Olmo3论文精读
整个管线极度依赖高质量数据工程(olmOCR、合成数据、微退火筛选)。将训练拆解为 Pretrain -> Midtrain -> LongContext -> SFT -> DPO -> RL,每个阶段都有明确的目标和特定的数据配比。大规模应用基于规则验证(如代码执行、数学答案匹配)的强化学习(RLVR),这是提升推理能力的关键。提供了复现上述所有步骤所需的工具链(Olmo-core, Olmo
Olmo3论文精读

这篇论文介绍的是 Olmo 3,这是由艾伦人工智能研究所(Ai2)及其合作团队发布的最新一代 完全开放(Fully Open) 的语言模型家族。
Olmo 3 包含 7B 和 32B 两种参数规模,并在多个基准测试中达到了 SOTA(State-of-the-Art)水平,性能优于 Llama 3.1-8B、Qwen 2.5-32B 等开源权重模型。
其最大的亮点在于 “全流程开源(Full Model Flow)” :团队不仅发布了模型权重,还开源了从预训练到后训练的完整生命周期,包括所有数据(Dolma 3/Dolci)、中间检查点、训练代码(Olmo-core/OlmoRL)、数据处理工具及评估套件。
🌹🌹🌹Olmo 3 总体效果🌹🌹🌹
整个阶段
Think模型~32B
Base模型~32B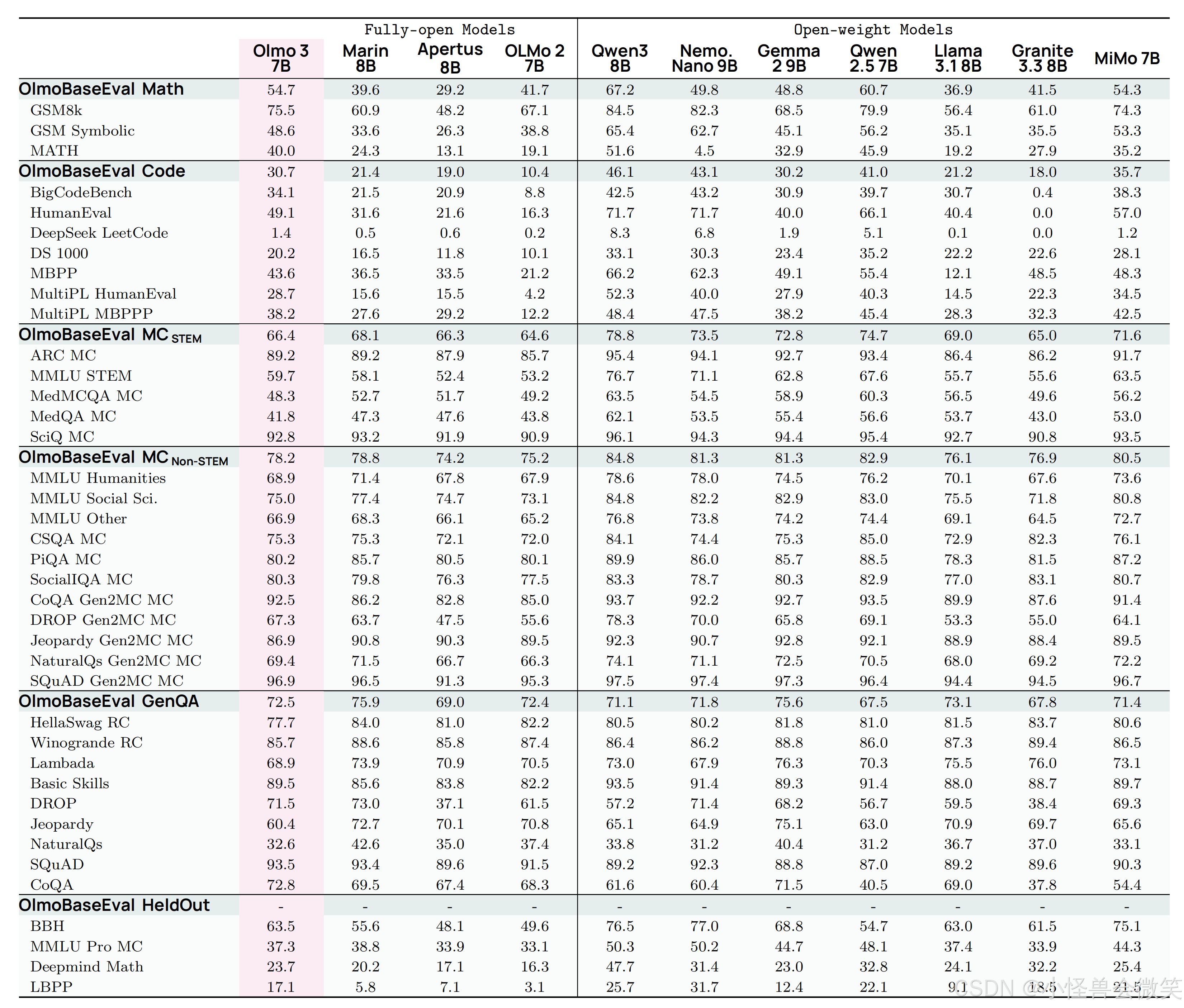
Base模型~7B
🌹🌹🌹Olmo 3 总体技术管线🌹🌹🌹
Olmo 3 的开发流程设计非常精细,分为两大阶段:基础模型训练(Base Model Training)和后训练(Post-training)。后训练阶段又根据目标能力分化为三条路径:Think(推理)、Instruct(指令/工具)和 RL-Zero。

第一阶段:基础模型训练 (Base Model Training)
这一阶段旨在构建一个通用的、高质量的底座模型。分为三个子阶段,数据课程设计层层递进:
1. 预训练 (Pretraining)
- 目标: 获取广泛的世界知识和语言能力。
- 数据: Dolma 3 Mix (约 6T tokens)。
- 核心创新:
- olmOCR: 为了解决学术 PDF 数据质量差的问题,团队开发了
olmOCR工具,将大量科学论文 PDF 转换为高质量的 Markdown 文本。 - 去重与上采样: 使用了名为
Duplodocus的工具进行全局去重,并采用“质量感知上采样(Quality-Aware Upsampling)”策略,对高质量数据(如数学、代码)进行高倍率重复训练,而非简单的过滤。
- olmOCR: 为了解决学术 PDF 数据质量差的问题,团队开发了
- 核心创新:
- 训练设施: 使用
Olmo-core框架,在 H100 集群上训练,利用了 PyTorch FSDP2 等技术优化吞吐量。
2. 中期训练 (Midtraining)
- 目标: 在预训练结束后,通过高质量数据“退火(Annealing)”,针对性提升数学、代码、问答和推理能力,为后训练打基础。
- 数据: Dolma 3 Dolmino Mix (100B tokens)。
- 策略: 采用了**“微退火(Microannealing)”**实验方法。即先在小规模数据上进行快速实验,验证某个特定数据源(如合成的数学题)是否能提升特定能力,然后再将其整合进大的混合数据中。
- 内容: 包含大量的合成数学数据(如 TinyMATH)、代码数据、以及为了“思考”模型准备的思维链(CoT)数据。
- 去污(Decontamination): 在此阶段引入了严格的去污流程,移除与评估集重叠的数据,以确保评测的真实性。
3. 长上下文扩展 (Long-context Extension)
- 目标: 将上下文窗口从 8K 扩展到 64K。
- 数据: Dolma 3 Longmino Mix (50B-100B tokens)。
- 主要使用处理过的长篇科学 PDF 和书籍。
- 技术: 使用 YaRN (Yet another RoPE for Non-uniform scaling) 技术处理位置编码,并采用文档打包(Document Packing)策略来提高训练效率。
第二阶段:后训练 (Post-training)
在 Base 模型基础上,Olmo 3 分化出三条不同的训练路径,使用 Dolci 数据集套件。
路径 A:Olmo 3 Think (旗舰推理模型)
这是 Olmo 3 的核心,旨在通过生成内部思维链(Thinking Process)来解决复杂问题。
- 监督微调 (SFT): 使用 Dolci Think SFT 数据集。包含大量长思维链的合成数据(如数学证明、代码解释)。
- 偏好优化 (DPO): 使用 Dolci Think DPO。
- Delta Learning (增量学习): 这是一个关键策略。团队发现,如果在 SFT 后继续用高质量数据微调效果不佳。因此,他们构建了具有明显 “能力差(Capability Delta)” 的偏好对:让一个强模型(如 Qwen-32B)生成“胜出”回答,让一个弱模型(如 Qwen-0.6B)生成“拒绝”回答。这种巨大的质量差异能给模型提供更强的学习信号。
- 强化学习 (RLVR - OlmoRL): 使用 Dolci Think RL。
- 核心: 带有 可验证奖励(Verifiable Rewards) 的强化学习。主要针对数学(答案唯一)、代码(通过测试用例)和指令遵循(满足约束)等领域。
- 算法: 改进版的 GRPO 算法,通过
OlmoRL框架实现高效的异步训练。
路径 B:Olmo 3 Instruct (通用对话模型)
侧重于简洁性、工具调用(Function Calling)和用户交互,不输出冗长的思维链。
- SFT: 引入了专门的工具调用数据(如 Web 搜索、科学问答)。
- DPO: 引入了长度控制(Length Control)。为了防止模型变得过于啰嗦(这是 DPO 的常见副作用),在偏好数据中惩罚过长的回复,确保模型输出简洁。
- RL: 同样使用 RLVR,但侧重于指令遵循和通用对话质量(使用 LLM 作为裁判)。
路径 C:Olmo 3 RL-Zero
- 这是一个实验性路径,旨在探索从 Base 模型直接进行强化学习(跳过 SFT/DPO)的可能性,类似于 DeepSeek R1-Zero 的思路。
- 提供了一个纯净的、去污的基准环境,供社区研究 RL 算法。
总结:关键技术特点
- 数据为王: 整个管线极度依赖高质量数据工程(olmOCR、合成数据、微退火筛选)。
- 分阶段优化: 将训练拆解为 Pretrain -> Midtrain -> LongContext -> SFT -> DPO -> RL,每个阶段都有明确的目标和特定的数据配比。
- 可验证的 RL: 大规模应用基于规则验证(如代码执行、数学答案匹配)的强化学习(RLVR),这是提升推理能力的关键。
- 全栈开源: 提供了复现上述所有步骤所需的工具链(Olmo-core, OlmoRL, Dolma3, Dolci)。
🌹🌹🌹Olmo 3 预训练详解🌹🌹🌹
在 Olmo 3 的 基础模型训练(Base Model Training) 中,预训练(Pretraining) 是消耗算力最多(超过 90%)、最关键的第一阶段。
这一阶段的核心目标是构建一个名为 Dolma 3 Mix 的数据集,总计约 5.93 万亿 (5.93T) token。
以下是关于数据来源、分布、清洗管线、验证方法及核心创新的详细技术拆解:
1. 数据来源与分布 (Data Sources & Distribution)
Olmo 3 的预训练数据并非简单地将所有数据混合,而是经过了精细的配比。虽然数据池(Pool)总量接近 10T,但最终训练使用的 Mix(混合数据)约为 6T。
具体分布如下表所示:
| 数据来源 (Source) | 类型 | 最终混合占比 (6T Mix) | 说明 |
|---|---|---|---|
| Common Crawl | 网页文本 | 76.1% (4.51T) | 经过极度严格去重和质量筛选的网页。 |
| olmOCR Science PDFs | 学术文献 | 13.6% (805B) | 核心创新。通过视觉模型转录的 PDF,包含大量高质量科学知识。 |
| StackEdu | 代码 | 6.9% (409B) | GitHub 代码,经过重新平衡和教育价值筛选。 |
| FineMath 3+ | 数学网页 | 2.6% (152B) | 包含数学公式的高质量网页。 |
| arXiv | 论文源码 | 0.9% (50.8B) | 保留了 LaTeX 格式的论文源码。 |
| Wikipedia & Wikibooks | 百科全书 | 0.04% (2.5B) | 基础百科知识。 |
2. 核心技术创新 (Core Innovations)
Olmo 3 在预训练阶段引入了三项关键技术创新:
- olmOCR 科学文献转录: 传统的 PDF 提取工具(如 pdftotext)会破坏排版和公式。团队开发了基于视觉语言模型(VLM)的工具
olmOCR,将 PDF 直接转换为高质量的 Markdown 文本,保留了复杂的科学符号和结构。 - Duplodocus 全局去重工具: 开发了基于 Rust 的工具
Duplodocus,能够在万亿 token 规模上进行快速、可扩展的全局去重。 - 质量感知上采样 (Quality-Aware Upsampling): 改变了以往“过滤掉低质量数据”的简单做法,转而采用“对高质量数据进行不同倍率的重复采样”策略(详见下文)。
3. 数据清洗管线 (Data Cleaning Pipeline)

数据清洗流程极其复杂,特别是针对占比最大的 Common Crawl (Web) 数据,主要包含以下步骤:
A. 文本提取与启发式过滤 (Extraction & Heuristic Filtering)
- 提取: 使用 Resiliparse 去除 HTML 标签。
- 过滤: 应用 URL 阻断列表(色情/垃圾邮件)、长度过滤、符号比例过滤等。
- 语言识别: 使用 fastText 保留英文文档。
- Madlad-400 规则: 应用特定的句子级规则(如去除含大量大写单词的句子)。
- 结果: 这一步删除了原始池中约 84.6% 的文档。
B. 多级去重 (Deduplication) - 关键步骤
为了实现极致的 token 效率,采用了三级去重策略:
- 精确去重 (Exact Deduplication): 基于文档哈希值,删除完全相同的副本。删除了剩余数据的 66%。
- 模糊去重 (Fuzzy Deduplication): 使用 MinHash 算法识别内容高度相似的文档(如只有页眉页脚不同的网页),保留最新日期的版本。删除了剩余数据的 23%。
- 子串去重 (Substring Deduplication): 使用模糊后缀数组 (Fuzzy Suffix Array) 方法。这是为了删除文档内部重复出现的“样板文本”(如网站导航栏、版权声明),即使它们在不同文档中夹杂了少量不同字符也能被识别。删除了 14% 的文本字节。
C. 质量分类与上采样 (Classification & Upsampling)
- 分类: 使用
WebOrganizer工具将数据分为 24 个主题(如科技、政治、医学),并训练了一个 fastText 质量分类器打分。 - 上采样策略(Quality-Aware):
- 传统做法: 设置一个质量阈值,切掉阈值以下的数据(Flat Filtering)。
- Olmo 3 做法: 发现与其切掉数据,不如重复高质量数据效果更好。他们设计了一个上采样曲线(Upsampling Curve):质量最高的 5% 数据会被重复训练 7次,而低质量数据只训练 1 次或丢弃。

4. 验证:怎么知道清洗得好不好? (Validation)
在动用数千张 GPU 训练 7B/32B 模型之前,团队必须验证数据配比和清洗策略是否有效。他们采用了 “蜂群(Swarm)”实验方法:
- 代理模型 (Proxy Models): 训练大量小规模模型(如 30M 参数,训练 3B token),每个模型使用不同的数据混合比例(从狄利克雷分布中采样)。
- 评估套件 (Base Easy Suite): 由于小模型在复杂的基准测试(如 MMLU)上通常只有随机表现,无法区分优劣,团队构建了一个 Base Easy Suite。
- 这个套件不看准确率,而是看Bits-per-byte (BPB) 或困惑度(Perplexity)。
- 验证相关性: 团队证明了小模型在 Base Easy 上的 BPB 分数与大模型在 Base Main(正式榜单)上的表现有极强的相关性。
- 回归分析: 根据这些小模型的表现,拟合一个广义线性模型,预测哪种数据混合比例(Mix)能带来最低的 Loss。
- 结论验证:
- 实验证明,质量感知上采样比传统的“切除低分数据”策略在受限数据下表现更好(Table 36)。
- 优化后的混合比例在所有指标上都优于数据的自然分布(Table 35)。
通过这套严密的 “清洗 -> 去重 -> 上采样 -> 小模型验证 -> 回归预测” 的管线,Olmo 3 确保了在正式预训练时使用的是最高效、信息密度最高的数据组合。
🌹🌹🌹Olmo 3 中期训练详解🌹🌹🌹
Olmo 3 的 中期训练(Midtraining) 阶段是衔接大规模预训练(Pretraining)与特定能力后训练(Post-training)的关键环节。这一阶段不再追求数据的广度,而是通过约 1000 亿 (100B) token 的高质量数据进行“退火”训练,旨在提升模型的特定领域能力并为后续阶段打下基础。
以下是该阶段的详细复述,包括数据构成、目标、清洗策略及验证方法:
1. 目标 (Goals)
中期训练主要有两个核心目标:
- 能力注入: 针对性地大幅提升代码(Code)、数学(Math)以及通用问答(QA)的能力。
- 为后训练铺路: 提前引入指令(Instruction)和思维链(Thinking Traces)数据,降低后续监督微调(SFT)和强化学习(RL)阶段的学习难度。
2. 数据分布与来源 (Data Distribution & Sources)
中期训练使用的是 Dolma 3 Dolmino Mix,这是一个包含大量合成(Synthetic)和重写(Rewrite)数据的高密度混合集。具体分布如下:

| 领域 (Domain) | 占比 | 典型数据源与处理方式 |
|---|---|---|
| 数学 (Math) | ~19% | - TinyMATH:合成题 + 代码解法 - CraneMath:用 Qwen 重写 FineMath 以规避 Llama 协议 - Dolmino Math:Olmo2 的数学数据 |
| 代码 (Code) | ~20% | - StackEdu (FIM):带填空任务的 GitHub 代码 - CraneCode:用 Qwen 重写 Stack-v2 的 Python 代码 |
| 问答 (QA) | ~14% | - Reddit-to-Flashcards:将 Reddit 讨论合成为多选题 - Wiki-to-RCQA:基于维基百科的阅读理解合成 - Nemotron QA |
| 思维链 (Thinking) | ~6% | - Meta-Reasoning:针对自我反思、回溯等元认知能力的合成数据 - Program-Verifiable:可通过程序验证结果的推理题 - 现有思维链数据(如 OpenThoughts) |
| 指令 (Instruction) | ~6% | - Tulu 3 SFT:指令微调数据 - Flan |
| 通用正则化 (Regularization) | ~32% | - 高频采样的高质量 Web 数据和 olmOCR PDF 数据 目的:防止模型在专注于特定领域时遗忘通用语言能力(灾难性遗忘) |
3. 数据清洗与处理 (Data Cleaning & Processing)

中期训练的数据处理非常注重合规性、格式纯净度和去污:
- 许可合规性重写 (Licensing Rewrites):
- 团队发现许多开源的高质量合成数据(如 SwallowMath)是基于 Llama 生成的,受限于非商业许可。为了保持“完全开放”,他们使用 Qwen 3 等模型重新生成了这些数据(如 CraneMath 和 CraneCode),在保证质量的同时解决了版权问题。
- 特殊 Token 处理 (Special Token Handling):
- 实验发现,如果在中期训练就引入 Chat 模板的特殊 Token(如
<|im_start|>),模型会在推理时不受控地输出这些 Token,导致性能崩塌。 - 解决方案:删除所有指令数据中的特殊 Token 和 Chat 模板,仅保留纯文本格式(如用换行符分隔),将格式学习留给 SFT 阶段。
- 实验发现,如果在中期训练就引入 Chat 模板的特殊 Token(如
- 严格去污 (Decontamination):
- 由于中期训练旨在提升基准测试能力,数据泄露风险极高。团队实施了严格的 N-gram 匹配去重。
- 范围:针对所有评估基准的 所有拆分(Train/Val/Test) 进行去重。不仅仅是测试集,因为开发过程中会用到验证集,泄露会误导决策。
4. 验证方法:如何证明清洗和配比是好的? (Validation)
Olmo 3 采用了一套双环验证机制来确保数据质量和混合比例的有效性:
-
微退火 (Microannealing) —— 快速验证单点数据:
- 操作:抽取 50亿 (5B) 目标新数据(例如新合成的数学题),与 50亿 (5B) 通用 Web 数据混合。
- 训练:在基础模型上进行短时间的“退火”训练(共 10B token)。
- 对比:将训练后的模型与 “仅使用 10B Web 数据退火” 的基线模型进行对比。
- 标准:如果模型在目标能力(如 Math)上有显著提升,且在通用能力(如 MMLU)上没有严重下降,则该数据源被视为有效。
-
集成测试 (Integration Tests) —— 验证整体混合效果:
- 将通过微退火验证的多个数据源组合成完整的 100B 混合数据。
- 进行完整的训练,并评估模型在所有基准上的表现,以及其后训练潜力(Post-trainability)(即后续微调的效果)。
- 团队进行了 5 轮大的集成测试,每一轮都根据反馈调整了数据配比。
5. 关键实验发现 (Key Findings)
- 领域权衡 (Trade-offs):实验表明,过度增加数学和代码数据的权重会导致通用问答(QA)能力下降;反之亦然。最终的混合比例是在多次实验后找到的平衡点。
- 模型汤 (Model Souping):在中期训练结束时,团队发现将两个不同随机种子(Seed)训练出的中期检查点进行权重平均(Model Souping),可以显著提升 32B 模型在 GSM8K 和 MMLU 上的表现。因此,发布的最终模型实际上是两个中间模型的融合体。
- 去污验证:为了证明去污有效,团队在 RL-Zero 阶段进行了“虚假奖励(Spurious Reward)”实验。如果模型通过数据泄露记住了答案,即便给它随机奖励,分数也会上升。实验结果显示分数没有上升,证明模型没有作弊。
🌹🌹🌹Olmo 3 长文本扩展训练详解🌹🌹🌹
Olmo 3 的 长文本扩展(Long-context Extension) 阶段(即 Stage 3)旨在将模型的上下文窗口从预训练和中期训练时的 8,192 (8K) token 扩展到 65,536 (64K) token。
这一阶段不仅是简单的增加序列长度,而是涉及了专门的数据合成、独特的数据混合策略以及特定的训练技术。
以下是该阶段的技术细节拆解:
1. 核心技术方案 (Technologies & Recipe)
Olmo 3 在长文本训练中采用了一套经过消融实验验证的“最佳实践组合”:
- YaRN 位置编码扩展:
- 技术: 使用 YaRN (Yet another RoPE for Non-uniform scaling) 方法来扩展 RoPE 位置编码。
- 策略: Olmo 3 采用了滑动窗口注意力(SWA)架构(每4层中有3层是 SWA,1层是全注意力)。关键发现是:仅在全注意力层(Full Attention Layers)应用 YaRN,而不调整 SWA 层的位置嵌入,效果最好。
- 最佳适配文档打包 (Best-fit Document Packing):
- 问题: 传统的“拼接后切分”方法会导致长文本被截断,使得训练样本平均长度短于实际文档长度。
- 方案: 采用“最佳适配打包(Best-fit Packing)”策略,将多个文档组合到一个序列中,尽量减少填充(Padding)并保留文档完整性。实验证明这比朴素拼接显著提升了长文性能。
- 配套技术: 配合文档内掩码(Intra-document Masking),防止同一序列中不同文档之间的注意力相互干扰。
- 分布式训练基础设施:
- 使用 8路上下文并行(Context Parallelism, CP),结合 Ring Attention 策略,使得每个 GPU 处理 8K token,从而支持 64K 的总序列长度。
2. 数据来源与分布 (Data Sources & Distribution)
这一阶段使用的数据集称为 Dolma 3 Longmino Mix,总计约 6000 亿 (600B) token 的池子,但在实际扩展训练中,7B 模型使用了 50B,32B 模型使用了 100B。
数据分布采用 34% 长文本数据 + 66% 短文本数据 的混合策略,以防止模型在学习长文时遗忘短文能力。
具体长文本数据构成如下:

| 数据类型 | 来源 | 说明 |
|---|---|---|
| 合成数据 (Synthetic) | CWE & REX | 核心创新。通过 LLM 构造的“大海捞针”式聚合任务(详见下文)。 |
| 长文档 (Long Docs) | olmOCR PDFs | 分为 8K-16K, 16K-32K, 32K-64K 等多个长度桶。 |
| 短文本 (Regular) | Midtraining Mix | 占比 66%。直接复用中期训练的高质量数据(Math/Code/QA)。 |
其中,olmOCR得到的数据分布如下:
3. 数据合成与清洗 (Data Synthesis & Cleaning)
为了解决自然长文本缺乏监督信号的问题,Olmo 3 借鉴 CLIPPER 方法,生成了大量合成数据。
A. 合成数据生成管线 (Synthetic Augmentation Pipeline)
这是一套“自举(Bootstrap)”流程,即便没有现成的长文模型也能生成长文训练数据:
- 切分: 将长文档(32K-64K)切分为多个 8K-32K 的片段。
- 提取: 统计片段中的高频名词短语(TF-IDF)。
- 生成任务: 使用 OLMO 2 32B 生成两种任务:
- CWE (Common Word Extraction): 给定几个高频词,要求模型输出它们在文中出现的确切次数(考验计数和长程检索能力)。
- REX (Rewriting EXpressions): 给定某个名词短语及其上下文片段,要求模型基于上下文写一段特定风格的文字(如“像给5岁孩子解释”、“写成推特帖子”等)。
B. 数据清洗与过滤 (Filtering)
针对核心的 olmOCR PDF 数据,团队主要使用了 Gzip 压缩率 进行过滤:
- 原理: 压缩率过高通常意味着重复内容太多(信息量低),压缩率过低可能意味着乱码或噪音。
- 操作: 移除压缩率最高和最低的各 20% 数据(即只保留中间 60%)。
- 失败的尝试: 团队尝试过使用 LongPpl(长文困惑度)——即测量一个 token 在有长上下文时的困惑度下降幅度——来筛选那些真正依赖长距离依赖的文档。但在实验中,这种方法并没有超过简单的 Gzip 过滤。
4. 实验验证:如何确定这是最佳方案? (Experimental Validation)
Olmo 3 使用 RULER 基准作为开发阶段的主要指标,并使用 HELMET 作为留出的测试集。
通过在 RULER 上进行消融实验(Ablation Studies),团队得出了以下关键结论(如图 13 所示):
- 注意力缩放 (Attention Scaling): 对比了多种 RoPE 扩展方法,发现 “YaRN only on full layers”(仅在全注意力层使用 YaRN) 效果最好,优于在所有层使用 YaRN 或简单的元数据缩放。
- 数据质量 (Better Data): 实验证明,使用 olmOCR 处理的科学 PDF 训练出的长文能力,显著优于使用普通网页数据(Web Text)。
- 合成数据增强 (Synthetic Augmentation): 在自然 PDF 的基础上加入合成的聚合任务(CWE/REX),进一步提升了性能。
- 文档打包 (Document Packing): 相比于不打包(No packing),使用 Best-fit Packing 能显著提升长序列上的表现。
- 训练时长 (Token Budget): 长文本训练越久越好。从 10B 增加到 50B/100B,RULER 分数(尤其是 32K/64K 长度)有明显提升。
5. 模型汤 (Model Souping)
与中期训练类似,在长文本训练结束时,团队将训练过程中最后三个检查点(例如 Step 10k, 11k, 11.9k)进行了权重平均(Model Souping)。这被证明能进一步提升模型的稳健性和性能。
🌹🌹🌹Olmo 3 Think模型训练详解🌹🌹🌹
Olmo 3 Think 是 Olmo 3 系列中的旗舰推理模型,其核心训练路径(Path A)旨在通过生成扩展的思维链(Thinking Traces)来显著提升模型的推理能力,使其在回答问题前能够进行深度的“思考”。
1. 核心目标 (Goal)
- 构建最强开源推理模型: 旨在打造最强的完全开放(Fully Open)推理模型。Olmo 3 Think-32B 在数学、代码、推理等基准测试上优于 Qwen 2.5-32B、Gemma 2 27B 等模型,并缩小了与 Qwen 3-32B 等顶级开源权重模型的差距,尽管其训练数据量少得多。
- 思维链生成: 训练模型在生成最终答案之前,先生成一段长思维链(Long Thinking Traces),以此来处理复杂任务。
2. 数据使用与分布 (Data Usage & Distribution)
Olmo 3 Think 的训练使用了 Dolci Think 数据集套件,针对后训练的三个阶段(SFT、DPO、RL)分别构建了专门的数据集。数据处理的pipeline如下图所示:
A. SFT 数据:Dolci Think SFT
该数据集包含大量带有详细思维链的合成数据,旨在教会模型“如何思考”。数据经过严格筛选和去污。

- 总规模: 约 177 万 条指令数据。
- 数据分布与来源:
- 数学 (Math, ~95.7万): 来源包括 OpenThoughts 3、SYNTHETIC-2 等。对于不完整的思维链,使用 QwQ-32B 重新生成完整的推理过程。
- 代码 (Code, ~66.9万): 来源包括 AceCoder、The Algorithms (Python)、Nemotron 等。使用 QwQ-32B 生成回复,并通过 GPT-4.1 生成的测试用例进行验证过滤。
- 对话与安全 (Chat & Safety, ~15.3万): 来源包括 WildChat、OpenAssistant、WildGuard 等。使用 DeepSeek R1 生成思维链。
- 精确指令遵循 (Precise IF, ~35.6万): 来源包括 Tulu 3 及其变体,增加了可验证的约束条件,并使用 QwQ-32B 生成回复。
- 科学与其它 (Science & Other, ~20.1万): 来源包括 OpenThoughts 3 Science、Aya (多语言)、TableGPT 等。
B. DPO 数据:Dolci Think DPO
该数据集用于偏好微调,核心策略是构建具有明显“能力差”的对比数据。

- 总规模: 约 20 万 条偏好对。
- 数据分布: 涵盖数学(1.9万)、代码(2.3万)、科学(2.1万)、安全(1.2万)、指令遵循(2.4万)及通用对话(4万)等。
- 构建策略 (Delta Learning): 为了产生有效的学习信号,对于同一个提示词,使用强模型(Qwen3-32B Thinking)生成“胜出(Chosen)”回答,使用弱模型(Qwen3-0.6B Thinking)生成“拒绝(Rejected)”回答。这种巨大的质量差异(Delta)被证明对提升推理能力至关重要。
C. RL 数据:Dolci Think RL
该数据集用于强化学习阶段,包含具有可验证奖励的任务。

- 总规模: 约 10.5 万 条提示词。
- 数据分布:
- 数学 (~4.4万): 来源 Open-Reasoner-Zero, DAPO-Math, OMEGA 等。
- 代码 (~2.3万): 来源 AceCoder, Klear Reasoner-Code 等。
- 指令遵循 (~3万): 来源 IF-RLVR。
- 通用对话 (~0.7万): 来源 WildChat 等,使用 LLM 作为裁判进行打分。
3. 实验方法 (Experiments)
Olmo 3 Think 采用了三阶段训练流程:SFT → \rightarrow → DPO → \rightarrow → RLVR。
-
监督微调 (SFT):
- 使用
Olmo-core框架进行训练,速度比 Open-Instruct 快 8 倍。 - 训练 2 个 epoch,通过学习率扫描和定性“体感测试(Vibe-test)”选择最佳检查点,并采用了模型汤(Model Souping)技术融合不同学习率的模型。
- 使用
-
偏好优化 (DPO):
- 引入 Delta Learning 概念。实验发现,如果在 SFT 后继续用高质量数据(Qwen3-32B 生成的 Chosen 回答)进行 SFT,模型性能反而会下降。只有通过 DPO 学习“强模型 vs 弱模型”之间的差异,才能进一步推高推理能力的边界。
-
强化学习 (RLVR with OlmoRL):

- 算法: 使用改进版的 GRPO 算法(Group Relative Policy Optimization)OlmoRL (博客后面展开讲了下),引入了 Token 级损失、截断重要性采样(Truncated Importance Sampling)等改进。
- 奖励机制:
- 数学/代码/IF: 使用可验证奖励(Verifiable Rewards),即通过代码执行或规则检查答案的正确性(二值奖励)。
- 通用对话: 使用 LLM 作为裁判打分(连续值奖励)。
- 基础设施: 实现了完全异步的训练架构、连续批处理(Continuous Batching)和 Inflight Updates,将训练速度提升了 4 倍。
4. 关键发现 (Key Findings)
- DPO 是 RL 的最佳起点: 实验对比了从 SFT 模型直接进行 RL 和从 DPO 模型进行 RL。结果显示,SFT → \rightarrow → DPO → \rightarrow → RL 的路径效果最好。DPO 模型在 RL 开始前具有更高的 Pass@K 性能,且在 RL 过程中能保持更好的稳定性,而从 SFT 直接开始 RL 往往难以达到同等水平。
- Delta Learning 至关重要: 直接对强模型生成的推理数据进行 SFT 会导致模型退化(Collapse),因为 SFT 模型已经具备了类似的能力。唯有通过 DPO 学习“好”与“差”的对比,才能在数学和代码推理上取得实质性突破。
- 混合数据防止过拟合: 在 RL 阶段,如果只针对单一领域(如 IFEval)进行训练,会导致该领域分数上升但其他能力(如 AlpacaEval)下降。使用混合数据(Math + Code + IF + Chat)进行 RL 训练,可以在提升特定能力的同时保持通用能力的稳定。
- 去污验证: 通过在 RL 阶段引入虚假奖励(随机给予奖励)进行测试,发现模型性能没有提升,从而反向证明了训练数据没有受到评估集的污染(如果泄露了,模型会通过记忆答案来获得奖励,哪怕奖励是随机的)。
🌹🌹🌹Olmo 3 Instruct模型训练详解🌹🌹🌹
Olmo 3 Instruct 是 Olmo 3 系列中的通用对话模型(路径 B),其设计初衷是服务于日常应用场景。与 Think 模型不同,它不生成内部思维链,而是专注于简洁性、工具使用(Function Calling)以及高效的用户交互。
以下是关于 Olmo 3 Instruct 的目标、训练流程、数据细节、实验及发现的详细介绍:
1. 核心目标 (Goal)
- 通用助手: 旨在快速、有帮助地回答用户的常见查询(如寻求建议、信息检索),不需要像推理模型那样进行长时间的推演。
- 工具使用 (Function Calling): 具备强大的工具调用能力,能够利用外部工具(如搜索、代码执行)来获取信息和解决问题。
- 推理效率: 通过不生成思维链(Thinking Traces),显著降低推理成本和延迟,适合大规模部署。
2. 训练流程 (Process)
Olmo 3 Instruct 同样遵循三阶段后训练流程,但在具体策略上有所调整:
-
监督微调 (SFT):
- 起点创新: 并非直接从 Base 模型开始,而是基于 Olmo 3 Think SFT 模型进行训练。这意味着 Instruct 模型继承了 Think 模型的推理能力,但被训练为直接输出答案而非思维过程。
- 数据: 使用 Dolci Instruct SFT,重点引入了工具调用和多轮对话数据。
-
偏好优化 (DPO):
- 长度控制 (Length Control): 这是一个关键差异。为了防止模型变得啰嗦(DPO 的常见副作用),在构建偏好数据时,会惩罚过长的回复,通过数据筛选限制“胜出”和“拒绝”回答的长度差(控制在 100 token 以内),强制模型学习简洁。
- 多轮交互: 引入了合成的多轮对话偏好数据,提升长对话能力。
-
强化学习 (RLVR with OlmoRL):
- 策略: 使用 Dolci Instruct RL。虽然也包含数学和代码任务,但难度较低,更侧重于指令遵循(IFEval)和通用对话质量(使用 LLM 作为裁判)。
- 选型: 在 DPO 阶段会训练多个候选模型,最终选择一个在“体感测试(Vibe Test)”和性能之间平衡最好的模型进行 RL。
3. 数据使用与分布 (Data Usage & Distribution)
Instruct 模型的数据构建非常强调工具使用和真实对话场景。

A. SFT 数据:Dolci Instruct SFT
- 工具调用数据 (Function Calling):
- 真实交互 (Real MCP): 收集了基于真实环境(MCP 服务器)的轨迹。
- Science QA: 使用 ASTA 工具查阅科学文献。
- Web Search QA: 使用 Google 搜索工具回答复杂问题。
- 模拟交互 (SimFC): 为了提高泛化性,合成了 20 万条模拟工具调用的轨迹,包含多种 API 和错误处理场景。
- 真实交互 (Real MCP): 收集了基于真实环境(MCP 服务器)的轨迹。
- 通用对话: 包含 WildChat(用户真实查询)、Tulu 3 等数据。注意,对于原本包含思维链的数据(如 OpenThoughts),在这一阶段会移除思维链,只保留最终答案。
B. DPO 数据:Dolci Instruct DPO
- 总规模: 约 215 万 条提示词(Prompt)的大型池子,涵盖数学、代码、对话、安全等。
- 偏好对构建:
- 混合信号: 结合了“Delta Learning”(强弱模型对比)和“GPT-4 判断”(LLM-as-a-judge)两种信号。实验证明两者互补效果最好。
- 多轮对话: 专门生成了多轮对话数据(Self-talk),仅针对最后一轮进行偏好标注。
C. RL 数据:Dolci Instruct RL
- 规模: 约 17 万 条数据。
- 分布: 相比 Think 模型,减少了高难度数学/代码题,增加了通用对话(Chat)和指令遵循(IF)的比例。
- IF: ~3.8万
- Code: ~2万
- Math: ~5万 (包含 Polaris, OMEGA 等)
- Chat: ~5万 (Tulu 3, WildChat)
4. 实验与关键发现 (Experiments & Findings)
-
从 Think SFT 启动至关重要: 实验对比了直接训练 Instruct SFT 和从 Think SFT 接续训练。结果显示,先学“思考”再学“指令”(Thinking SFT → \rightarrow → Instruct SFT)能显著提升性能(例如 MATH 提升 5.6 分,GSM8K 提升 3.5 分),且不会增加回复长度。这表明模型保留了内在的推理能力,只是学会了不显式输出它。

-
长度控制提升可用性与 RL 效果: 在 DPO 阶段强制进行长度控制(Length Control),虽然会导致某些对长度敏感的指标(如 AIME)分数下降,但在人工定性评估(Vibe check)中更受欢迎,因为回复更直接。更重要的是,简洁的 DPO 模型是 RL 更好的起点,RL 训练过程更稳定。

-
工具使用真实有效: 在 SimpleQA 和 LitQA2 基准上的测试表明,Olmo 3 Instruct 在使用工具后性能大幅提升。特别是在 LitQA2 上,相比 Qwen 模型(使用工具反而可能下降),Olmo 3 展现了更强的工具利用能力。

-
偏好信号的互补性: 单独使用 Delta Learning(强弱模型对比)或单独使用 GPT 裁判数据都能提升模型,但将两者结合(Delta-aware GPT-judged pairs)能取得最佳效果。

🌹🌹🌹Olmo 3 Zero-RL模型训练详解🌹🌹🌹
Olmo 3 RL-Zero 是 Olmo 3 技术管线中一条独特的、具有高度实验性质的路径(路径 C)。它与其他两条路径(Think 和 Instruct)最大的不同在于:它跳过了监督微调(SFT)和偏好优化(DPO)阶段,直接在 基础模型(Base Model) 上应用强化学习(RLVR)。
这类似于 DeepSeek R1-Zero 的思路,旨在探索仅通过强化学习激励模型涌现推理能力的极限。
以下是关于 Olmo 3 RL-Zero 的目标、流程、数据、实验及发现的详细介绍:
1. 核心目标 (Goal)
- 建立纯净的 RL 基准: 当前许多开源 RLVR 研究是基于已经过 SFT 或未公开数据的模型进行的,这导致社区难以判断性能提升是来自 RL 算法本身,还是因为模型在预训练/微调阶段已经“背过”了答案(数据污染)。Olmo 3 RL-Zero 旨在提供一个完全透明、 经过去污(Decontaminated) 的基准,供社区研究预训练数据对 RL 性能的真实影响。
- 验证基础模型潜力: 探索 Olmo 3 Base 模型是否具备足够的内在潜力,仅通过强化学习就能被激发出强大的推理能力。
2. 训练流程 (Process)
- 起点: 直接使用 Olmo 3 Base 模型。
- 提示词模板 (Prompt Template):
- 关键细节: 由于 Base 模型在预训练中几乎没见过 Chat 格式(如
<|im_start|>),直接使用复杂的 Post-train 模板效果很差。 - 策略: 采用了 “简单模板(Simple Template)” ,仅包含最基础的问题描述(例如直接输入数学问题,不加 System Prompt),这被证明对于 Base 模型更有效。
- 关键细节: 由于 Base 模型在预训练中几乎没见过 Chat 格式(如
- 算法: 使用 OlmoRL(改进版 GRPO),最大生成长度设置为 16K token,以适应长思维链。
- 去污: 对训练数据进行了针对预训练数据和评估集的双重严格去污。
3. 数据使用与分布 (Data Usage & Distribution)
使用了专门构建的 Dolci RL-Zero 数据集。
- 总规模: 相对较小,例如数学领域仅包含约 1.33 万 (13.3k) 条提示词。
- 数据分布:
- 数学 (Math): 核心部分。来源包括 DAPO-Math 和 Klear-Reasoner Math。经过了去重、非英文过滤、语义聚类筛选(每类只选一个代表),以及离线难度过滤(Offline Difficulty Filtering)——即剔除那些 Base 模型已经能 8/8 次完全做对的简单题。
- 代码 (Code) & 指令 (IF): 从 Dolci Think RL 数据集中进行子采样。
- 混合 (Mix): 创建了一个包含上述三个领域的混合数据集,用于研究多目标 RL。
4. 实验与关键发现 (Experiments & Findings)
Olmo 3 RL-Zero 进行了一系列科学性极强的实验,主要为了验证方法的有效性和数据的纯净度。
-
推理能力的涌现:
- 发现: 即使没有 SFT,Olmo 3 Base 模型在 AIME 2024/2025 等数学基准上的 Pass@1 分数在训练前几百步内急剧上升,最终得分接近那些使用了更大模型(Qwen 2.5-32B)且训练时间更长的现有研究(如 DAPO)。这证明了 Base 模型本身蕴含了强大的推理潜力,且 RL-Zero 是一种高效的激发手段。
-
去污验证 —— “虚假奖励”实验 (Spurious Rewards):
- 背景: 如果训练数据被污染(即模型见过考题),那么即便给模型随机的奖励,模型也能通过“回忆”正确答案来提高分数。
- 实验: 团队进行了一个负对照实验,给模型分配与答案正确性无关的随机二值奖励。
- 发现: 模型在所有基准上的性能保持平坦或下降,没有提升。这有力地证明了 Dolci RL-Zero 数据集是干净的,模型性能的提升完全源于学会了推理,而非记忆。
-
中期训练数据的关键作用:
- 实验: 对比了两个早期的 Base 模型,一个使用了包含丰富思维链的中期训练数据(Reasoning Mix),另一个使用不充分的数据(Insufficient Mix)。
- 发现: 使用“不充分”数据的模型在 RL 过程中无法学会生成长思维链(回复长度停滞),也学不会回溯和验证等高级认知技能。这表明 RL-Zero 的成功高度依赖于中期训练奠定的基础。
-
主动采样 (Active Sampling) 的稳定性:
- 实验: 消融了 OlmoRL 基础设施中的主动采样功能。
- 发现: 开启主动采样(持续从队列中补充非零梯度的样本)能显著降低训练 Loss 的方差,使训练过程更加稳定。
总的来说,Olmo 3 RL-Zero 不仅是一个模型,更是一个科学实验平台,它证明了在完全去污的环境下,仅靠 RL 就能从 Base 模型中激发出强大的推理能力,同时也反向验证了 Olmo 3 Base 模型在中期训练阶段的质量。
🌹🌹🌹Olmo3的评估工作详解🌹🌹🌹
OlmoBaseEval 是 Olmo 3 团队为了解决在大模型开发过程中,特别是 基础模型(Base Model) 训练阶段进行高效、可靠决策而专门构建的一套评估套件。
传统的评估基准在模型规模较小(用于快速实验)时往往只有随机表现,且噪声很大,难以指导数据配比的决策。OlmoBaseEval 的核心目标是 “计算效率(Compute-Efficient)” ,即通过小规模模型的评估结果,准确预测大规模模型的表现。
以下是关于 OlmoBaseEval 的构建思路、处理方式、验证方法及应用场景的详细介绍:
1. 构建思路与处理方式 (Methodology)
OlmoBaseEval 的构建过程包含三个关键步骤:任务聚类、缩放分析和信噪比分析。
A. 任务聚类 (Task Clustering) —— 解决任务繁杂问题

- 思路: 评估任务虽多,但很多任务测试的是相似的能力。为了使决策更具针对性(例如针对“代码能力”而不是针对某个特定数据集),团队将任务聚合为几个大的“簇(Clusters)”。
- 处理方式:
- 收集了 70 个外部开源模型在 23,000 个基准测试结果上的数据。
- 假设如果两个基准测试对模型的排名相似,则它们测试的是相似的能力。
- 使用 Ward 方差最小化(Ward’s variance-minimization) 层次聚类算法,将表现相关的任务聚在一起。
- 人工调整: 聚类后进行了少量人工干预,主要是为了统一格式(例如将所有代码执行任务放在一起),并将多选(MC)任务拆分为 STEM 和 Non-STEM。
- 结果: 最终形成了 6 个核心任务簇:MC STEM(科学多选)、MC Non-STEM(人文社科多选)、GenQA(生成式问答)、Math(数学)、Code(代码)、Code FIM(代码中间填空)。
B. 缩放分析 (Scaling Analysis) —— 解决小模型评估难问题

- 思路: 在小计算规模下(例如数据消融实验常用的 1B 模型),模型在数学和代码等困难任务上通常只有随机表现(Pass@1 接近 0),无法区分数据好坏。团队需要找到一种在小规模下就有区分度,且能预测大规模表现的“代理指标”。
- 处理方式:
- Base Easy Suite (针对小模型): 使用 Bits-per-byte (BPB) 作为指标。即计算模型对标准答案(Gold Answer)的困惑度(Perplexity)。这是一种连续指标,即使模型答不对题,也能反映其对相关知识的掌握程度。
- Base Main Suite (针对大模型): 使用标准的 Pass@1 或 准确率(Accuracy)。
- 验证: 实验证明,Base Easy Suite 在小规模下就能看到信号,且与大规模下的 Base Main Suite 表现高度相关。
C. 信噪比分析 (Signal-to-Noise Analysis) —— 解决评估波动问题

- 思路: 某些基准测试(如 BoolQ)的方差极大,模型训练过程中的微小波动会导致分数剧烈震荡,误导开发决策。
- 处理方式:
- 计算每个基准的信噪比(SNR)。
- 移除噪声任务: 彻底剔除那些二分类任务(如 BoolQ)和噪声过大的任务(如 CruxEval 虽然衡量代码能力,但因噪声太大未计入宏观平均)。
- 增加样本量: 只要计算允许,尽量使用全量测试集而非 1K 样本子集。
- 调整参数: 通过扫描温度(Temperature)和 Top-p 参数,找到既能保证分数又能稳定的生成设置(最终选定 temp=0.6, top-p=0.95)。
2. 引入的新评测基准 (New Benchmarks)
除了整合现有任务,OlmoBaseEval 还引入了几个新设计的基准:
- BasicSkills: 一组 6 个任务,用于隔离测试预训练期间的基本技能(如简单算术、字符串操作、简单逻辑),不依赖指令遵循能力。
- Gen2MC (Generative to Multiple Choice): 将生成式 QA(如 DROP, SQUAD)转换为多选题。这是为了解决生成式评估中,模型答案正确但因格式问题被判错(False Negative)的问题。
- Masked Perplexity: 针对真实聊天数据(如 WildChat)的评估。为了不让模型过度拟合聊天的“风格”而忽略内容,计算困惑度时只计算“困难 token”的损失,并屏蔽掉简单的格式 token。
3. 如何验证评测集的好坏? (Verification)
团队通过以下方式验证了 OlmoBaseEval 的有效性:
- 相关性验证: 验证了使用 Base Easy (BPB) 对小模型进行排名的结果,与这些模型变大后在 Base Main (Pass@1) 上的排名高度一致(如图 31 所示)。这证明了可以用便宜的小模型实验来指导昂贵的大模型训练。
- 信噪比 (SNR) 提升: 相比于单个基准测试,经过聚类聚合后的任务簇(Task Clusters)显示出了更高的信噪比,使得训练曲线更加平滑,更容易观察到数据干预带来的效果(如图 29 和 图 7)。
4. 在训练全流程中的应用 (Application)
OlmoBaseEval 贯穿了 Olmo 3 开发的各个环节:
-
预训练 (Pretraining) —— 数据配比决策:
- 利用 Base Easy Suite 和 蜂群(Swarm) 方法,在仅训练 3B token 的 30M 小模型上进行大量实验,快速确定最佳的数据混合比例。
- 监控模型在训练过程中是否出现了“能力涌现”的迹象。
-
中期训练 (Midtraining) —— 能力监控与迭代:
- 使用 Base Main Suite 评估 100B token 的中期训练效果。
- 通过 集成测试 (Integration Tests),量化不同数据源(如 TinyMATH, Reddit-QA)对特定能力簇(如 Math, GenQA)的具体提升和权衡(Trade-offs)。
- 例如,通过评测发现增加数学数据虽然提升了 Math 分数,但导致 GenQA 分数下降,从而指导了最终的混合比例调整。
-
去污 (Decontamination):
- 使用 OlmoBaseEval 中的所有基准测试数据(包括训练集和测试集)作为过滤源,对预训练和中期训练数据进行严格的 N-gram 去重,防止“刷榜”现象。
总结来说,OlmoBaseEval 不仅仅是一组考题,它是一套经过精心设计的 “测量工具”,使得 Olmo 3 团队能够在算力受限的情况下,对海量数据和训练策略做出科学、精准的取舍。
🌹🌹🌹OlmoRL 算法详解🌹🌹🌹
OlmoRL 的最终目标函数 J ( θ ) \mathcal{J}(\theta) J(θ) 是一个用于训练语言模型(或视觉-语言模型 vLLM)的强化学习目标函数,旨在通过模仿人类偏好来优化生成策略。其核心思想是结合了策略梯度方法与强化学习中的重要性采样和优势估计。它融合了以下关键组件:
- Token-level loss(逐token损失)
- 截断的重要性采样(Truncated Importance Sampling)
- clip-higher(高值裁剪)
- 无标准差的优势计算(No standard deviation in advantage calculation)
🔹 公式详解:(1)
J ( θ ) = 1 ∑ i = 1 G ∣ y i ∣ ∑ i = 1 G ∑ t = 1 ∣ y i ∣ min ( π ( y i , t ∣ x , y i , < t ; θ old ) π vLLM ( y i , t ∣ x , y i , < t ; θ old ) , ρ ) min ( r i , t A i , t , clip ( r i , t , 1 − ε low , 1 + ε high ) A i , t ) (1) \mathcal{J}(\theta) = \frac{1}{\sum_{i=1}^G |y_i|} \sum_{i=1}^G \sum_{t=1}^{|y_i|} \min\left( \frac{\pi(y_{i,t} \mid x, y_{i,<t}; \theta_{\text{old}})}{\pi_{\text{vLLM}}(y_{i,t} \mid x, y_{i,<t}; \theta_{\text{old}})}, \rho \right) \min\left( r_{i,t} A_{i,t},\ \text{clip}(r_{i,t},\ 1 - \varepsilon_{\text{low}},\ 1 + \varepsilon_{\text{high}}) A_{i,t} \right) \tag{1} J(θ)=∑i=1G∣yi∣1i=1∑Gt=1∑∣yi∣min(πvLLM(yi,t∣x,yi,<t;θold)π(yi,t∣x,yi,<t;θold),ρ)min(ri,tAi,t, clip(ri,t, 1−εlow, 1+εhigh)Ai,t)(1)
✅ 各符号含义
- θ \theta θ: 当前策略参数(即要优化的模型参数)
- θ old \theta_{\text{old}} θold: 上一版本的策略参数(固定不变,在PPO中常用)
- x x x: 输入(例如图像+文本提示)
- y i y_i yi: 第 i i i个样本的输出序列(响应),长度为 ∣ y i ∣ |y_i| ∣yi∣
- G G G: 所有样本的数量(可能是一个 batch 或一组候选响应)
- y i , t y_{i,t} yi,t: 第 i i i个响应中第 t t t个 token
- y i , < t y_{i,<t} yi,<t: 在时间步 t t t之前已生成的 token 序列
- π ( y i , t ∣ x , y i , < t ; θ ) \pi(y_{i,t} \mid x, y_{i,<t}; \theta) π(yi,t∣x,yi,<t;θ): 使用当前策略生成下一个 token 的概率
- π vLLM ( y i , t ∣ x , y i , < t ; θ old ) \pi_{\text{vLLM}}(y_{i,t} \mid x, y_{i,<t}; \theta_{\text{old}}) πvLLM(yi,t∣x,yi,<t;θold): 基础模型(如 vLLM)在旧参数下生成该 token 的概率
- r i , t = π ( y i , t ∣ x , y i , < t ; θ ) π ( y i , t ∣ x , y i , < t ; θ old ) r_{i,t} = \frac{\pi(y_{i,t} \mid x, y_{i,<t}; \theta)}{\pi(y_{i,t} \mid x, y_{i,<t}; \theta_{\text{old}})} ri,t=π(yi,t∣x,yi,<t;θold)π(yi,t∣x,yi,<t;θ): 重要性采样比率(Importance Sampling Ratio)
- ρ \rho ρ: 截断重要性采样的上限(truncation cap),防止极端权重影响训练稳定性
- A i , t A_{i,t} Ai,t: 第 i i i个样本、第 t t t个 token 的优势函数(Advantage)
- ε low , ε high \varepsilon_{\text{low}}, \varepsilon_{\text{high}} εlow,εhigh: 裁剪边界(clipping hyperparameters)
🔍 分析结构
这个目标函数分为两层 min 操作:
第一层:截断重要性采样
min ( π ( y i , t ) π vLLM ( y i , t ) , ρ ) \min\left( \frac{\pi(y_{i,t})}{\pi_{\text{vLLM}}(y_{i,t})},\ \rho \right) min(πvLLM(yi,t)π(yi,t), ρ)
这是为了稳定训练过程而引入的截断重要性采样(Truncated IS)。
⚠️ 注意:虽然通常我们用的是 π / π old \pi / \pi_{\text{old}} π/πold,但这里写成 π / π vLLM \pi / \pi_{\text{vLLM}} π/πvLLM,说明他们把 vLLM 视为“行为策略”(behavior policy),而不是旧策略。这可能意味着:
- vLLM 是一个预训练好的基础模型(如 Llama、Qwen 等),用来收集数据;
- 当前策略 π \pi π是我们要优化的新策略;
- 因此,使用 vLLM 的输出作为参考分布进行重要性采样。
这样做的好处是:避免从过时的旧策略中采样导致偏差,而是以更强的基础模型为准。
第二层:双重 min 控制更新幅度
min ( r i , t A i , t , clip ( r i , t , 1 − ε low , 1 + ε high ) A i , t ) \min\left( r_{i,t} A_{i,t},\ \text{clip}(r_{i,t},\ 1 - \varepsilon_{\text{low}},\ 1 + \varepsilon_{\text{high}}) A_{i,t} \right) min(ri,tAi,t, clip(ri,t, 1−εlow, 1+εhigh)Ai,t)
这是一个双层控制机制,目的是防止策略更新过大,从而提高训练稳定性。
解读:
- r i , t A i , t r_{i,t} A_{i,t} ri,tAi,t: 完整的重要性采样项乘以优势,相当于原始 PPO 中的更新项。
- clip ( r i , t , 1 − ε low , 1 + ε high ) A i , t \text{clip}(r_{i,t},\ 1 - \varepsilon_{\text{low}},\ 1 + \varepsilon_{\text{high}}) A_{i,t} clip(ri,t, 1−εlow, 1+εhigh)Ai,t: 对 r i , t r_{i,t} ri,t进行裁剪,限制其变化范围(类似 PPO 的 clipping trick)。
- 最终取两者中的较小值 → 选择更保守的更新方向
👉 这种设计被称为 “clip-higher” —— 不仅对 r i , t r_{i,t} ri,t做 clip,还让整个目标函数在两个选项之间做最小值选择,进一步抑制剧烈变化。
🔹 优势函数定义:(2)
A i , t = ( r ( x , y i ) − mean ( { r ( x , y i ) } i = 1 G ) ) (2) A_{i,t} = \left( r(x, y_i) - \text{mean}\left( \{ r(x, y_i) \}_{i=1}^G \right) \right) \tag{2} Ai,t=(r(x,yi)−mean({r(x,yi)}i=1G))(2)
关键点:
- r ( x , y i ) r(x, y_i) r(x,yi): 验证器(verifier)返回的奖励分数,表示对输出 y i y_i yi的质量评估(比如由人类标注或奖励模型给出)
- 优势 A i , t A_{i,t} Ai,t是基于组内平均奖励计算的相对奖励
- 即使不同 token 的时间步 t t t不同,所有 token 的优势都共享同一个全局优势值(因为每个响应只对应一个总奖励)
💡 为什么这样做?
- 传统 RL 中优势通常是按时间步计算的(如 GAE),但在这里,由于每个响应只有一个整体奖励,无法精确地分配到每个 token。
- 所以采用组内均值归一化的方式,使得高奖励的响应获得正优势,低奖励的获得负优势。
- 这种方式类似于 “reward shaping” 或 “relative reward” 方法,常用于基于人类反馈的强化学习(RLHF)
🔎 特殊设计亮点总结
| 设计 | 作用 |
|---|---|
| Truncated Importance Sampling | 防止重要性采样方差爆炸,提升训练稳定性 |
| Clip-Higher | 双重约束更新幅度,防止策略突变 |
| No Standard Deviation in Advantage Calculation | 优势直接用组内均值减去自身奖励,不除以标准差 → 更简单且避免异常波动 |
| Group-based Reward Normalization | 所有响应在一个 group 内比较,体现相对优劣 |
| Token-Level Loss | 每个 token 都参与梯度更新,而非仅关注整体输出 |
🧩 补充说明
- 文中提到 “hyperparameters for various runs are in Appendix Table 47”,说明实验中对 ρ \rho ρ, ε low \varepsilon_{\text{low}} εlow, ε high \varepsilon_{\text{high}} εhigh等进行了调参。
- π vLLM \pi_{\text{vLLM}} πvLLM是固定的,因此可以看作是离线数据收集策略,而 π \pi π是在线优化策略。 - 整个目标函数是对 每条响应中每个 token 的贡献求和,然后平均(归一化分母是总 token 数),确保长序列不会主导损失。
🌹🌹🌹OlmoRL 算法与其他代表的RL算法对比🌹🌹🌹
OlmoRL(从公式结构来看)是一种基于 策略梯度 + 重要性采样 + 相对奖励归一化 的强化学习目标函数,其设计融合了 PPO 的稳定性思想与 GRPO/GSPO 的组内相对奖励机制。下面将从核心机制、优化目标、数据需求、适用场景等维度,系统对比 OlmoRL 与 PPO / DPO / GRPO / GSPO / DAPO 的区别。
🧭 总体定位
| 方法 | 类型 | 是否需要奖励模型 | 是否使用优势函数 | 是否依赖参考模型 | 是否端到端 |
|---|---|---|---|---|---|
| PPO | 强化学习(Actor-Critic) | ✅ 需要独立 RM | ✅ 是(GAE) | ✅(KL 约束) | ❌(两阶段) |
| DPO | 监督式偏好学习 | ❌ 不需要 | ❌ 否(隐式) | ✅(固定 SFT 模型) | ✅ |
| GRPO | 无评论家 RL(Group-based) | ❌(只需胜者选择) | ✅(组内均值归一化) | ❌ 或弱依赖 | ✅ |
| GSPO | 序列级 GRPO 改进 | ❌ | ✅(序列粒度优势) | ❌ | ✅ |
| DAPO | 动态偏好优化 | ✅ 或 ❌(可选) | ✅ | ✅(动态参考) | ✅ |
| OlmoRL(本文) | Token-level Group RL | ❌(用 verifier 给分) | ✅(组内均值归一化) | ✅(vLLM 作行为策略) | ✅ |
注:这里的 “verifier” 可以是人工评分、规则打分或轻量奖励模型,但不需训练一个完整的 RM,因此通常视为“无需 RM”。
🔍 逐一对比分析
1. vs PPO(Proximal Policy Optimization)
| 维度 | PPO | OlmoRL |
|---|---|---|
| 奖励来源 | 需训练独立奖励模型(RM) | 使用 verifier 对整句打分(如人工/规则),无需训练 RM |
| 优势计算 | GAE(时间步级,需价值网络 Critic) | 组内均值归一化( A = r − mean ( r ) A = r - \text{mean}(r) A=r−mean(r)),无 Critic |
| 策略更新约束 | 通过 KL 散度 + clipping 控制偏离 | 通过 截断重要性采样( min ( π / π vLLM , ρ ) \min(\pi/\pi_{\text{vLLM}}, \rho) min(π/πvLLM,ρ))+ clip-higher 控制 |
| 参考模型 | 固定 SFT 模型(用于 KL 惩罚) | vLLM 作为行为策略(用于重要性采样分母) |
| 复杂度 | 高(4 模型协同:Policy, Value, RM, Ref) | 中(仅需当前策略 + vLLM + verifier) |
✅ 关键区别:
OlmoRL 移除了 Critic(价值网络),采用组内相对奖励替代 GAE,更接近 GRPO 范式,但保留了 PPO 的 clipping 和重要性采样思想。
2. vs DPO(Direct Preference Optimization)
| 维度 | DPO | OlmoRL |
|---|---|---|
| 优化目标 | 最大化偏好对的 log-odds(分类损失) | 最大化 token-level 奖励期望(RL 目标) |
| 是否 RL | ❌ 本质是监督学习(带参考模型的对比学习) | ✅ 是强化学习(有明确 reward 和 advantage) |
| 数据格式 | ( x , y w , y l ) (x, y_w, y_l) (x,yw,yl) 成对偏好 | ( x , y i , r i ) (x, y_i, r_i) (x,yi,ri) 多候选 + 分数(或胜者) |
| 是否需采样 | 否(直接优化概率比) | 是(需从 vLLM 采样生成 y i y_i yi) |
| 灵活性 | 对偏好质量敏感,难处理多于两个选项 | 可处理任意数量候选(group size G G G) |
✅ 关键区别:
DPO 是非 RL 的偏好对齐方法,而 OlmoRL 是真 RL 方法,能利用稠密或稀疏奖励信号进行策略搜索,更适合复杂任务(如长文本、多模态)。
3. vs GRPO(Global Reward Policy Optimization)
| 维度 | GRPO | OlmoRL |
|---|---|---|
| 奖励粒度 | 全局奖励(每响应一个分数) | 全局奖励 → 广播到每个 token |
| 损失粒度 | 响应级(整个序列一个 loss) | Token-level loss(每个 token 单独加权) |
| 重要性采样 | 通常不用,或简化处理 | 显式使用 π / π vLLM \pi / \pi_{\text{vLLM}} π/πvLLM 并截断 |
| clip 机制 | 一般无 clip | 有 clip-higher 双 min 机制 |
| 稳定性设计 | 依赖组内竞争 | 额外加入 PPO-style 稳定性控制 |
✅ 关键区别:
OlmoRL 是 GRPO 的精细化升级版 —— 将 GRPO 的“响应级优化”细化为 token 级优化,并引入 PPO 的 clipping 和截断 IS 技术,提升训练稳定性与生成控制力。
4. vs GSPO(Group Sequence Policy Optimization)
GSPO 是 GRPO 的改进版,主要解决:
- GRPO 在长序列中因 token 独立假设导致的不一致性
- 引入 序列级重要性权重 和 更合理的梯度传播
| 对比点 | GSPO | OlmoRL |
|---|---|---|
| 序列建模 | 强调序列整体一致性,避免 token 独立偏差 | 仍按 token 计算,但共享全局优势 |
| 优势分配 | 可能使用折扣累积或序列级归一化 | 所有 token 共享同一 A i A_i Ai |
| 适用任务 | 超长文本、代码生成 | 多模态短-中长度生成(如图文问答) |
✅ 关键区别:
GSPO 更关注长序列内部一致性,而 OlmoRL 更侧重多候选比较 + token 精细控制,适用于多模态、中等长度、高精度对齐场景。
5. vs DAPO(Dynamic Actor Preference Optimization)
DAPO 的核心是:
- 动态调整参考模型(不再是固定 SFT)
- 结合在线学习与偏好演化
| 对比点 | DAPO | OlmoRL |
|---|---|---|
| 参考模型 | 动态更新(如 EMA) | 固定 vLLM(行为策略) |
| 目标 | 适应偏好漂移(如用户反馈变化) | 静态对齐(给定 verifier 下最优) |
| 应用场景 | 在线推荐、个性化对话 | 离线高质量生成(如科研写作、图像描述) |
✅ 关键区别:
DAPO 面向动态环境,OlmoRL 面向静态高质量对齐。
📊 总结对比表
| 方法 | 核心思想 | 奖励形式 | 是否 RL | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| PPO | Actor-Critic + Clipping | 稠密 RM 分数 | ✅ | 中(需调参) | 通用 RLHF(如 GPT-4) |
| DPO | 偏好对 → 隐式奖励 | 成对偏好 ( y w , y l ) (y_w, y_l) (yw,yl) | ❌ | 高 | 快速对齐、资源有限 |
| GRPO | 组内竞赛 + 全局奖励 | 稀疏胜者选择 | ✅ | 中 | 长文本、创作 |
| GSPO | 序列级 GRPO 改进 | 同上 | ✅ | 高 | 超长文本、MoE 模型 |
| DAPO | 动态参考 + 在线偏好 | 可变偏好流 | ✅ | 中 | 个性化、在线系统 |
| OlmoRL | Token-level Group RL + Truncated IS + Clip-Higher | verifier 分数(每响应) | ✅ | 高(多重稳定机制) | 多模态、高精度生成 |
💡 结论:OlmoRL 的独特价值
OlmoRL 并不是完全新算法,而是 PPO 与 GRPO 的融合创新:
- 继承 PPO:clipping、重要性采样、策略约束
- 吸收 GRPO:组内相对奖励、无 Critic、多候选竞争
- 新增特性:token-level loss + 截断 IS + clip-higher → 更强的生成控制与稳定性
它特别适合:
- 视觉语言模型(VLM)微调
- 有 verifier(如人工评分、规则引擎)但无 RM 的场景
- 需要精细控制每个 token 生成质量的任务(如科学图表描述、医疗报告生成)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)