端侧基础大模型全景指南:从CLIP到VLM(一)
本文全面介绍了当前主流的端侧基础大模型及其应用。从环境配置到模型选择指南,详细对比了CLIP、BLIP、LLAVA等模型的特点和硬件需求,重点解析了CLIP的核心原理、技术优势及零样本识别能力。文章提供了实用开发指南,帮助开发者根据图像分类、视觉问答等不同场景选择合适的模型,并实现高效部署。通过分析各模型的性能表现和适用领域,为端侧AI应用开发提供了系统性参考。
·
0. 端侧基础大模型全景指南:从CLIP到LLAVA
1. 入门指南:快速上手端侧大模型
近年来,随着人工智能技术的飞速发展,各种功能强大的端侧基础模型(Foundation Models)层出不穷。这些模型能够在设备端直接运行,无需依赖云端处理,为各种应用场景提供了灵活且高效的解决方案。本文将为您全面介绍当前主流的端侧基础大模型,包括它们的核心任务、实现代码以及效果展示,帮助您快速了解并上手这些强大的工具。在深入了解各种端侧大模型之前,让我们先建立一个通用的开发环境和工作流程,帮助初学者快速入门。
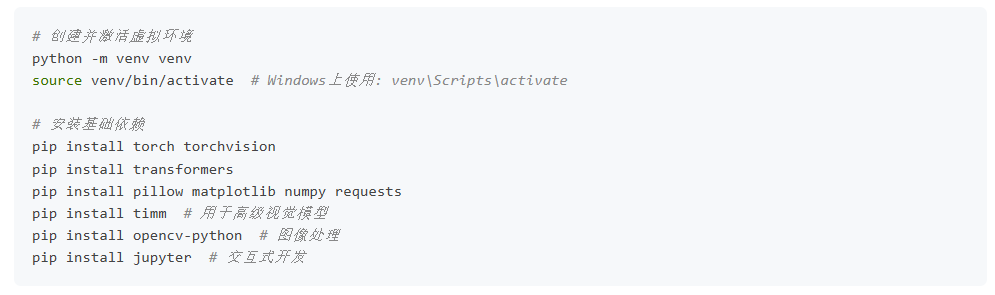
1.1 环境配置
首先,建立一个基础的Python环境:
1.2 模型选择指南
根据您的应用场景选择合适的模型:
| 应用需求 | 推荐模型 | 特点 |
|---|---|---|
| 图像分类与检索 | CLIP 或 SigLIP | 零样本能力强,适合图文匹配 |
| 图像描述生成 | BLIP 或 InstructBLIP | 生成自然流畅的图像描述 |
| 视觉问答系统 | BLIP、LLAVA 或 CogVLM | 理解图像并回答相关问题 |
| 精确物体分割 | SAM 或 SAV | 交互式、高精度分割 |
| 文本引导检测 | Grounding DINO | 用自然语言定位目标 |
| 文本引导分割 | Grounded-SAM | 结合检测和分割能力 |
| 通用视觉任务 | DINO 或 DINO-v2 | 自监督学习,特征提取强 |
| 多模态对话 | MiniGPT-4、Flamingo 或 mPLUG-Owl | 自然多轮对话,复杂视觉理解 |
| 中文多模态应用 | MiniCPT | 针对中文场景优化 |
1.3 硬件要求参考
| 模型 | 最低配置 | 推荐配置 | 移动设备支持 |
|---|---|---|---|
| CLIP | 4GB GPU/8GB RAM | 8GB GPU/16GB RAM | 支持(优化版) |
| BLIP | 8GB GPU/16GB RAM | 12GB GPU/32GB RAM | 有限支持 |
| DINO/DINO-v2 | 4GB GPU/8GB RAM | 8GB GPU/16GB RAM | 支持 |
| SAM | 8GB GPU/16GB RAM | 12GB GPU/32GB RAM | 支持(MobileSAM) |
| SAV | 10GB GPU/16GB RAM | 16GB GPU/32GB RAM | 有限支持 |
| Grounding DINO | 8GB GPU/16GB RAM | 12GB GPU/32GB RAM | 有限支持 |
| SigLIP | 4GB GPU/8GB RAM | 8GB GPU/16GB RAM | 支持 |
| LLAVA | 16GB GPU/32GB RAM | 24GB+ GPU/64GB RAM | 需要特殊优化 |
| Flamingo | 24GB GPU/32GB RAM | 40GB+ GPU/64GB RAM | 难以支持 |
| MiniCPT | 8GB GPU/16GB RAM | 12GB GPU/32GB RAM | 支持(优化版) |
| InstructBLIP | 12GB GPU/16GB RAM | 24GB+ GPU/32GB RAM | 有限支持 |
| mPLUG-Owl | 16GB GPU/32GB RAM | 24GB+ GPU/64GB RAM | 需要特殊优化 |
| MiniGPT-4 | 16GB GPU/32GB RAM | 24GB+ GPU/64GB RAM | 需要特殊优化 |
| CogVLM | 16GB GPU/32GB RAM | 24GB+ GPU/64GB RAM | 需要特殊优化 |
2. CLIP (Contrastive Language-Image Pre-training)
2.1 核心任务与原理
CLIP由OpenAI于2021年发布,是一个革命性的多模态预训练模型,它通过对比学习方法将图像和文本映射到同一特征空间。CLIP同时训练两个编码器:图像编码器(基于Vision Transformer或ResNet)和文本编码器(基于Transformer),使用对比损失函数使配对的图像和文本表示相似,而非配对的表示相互远离。
2.2 技术优势与关键特点
- 零样本识别能力:无需针对特定任务微调,可直接应用于新的分类任务
- 强大的泛化性:在未见过的数据分布上表现良好
- 多任务适应性:除图像分类外,还可用于图文检索、图像搜索等任务
- 开放词汇理解:能理解训练中未出现的概念和描述
2.3 工作流程
- 训练阶段:使用大规模图文对数据集(如4亿对),训练模型学习图像和文本的共同嵌入空间
- 推理阶段:
- 将目标类别转换为文本描述(如"a photo of a {category}")
- 计算图像与每个类别描述的相似度
- 选择相似度最高的类别作为预测结果
2.4 实际应用场景
- 零样本图像分类:无需额外训练识别新类别
- 图文检索:根据文本描述查找相关图像,或根据图像生成描述
- 视觉问答系统:结合其他模型回答关于图像的问题
- 创意内容生成:与生成模型结合创建特定风格的图像
- 图像搜索引擎:提升基于文本的图像搜索质量
2.5 详细实现代码
点击链接端侧基础大模型全景指南:从CLIP到VLM(一)阅读原文

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)