OpenVINO助力端侧AI应用快速实现
本文介绍了利用OpenVINO框架在英特尔AI-PC上开发的端侧AI开放文字游戏“赫奇帕奇的回响”。该游戏基于《哈利波特》世界观,通过通义千问8B量化模型作为游戏引擎,实现开放式情节生成。系统采用Gradio构建界面,并整合Z-Image-Turbo模型实现情节插图生成。实践表明,在Intel Ultra 9285H处理器上,OpenVINO能有效加速8B模型的推理,提供流畅的游戏体验。文章详细介
端侧AI是直接在终端设备上运行的人工智能模型,可理解为“本地化”、“离线化”的AI。与云侧AI相比,端侧AI的计算资源和存储能力有限,但在隐私保护、可靠性、低时延上有优势,特别是与端侧硬件设备结合为端侧AI的应用提供了无限的可能。
近期我参加了魔搭社区主办的“端侧AI创新挑战赛”,利用openvino在英特尔AI-PC上完成了一个试验作品——赫奇帕奇的回响,一个以小说《哈利波特与魔法石》为背景的开放式文字游戏。在游戏中,用户扮演一名虚构出的霍格沃茨魔法学校的一年级新生——芬恩·麦克米伦,通过与程序对话来推动情节,展开冒险历程。
在具体实现时,我通过程序用提示词控制通义千问大模型(qwen3)扮演一个文字游戏引擎,输入了第一个游戏场景,后面的情节和发展都交由大模型根据游戏规则设定和用户的选择自主生成。此外还设计了根据游戏过程对话历史整理成小说(qwen3 think模式)和根据对话情节描述生成插图(Z-Image-Turbo)的功能。
运行环境及部署
- 硬件环境:极摩客EVO-T1 【EVO-T1_Ultra 9 285H_64GB_1TB】
其中:CPU: Intel UItra9 285H
GPU: Intel Arc 140T核显
- 选用模型:
通义千问3的8B量化模型 【OpenVINO/Qwen3-8B-int4-ov 】
造相Z-Image-Turbo【Tongyi-MAI/Z-Image-Turbo】
(说明:在实际开发中,尝试过通义千问0.6B、1.7B等模型。在本次作品的需求下,0.6B不能用,1.7B勉强能用,但生成的文字文笔差,偶尔陷入think死循环。8B模型下程序能出较好的成果,配合关闭千问3原有的思维链在极摩客EVO-T1的Intel UItra9 285H上借助OpenVINO加速,生成的速度非常好,已经能够带给用户流畅的游戏体验了。)
- 部署工具: OpenVINO 2025.4.0.dev20251010
- 软件环境:
Python3: 3.13.7
OpenVINO: 2025.4.0.dev20251010
openvino-genai:2025.4.0.0.dev20251010
modelScope: 1.30.0
gradio: 5.49.1
- 环境配置关键步骤:
安装软件包:
pip install openvino==2025.4
pip install openvino-genai
pip install modelScope
pip install gradio
pip install git+https://github.com/huggingface/diffusers
pip install git+https://github.com/openvino-dev-samples/optimum-intel.git@zimage
pip install nncf
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cpu注意:5-8项的安装运行Z-Image-Turbo模型所需要的,其中第5项diffusers版本必须是0.36.0.dev0,否则Z-Image-Turbo无法正常运行。
从魔搭社区下载模型:
modelscope download --model OpenVINO/Qwen3-8B-int4-ov --local_dir ./model_dir
modelscope download --model Tongyi-MAI/Z-Image-Turbo --local_dir Z-Image-Turbo转换Z-Image-Turbo模型到openvino支持格式:
optimum-cli export openvino --model Z-Image-Turbo --task text-to-image Z-Image-Turbo-ov --weight-format int4 --group-size 64 --ratio 1.0执行完后,Z-Image-Turbo-ov目录中就是转换后可以用openvino启动的量化模型了。
应用实现
使用OpenVINO进行端侧AI应用开发的优势很多。首先OpenVINO的使用也很方便,两三行代码就可以调用模型进行推理,通过参数device的值(CPU、GPU或者NPU)设置,可以方便选择模型运行设备,在不同的平台上保持代码的一致性。其次作为Intel公司推出的软件,它的文档资料规范详实,可以减少自行摸索的时间。此外,它还提供了各种应用场景的例程,对新手来说,跑通例程并在例程基础上修改,可以快速实现应用。
通过如下命令,下载OpenVINO GenAI 的源代码:
git clone https://github.com/openvinotoolkit/openvino.genai.git
在openvino.genai\samples目录下可找到官方提供的很多例程,包括了典型的文本推理、语音生成、文生图等类型;各目录中均包含了详尽的README文档。
本次参赛时,利用OpenVINO的跨平台特性,在获得Intel AI-PC设备前,已经通过异构平台的CPU模式测通了代码、跑起了模型、解决了技术堵点,为最终项目快速实现争取了时间。
此次前端采用Gradio的Blocks自定义用户界面,后端用OpenVINO驱动Qwen3等模型,前期遇到的最大问题是在流式输出时两者的匹配问题,后来设法解决了,关键代码如下:
streaming_output = ""
def streamer(subword):
# 流式输出生成的文本,每次输出一个子词单位
global streaming_output
print(subword, end='', flush=True)
streaming_output += subword
return openvino_genai.StreamingStatus.RUNNING
def predict(input,history, output,max_new_tokens=40000,**kwargs,):
global streaming_output,chat_started,chat_history
# 检查聊天会话是否已开始
if not chat_started:
out_txt="请先点击'开始游戏'按钮开始冒险旅程~~"
return out_txt
now_input = '游戏开始 /no_think' if len(chat_history)==0 else input
out_txt = ""
streaming_output=""
chat_history.append((now_input, ""))
# 使用线程并行执行
# import threading
generation_complete = threading.Event()
def generate_wrapper():
pipe.generate(now_input, generation_config=config, streamer=streamer)
generation_complete.set()
# 启动生成线程
generation_thread = threading.Thread(target=generate_wrapper)
generation_thread.start()
# 流式返回结果
while not generation_complete.is_set() :
if streaming_output:
out_txt = re.sub(r'<think>.*?</think>', '', streaming_output, flags=re.DOTALL).lstrip()
time.sleep(0.05)
yield out_txt
generation_complete.wait(0.1) # 短暂等待,避免过度占用CPU
# 提取生成的回复部分
chat_history[-1]=(now_input, re.sub(r'<think>.*?</think>', '', streaming_output, flags=re.DOTALL).lstrip())
out_txt = re.sub(r'<think>.*?</think>', '', streaming_output, flags=re.DOTALL).lstrip() +'\n--------------------------------------\n\n'
yield out_txt与ollama、LM Studio等部署方式相比,OpenVINO更适合在应用代码中直接直接调用,执行完相应功能后就释放占用资源,对于端侧内存、运算能力受限的场景有它的优势。
试验成果
游戏界面
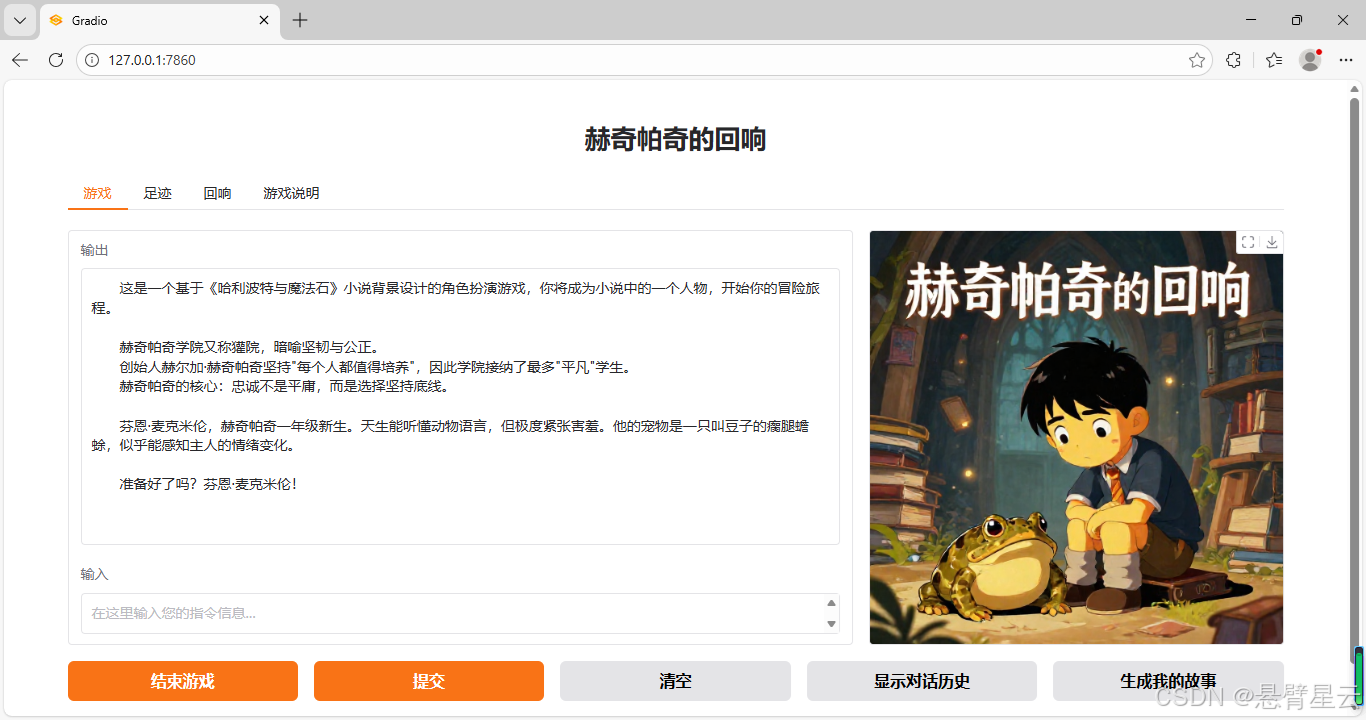
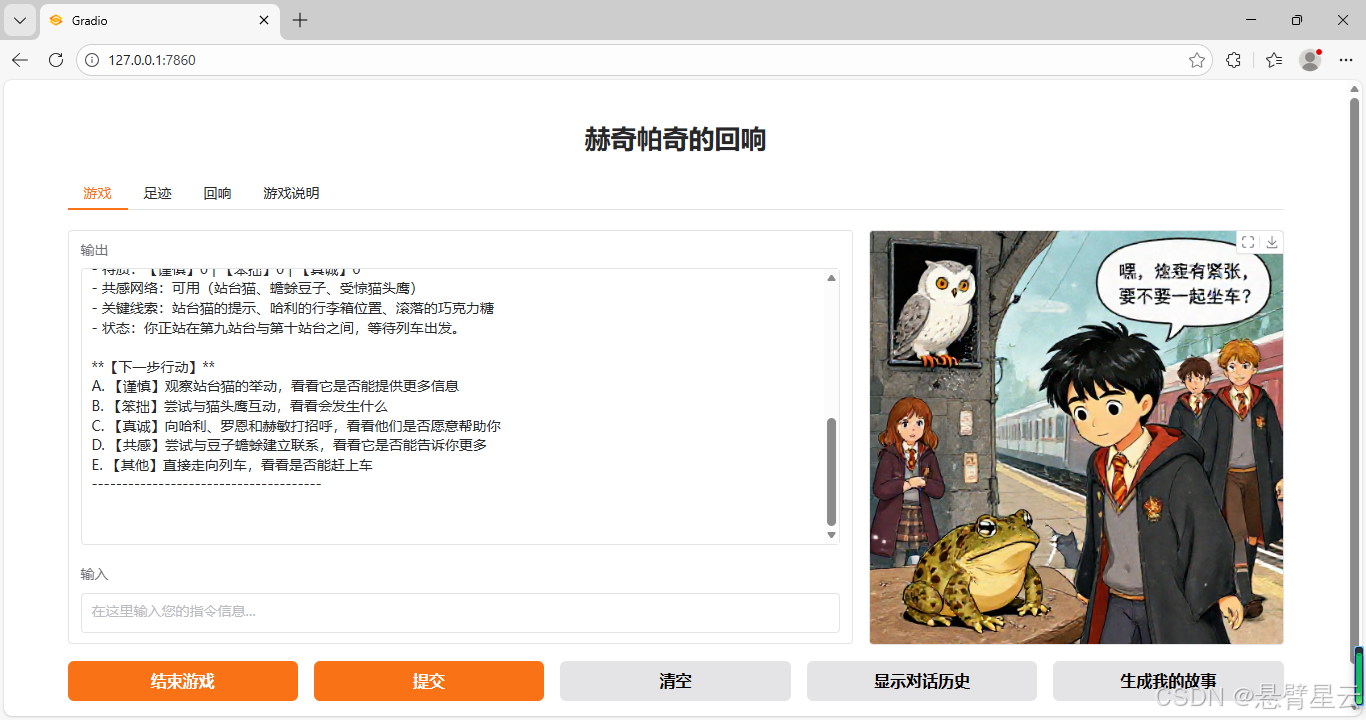
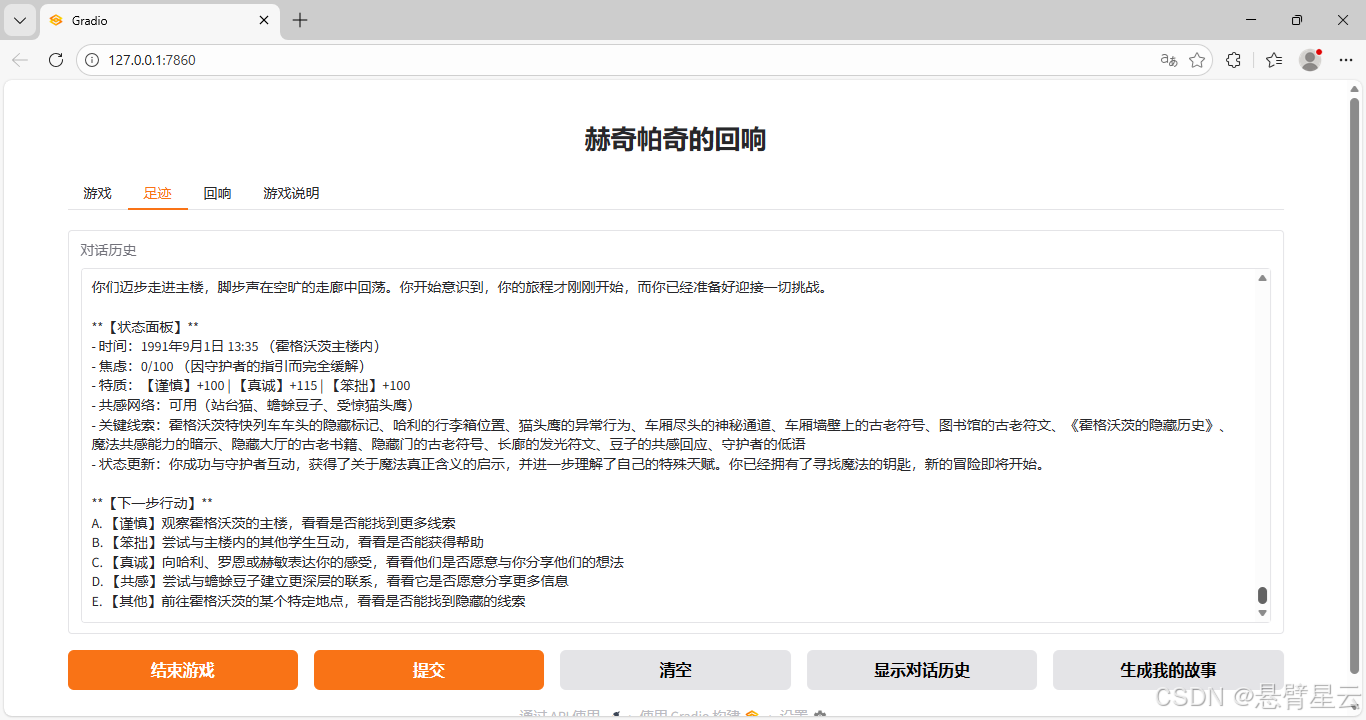
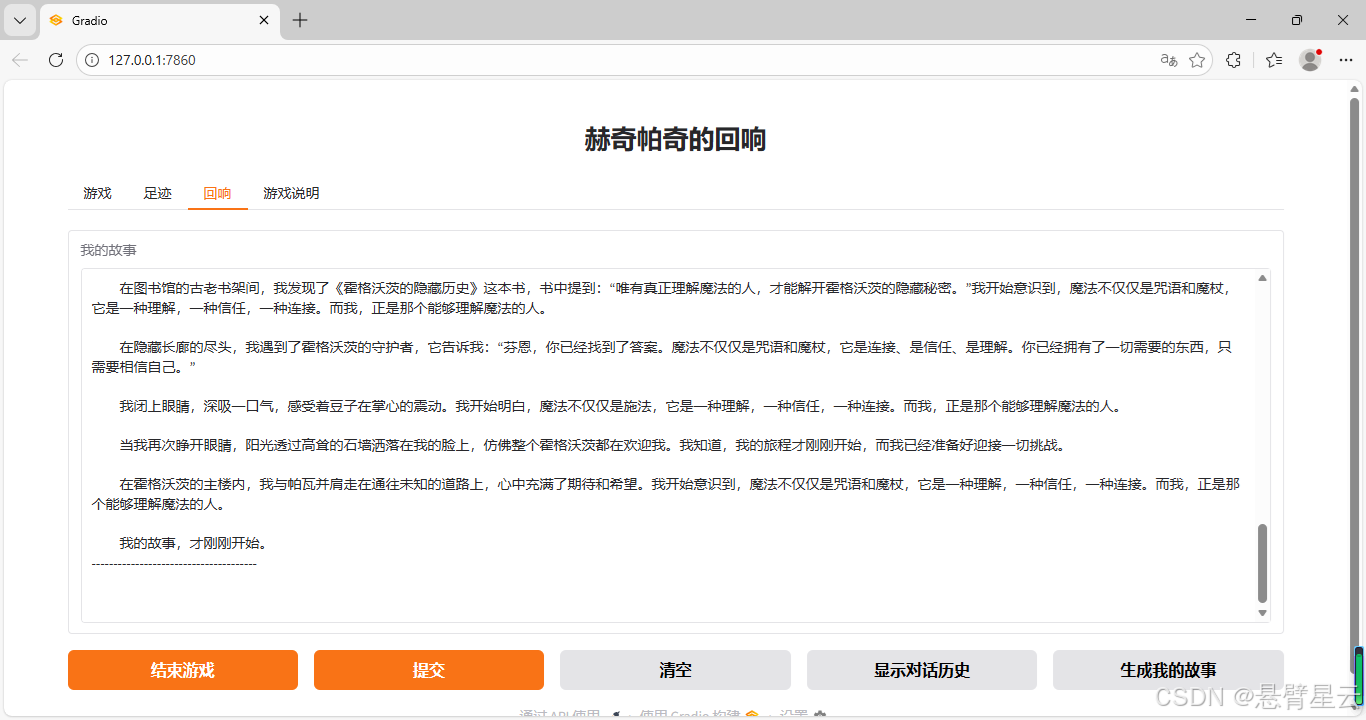
此次开放游戏试验,借助OpenVINO开源AI推理框架,快速实现了模型部署运行,让我可以将主要精力放在提示词设计及功能实现上,成功实现了试验目标:
1)设定了游戏规则、人物设定等和开场第一个回复的内容,其他都由大模型自己生成;
2)可以将游戏带入大模型已知的小说内;
3)将游戏过程整理成小说。
最后借助最新推出的通义造相Z-Image-Turbo的急速生图能力,增加了对话过程中生成剧情插图功能。在OpenVINO的支持下,同步生成剧情插图只造成内容生成过程中几秒生成速度变慢的影响。
参考资料:
1. OpenVINO™加速工具,让你的AI PC更流畅跑Qwen大模型 https://www.modelscope.cn/learn/2034
2. OpenVINO开始 https://www.intel.cn/content/www/cn/zh/developer/tools/openvino-toolkit/get-started.html
3. OpenVINO在线文档 https://docs.openvino.ai/2025/index.html
4. 造相Z-Image-Turbo介绍 https://modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo
5. OpenVINO™部署通义Z-Image(造相 https://mp.weixin.qq.com/s?__biz=Mzk4ODc5NzA2Mg==&mid=2247532919&idx=1&sn=7c59b80e0783a917709bf4eddc3aa431

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)