LangGraph 能解决哪些真实问题?
LangGraph框架专注于解决现实场景中的复杂流程问题,支持长流程执行、人机协同和多Agent协作。其核心优势包括:1)通过持久化检查点实现分钟级任务的可靠执行;2)提供interrupt/resume机制实现任意节点的人工干预;3)支持多Agent模块化协作,提升任务处理质量。典型案例涵盖金融合规审核、科研自动化等需要长时间运行或人工参与的流程,但不适用于简单对话场景。LangGraph通过状
作为一名开发者,我在实践中深深体会到,智能代理的核心价值并不在于“刷新聊天记录”,而在于解决现实世界中的复杂流程。从银行风控到企业文档审批、从多机器人协作到科研自动化,LangGraph 提供了一套底层框架来支撑这些场景。本章围绕几个常见的痛点,阐述 LangGraph 如何发挥作用,并指出它不适合的情况。
长流程 Agent(> 30 秒 / 分钟级)
许多企业级应用的执行时间远远超过普通对话。例如,一个合规审核流程可能需要几分钟到几天:用户上传 PDF,分类器标记为高风险,系统等待第三方审计或监管 API 返回,然后用户还可能在流程中修改文档。这种流程包含大量等待事件和异步决策,传统 BPMN 模型很难表达 。另外 Agent程序经常需要暂停几秒或几分钟,以调用外部工具或等待人类反馈 。
LangGraph 通过持久化检查点解决了这一难题。它在每个“超步(super‑step)”保存全局状态,当流程暂停或失败时可以从上次保存的状态恢复。这样,长时间的文件处理或耗时的 API 调用不会导致重新计算,系统也能跨机器或服务重启继续执行 。此外,官方文档总结了几种处理长流程的模式:
• Wait‑for‑Event:在图中放置一个等待节点,直到外部事件(如文件上传、回调消息)触发继续执行 。
• Periodic Wake‑Up:定期唤醒代理检查外部状态,例如每小时轮询一次邮件或数据库 。
• Escalation Trees:在长流程中设置超时和升级逻辑,超过阈值便通知人工干预或走备用路线 。
下图展示了一个典型的长流程和人机协同的组合。流程从用户请求出发,经由 LLM 解释后调用耗时的外部工具。如果该步骤需要人工审批,LangGraph 通过 interrupt() 暂停执行,等待人类审查并修改状态,然后从持久化检查点恢复继续执行。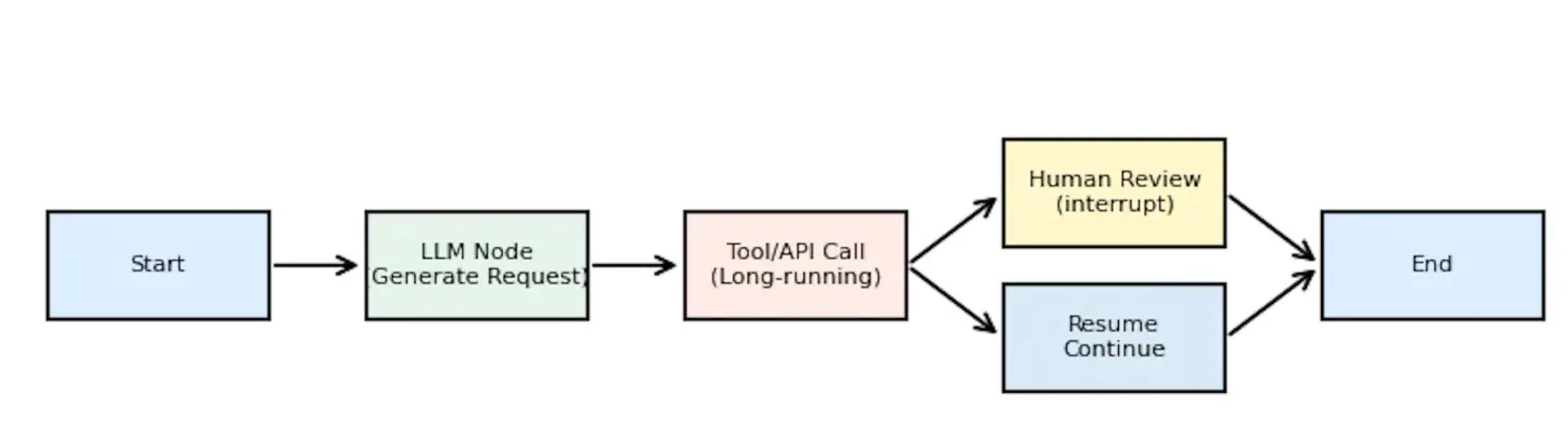
通过这种方式,LangGraph 能够支撑分钟甚至天级的任务,而且无需担心中断后状态丢失。开发者只需要为每个线程指定 thread_id 并提供一个合适的检查点存储,就可以让代理具备持久化执行能力 。
示例:长流程与持久化执行
为了演示如何在 LangGraph 中处理耗时任务和保存执行进度,下面的示例构建了一个异步节点,它会模拟一个长耗时操作(例如调用外部服务)。我们使用 SQLite 检查点持久化执行状态,以便在进程中断后恢复:
import asyncio
from typing import TypedDict, Annotated
import operator
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.sqlite import SqliteCheckpointer
# 定义状态,包含执行步骤和结果
class LongProcessState(TypedDict):
step: Annotated[int, operator.add]
result: str
async def long_task(state: LongProcessState) -> dict:
# 模拟长耗时操作
print(f"Step {state['step']}: starting long task...")
await asyncio.sleep(10) # 代表外部调用耗时 10 秒
return {"step": state["step"] + 1, "result": f"done at step {state['step']}"}
builder = StateGraph(LongProcessState)
builder.add_node("long_task", long_task)
builder.set_entry_point("long_task")
builder.add_edge("long_task", END)
# 使用 SQLite 持久化检查点
checkpointer = SqliteCheckpointer("./long_process.db")
graph = builder.compile(checkpointer=checkpointer)
# 异步调用时指定 thread_id,用于恢复
async def run():
state = {"step": 0, "result": ""}
final_state = await graph.ainvoke(state, thread_id="job-123")
print(final_state)
# asyncio.run(run()) # 运行示例
在这个例子中,如果程序在 await asyncio.sleep 期间被终止,可以重新调用 graph.ainvoke 并传入相同的 thread_id。检查点会使 LangGraph 从上次保存的状态继续执行,避免重新执行耗时操作 。
人机协同(Human‑in‑the‑Loop)
在许多高风险场景中,模型决策必须经过人类审核。LangGraph 提供了一种简单的方式在任何节点插入人工干预:调用 interrupt() 函数时,运行时会保存当前状态并停止调度 。外部系统(如用户界面或审批平台)可以在稍后通过 resume() 命令恢复执行,并将人为修改的状态传入。这一机制意味着:
• 任意节点可暂停:人机协同不局限于流程末尾,开发者可以在关键节点之前主动暂停,等待审批或输入。
• 状态可修改:在人类审核期间,可以直接编辑全局状态中的变量,例如更正错误信息或添加额外数据 。
• 持久等待:由于检查点保存了状态,代理可以等待任意长的时间而不会丢失上下文;在长流程场景中尤其重要。
当结合上一节提到的持久化执行,人机协同成为一种可靠的“安全阀”:在模型做出关键决策之前,人类可以介入、审查并修改结果。这对于金融合规、医疗诊断等领域非常关键。
示例:人机协同(Human‑in‑the‑Loop)
使用 LangGraph 可以在任何节点主动暂停执行,等待人工审核后再继续。下面的代码演示如何通过 interrupt() 暂停工作流,并在收到人类反馈后用 resume() 恢复。
from typing import TypedDict
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemoryCheckpointer
from langgraph import interrupt
class ReviewState(TypedDict):
content: str
approved: bool
# 节点:发送内容并等待审批
def submit_for_review(state: ReviewState) -> dict:
print(f"Submitting for review: {state['content']}")
# 暂停流程,等待外部审核;interrupt 返回值将作为恢复时的状态补丁
return interrupt({"approved": False})
# 节点:根据审核结果决定是否完成或修改
def finish(state: ReviewState) -> dict:
if state["approved"]:
print("Content approved")
return {}
else:
# 如果未通过审核,可以在这里修改内容或重新提交
return {"content": state["content"] + " (revised)", "approved": False}
# 路由函数:如果未批准则重新进入 submit_for_review
def route(state: ReviewState):
return "submit_for_review" if not state.get("approved", False) else END
# 构建图
builder = StateGraph(ReviewState)
builder.add_node("submit_for_review", submit_for_review)
builder.add_node("finish", finish)
builder.set_entry_point("submit_for_review")
builder.add_conditional_edges("submit_for_review", route)
builder.add_edge("finish", END)
graph = builder.compile(checkpointer=MemoryCheckpointer())
# 首次运行:提交内容后流程会在 interrupt 处暂停
state = {"content": "Draft contract", "approved": False}
result = graph.invoke(state, thread_id="review-1")
# result 表示暂停点,应用应提示用户进行审核
# 经过人工审批后恢复流程:传入修改过的状态补丁
resume_state = {"content": "Draft contract", "approved": True}
final_state = graph.invoke(resume_state, thread_id="review-1")
print(final_state)
在第一次调用 graph.invoke() 后,执行会暂停在 submit_for_review 节点。应用可以提示用户审核内容,并在审核完成后通过再次调用 graph.invoke 传入经编辑的 resume_state 继续执行。这展示了人机协同在 LangGraph 中的实现方式 。
多 Agent 协作
现实任务往往需要多角色协作。单个代理面对十几个工具或复杂任务时易出错;如果把任务拆分给不同的专长 Agent,各自有独立的提示、模型和工具,整体效果通常更好 。LangGraph 天生就是图结构,它把独立 Agent 视作节点,把它们之间的通信视作边 。多 Agent 设计有三大好处:
• 职责分离:每个 Agent 专注于单一领域(如撰写、校对、分析),减少模型选择过多工具而导致失败的概率 。
• 独立提示:不同的 Agent 可使用差异化的系统提示和 few‑shot 示例,提升任务质量 。
• 模块化调试:把复杂问题拆解为多个 Agent 节点,便于单独评估和优化,而不影响整体工作流 。
LangGraph 官方博客列举了三种多 Agent 模式:共享 scratchpad 的协作模式、由路由器协调的Agent Supervisor,以及将整个子图封装为节点的层次化团队。在这些模式中,Supervisor Agent 充当路由器,决定任务走向,而具体的工作则由底层 Agent 完成;开发者可以灵活组合这些模式构建任意复杂的协作体系。
示例:多 Agent 协作
下面的示例构建两个简单的代理:一个负责撰写草案,另一个负责审稿。状态对象中包含文档内容和阶段标记,路由函数根据阶段决定下一步由哪位代理处理。虽然示例省略了真实的 LLM 调用,但展示了多 Agent 如何在 LangGraph 中协同工作。
from typing import TypedDict, Annotated
import operator
from langgraph.graph import StateGraph, END
class DocState(TypedDict):
document: Annotated[str, operator.add]
stage: str
# 撰写代理:生成初稿
def writer_agent(state: DocState) -> dict:
content = state["document"] + "\n本文阐述了 LangGraph 的优势。"
return {"document": content, "stage": "review"}
# 审稿代理:审核并完成
def reviewer_agent(state: DocState) -> dict:
reviewed = state["document"] + "\n审核意见:通过。"
return {"document": reviewed, "stage": "done"}
# 路由函数:根据阶段调用不同代理
def route(state: DocState):
if state["stage"] == "write":
return "writer"
elif state["stage"] == "review":
return "reviewer"
else:
return END
builder = StateGraph(DocState)
builder.add_node("writer", writer_agent)
builder.add_node("reviewer", reviewer_agent)
builder.set_entry_point("writer")
builder.add_conditional_edges("writer", route)
builder.add_conditional_edges("reviewer", route)
graph = builder.compile()
initial_state = {"document": "初稿:", "stage": "write"}
final_state = graph.invoke(initial_state)
print(final_state["document"])
在这个示例中,writer 和 reviewer 两个节点扮演不同角色,由路由函数根据 stage 值决定流程走向。通过拆分职责并为每个代理提供独立的提示和工具,可以像官方博客所述那样提升任务质量并便于调试 。
复杂决策与回退
复杂任务常常需要循环、分支和条件判断。LangGraph 的图结构允许在节点之间灵活配置边,通过条件函数控制下一步走向,例如根据模型输出选择不同工具或分支。本质上,这种流程接近于有向图甚至状态机 。
然而,当决策出现错误时,我们希望能够回退到某个检查点,修改状态并重新执行。LangGraph 的时间旅行功能提供了这种能力:
• 运行图时,框架会为每个超步记录一个检查点并保存线程历史 。
• 开发者可以通过 get_state_history() 检索某个线程的执行历史,找到特定的检查点 。
• 使用 update_state() 修改状态并指定 checkpoint_id,随后调用 invoke() 即可从该检查点复盘或分叉执行 。
这种“时间旅行”不仅用于纠错,还能探索不同策略:在相同的起点上尝试多种分支,比较结果并选择最优路径 。下图示例中,代理在执行到 Node C 后出现错误,我们通过时间旅行回退到该检查点并选择另一条路径 Alternative C’,最终顺利结束。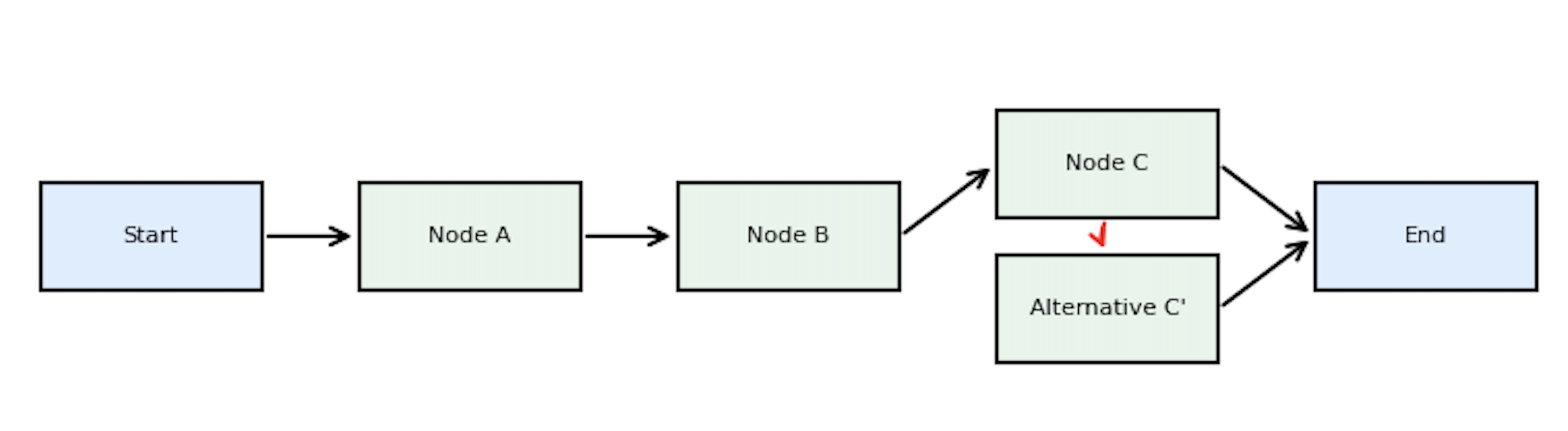
示例:条件决策与时间旅行
下面的示例展示如何在 LangGraph 中实现条件分支以及如何通过时间旅行功能回退并修改状态。当代理的决策出现错误时,我们可以获取执行历史、回退到某个检查点并重新运行。
from typing import TypedDict, Annotated
import operator
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemoryCheckpointer
class DecisionState(TypedDict):
value: Annotated[int, operator.add]
path: str
def decision_node(state: DecisionState) -> dict:
# 简单的决策:如果 value 太小,则加倍;否则减半
if state["value"] < 10:
return {"value": state["value"] * 2, "path": "double"}
else:
return {"value": state["value"] // 2, "path": "half"}
def route(state: DecisionState):
# 根据路径决定是否继续循环
return "decision" if state["path"] == "double" else END
builder = StateGraph(DecisionState)
builder.add_node("decision", decision_node)
builder.set_entry_point("decision")
builder.add_conditional_edges("decision", route)
graph = builder.compile(checkpointer=MemoryCheckpointer())
# 第一次运行,从 value=3 开始,会经历多次 double
thread_id = "decision-1"
result = graph.invoke({"value": 3, "path": ""}, thread_id=thread_id)
print(result) # 例如 {'value': 12, 'path': 'half'}
# 获取执行历史
history = graph.get_state_history(thread_id)
for step in history:
print(step["checkpoint_id"], step["state"])
# 假设我们要回退到第二个检查点并修改 value
checkpoint_id = history[1]["checkpoint_id"]
graph.update_state(thread_id, checkpoint_id, {"value": 7})
# 从修改后的状态重新执行
new_result = graph.invoke({}, thread_id=thread_id)
print(new_result) # 根据新的 value 走不同路径
上述代码中,decision 节点根据当前值决定翻倍还是减半。在初次运行结束后,我们调用 get_state_history() 获取所有历史检查点 。使用 update_state() 指定某个检查点并更新状态后,再次执行即可从该节点继续运行,探索不同的路径 。
可调试、可回溯、可复现的 Agent
在生产环境中,我们需要追踪和调试代理的决策过程。LangGraph 通过以下机制提升可观测性和复现能力:
- 持久化状态和历史记录:每一步都会存储检查点,包括输入、输出、下一个待执行节点和任务信息 。这些历史记录可以用于审计、调试,也可以生成再现报告。
- 可视化和时序分析:LangChain 生态中的 LangSmith 工具可显示执行路径、状态变更和运行时指标,帮助开发者发现性能瓶颈与错误 。
- 内置流式输出:LangGraph 支持将模型推理的 token 流、工具调用结果和自定义数据流实时发送给前端,提高用户体验并帮助开发者观察代理的思考过程 。
- 记忆管理:LangGraph 的状态不仅包含短期工作记忆,还可以与长久内存存储结合,让代理在不同会话间保持上下文 。
通过这些机制,我们可以复现任意一次运行,回放模型输出、检查决策点并修改错误,显著降低调试和迭代成本。
LangGraph 不适合的场景
尽管 LangGraph 在复杂任务中表现强大,但在以下情况下不一定是最佳选择:
• 简单线性流程:如果应用只有几个串联的模型调用,使用 LangChain 或原生 SDK 更简洁,无需图式编排。
• 对性能要求极高的服务:LangGraph 的持久化和调度会引入额外开销,可能不适合毫秒级延迟的场景。
• 工程复杂度敏感:LangGraph 的配置和状态管理较复杂,初学者需要理解节点、边、状态等概念。LangGraph 的缺点包括设置复杂、易出现代理循环、并且在大规模场景下资源消耗较大。这些问题需要通过仔细设计图结构和合理的检查点策略来规避。
• 严格控制 API 参数或自定义调度:在一些极度定制的系统中,直接调用底层 SDK 可能更灵活。社区讨论中也提到,当需要精细控制调用顺序或性能优化时,重写薄层封装比使用全功能框架更加可控 。
因此,在选择 LangGraph 时,应根据项目的复杂度、运行时长、协同需求和开发团队经验做出权衡。对于简单的聊天机器人或单步任务,LangChain 足以应对;而对于需要长时间运行、复杂决策、多角色协作、人工审查和可复现调试的场景,LangGraph 则提供了完善的基础设施。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)