黑箱压缩,不知道丢了什么 | 完全透明,所有历史可查 |
| 信息完整性 | 每次压缩都有损失 | 每次 commit 都完整保留 |
| 回滚能力 | 无法回滚 | git revert 轻松回到任意状态 |
| 协作支持 | 单代理使用 | 多代理/多人可共享 |
每一次 commit 都回答了三个关键问题:
- What:commit message 说明做了什么
- Why:可以在 message 中解释原因
- How:diff 显示了具体改动
3.2 进度日志:高效的交接班机制
claude-progress.txt 看似简单,却是"交接班"的关键。
它的定位:Git commit 的高层概览。
Git 历史虽然完整,但对于快速了解"最近在干什么"来说太详细了。进度日志是精简版的工作摘要,让新 Session 能在几秒内进入状态。
3.3 特性列表:任务拆解 + 进度可视化
feature_list.json 的设计运用了一个心理学技巧:
所有特性初始都是 failing 状态。
这强制代理承认"现在还没做完",避免过早宣告成功。这就像敏捷开发中的 Sprint Backlog——只有把所有 User Story 都标记为 Done,才能说这个 Sprint 完成了。
3.4 端到端测试:眼见为实
文章中提到了一个关键的失败模式:
Claude 倾向于不经过充分测试就标记特性为完成。
Anthropic 的解决方案是:让 Claude 像真实用户一样测试。
他们为 Claude 配备了 Puppeteer(浏览器自动化工具),让它真的去点按钮、输入文字、检查页面显示。
Puppeteer 端到端测试流程
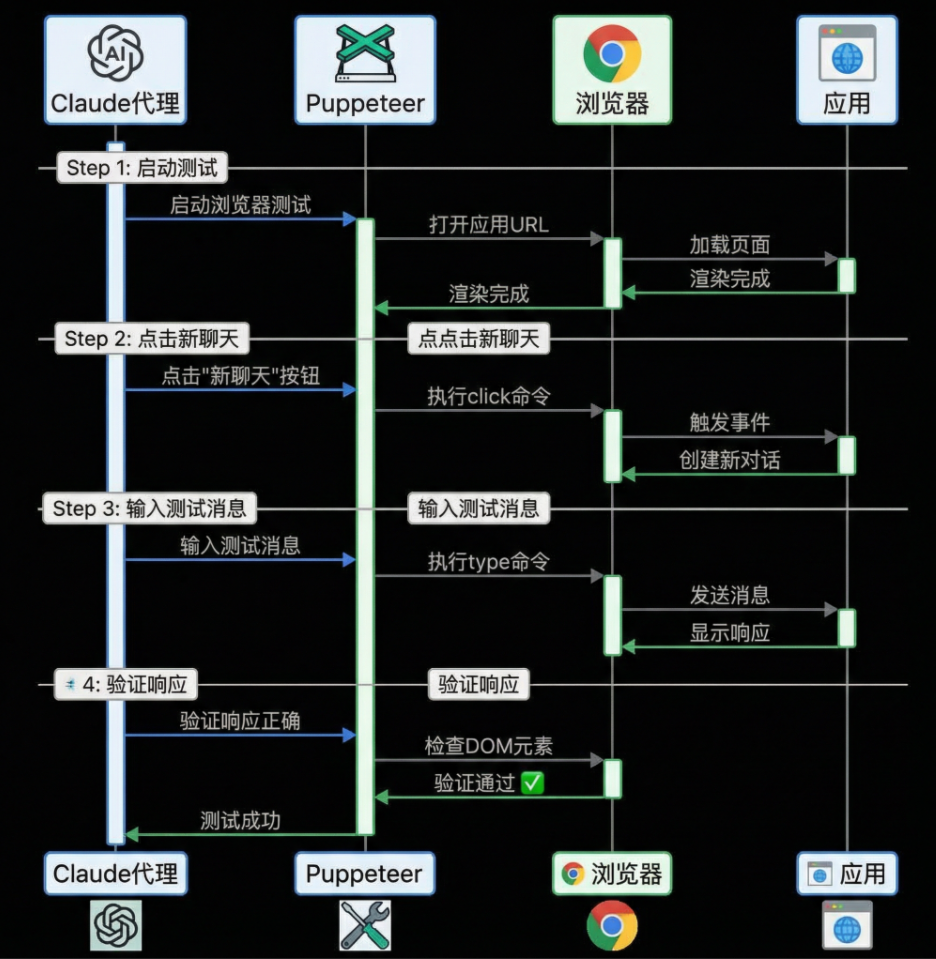
这比 curl 命令或单元测试可靠得多——代码层面看不出的问题,真实用户操作一下就暴露了。
第四部分:实战落地——用 Hooks 自动化整套流程
理论讲完了,怎么在 Claude Code 中落地?
核心工具:Claude Code Hooks 系统
4.1 SessionStart Hook:自动加载上下文
创建 .claude/hooks/session_start.sh:
#!/bin/bash
echo "=== 项目上下文自动加载 ==="
echo ""
# Git 分支信息
echo "## 当前分支"
git branch --show-current
echo ""
echo "## 最近 5 次提交"
git log --oneline -5
echo ""
echo "## 工作区状态"
git status --short
# 如果有特性列表
if [ -f "feature_list.json" ]; then
echo ""
echo "## 待完成功能(前 5 项)"
jq -r '.[] | select(.passes == false) | "- \(.description)"' feature_list.json | head -5
fi
# 如果有进度日志
if [ -f "claude-progress.txt" ]; then
echo ""
echo "## 最近工作进展"
tail -5 claude-progress.txt
fi
4.2 配置 settings.json
{
"hooks": {
"SessionStart": [
{
"hooks": [
{
"type": "command",
"command": ".claude/hooks/session_start.sh"
}
]
}
]
}
}
4.3 完整实践流程
完整实践流程
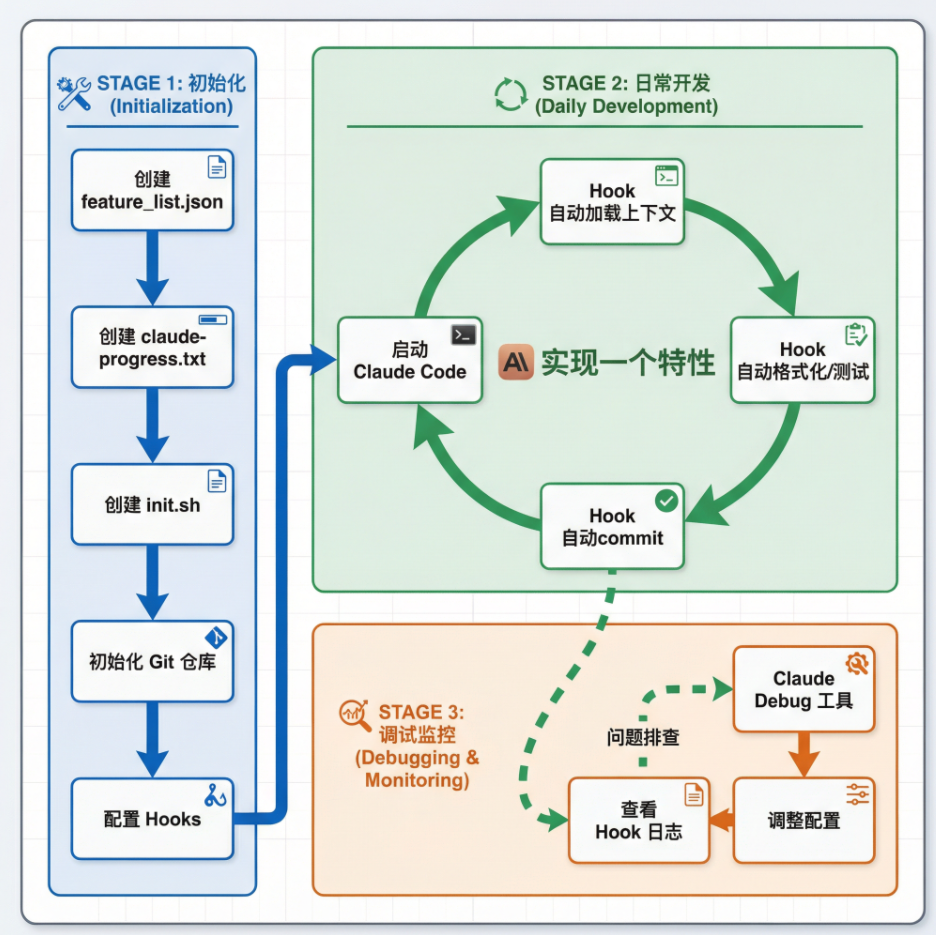
关键收益:
- 自动化 Anthropic 方案的每一步
- 节省 Token(上下文直接注入,无需 Claude 执行命令获取)
- 团队可共享配置(提交到 Git)
第五部分:深层思考——代理记忆与知识传承
5.1 显性知识 vs 隐性知识
人类团队的知识传承分为两类:
| 类型 | 定义 | 传承难度 |
|---|---|---|
| 显性知识 | 文档、代码、规范、流程 | 容易,写下来即可 |
| 隐性知识 | 设计原因、权衡取舍、踩过的坑 | 困难,需要潜移默化 |
AI 代理没有"潜移默化"的能力——它只能依靠显性知识。
这就是为什么 Anthropic 的方案强调:
- 用 JSON 而非 Markdown(结构更严格)
- 用 Git commit(格式固定)
- 用进度日志(简单明了)
- 用启动脚本代替"怎么启动项目"的知识
- 用测试脚本代替"怎么验证功能"的知识
本质上,是把原本需要人脑记住的隐性知识,全部外化为文件和脚本。
5.2 结构化知识传递的核心原则
结构化知识传递金字塔
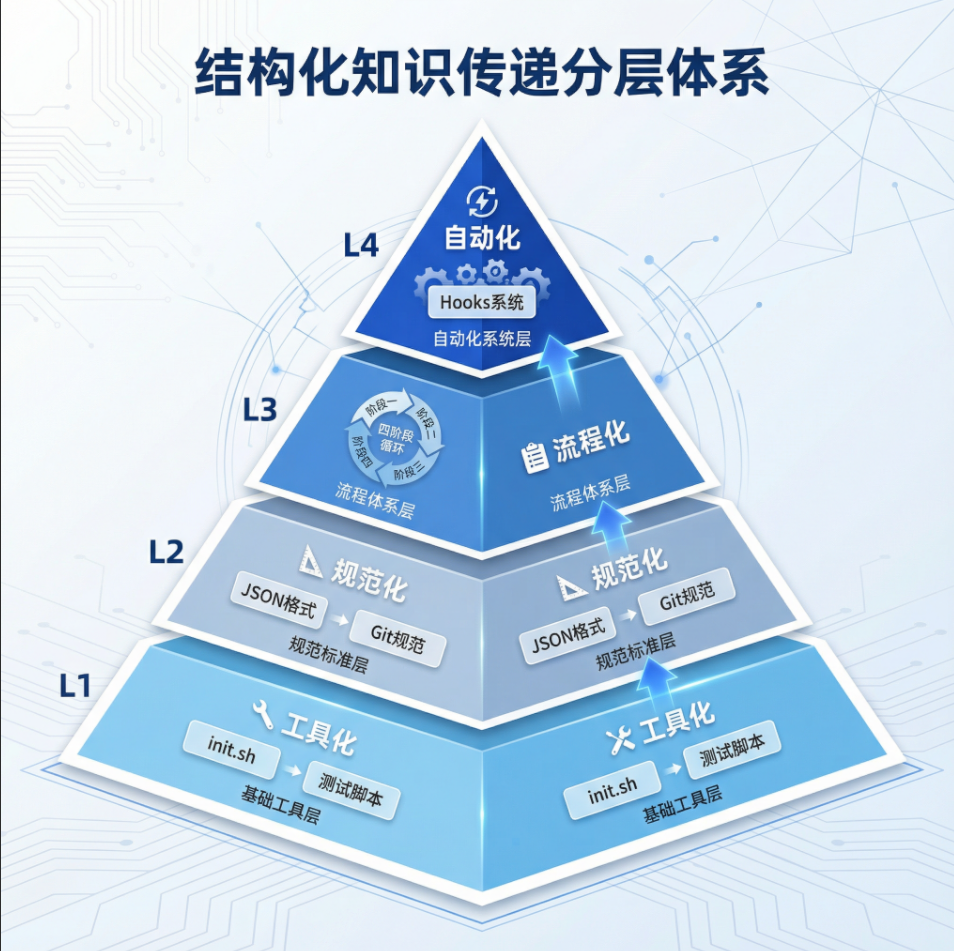
Anthropic 方案遵循的核心原则:
- 强制规范化:用结构严格的格式,减少"顺手改坏"的可能
- 减少传递负担:每次只做一件事,降低单次传递的信息量
- 用工具代替经验:把"怎么做"固化成脚本
- 流程大于智能:代理不需要"理解"项目,只需要"执行"流程
第六部分:给你的五条实操建议
即使你不开发 AI 代理系统,这些原则也广泛适用:
建议 1:做好交接文档
参考 Anthropic 的四件套:
- 进度日志:简短、高层、易读
- 详细历史:Git commit,有据可查
- 任务清单:feature_list,一目了然
- 启动指南:init.sh,一键运行
建议 2:增量式推进
不要一口吃个胖子。每次只做一件事,做完再做下一件。
好处:
- 容易测试
- 容易回滚
- 容易跟踪进度
- 出问题好定位
建议 3:端到端测试
别只看代码,要真的跑起来测。
单元测试有用,但不够。集成测试也有用,但还不够。最可靠的是端到端测试——像用户一样操作。
建议 4:结构化优于自由
能用 JSON 就别用 Markdown,能用固定格式就别用自由文本。
结构化的东西不容易被意外改掉——JSON 改错了会报错,Markdown 改错了可能毫无察觉。
建议 5:流程大于智能
对于重复性任务,好的流程比聪明的执行者更可靠。
AI 代理需要的不是"聪明",而是清晰的流程:
- 做什么
- 怎么做
- 怎么验证
- 怎么记录
结语:工程问题需要工程解决
回到开头的问题:为什么 Compact 越来越频繁,效果越来越差?
因为 Compact 不是长期运行代理的正解,它只是权宜之计,治标不治本。
真正的解决方案是:
| 错误认知 | 正确做法 |
|---|---|
| 指望代理"记住"一切 | 用外部文件存储状态 |
| 让代理一次做完 | 每次只做一件事 |
| 让代理猜测意图 | 所有信息都显性化 |
| 相信没测试的代码 | 真的跑起来测 |
Anthropic 方案的精妙之处在于:没有发明新轮子,而是巧妙运用了软件工程领域几十年积累的最佳实践。
Git、测试、日志、SOP——这些经过时间检验的方法,对人类有用,对 AI 代理同样有用。
因为归根结底,软件工程的本质问题——复杂度管理、知识传承、质量保证——不会因为执行者从人类变成 AI 就消失。
参考资料
-
Effective harnesses for long-running agents - Anthropic 官方博客
-
Claude Agent SDK - Claude 代理 SDK 文档
-
Claude 4 Prompting Guide - 多上下文窗口工作流最佳实践
如果你在用 Claude Code 做长期任务时也遇到了 Compact 困境,强烈建议试试这套方案。一次配置好,后面能省无数时间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)