详情页的爬取(正则)
本文介绍了一个爬取书籍网站数据的Python爬虫程序。程序采用模块化设计,主要包含以下功能:1)通过toscrape_api函数获取网页HTML;2)使用toscrape_index函数构建列表页URL;3)通过正则表达式提取详情页链接;4)获取详情页内容并解析书名、价格、库存等信息;5)将结果保存为CSV文件。程序采用生成器优化性能,包含反爬机制,并通过主函数main()协调各功能模块。最终实现
先看代码,代码大部分都是定义函数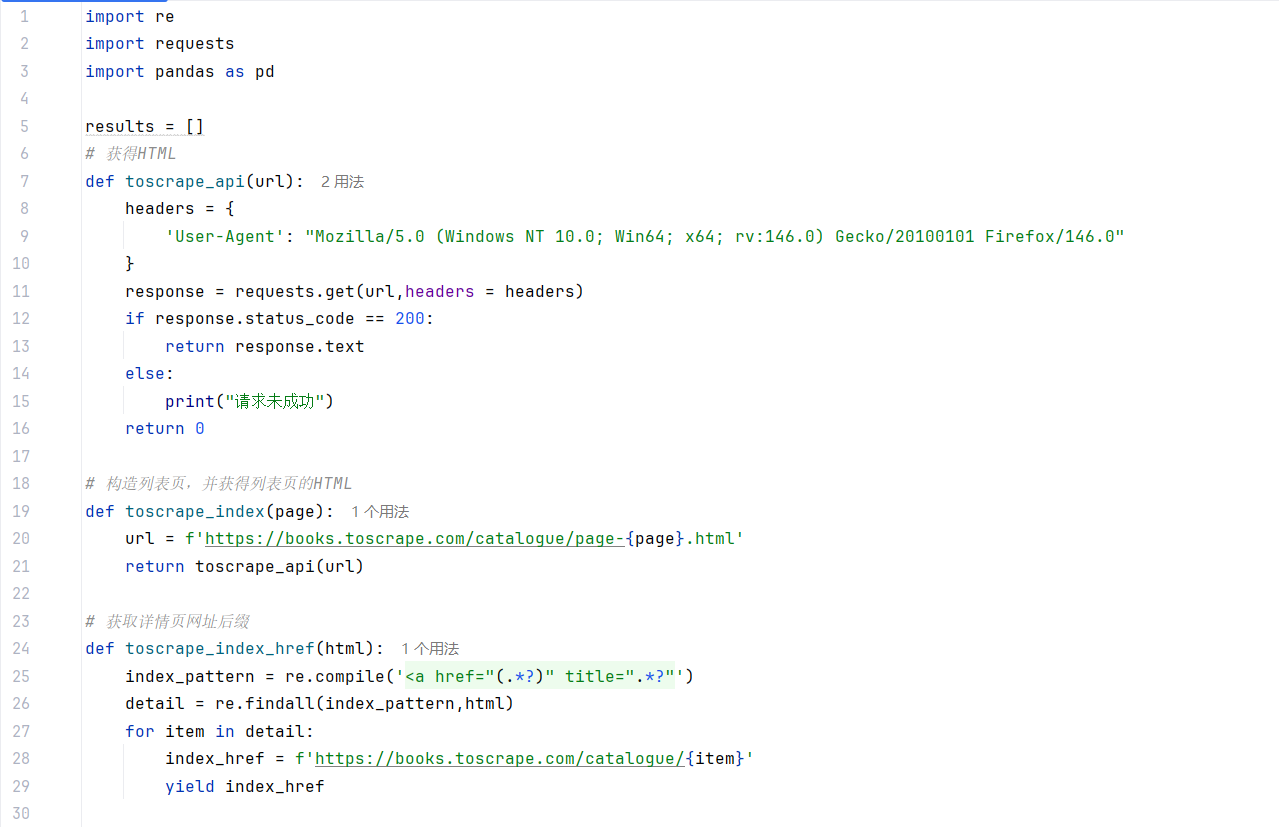
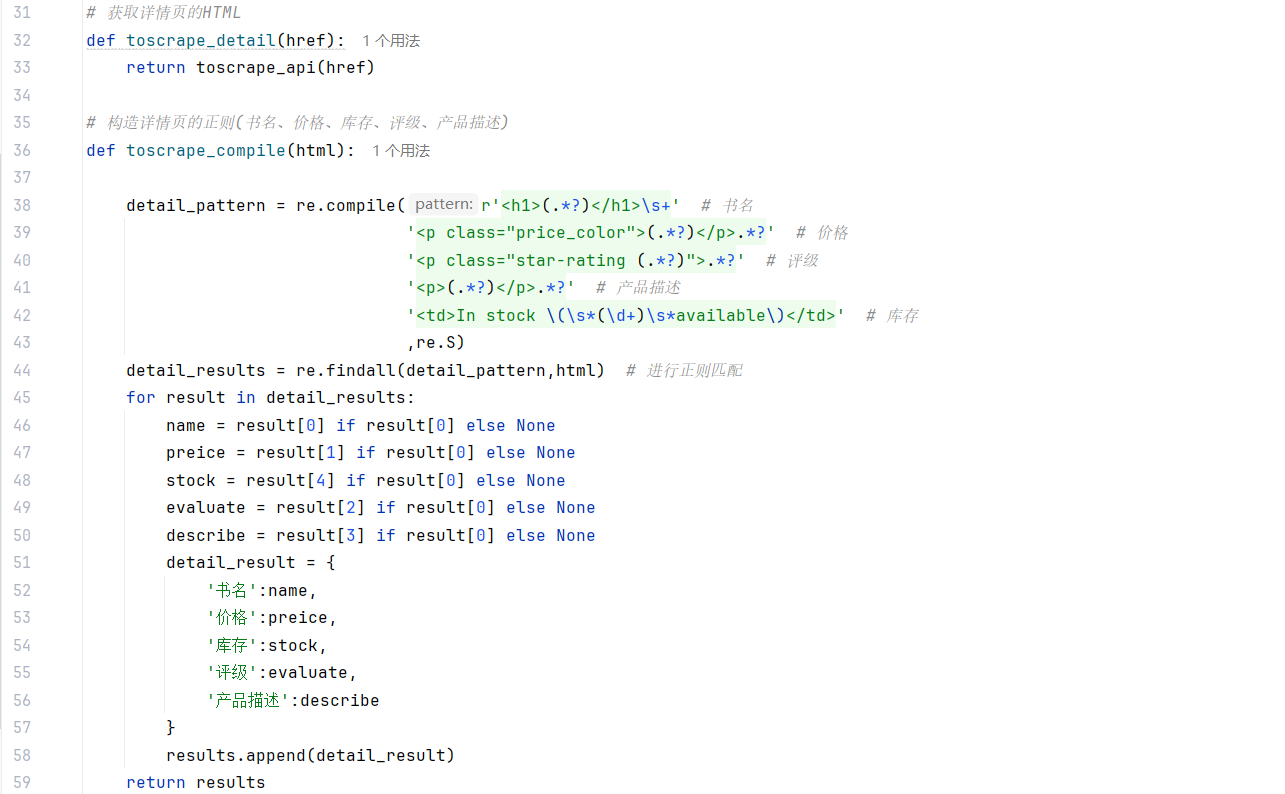
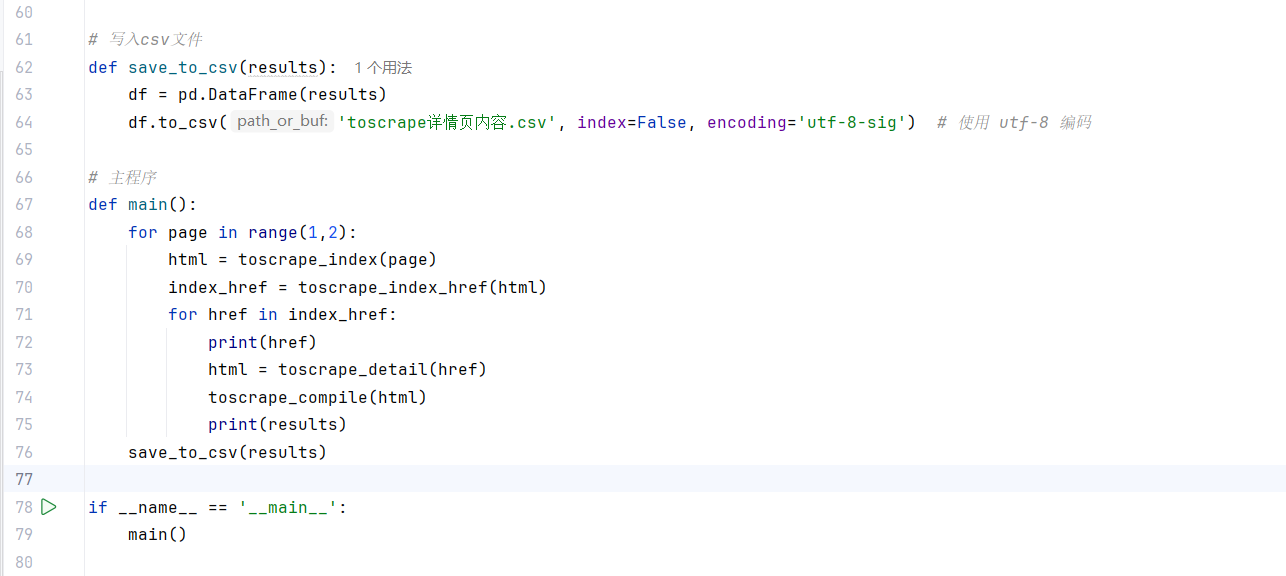
代码就是这样,全是用定义函数,这样出现问题维护和在其他地方调用都比较方便
另外,简单爬虫基本都要遵守:发送请求,获得响应,得到网页文本,定位目标位置(本文用正则表达式),获取信息,打印信息
爬取网址:https://books.toscrape.com/catalogue/page-1.html
一、获取HTML文本
首先定义了一个toscrape_api(url)函数,并传入了一个参数url,这个定义函数用于获得传入参数url的HTML文本,我说白了,我白说了这其实是一个通用函数,只要传入url参数(网址),就获得该参数的HTML。
其中内容还是,发送请求response = requests.get(url,headers = headers),获得响应response,在这其中还做了个简单的反爬headers,至于到底有没有的得到响应,就if语句判断一下
if response.status_code == 200: return response.text else: print("请求未成功") return 0
如果状态码是200,说明就请求成功了,函数就返回response.text,这就是HTML,不然就输出"请求未成功",并返回0,也好让我们知道请求未成功
二、列表页网址获取
我们想要进去每一个书籍的详情页就需要获得每一个详情页的网址url,通过观察发现(有的人说怎么观察,多点开几个书籍的详情页,观察他们的网址变化),每一个书籍的详情页都是网址(https://books.toscrape.com/catalogue/)+列表页中每一本书的属性为href的值,这就需要我们先爬取列表页中每一本书属性为href的值,在与这个网址(https://books.toscrape.com/catalogue/)结合,就形成了详情页的网页,在进行爬取就行了
但在爬取列表页中href的值之前,我们还需要构造列表页的网址,毕竟列表页有10页,通过观察(还是多点几个列表页,看看网址),很容易发现,网址中就只有其中的数字在发生变化,1—10,刚好就是10页的详情页,用一个for循环就能轻易搞定,就是下面代码:
def toscrape_index(page): url = f'https://books.toscrape.com/catalogue/page-{page}.html' return toscrape_api(url)
上面代码中并没有for循环,因为for循环在主程序(定义函数main)中,上面只是构建了列表页网址,其中返回值是定义函数toscrape_api(url),假设传入的参数page为1,那就获得了列表第一页的网址url,然后将该url传入toscrape_api(url)函数中,就获得列表页第一页的HTML
三、获取详情页网址后缀
现在来定义一个方法,用来获得列表页中属性为href的值,也就是详情页的网址的后缀,用正则来匹配
def toscrape_index_href(html): index_pattern = re.compile('<a href="(.*?)" title=".*?"') detail = re.findall(index_pattern,html) for item in detail: index_href = f'https://books.toscrape.com/catalogue/{item}' yield index_href
用compile方法构造正则表达式,然后findall方法查找该列表页的HTML,就能找到匹配该列表页所有的href的值,并以列表的形式存储在detail中,其中每一个href的值都是以元组的形式存在,接着用for循环遍历这个列表,把详情页后缀和https://books.toscrape.com/catalogue拼配就形成了详情页,但是遍历后并没有把他全部存储,而是用yield方法生成了一个生成器index_href,简单来说,就是,遇到yield index_href就先订到这里,再次下面代码出现index_href才进行下一次的循环,直到再次遇到yield index_href又定到这里,或者直接理解成列表也可以遍历,虽然错误,但好理解
四、获取详情页的HTML
既然详情页的网址已经有了,就按照重复性步骤,接着还是发送请求就是下面代码
def toscrape_detail(href): return toscrape_api(href)
至于为什么不在上一个定义函数的结尾直接返回toscrape_api(href),而是多此一举的又定义一个函数,因为有条理,而且出现错误也比较好找,OK,通过这个定义函数,我们就获得了详情页的HTML,接着还是像上面某一步一样,用正则匹配详情页中需要的内容
五、构造匹配详情页书名、价格、库存、评级、产品描述的正则
接下来的定义函数稍微有点长,简单分成两部分
1.正则匹配
其实就是构建正则匹配对象,也挺简单,实在不行就单独创建一个.py文件,多尝试几次,代码就是下面
detail_pattern = re.compile(r'<h1>(.*?)</h1>\s+' # 书名 '<p class="price_color">(.*?)</p>.*?' # 价格 '<p class="star-rating (.*?)">.*?' # 评级 '<p>(.*?)</p>.*?' # 产品描述 '<td>In stock \(\s*(\d+)\s*available\)</td>' # 库存 ,re.S) detail_results = re.findall(detail_pattern,html)
当然也可以创建5个complie方法,用search()方法进行查找,用group()方法获取内容,也很简单,OK还是说说这个,构建了一个整体的正则匹配,如果第一个匹配不到,后面几个也匹配不到,还是建议用(5个complie方法),构建完就进行查找,用的是findall方法,查找结果是列表,列表中的元素是以元组的形式存在
2.获取内容
既然需要的内容是以列表的形式存在,直接遍历就行了
for result in detail_results: name = result[0] if result[0] else None preice = result[1] if result[0] else None stock = result[4] if result[0] else None evaluate = result[2] if result[0] else None describe = result[3] if result[0] else None detail_result = { '书名':name, '价格':preice, '库存':stock, '评级':evaluate, '产品描述':describe } results.append(detail_result) return results
通过遍历就拿到列表中的每一个元素,而这些元素又是元组,所以可以根据索引获得值,方才说,如果第一个匹配错误,后面都匹配不了,直接返回[ ],所以这里的if result[0] else None没啥用,可以删了,然后创建字典,把内容以字典形式存储,然后把字典加入到全局变量列表results,那后面的return results也没啥用可以删了,或者写成return 0都行
这样每使用一次定义函数toscrape_compile(),就在全局变量列表results中加入一次字典(就是一本书籍的信息),直到全部加入
六、保存为csv文件
这是固定用法,这个用法只用传入两个参数,文件名称和列表,这里直接命名为toscrape详情页内容.csv,就只用传入一个参数了
def save_to_csv(results): df = pd.DataFrame(results) df.to_csv('toscrape详情页内容.csv', index=False, encoding='utf-8-sig')
将刚才的全局变量results传入就行了
七、主程序
用以调用各个定义函数,将定义函数联系起来
def main(): for page in range(1,3): html = toscrape_index(page) index_href = toscrape_index_href(html) for href in index_href: print(href) html = toscrape_detail(href) toscrape_compile(html) print(results) save_to_csv(results)
这里详细说下整篇思路:先用for page in range(1,3)(由于内容有点多,我就爬了前两页的)把值赋给toscrape_index(page)函数,就获得了列表页的html,把列表页的html传入toscrape_index_href(html)函数,就获得了详情页的网址url(index_href),这里就遍历了生成器(index_href),把网址index_href传入toscrape_detail(href)函数,就获得详情页的html,将详情页的html传入toscrape_compile(html)这样就会获得书籍的详细内容,通过for循环,不断网全局变量中加入每一本书籍的内容,最后调用save_to_csv(results)函数,把数据存放在CSV文件中,整体过程就是这样
最后还有个启动程序
if __name__ == '__main__': main()y 运行结果


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)