对Tesla V100的理论性能测评和与5060Ti的对比
NVIDIA Tesla V100 SXM2 16G评测摘要 Tesla V100作为2017年发布的Volta架构计算卡,曾凭借640个Tensor Core和815mm²大核心在AI计算领域占据重要地位。测试显示其FP64性能达6.93TFLOPS,FP16性能高达105TFLOPS,显存带宽900GB/s。但与新一代RTX 5060Ti对比发现:V100在FP64保持20倍优势,但新卡在BF
首先先简要介绍一下今天的主角:
NVIDIA Tesla V100 SXM2 16G
此GPU发布于2017年,基于Volta架构,CUDA GPU Compute Capability 7.0,针对数据中心环境设计。Tesla V100 是英伟达公司首款针对深度学习设计的GPU,引入了第一代Tensor Core,拥有极高的FP16半精度浮点算力,并保留了完整的FP64双精度计算能力,使用HBM2显存,核心面积达到了惊人的815平方毫米。
Tesla V100家族的datasheet如下:
| 型号 | V100 PCle | V100 SXM2 | V100S PCle |
| 架构 | NVIDIA Volta | NVIDIA Volta | NVIDIA Volta |
| Tensor 核心数量 |
640 | 640 | 640 |
| CUDA® 核心数量 |
5120 | 5120 | 5120 |
| 双精度浮点运算性能(FP64) | 7 TFLOPS | 7.8 TFLOPS | 8.2 TFLOPS |
| 单精度浮点运算性能(FP32) | 14 TFLOPS | 15.7 TFLOPS | 16.4 TFLOPS |
| Tensor 性能(FP16稠密) | 112 TFLOPS | 125 TFLOPS | 130 TFLOPS |
| GPU 显存 | 32 GB 或 16 GB HBM2 | 32 GB 或 16 GB HBM2 | 32 GB HBM2 |
| 显存带宽 | 900 GB/s | 900 GB/s | 1134 GB/s |
| 互联带宽 | 32 GB/s | 300 GB/s | 32 GB/s |
| 系统接口 | PCIe 3.0 | NVIDIA NVLink™ | PCIe 3.0 |
| 外形尺寸 | PCIe 全高 / 全长 | SXM2 | PCIe 全高 / 全长 |
| 最大功耗 | 250 瓦 | 300 瓦 | 250 瓦 |
| 散热解决方案 | 被动式 | 被动式 | 被动式 |
目前在二手市场上较为常见的是V100 PCle和V100 SXM2,在大船靠岸之前,主要还是以V100 PCIe为主,且价格都不大友好。
但是随着人工智能技术的发展,近年来各类新算子在不断推广应用,目前许多模型也逐渐转向更低的计算精度,对于这个CUDA计算能力7.0、只有FP16性能占优的老将而言,已经跟不上时代了。自2024年起,许多V100计算卡从世界各地的机房中拆下,其中或许很大一部分,流入了中国的二手市场。2025年,英伟达公司宣布停止对Volta架构GPU提供CUDA支持,这进一步推动了V100显卡的换代更新。截至2025年12月,NVIDIA Tesla V100 SXM2 16G在闲鱼上可以以400元不到的价格购入,如果使用廉价转接卡和水冷散热器,可以将成本压缩到500多元。
笔者本次评测的对象是:NVIDIA Tesla V100 SXM2 16G,使用第三方SXM2转PCIe 3.0 转接板,涡轮风冷散热,供电满足300W最大功耗,不支持NVLink™。

笔者将这块显卡部署于Dell PowerEdge 第 13 代服务器 R730xd 的RISER2上,使用戴尔RISER卡8PIN转PCIE双8PIN电源线供电。
*这块成品卡的默认风扇策略已经可以满足测试和使用。
这张涡轮成品卡的风扇使用内置单片机调速,温度探头安装在散热鳍片上,内置单片机能在GPU肩部的数码管上显示当前的温度读数,并根据设置的风扇转速策略进行自动调速(可通过涡轮风扇上的三个按钮调节)。
笔者的测试环境配置如下:
| 平台 | Dell PowerEdge 13G R730xd |
| CPU | Intel Xeon 2682V4 x2 |
| 内存 | 三星 DDR4 4Rx4 32G 2133MHz x2 |
| 硬盘 | 雷克沙 SATA SSD 512G |
| 系统 | Ubuntu-live-server-24.04 |
| GPU驱动版本 | 580.105.08 |
| CUDA版本 | 12.8 |
| 虚拟化配置 | 32线程+16G内存+200G SATA SSD |
测试程序:CUDABurner (https://github.com/stlin256/CUDABurner)
CUDABurner支持多种精度下的GPU计算性能测试,区分有无tensor core加入、稠密/稀疏计算等,支持对降频情况进行标注,兼容Pascal架构到Blackwell架构的NVIDIA GPU;CUDABurner还支持对GPU进行压力测试。 使用CUDABurner对NVIDIA Tesla V100 SXM2 16G进行性能测试
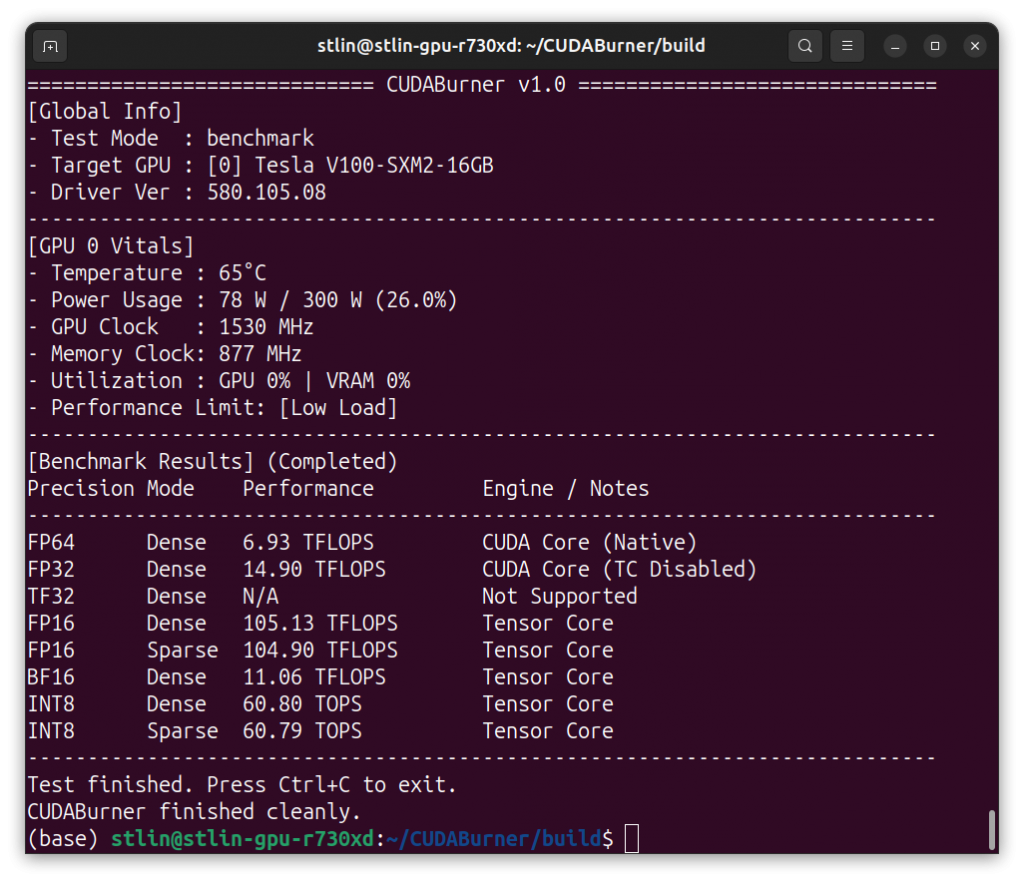
运行CUDABurner后,我们得到了测试结果:
| 精度 | 稠密/稀疏 | 性能 | 备注 |
| FP64双精度 | 稠密 | 6.93 TFLOPS | |
| FP32单精度 | 稠密 | 14.90 TFLOPS | |
| TF32* | 稠密 | N/A | 不支持 |
| FP16半精度 | 稠密 | 105.13 TFLOPS | |
| FP16半精度 | 稀疏 | 104.90 TFLOPS | |
| BF16* | 稠密 | 11.06 TFLOPS | 使用FP32模拟 |
| INT8 | 稠密 | 60.8 TOPS | |
| INT8 | 稀疏 | 60.79 TOPS |
*Ampere或更新架构才具备TF32精度和BF16精度的原生支持
我们可以从结果中看到,Tesla V100的FP64双精度浮点性能十分强劲,速度约为FP32单精度的一半,而FP16的性能在大规模的Tensor Core加持下,速度来到了惊人的105TFLOPS。尽管Tesla V100原生支持INT8精度,但是速度没有FP16那样惊艳。
从结果中我们可以观察到,Tesla V100 并不能利用稀疏运算进行加速,其FP16和INT8的稀疏运算性能和稠密性能别无二致,这在运行最新的一些具备稀疏化*的模型上是不占优势的。
*什么是稀疏化
简单来说,稀疏化就是将模型权重矩阵中不重要的数值“修剪”为 0。在理论上,计算
X * 0是没有意义的,因此如果我们能跳过这些零值的计算,就能大幅减少计算量并降低显存占用。现代 AI 硬件引入了结构化稀疏(Structured Sparsity)技术,专门设计了电路来自动忽略这些零值,从而实现性能翻倍。
我们也可以注意到,Tesla V100 并不能原生支持TF32和BF16精度,不过可以使用FP32对BF16进行模拟*,但是这就无法利用Tensor Core加速,同时会带来两倍显存占用。随着近年来BF16成为大模型训练的主流格式,这一缺陷导致包括Tesla V100 在内的所有Volta架构GPU相对Ampere、Ada、Hopper、Blackwell等新架构最大的短板。
*为什么不能把BF16直接转换为FP16来进行计算?
BF16 目前已成为大模型训练的主流格式,因为它保留了与 FP32 相同的动态范围,保证了数值稳定性。我们不能简单地将 BF16 强转为 FP16,因为 FP16 的数值范围极窄(最大仅 65504),一旦模型中的权重或激活值超出此范围,强制转换就会引发数值溢出(NaN),直接导致计算崩溃。
我们可以发现,这张Tesla V100尽管功力雄厚,但是在一些现代AI所需的特性上却处处碰壁。下面,我将引入基于英伟达最新的Blackwell架构的消费级入门GPU 进行对比:
NVIDIA GeForce RTX 5060 Ti 16G
| 型号 | RTX 5060 Ti 16G |
| 架构 | Blackwell |
| Tensor 核心数量 |
144 |
| CUDA® 核心数量 |
4608 |
| GPU 显存 | 16GB GDDR7 |
| 显存带宽 | 448 GB/s |
| 系统接口 | PCIe 5.0 x8 |
| 最大功耗 | 180 瓦 |
NVIDIA GeForce RTX 5060 Ti 16G 作为最新一代架构的显卡,坐拥第5代Tensor Core,支持各类最新特性。
我们同样使用CUDABurner进行测试,测试平台如下
| 平台 | ASUS TUF B450M PRO S |
| CPU | AMD Ryzen 5700X |
| 内存 | 威刚 XPG Z1 DDR4 3000Mhz 8G x4 |
| 硬盘 | 西部数据 SN560 1T nvme |
| 系统 | Ubuntu-Desktop-24.04 tty模式 |
| GPU驱动版本 | 580.95.05 |
| CUDA版本 | 13.1 |
将测试结果与NVIDIA Tesla V100 SXM2 16G 进行对比,结果如下:
| 精度 | 稠密/稀疏 | V100性能 | 5060 Ti 性能 |
| FP64双精度 | 稠密 | 6.93 TFLOPS | 0.33 TFLOPS |
| FP32单精度 | 稠密 | 14.90 TFLOPS | 17.27 TFLOPS |
| TF32 | 稠密 | N/A | 24.45 TFLOPS |
| FP16半精度 | 稠密 | 105.13 TFLOPS | 49.76 TFLOPS |
| FP16半精度 | 稀疏 | 104.90 TFLOPS | 97.65 TFLOPS |
| BF16 | 稠密 | 11.06 TFLOPS | 49.79 TFLOPS |
| INT8 | 稠密 | 60.8 TOPS | 52.24 TOPS |
| INT8 | 稀疏 | 60.79 TOPS | 377.09 TOPS |
从测试结果来看,二者在不同精度下展现出了明显的“错位竞争”态势,可谓互有胜负。
在FP64双精度领域,Tesla V100 展现了统治级的实力,其性能是 RTX 5060 Ti 的 20 倍以上。对于涉及高精度数值模拟的科学计算需求而言,这种未被阉割的 FP64 算力正是计算卡与消费级显卡之间不可逾越的护城河。
在深度学习常用的 FP32 和 FP16 精度上,战况则较为复杂。虽然 V100 在标准的 FP32 单精度上略逊一筹,但得益于其高达 640 个 Tensor Core 的暴力堆料,在稠密 FP16 计算下,其性能达到了 RTX 5060 Ti 的两倍。这使得 V100 在运行未针对稀疏化优化的老模型时,依然保有显著优势。更关键的是,V100 拥有两倍于 5060 Ti 的显存带宽,这在运行 GGUF 格式的大语言模型推理时不仅不慢,反而速度能达到 5060 Ti 的两倍(这一点将在后续实测文章中详细验证)。
然而,架构的代差在现代特性上暴露无遗。虽然 RTX 5060 Ti 的稠密算力较弱,但凭借对FP16 稀疏计算的优化,其性能已能逼近 V100,若考虑到功耗比,V100 毫无优势。而在更新的BF16精度上,RTX 5060 Ti 更是凭借架构红利实现了对 V100 的 4.5 倍性能碾压,导致 V100 在现代 AI 模型的训练和微调任务中已显得力不从心。
最后在 INT8 量化方面,虽然两者的稠密算力旗鼓相当,但 RTX 5060 Ti 开启稀疏化后,其 INT8 吞吐量暴增至 V100 的六倍以上。这意味着在追求极致效率的量化推理任务中,新架构显卡在能效比和绝对性能上都彻底终结了这位老前辈。
不仅如此,Blackwell 架构还带来了对 NF4精度的原生支持。NF4是目前 QLoRA 低成本微调和超大参数模型推理的“黄金格式”。在 Tesla V100 上,NF4 仅仅只能作为一种节省显存的“压缩存储手段”,计算时必须消耗算力将其反量化为 FP16/FP32;而 RTX 5060 Ti 配合最新的架构特性,能够极高效地处理这些低比特数据。这意味着在同样的 16GB 显存限制下,5060 Ti 不仅能“装下”参数量更大的模型,更能以 V100 难以企及的效率进行推理和微调,进一步拉大了二者在实际应用落地层面的差距。
小结
毫无疑问,Tesla V100 的纯算力在其价位段处于绝对的 T0 水准。 即便使用和GPU几乎一样的涡轮散热方案成本,其性价比依然无可撼动。
但“性价比高”是否等同于“好用”?答案恐怕是否定的。
面对 300W 的高功耗、现代特性的全面缺失(羸弱的 BF16 性能、缺乏原生 Flash Attention 加速)、刺耳的电感啸叫,以及 Windows 端繁琐的驱动配置和架构生命周期的终结……这一系列门槛足以劝退绝大多数人。
这张GPU并不适合追求“即插即用”的普通用户,而更适合成为预算有限的学生党、热衷折腾的垃圾佬的廉价算力来源。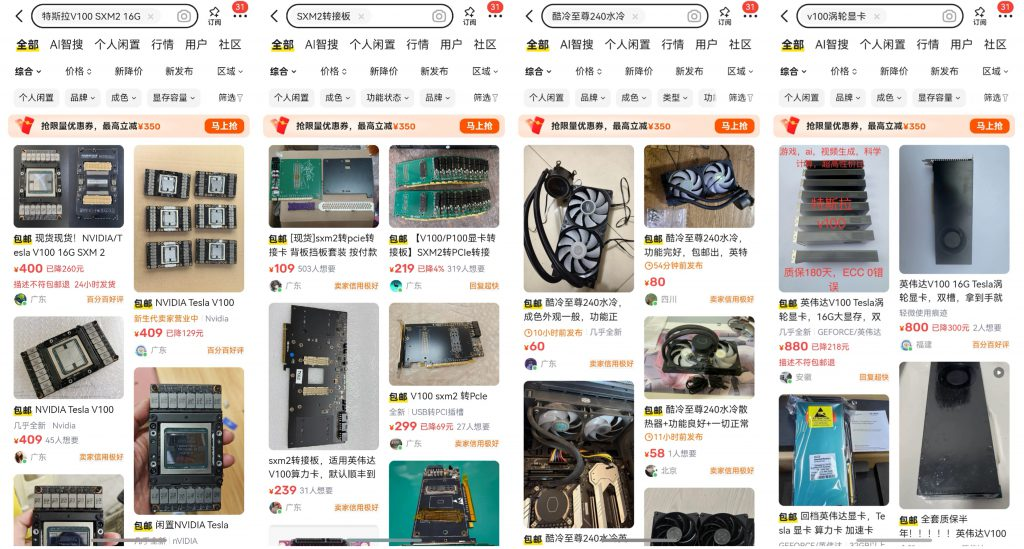

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)