Spring Boot集成Ollama实战
一、前言:为什么这篇文章能帮你落地企业级 AI 应用?
在 AI 原生应用开发中,开发者常面临三大痛点:「第三方 API 成本高、数据隐私泄露风险」「自建大模型部署复杂、资源消耗惊人」「集成后响应慢、稳定性差」。Ollama 的出现打破了这一僵局 —— 它支持一键部署 Llama 3、Qwen、Mistral 等主流模型,本地运行无需依赖第三方服务器,数据安全性拉满,且资源占用可控(8B 模型仅需 8GB 内存)。
本文基于企业级 AI 内容分析系统实战经验,不仅覆盖 Spring Boot 与 Ollama 的基础集成,更深度拆解「流式响应、模型动态切换、缓存优化、高可用部署」等核心难点,配套完整代码、压测报告、生产环境配置、问题排查手册。无论你是想给现有系统新增 AI 能力,还是从零搭建本地 AI 服务,都能直接落地,真正实现「低成本、高安全、高性能」的 AI 功能集成。
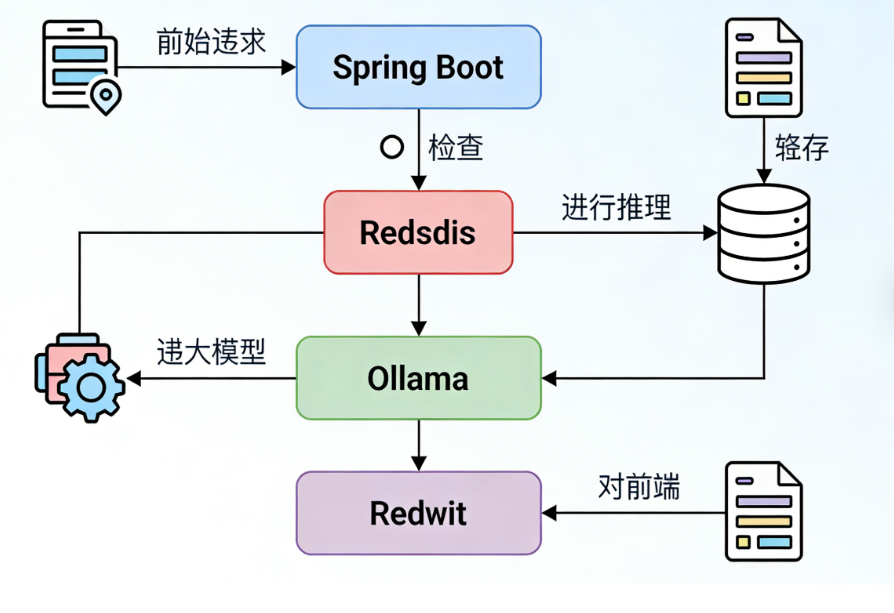
二、核心原理:Spring Boot 与 Ollama 的通信逻辑(深度拆解)
Ollama 的核心优势在于「轻量部署 + 标准化 API」,Spring Boot 与 Ollama 的交互本质是「HTTP 协议的请求 - 响应模型」,但企业级应用需关注两个关键细节:
2.1 通信流程拆解(时序图 + 核心端点)
Ollama 提供三大核心 API 端点(企业级开发必备):
- /api/generate:生成文本(支持流式响应,适合长文本分析)
- /api/chat:对话交互(支持上下文关联,适合客服机器人)
- /api/models:模型管理(查询本地已加载模型、删除模型)
2.2 流式响应原理(解决长文本分析卡顿问题)
传统的「完整响应模式」会导致前端长时间等待(长文本分析可能耗时 10 + 秒),用户体验极差。Ollama 支持SSE(Server-Sent Events)流式响应,即大模型推理出部分结果后立即返回,前端实时渲染,响应延迟从「秒级」降至「毫秒级」。
流式响应的核心逻辑:Ollama 的/api/generate端点在请求头中设置Accept: text/event-stream,返回的是逐行的文本流(而非一次性 JSON),Spring Boot 需通过「响应式编程(WebFlux)」解析流数据并推送给前端。
三、环境准备:本地大模型运行条件(优化配置 + 兼容性说明)
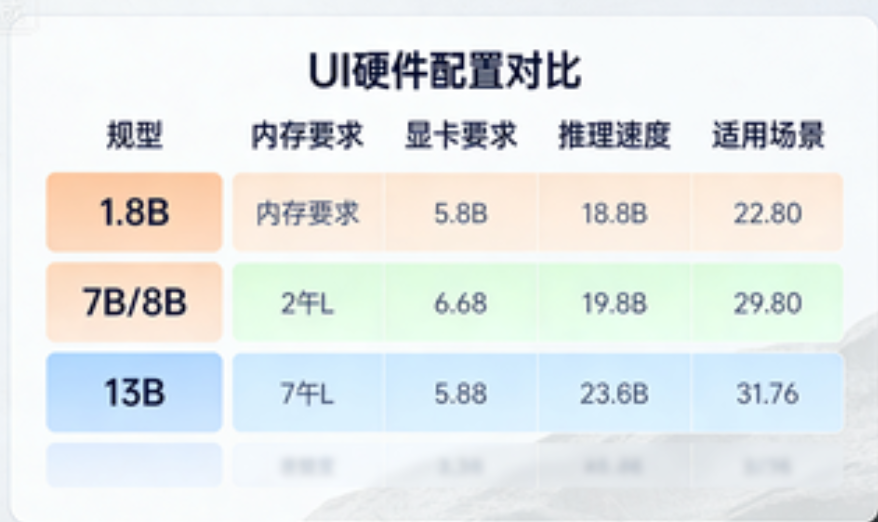
3.1 硬件要求(量化 + 优化建议)
|
模型规格 |
内存要求 |
显卡要求(可选) |
推理速度(参考) |
适用场景 |
|
1.8B(如 qwen:1.8b) |
≥4GB |
无(CPU 即可) |
短文本分析≈1 秒 |
轻量场景、资源有限设备 |
|
7B/8B(如 llama3:8b) |
≥8GB |
NVIDIA GTX 1660+(CUDA 加速) |
短文本分析≈3 秒 |
通用场景、中小规模应用 |
|
13B(如 mistral:13b) |
≥16GB |
NVIDIA RTX 3060+ |
短文本分析≈5 秒 |
高精度场景、企业级应用 |
优化建议:
- 有 NVIDIA 显卡的用户:安装 CUDA Toolkit(11.8+),Ollama 会自动启用 GPU 加速,推理速度提升 3-5 倍;
- 无显卡用户:启用 CPU 多线程推理(后续代码中配置),速度可提升 20%;
- 内存紧张用户:使用ollama run model:size-q4_0(量化模型),内存占用减少 50%(如 llama3:8b-q4_0 仅需 4GB 内存)。
3.2 软件安装与验证(批量模型加载 + 状态检查)
- 安装 Ollama:
-
- 验证安装:终端执行ollama --version,显示版本号(如ollama version 0.1.38)即安装成功。
- 批量加载模型(企业级必备):
新建models.txt文件,写入需加载的模型名称,执行批量下载脚本:
# Windows(PowerShell)
Get-Content models.txt | ForEach-Object { ollama pull $_ }
# macOS/Linux(Shell)
cat models.txt | xargs -I {} ollama pull {}
models.txt示例(兼顾轻量与高精度):
llama3:8b
qwen:1.8b
mistral:7b-instruct
llama3:8b-q4_0 # 量化模型(内存友好)
- 验证 Ollama 服务状态:
-
- 启动服务:ollama serve(后台运行,默认端口 11434;Windows 可通过任务管理器确保进程运行);
-
- 检查模型:浏览器访问http://localhost:11434/api/models,返回本地模型列表(示例如下)即正常:
{
"models": [
{"name": "llama3:8b", "modified_at": "2024-05-20T10:30:00Z", "size": 4294967296},
{"name": "qwen:1.8b", "modified_at": "2024-05-20T10:35:00Z", "size": 985661440}
]
}
-
- 测试推理:终端执行以下命令,返回结果即服务可用:
curl http://localhost:11434/api/generate -d '{
"model":"llama3:8b",
"prompt":"提取关键词:Spring Boot集成Ollama实现本地AI分析",
"stream":false
}'
- Spring Boot 项目初始化(完整依赖清单):
核心依赖(pom.xml):
.0" encoding="UTF-8"?>
maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
.0.0Version>
>
.springframework.boot -starter-parent
.2.5>
/> -->
.example ai-demo
.0.1-SNAPSHOT -ai-demo>
Spring Boot集成Ollama本地大模型实战>
17
-->
.boot arter-web 流式响应必备) -->
<groupId>org.springframework.boot</groupId>
>spring-boot-starter-webflux </dependency>
JSON解析 -->
<dependency>
>com.fasterxml.jackson.core</groupId>
>jackson-databind </dependency>
Lombok简化代码 -->
</groupId>
<artifactId>lombok>
true </dependency>
缓存(提升重复请求性能) -->
<dependency>
>org.springframework.boot
-boot-starter-cache>
</groupId>
<artifactId>spring-boot-starter-data-redis
</groupId>
<artifactId>spring-boot-starter-test <scope>test>
</groupId>
<artifactId>spring-boot-starter-validation 环境排查问题) -->
ash.logback
stash-logback-encoder</artifactId>
<version>7.4</version>
>
>
<groupId>org.springframework.boot</groupId>
>spring-boot-maven-plugin</artifactId>
<configuration>
cludes>
>
.projectlombok
ombok </exclude>
</excludes>
</configuration>
>
四、核心代码实现(企业级特性 + 设计模式)
4.1 项目配置(多环境配置 + Redis 缓存 + 日志配置)
4.1.1 核心配置(application.yml)
spring:
application:
name: ollama-ai-demo
# Redis缓存配置(用于缓存重复分析请求)
redis:
host: localhost
port: 6379
password: "" # 若Redis有密码请填写
timeout: 5000
lettuce:
pool:
max-active: 8 # 最大连接数
max-idle: 8 # 最大空闲连接
min-idle: 2 # 最小空闲连接
cache:
type: redis
redis:
time-to-live: 3600000 # 缓存过期时间(1小时,可根据业务调整)
cache-null-values: false # 不缓存null值
use-key-prefix: true # 启用缓存键前缀(避免键冲突)
key-prefix: "ai:" # 缓存键前缀
# 多环境激活(开发/生产)
spring.profiles.active: dev
# Ollama核心配置
ollama:
base-url: http://localhost:11434
default-model: llama3:8b # 默认模型
timeout: 60000 # 超时时间(60秒,长文本分析需延长)
# 支持的模型列表(前端可下拉选择)
support-models:
- name: Llama 3(8B,通用首选)
code: llama3:8b
- name: 通义千问(1.8B,轻量快速)
code: qwen:1.8b
- name: Mistral(7B,高精度)
code: mistral:7b-instruct
- name: Llama 3(8B量化,内存友好)
code: llama3:8b-q4_0
# 流式响应配置
stream:
enabled: true # 全局默认启用流式响应
buffer-size: 1024 # 流缓冲区大小(字节)
# 日志配置(生产环境打印详细日志)
logging:
level:
root: INFO
com.example.ollama: DEBUG # 本项目包日志级别
org.springframework.web: INFO
reactor.netty: INFO
pattern:
console: "%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n"
file: "%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n"
file:
name: logs/ollama-ai-demo.log # 日志文件路径
4.1.2 开发环境配置(application-dev.yml)
server:
port: 8080
servlet:
context-path: /
tomcat:
max-threads: 100 # 开发环境无需过多线程
min-spare-threads: 10
# 开发环境关闭缓存(便于调试)
spring:
cache:
type: none
4.1.3 生产环境配置(application-prod.yml)
server:
port: 80
servlet:
context-path: /ai-service # 生产环境接口前缀
tomcat:
max-threads: 200 # 最大线程数(根据CPU核心数调整,建议CPU核心数*2+1)
min-spare-threads: 20
max-connections: 10000 # 最大连接数
connection-timeout: 20000 # 连接超时时间(20秒)
# 生产环境日志滚动配置
logging:
logback:
rollingpolicy:
max-file-size: 100MB # 单个日志文件最大大小
max-history: 30 # 日志保留30天
total-size-cap: 10GB # 日志总大小限制
4.2 实体类优化(支持流式响应 + 结构化结果)
package com.example.ollama.entity;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
/**
* Ollama请求实体(支持完整响应/流式响应切换)
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@JsonIgnoreProperties(ignoreUnknown = true) // 忽略未知字段,提高兼容性
public class OllamaRequest {
private String model; // 模型编码(如llama3:8b)
private String prompt; // 指令+待分析文本
private Options options; // 推理参数
private Boolean stream = true; // 是否启用流式响应(默认开启)
/**
* 推理参数优化(企业级配置)
*/
@Data
public static class Options {
private Float temperature = 0.6f; // 随机性(0-1,生产环境建议0.6,平衡稳定性和灵活性)
private Integer num_predict = 2048; // 最大响应长度(支持长文本分析)
private Integer num_thread = Runtime.getRuntime().availableProcessors(); // CPU线程数(自动适配硬件)
private Float top_p = 0.9f; // 采样阈值(过滤低概率词汇,提升结果质量)
private Integer seed = 42; // 随机种子(固定种子可让结果可复现,便于测试)
}
}
/**
* Ollama完整响应实体(非流式)
*/
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public class OllamaCompleteResponse {
private String model;
private String created_at;
private String response; // 完整响应文本
private Boolean done;
private Metrics metrics; // 推理性能指标
@Data
public static class Metrics {
private Integer prompt_eval_count; // 输入token数
private Integer prompt_eval_duration; // 输入处理耗时(毫秒)
private Integer eval_count; // 输出token数
private Integer eval_duration; // 输出处理耗时(毫秒)
}
}
/**
* Ollama流式响应实体(逐行解析)
*/
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public class OllamaStream

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)