英伟达NVL576正交架构解析&国内正交架构超节点差异对比
英伟达最新发布的NVL576正交架构采用革命性设计,通过中置背板实现计算节点与交换节点的正交互联,相比前代NVL72显著提升了系统可靠性和可维护性。该架构单机柜推理算力达15EFLOPS,配备4.6PB/s带宽的HBM4e显存,NVLink互连带宽达1.5PB/s。与国内海光scaleX640、阿里磐久AL128相比,NVL576在互联拓扑复杂度上更为激进,保留了关键的中置背板设计。正交架构正成为
转自微信号:牛逼的IT
英伟达最新发布的NVL576正交架构,不仅标志着其在超大规模节点设计上的一次重大革新,也引发了与国内如海光、阿里等同类架构的对比讨论。本文将深入剖析NVL576的技术特点、设计突破,并与海光scaleX640、阿里磐久AL128进行差异对比。
一、NVL576:正交架构的颠覆性创新
英伟达NVL576相较于前代NVL72,在架构上实现了根本性的变革。其最显著的特点是彻底摒弃了高故障率且难以维护的Cable tray(线缆托盘),转而采用可靠性与可维护性更优的正交架构。
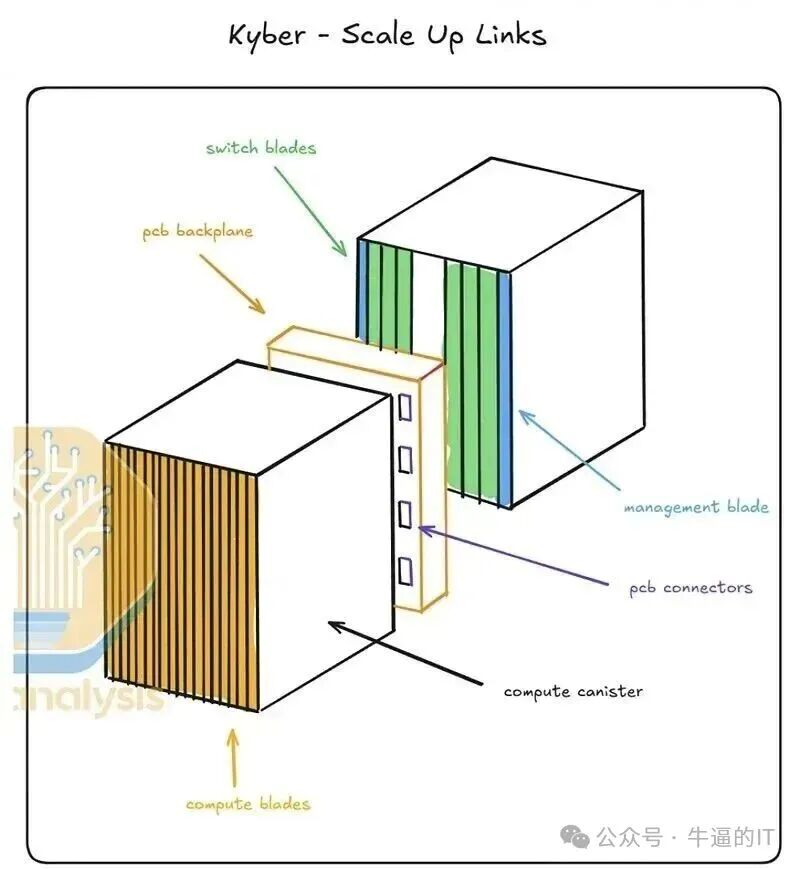
具体来看,NVL72的计算节点和交换节点均横向放置,通过机柜后方的复杂线缆互联。这种设计在实际部署中容易因线缆松动、损坏导致故障率升高,且维护时需要大量人工操作。而NVL576则将交换节点横向布置在机柜后部,计算节点则纵向排列在机柜前部,两者通过一块高度集成的中置背板(Midplane)相连,极大提升了系统的稳定性与可服务性。
从性能指标来看,NVL576基于Rubin Ultra平台,计划在2027年下半年推出。其单机柜推理算力(FP4)高达15 EFLOPS,训练算力(FP8)达5 EFLOPS,分别为GB300 NVL72的14倍。内存系统同样惊人,配备4.6 PB/s带宽的HBM4e显存和365 TB快速内存,NVLink互连带宽达到1.5 PB/s,CX9互联带宽为115.2 TB/s。

在物理布局上,NVL576机柜前部分为4个区域,每个区域包含18个计算节点。每个计算节点集成2颗Rubin Ultra GPU和2颗Vera CPU。这里需要特别说明的是命名规则:NVL576中的“576”并非指GPU数量,而是GPU芯片die的总数。每个Rubin Ultra GPU内部包含4个GPU Die,因此总Die数量为4区域×18节点×2 GPU×4 Die = 576个,这也是其名称的由来。
二、NVL576与NVL72互联方式对比
NVL72的互联方式相对传统,计算节点与交换节点均水平放置,通过机柜后部的线缆连接。这种设计虽然直观,但在大规模部署中暴露出诸多问题:线缆数量庞大、布线复杂、故障定位耗时、维护需要大量人工干预。
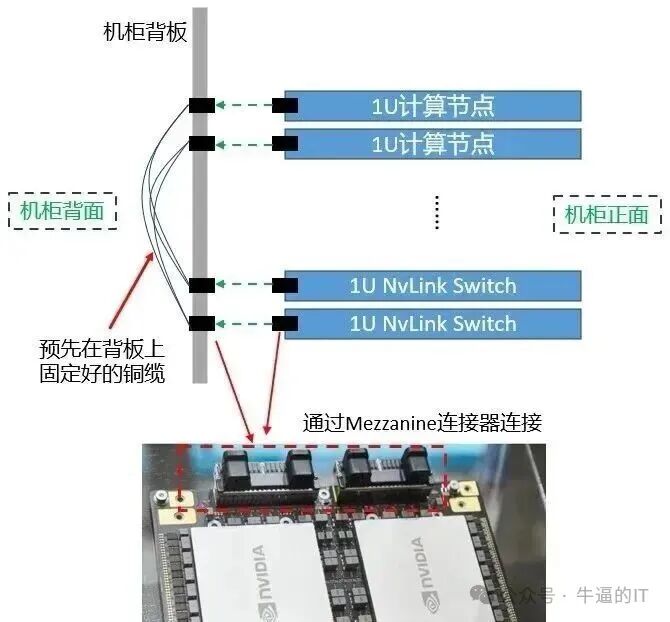
而NVL576的正交架构则彻底改变了这一局面。计算节点纵向排列,交换节点横向置于机柜后部,两者通过中置背板连接。这种设计通过Mezzanine连接器实现预先在背板上固定的铜缆互联,既减少了物理线缆的使用,又提高了信号完整性。
中置背板作为NVL576架构的关键创新,解决了数万根铜缆互联的制造与维护难题。每个计算节点有4个NVLink外部端口,每个端口带宽达3.6 TB/s,对应约72对差分线。单块背板上的差分线对总数至少为18节点×4端口×72对 = 5,184对。这种高密度互联要求背板设计达到极高标准。
三、NVL576中置背板的技术突破
英伟达为中置背板引入了多项先进材料和工艺,以应对信号完整性、工艺制造和布局布线方面的挑战。这块背板的技术规格堪称业界顶尖:
-
采用M9高性能板材,板层数达78层
-
使用三块26层以上PCB压合而成
-
线宽线距≤25μm,远低于传统PCB的50μm标准
-
介电常数(Dk)<3.0,热膨胀系数(CTE)<12ppm/℃
为实现这一设计,英伟达引入了多项特殊工艺:
-
7阶HDI工艺:实现更高密度的互联和更小的孔径
-
增强型填料:通过增加球形二氧化硅填料(体积占比50%),将PCB抗分层能力提高30%
-
LowDK石英布:采用Dk=2.2的石英布替代传统玻璃布,信号损耗降低50%
-
HVLP4铜箔:表面粗糙度降至0.3μm以下,较HVLP3铜箔减少30%信号反射

这种高端背板的单柜价值高达20万美元,也带动了相关供应链企业的发展。从板厚来看,这款背板也突破了传统PCB的制造极限,体现了英伟达在硬件设计上的领先地位。
四、国内正交架构设计:海光scaleX640与阿里磐久AL128
在国内,采用类似正交架构设计的超节点产品主要有阿里磐久AL128和海光scaleX640。
阿里磐久AL128将GPU节点分布在机柜上下两个区域,每个区域包含16个节点,共64颗阿里自研PPU芯片。这些PPU芯片通过机柜后部纵向排列的交换节点进行互联。

海光scaleX640的设计则与NVL576更为接近,计算节点采用纵向排列布局,机柜后部通过横向布置的交换节点进行互联。

五、国内外关键设计差异:中置背板的有无
NVL576与国内产品最核心的设计差异在于中置背板的使用。海光scaleX640和阿里磐久AL128均采用了无中置背板设计,而英伟达NVL576则保留了这一组件。
这一差异的根本原因在于互联拓扑的复杂度。NVL576每个计算节点的4个NVLink外部端口需要分别连接到后部每个域的所有交换节点,只有通过中置背板才能实现如此复杂的拓扑连接。从背板设计可见,每个计算节点纵向4个连接器对应4个NVLink端口,这种高密度互联要求必须有一个中央转接平台。

而海光scaleX640和阿里磐久AL128在GPU互联拓扑上做了一定程度的简化,降低了互联复杂度,从而能够取消中置背板。这体现了不同的Scale-up(纵向扩展)方案选择:英伟达追求极致的互联带宽和灵活性,而国内方案在性能与复杂度之间采取了更平衡的策略。
六、正交架构的发展趋势与市场影响
正交架构正在成为下一代GPU整机柜的主流设计方向,其优势主要体现在三个方面:
-
可靠性提升:减少线缆使用,降低连接点故障率
-
维护性优化:模块化设计使单点维护更加容易
-
信号完整性改善:缩短信号传输路径,提高数据传输质量
目前,国内外厂商在这一领域的竞争日趋激烈。英伟达凭借NVL576进一步巩固了其在高端AI计算市场地位,而海光、阿里等国内厂商也通过各自的正交架构产品展现了一定的技术实力。
值得注意的是,互联协议标准之争也日益白热化。英伟达的NVLink虽然性能领先,但国内厂商正在推动开放标准的发展,以突破NVLink的技术壁垒。未来,GPU互联协议的市场格局可能会出现新的变化。
七、总结与展望
英伟达NVL576正交架构代表了当前GPU超节点设计的最高水平,其中置背板技术体现了在高速高密度互联领域的深厚积累。与国内同类产品相比,NVL576在互联复杂度和性能指标上更为激进,但也带来了更高的制造和维护成本。
国内厂商如海光和阿里在正交架构上的实践表明,通过适当的拓扑简化,可以在保持较高性能的同时降低系统复杂度,这对于大规模部署具有实际意义。随着AI算力需求的持续增长,正交架构及其相关技术将成为各方竞争的焦点领域。
未来,我们预期将看到几个发展趋势:
- 中置背板技术将向更高密度、更低损耗方向发展;
- 互联协议可能出现更多开放标准;国内厂商将在特定应用场景下缩小与英伟达的技术差距。
- 正交架构作为支撑AI算力规模扩展的重要基础,其技术创新和产业竞争值得持续关注。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)