RT-detr-r18 u版结构及解析
RT-DETR模型架构解析:该YAML文件定义了一个结合CNN与Transformer优势的实时检测模型。模型包含三部分:1)骨干网络采用ResNet风格结构,通过4个阶段提取P3-P5多尺度特征;2)头部创新性使用AIFI模块仅在最高层应用注意力机制,通过FPN/PANet结构实现特征融合;3)最终采用Transformer解码器直接预测300个检测框。模型特点包括:使用RepC3模块优化特征处
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, None, False, 'relu']] # 0-P1/2
- [-1, 1, ConvNormLayer, [32, 3, 1, None, False, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, None, False, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2/4
# [ch_out, block_type, block_nums, stage_num, act, variant]
- [-1, 1, Blocks, [64, BasicBlock, 2, 2, 'relu']] # 4
- [-1, 1, Blocks, [128, BasicBlock, 2, 3, 'relu']] # 5-P3/8
- [-1, 1, Blocks, [256, BasicBlock, 2, 4, 'relu']] # 6-P4/16
- [-1, 1, Blocks, [512, BasicBlock, 2, 5, 'relu']] # 7-P5/32
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]] # 9
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 12 input_proj.1
- [[-2, -1], 1, Concat, [1]] # 13
- [-1, 3, RepC3, [256, 0.5]] # 14, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 15, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [5, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 17 input_proj.0
- [[-2, -1], 1, Concat, [1]] # 18 cat backbone P3
- [-1, 3, RepC3, [256, 0.5]] # X3 (19), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.0
- [[-1, 15], 1, Concat, [1]] # 21 cat Y4
- [-1, 3, RepC3, [256, 0.5]] # F4 (22), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 23, downsample_convs.1
- [[-1, 10], 1, Concat, [1]] # 24 cat Y5
- [-1, 3, RepC3, [256, 0.5]] # F5 (25), pan_blocks.1
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # Detect(P3, P4, P5)
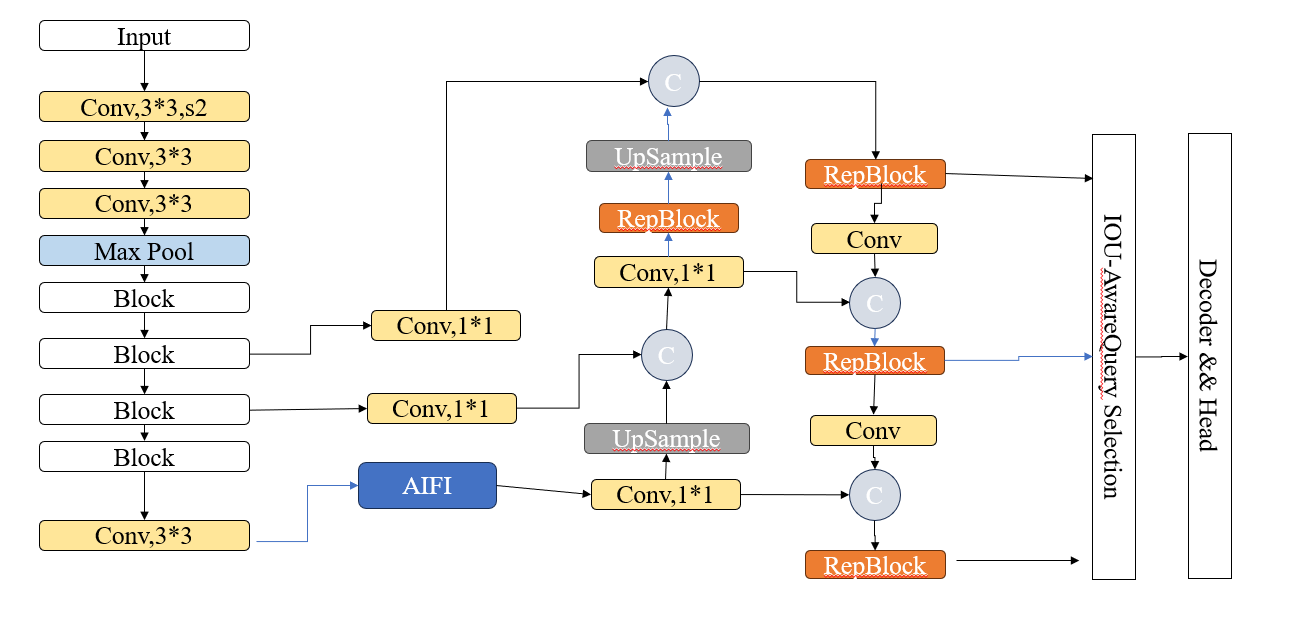
结构图
这份 YAML 文件是 RT-DETR(Real-Time DEtection TRansformer)对象检测模型的网络结构定义文件。
RT-DETR 是一个结合了 Transformer 和 CNN 优势的模型,旨在提供高精度的同时保持实时性。
为了让你看懂,我将它拆解为 三个主要部分 来解释:
-
参数定义 (Parameters)
-
骨干网络 (Backbone):负责提取图像特征。
-
头部/颈部 (Head):负责融合特征并进行预测。
第一部分:基础语法解释
在每一行配置中,格式通常为:
[from, repeats, module, args]
-
from: 输入来自哪一层。-1 表示上一层,[6, 4] 表示来自第 6 和第 4 层。
-
repeats: 该模块重复几次。
-
module: 使用的模块名称(如 Conv, RepC3 等)。
-
args: 传递给该模块的具体参数(如通道数、卷积核大小等)。
第二部分:详细代码解读
1. 参数设置
nc: 80 # number of classes (类别数量,例如 COCO 数据集是 80 类)
scales: # 模型缩放系数
l: [1.00, 1.00, 1024] # 分别对应 [深度 depth, 宽度 width, 最大通道数]
2. Backbone (骨干网络)
这部分的作用像是人的眼睛,将输入的图片一层层缩小,提取出不同尺度的特征(纹理、轮廓、物体部件)。
-
层 0-3 (Stem/主干): 快速降低图片分辨率。
-
ConvNormLayer: 这是一个组合层(卷积+归一化+激活函数)。
-
MaxPool2d: 最大池化层,用于降采样。
-
经过这几层后,图像尺寸变小,特征通道数增加。
-
-
层 4-7 (Stages/阶段): 提取核心特征。
-
这里使用了 BasicBlock,这是 ResNet(残差网络)的基础模块。
-
第 5 层 (P3): 输出 128 通道,对应 stride 8 (原图大小的 1/8)。
-
第 6 层 (P4): 输出 256 通道,对应 stride 16 (原图大小的 1/16)。
-
第 7 层 (P5): 输出 512 通道,对应 stride 32 (原图大小的 1/32)。这是最高级的语义特征。
-
3. Head (头部 - 混合编码器与解码器)
这部分是 RT-DETR 的核心,称为 Hybrid Encoder (混合编码器) 和 Decoder (解码器)。它将 Backbone 提取的特征进行融合和处理。
A. 处理最高层特征 (Transformer 部分)
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8: 将 P5(512通道) 压缩到 256通道
- [-1, 1, AIFI, [1024, 8]] # 9: AIFI (Attention-based Intra-scale Feature Interaction)
-
AIFI: 这是 RT-DETR 的关键创新。它只在最高层特征(P5)上使用 Transformer 的注意力机制。这比在所有层都用 Transformer 要快得多,同时能捕捉全局信息(比如图片的左上角和右下角有什么关联)。
B. 特征融合 (FPN + PANet 结构)
这里采用了类似 YOLO 的特征金字塔结构,先上采样(从小图变大图),再下采样(从大图变小图),把深层语义和浅层细节结合。
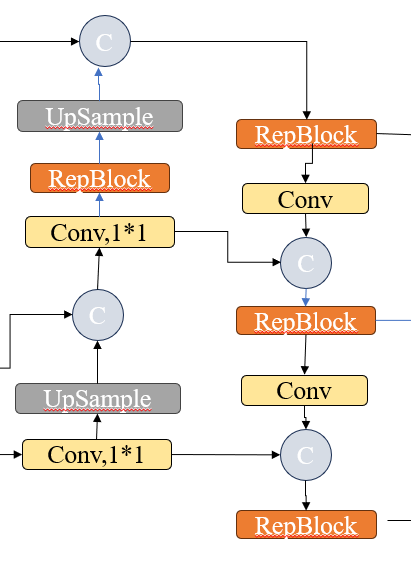
2. 流程详解(数据的流动)
这张图的流动逻辑是一个 “倒U型” 或 “回旋镖” 结构:
第一阶段:左侧流程(自顶向下,变大)
第二阶段:右侧流程(自底向上,变小)
3. 对应到你的代码
让我们把图中的关键节点和代码对上号(假设图是从下往上再往下):
(接着继续向上/变大)
(开始右侧下采样流程)
-
图例解释(看图说话)
-
🔵 C (蓝圆圈 - Concat):
-
意思: 拼接。就像把两块积木并排粘在一起。
-
作用: 把来自不同来源的特征“叠”在一起,让通道数变厚,信息量变大。
-
对应代码: Concat (例如第 13, 18, 21, 24 行)。
-
-
🟧 RepBlock (橙色方块):
-
意思: 卷积模块。
-
作用: 对拼接后的特征进行“消化”和融合,提取有用信息。
-
对应代码: RepC3 (例如第 14, 19, 22, 25 行)。
-
-
⬜ UpSample (灰色方块):
-
意思: 上采样(图片放大)。
-
作用: 把小的特征图放大(比如从 20x20 变成 40x40),这样它才能和下一层的大图进行拼接。
-
对应代码: nn.Upsample (例如第 11, 16 行)。
-
-
🟨 Conv (黄色方块):
-
左边的 Conv, 1*1: 调整通道数(瘦身),方便后续拼接。
-
右边的 Conv (无标号): 这是一个下采样卷积(Stride=2),作用是把图片变小(比如 40x40 变成 20x20),提取更抽象的特征。
-
对应代码: 左边对应 Conv (Line 12, 17),右边对应 Conv (Line 20, 23)。
-
-
方向: 从下往上画(但在逻辑上是把深层的小图放大)。
-
逻辑:
-
拿来一个深层的特征(很抽象,比如“这里有个物体”)。
-
UpSample (放大)。
-
C (拼接): 和浅层的特征(很清晰,比如“这里是边缘”)拼在一起。
-
RepBlock: 融合。
-
-
目的: 让浅层的大图(负责看小物体)也能拥有深层的语义信息(知道是什么)。
-
方向: 从上往下画。
-
逻辑:
-
拿来刚才融合好的大图特征。
-
Conv (缩小/下采样)。
-
C (拼接): 和左边同一高度的特征再次拼接。
-
RepBlock: 再次融合。
-
-
目的: 把底层的细节信息(纹理、边缘)再次传回给高层,让高层的小图(负责看大物体)定位更精准。
-
图左下角 Conv 1*1: 对应代码 第 12 行 [6, 1, Conv, [256, 1, 1...]] (处理 P4 特征)。
-
图左侧 UpSample: 对应代码 第 11 行 Upsample。
-
图左侧 C (蓝圈): 对应代码 第 13 行 Concat (把 P5 上采样后的结果 和 P4 拼起来)。
-
图左侧 RepBlock: 对应代码 第 14 行 RepC3。
-
图中间 UpSample: 对应代码 第 16 行。
-
图中间 C: 对应代码 第 18 行 (和 P3 拼)。
-
图上方 RepBlock: 对应代码 第 19 行 (这是 P3 输出,最小的物体)。
-
图右侧 Conv (黄色): 对应代码 第 20 行 (下采样,变小)。
-
图右侧 C: 对应代码 第 21 行 (拼接)。
-
图右侧 RepBlock: 对应代码 第 22 行 (这是 P4 输出,中等物体)。
C. 最终解码器 (Decoder)
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]]
-
输入: [19, 22, 25] 分别代表融合后的 P3, P4, P5 特征图。
-
RTDETRDecoder: 这是 Transformer 解码器头。
-
参数解释:
-
nc: 80 (类别数)
-
256: 隐藏层通道数
-
300: Queries 数量 (Transformer 一次性预测 300 个潜在框,而不是像 YOLO 那样基于网格生成成千上万个候选框)。
-
4: 解码器层数
-
8: 注意力头数 (Attention Heads)
-
总结:这个配置文件的逻辑流
-
图片进入 -> 经过 ResNet 风格的 Backbone -> 得到 P3, P4, P5 三个尺度的特征。
-
P5 特征 单独拿出来,经过 AIFI (注意力机制) 增强全局感知能力。
-
FPN/PANet: 增强后的 P5 与 P4、P3 进行复杂的“上下融合”(使用 RepC3 模块),让每一层特征都同时包含丰富的细节(来自浅层)和丰富的语义(来自深层)。
-
RTDETRDecoder: 同时接收三个尺度的特征,利用 Transformer 的 Query 机制,直接输出 300 个预测框和类别。
简单来说: 这就是一个用 "ResNet" 做身体,用 "YOLOv8 零件" 做脖子,用 "Transformer" 做大脑的缝合怪模型(褒义),旨在兼顾速度和精度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)