AI人工智能-序列标注任务-第九周(小白)
目标:找到使概率最大的标签序列y关键概念:发射矩阵(Emitter Matrix):shape 为「序列长度 × 标签数」,表示每个 token 对应每个标签的概率;转移矩阵(Transition Matrix):shape 为「标签数 × 标签数」,表示从一个标签转移到另一个标签的概率;归一化项:确保概率之和为 1;特征函数:捕捉标签转移和 token 特征的关联。
一、序列标注的核心概念
1.定义与核心逻辑
序列标注是自然语言处理(NLP)中的基础任务,核心是对输入序列的的每个时间步(token)进行分类,输出对应的标签序列。
-
输入:长度为 n 的序列
(如汉字、单词、字符等);
-
输出:长度相同的标签序列
(如边界标签、实体类型标签等)。
本质是建立“输入token -> 输出标签”的映射关系,且考虑序列的上下文关联性(如一个token的标签依赖于前后token的标签)
2.典型的应用场景
序列标注是众多NLP任务的底层支撑,核心应用包括
-
中文分词:判断每个字是否为词边界;
-
词性标注:标注每个词的语法属性(如名词、动词);
-
句法分析:标注句子成分(如主语、谓语);
-
命名实体识别(NER):识别文本中的人名、地名、机构名等实体;
-
文本加标点:为无标点文本自动添加标点(粗粒度分词);
-
句子级分类:对段落中的每句话进行类别标注。
二、核心应用场景
1.中文分词(基于序列标注)
(1)标注体系
通过标签定义词的边界和内部结构,常用标签集:
-
B(Begin):词的左边界;
-
E(End):词的右边界;
-
M(Middle):词的内部;
-
S(Single):单字成词。
(2)标注约束
-
B后面不能直接跟S
-
M后面不能跟S
-
S后面不能跟M或E
(3)示例
输入文本:“跟着 Tfboys 学左手右手一个慢动作”
标注结果:跟 / B 着 / E Tfboys/S 学 / S 左 / B 手 / E 右 / B 手 / E 一 / B 个 / E 慢 / B 动 / M 作 / E
后处理结果:跟着 Tfboys 学 左手 右手 一个 慢动作
2.命名实体识别(NER)
(1)标注体系
针对不同实体类型(地址、机构、人名)设计专属边界标签,避免混淆:
-
地址:BA(左边界)、MA(内部)、EA(右边界);
-
机构:BO(左边界)、MO(内部)、EO(右边界);
-
人名:BP(左边界)、MP(内部)、EP(右边界);
-
O:无关字(非实体)。
(2)示例
输入文本:“花园北路的北医三院里,昏迷三年的我听杨幂的爱的供养时起身关了收音机”
标注结果:花 /BA 园 /MA 北 /MA 路 /EA 的 /O 北 /BO 医 /MO 三 /MO 院 /EO 里 /O 杨 /BP 幂 / EP 的/O 爱/O 的/O 供/O 养/O 时/O 起/O 身/O 关/O 了/O 收/O 音/O 机/O 。/O
后处理结果:{花园北路 / Address} 的 {北医三院 / Org} 里,昏迷三年的我听 {杨幂 / PersonName} 的 爱 的 供 养 时 起 身 关 了 收 音 机 。
3.文本加标点任务
-
背景:语音识别、机器翻译的输出常无标点,需自动补全以提升可读性;
-
本质:粗粒度分词任务,通过序列标注判断 “是否需要添加标点”(如逗号、句号、感叹号);
-
价值:降低文本阅读成本,为后续 NLP 任务(如句子级分类)提供基础。
4.句子级序列标注
-
任务逻辑:对段落中的每句话进行分类(如情感类别、主题类别);
-
流程:paragraph→sentence→token,先拆分句子,再对每个句子向量化,最后进行序列标注;
-
特点:颗粒度比 token 级标注更粗,聚焦句子整体属性。
三、技术实现方案
1.基于深度学习的基础框架
核心思路:通过神经网络将每个token向量化,捕捉上下文特征后预测标签
- 核心组件:常用BLSTM(双向长短期记忆网络)作为特征提取器,能同时利用前向和后向上下文信息
- 流程:token->embedding(词嵌入)->BLSTM(特征提取)->标签分类
2.CRF(条件随机场)
CFR是序列标注的核心模块,解决“标签上下文依赖”问题(如 “B” 后不能直接接 “B”,需接 “M” 或 “E”),常与BLSTM结合使用(BLSTM-CRF)
(1)核心定义
- 目标:找到使概率
最大的标签序列y
-
关键概念:
-
发射矩阵(Emitter Matrix):shape 为「序列长度 × 标签数」,表示每个 token 对应每个标签的概率;
-
转移矩阵(Transition Matrix):shape 为「标签数 × 标签数」,表示从一个标签转移到另一个标签的概率;
-
归一化项
:确保概率之和为 1;
-
特征函数
:捕捉标签转移和 token 特征的关联。
-
(2)转移矩阵示例
以 “人名(Person)” 和 “机构(Organization)” 为例,转移矩阵中的值表示标签间转移的概率(或权重):
| 从 \ 到 | START | B-Person | I-Person | B-Org | I-Org | END |
|---|---|---|---|---|---|---|
| START | 0 | 0.8 | 0.007 | 0.7 | 0.9 | 0.08 |
| B-Person | 0.9 | 0.0006 | 0.6 | 0.009 | -1 | 0.5 |
| I-Person | 0.0003 | 0.008 | ... | ... | ... | ... |
注:负值表示该转移几乎不可能(如 B-Person 后直接接 END)。
(3)Loss计算
- 核心逻辑:最大化正确标签序列的对数概率,最大化loss
- 公式:
输入序列X,输出序列为y的分数:
输入序列X,预测输出序列为y的概率:
对上式取log,目标为最大化该值
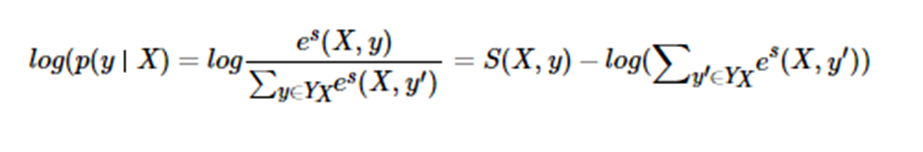
对上式取相反数做loss,目标为最小化该值:
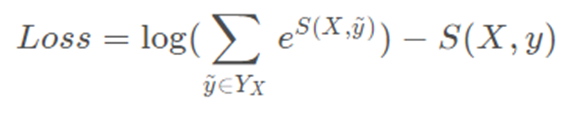
3.解码算法(序列预测阶段)
解码是根据模型输出(发射矩阵+转移矩阵)找到最优标签序列的过程,常用两种算法
(1)维特比解码(Viterbi Decoding)
- 核心思想:动态规划,通过“局部最优->全局最优”,在每个时间步记录最优路径
- 复杂度:
(n为序列长度,D为标签数)
- 特点:高效,精确,是序列标注的首选解码算法
(2)束搜索(Beam Search)
- 核心思想:每一步保留概率最高的B个路径(B为束宽),避免局部最优陷阱
- 复杂度:
(B为束宽,通常
)
- 特点:比维特比更灵活,适合复杂序列,但需权衡束宽(B越大,复杂度越高)
(3)效率对比
| 算法 | 复杂度 | 特点 |
|---|---|---|
| 穷举路径 | 复杂度极高,不可用 | |
| 维特比解码 | 高效、精确,首选 | |
| 束搜索 | 灵活,适合复杂场景 |
4.基于规则的方法
(1)核心逻辑
通过正则表达式、词表匹配等规则直接标注序列,无需训练模型。
-
适用场景:规则能明确覆盖的简单任务(如匹配手机号、邮箱、固定格式的实体);
-
优势:无需标注数据,速度快,解释性强;
-
原则:“规则能处理好的,尽量不用模型”。
(2)正则表达式基础
正则表达式是规则方法的核心工具,用于描述字符串匹配模式,关键要素包括:
| 类型 | 示例与说明 |
|---|---|
| 基础匹配 | ab:匹配字符串中的 “ab” 子串(re.search("ab", "abb")返回 True) |
| 位置匹配 | ^ab:匹配字符串开头的 “ab”(re.match("ab", "abb")返回 True) |
| 元字符 | \d:匹配数字,\s:匹配空白字符,\w:匹配字母 / 数字 / 下划线 |
| 量词 | *(0 次及以上)、+(1 次及以上)、?(0 次或 1 次)、{n,m}(n-m 次) |
| 贪婪 / 非贪婪 | n.*w(贪婪,匹配最长符合串)、n.*?w(非贪婪,匹配最短符合串) |
| 修饰符 | re.I(大小写不敏感)、re.M(多行匹配)、re.S(.匹配换行) |
(3)常用正则函数
-
re.search(pattern, string):查找字符串中是否存在匹配 pattern 的子串; -
re.match(pattern, string):判断字符串开头是否匹配 pattern; -
re.findall(pattern, string):返回所有匹配的子串列表; -
re.sub(pattern, repl, string):替换匹配的子串; -
re.split(pattern, string):按匹配的子串分割字符串。
四、评价指标
序列标注的评价需区分 “token 级准确率” 和 “实体级准确率”,核心指标如下:
1. 基础指标(实体级)
实体需完整命中(边界和类型均正确)才算有效,指标定义:
-
准确率(Precision):
(预测为正且实际为正的实体数 / 所有预测为正的实体数);
-
召回率(Recall):
(预测为正且实际为正的实体数 / 所有实际为正的实体数);
-
F1 值:
(平衡准确率和召回率,核心评价指标)。
2. 宏平均(Macro-F1)与微平均(Micro-F1)
-
Macro-F1:对所有类别的 F1 值取算术平均,不考虑类别样本数量差异;
-
Micro-F1:将所有类别的 TP、FP、FN 合并计算 P 和 R,再求 F1,受样本量大的类别影响更大;
-
适用场景:类别样本不均衡时,Micro-F1 更能反映整体性能,Macro-F1 更关注小众类别的表现。
五、进阶拓展与问题解决
1. 实体标签重叠问题
(1)问题描述
同一文本片段可能属于多个实体类型(如 “北京博物馆” 既是 “地点” 也是 “机构”):
- 输入:“我周末去了北京博物馆看展览”;
- 地点标注:北 / B 京 / E 博 / O 物 / O 馆 / O(简化);
- 机构标注:北 / B 京 / M 博 / M 物 / M 馆 / E。
(2)解决方案
- 独立模型法:为每种实体类型训练单独的序列标注模型,避免标签冲突;
- 生成式模型法:直接生成实体及其类型,而非依赖标签序列,从根源上解决重叠问题。
2. 事件抽取(序列标注的高阶应用)
事件抽取是 “结构化信息提取” 任务,核心是从文本中识别事件(如地震、融资、夺冠)及相关要素(角色),本质是基于序列标注的复杂扩展。
(1)核心概念
- 触发词(Trigger):触发事件的核心词(如 “地震”“融资”);
- 事件类型(Event Type):事件的具体类别(如 “灾害 / 意外 - 地震”“财经 / 交易 - 融资”);
- 事件角色(Argument Role):事件的组成要素(如 “时间”“地点”“融资方”“融资金额”)。
(2)示例
输入文本:“泰安今早发生 2.9 级地震!靠近这个国家森林公园”事件抽取结果:
{
"event_list": [
{
"trigger": "地震",
"trigger_start_index": 10,
"class": "灾害/意外",
"event_type": "灾害/意外-地震",
"arguments": [
{"role": "时间", "argument": "今早", "argument_start_index": 2}
]
}
]
}(3)常见事件类型与角色
| 类别 | 事件类型 | 核心角色 |
|---|---|---|
| 财经 / 交易 | 融资 | 时间、融资方、融资金额、融资轮次、领投方 |
| 产品行为 | 发布 | 时间、发布方、发布产品 |
| 交往 | 会见 | 时间、地点、会见主体、会见对象 |
| 竞赛行为 | 夺冠 | 时间、冠军、夺冠赛事 |
3. 远程监督(弱监督标注方法)
(1)核心假设
若知识库中两个实体存在某种关系,则所有提及这两个实体的句子都表达该关系。
(2)流程
知识库中的实体对 → 检索包含该实体对的语料 → 自动标注为 “表达该关系” 的样本 → 用于训练序列标注模型;
(3)优势
解决标注数据稀缺问题,降低人工标注成本,适用于关系抽取、NER 等任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)