大模型应用开发-基础理论
大模型应用开发:1.CoT2.零样本推理能力3.ToT4.Toolformer5.Plan and Solve6.ReAct7.AgnetVerse8.AutoGen
大模型应用开发不是开发大模型本身,那是大模型开发的工作,大模型应用开发要做的事情是基于一个已经开发完毕的大模型,完成特定的业务需求,在这个过程中,大模型扮演的是一个内容理解、分析、推理的角色,在大模型应用开发中,称需要大模型进行处理的内容为上下文,这篇文章介绍为什么大模型可以作为内容理解、分析、推理角色的理论基础,后续介绍大模型应用开发常用的Langchain、LangGraph、MCP、扣子平台的使用。
首先要理解一个关键的概念“Prompt”,我们现在习惯称其为“提示词”。

好的 prompt 相当于在不改变模型权重的情况下,为其“加载”了一个虚拟的“任务适配器”,Prompt 不是给模型“灌输”新知识,而是教会它“如何使用”已有的知识。
一 思维链(CoT)
原论文:《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》
思维链可以看做所有大模型应用开发的开端。
作者通过实验发现了一个有趣的现象:我们在大模型输入提示(Prompt)中加入详细的推理过程后,大模型也会做出类似的推理,这样大模型在回答问题时会更加准确,把这种方法称作思维链(Chain-of-Thought,CoT)。

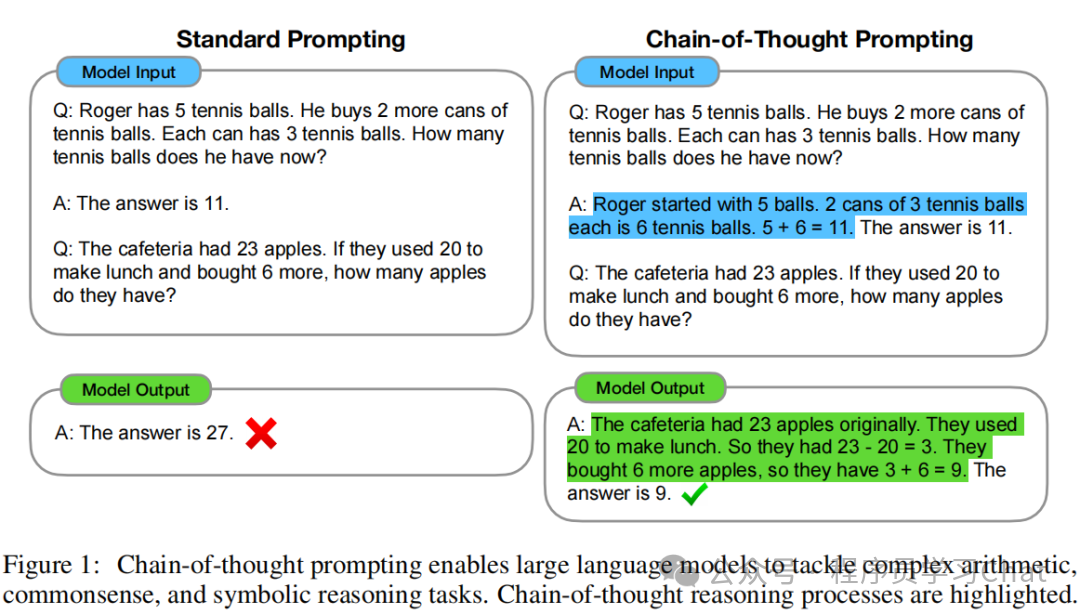
在 CoT 提出之前,为了让大模型对于问题的回答更加准确,我们会在输入提示中举出一些例子,让大模型模仿这些例子的关系进行输出,这种方法在需要多步推理的任务上(如数学应用题、常识推理)表现很差,模型往往无法生成正确的中间步骤,导致最终答案错误。
CoT的做法如下:

注意这里的Q、A是包含在大模型输入中的,是给大模型的提示信息(我们现在称作Prompt),来引导大模型的输出也产生类似的结构模式,这样大模型在面对用户的新问题Q后,也会像提示中的Q-A对儿一样,也对Q产生对应的推理,再进行回答,提高回答的准确性。CoT揭示了一个事实:大规模预训练模型具备内在的推理能力,这种能力在合适的引导后会被激活。这个事实很重要,如果不存在这个事实,现在的所有大模型应用都无从谈起。
二 大模型的零样本推理能力
原论文:《Large Language Models are Zero-Shot Reasoners》
这篇论文的核心贡献在于:它用一个极其简单的方法,揭示了大语言模型(LLM)被严重低估的零样本(Zero-Shot)推理能力,并为后续的研究设定了一个新的基线。在论文发表之前,业界普遍认为LLM在简单的、直觉性的任务上表现很好,但在需要多步、复杂推理的任务上(如数学应用题、符号逻辑等)LLM 表现很差,即使模型规模达到百亿甚至千亿级别。为了解决这个问题,当时最前沿的技术是 Chain-of-Thought (CoT)提示。CoT要求研究者为每个任务精心设计几个“思维链”示例提示,然后让模型模仿这个过程进行推理,这种方法效果显著,但依赖于人工编写的、任务特定的少样本示例。
因此核心问题就是:LLM的强大推理能力,是否真的依赖于这些人工编写的少样本示例?还是它们本身就具备零样本推理的潜力,只是我们没有找到正确的方法去激活?
作者的答案是:LLM本身就具备强大的零样本推理能力!他们提出的解决方案简单到令人难以置信:在原始问题后面,直接加上一句固定的提示语:“Let’s think step by step.” (让我们一步一步地思考),模型就会针对问题产生推理,这个方法被称为 Zero-shot Chain-of-Thought (Zero-shot-CoT)。
论文指出,为了获得最佳效果,Zero-shot-CoT过程可以分为两个阶段:
1.推理提取(Reasoning Extraction):
输入: Q:[原始问题]. A: Let's think step by step.
模型会输出: 一段自由生成的、分步的推理过程。
2.答案提取(Answer Extraction):
输入: 将步骤1的完整输出(人工输入的问题+推理提示语Let's think step by step+模型被引导,生成的推理过程),再加上一个答案提取提示(如 Therefore, the answer (arabic numerals) is),再输入到大模型中。
模型输出: 关于问题的最终答案。
这种方法完全不需要任何任务特定的示例,仅靠一个通用的触发词,就能让模型展现出复杂的推理能力。Zero-shot-CoT 的效果随着模型规模的增大而显著增强。小模型使用这个提示效果不佳,但像 GPT-3这样的超大规模模型则能从中获益,这说明这种零样本推理能力是大模型涌现的特性。
这篇论文的意义远不止于提出一个新技巧,它带来了几个深刻的洞见:
1)简单提示的巨大威力: 复杂的推理能力可以通过极其简单的语言指令来激发。这暗示了LLM的内部表征可能已经编码了丰富的、结构化的知识和推理模式,只需要一个正确的“钥匙”(提示)来解锁。
2)迈向通用认知能力: 一个单一的、通用的提示能在如此多样的任务上生效,这强烈暗示了LLM可能具备某种通用的、高层次的认知能力(如通用逻辑推理),而不仅仅是针对特定任务的狭窄技能。这为研究 AI 的通用智能提供了新的思路。
三 树状思维链(ToT)
原论文:《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》


ToC让大模型(LLM)不再只是答案生成器,而是变成:问题解决规划者+评估者



论文中的示意图如下
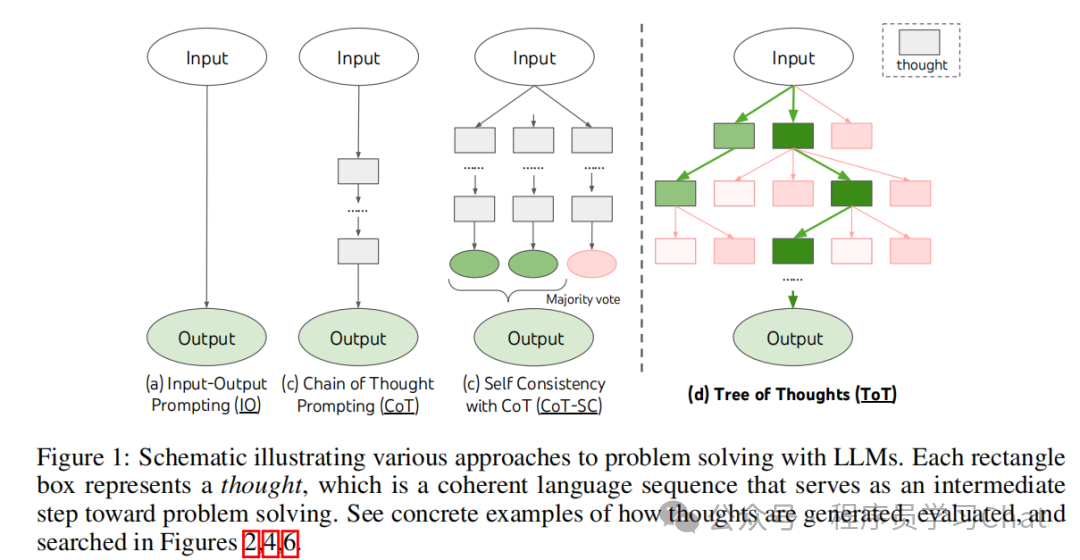
基于人工智能先驱们的工作,ToT将“求解问题”看做是在问题解空间中进行搜索的过程

ToT必须要解决4个问题:
1)思维分解:针对输入问题的每个思维是什么
2)思维生成:已经解决了思维分解中的一个子问题,产生了一个状态,如何根据这个状态产生下一阶段的思维(扩展思维树结构)
3)状态评估:如何评估一个部分解的好坏
4)搜搜策略:使用什么方法在生成这棵思维树中搜索最终可行解
思维分解:

思维生成:

状态评估:


搜索算法:


ToT已经具备了智能体的视角

四 Toolfromer
原论文:《Toolformer: Language Models Can Teach Themselves to Use Tools》
这篇论文的核心思想极具颠覆性:它通过一种新颖的、自监督的数据生成和过滤方法,让 LLM 学会了在何时、以何种方式主动调用外部工具,并将结果无缝整合到自己的文本生成中。
LLM 的固有缺陷:尽管 LLM 能力强大,但它们存在一些根本性局限:
1)知识过时:无法获取训练数据截止日期之后的信息。
2)事实幻觉:容易编造看似合理但错误的事实。
3)数学能力弱:难以进行精确的算术计算。
4)缺乏实时感知:不知道当前日期、时间等。
现有解决方案的不足:
1)依赖大量人工标注:有些方法需要人类为每个任务-工具对编写大量示例,成本高昂且难以扩展。
2)任务特定:很多工具集成方案被绑定在特定任务上,缺乏通用性。
因此核心问题是:能否设计一种通用、自监督的方法,让 LLM 自主学会使用多种外部工具,从而克服其固有缺陷,同时不损害其原有的语言建模能力?
Toolformer 分为四个主要步骤:
(1) 采样潜在的API调用(Sampling):给定一个预训练好的 LLM(如 GPT-J)和一个纯文本语料库(如 CCNet)。对于每种工具(如计算器、问答系统),研究人员只提供极少数的人工编写的API 使用示例。利用 LLM 强大的 In-Context Learning (上下文学习) 能力,让它“模仿”这些示例,在语料库的任意位置“猜测”可能有用的 API 调用。例如,在句子 “400 out of 1400...” 中,模型可能会插入 [计算器(400/1400)]。
(2) 执行API调用(Executing):将上一步采样出的所有潜在 API 调用真实地执行,并获取结果。
(3) 过滤有用的 API 调用 (Filtering) :这是最关键的一步!核心思想: 不是所有采样的 API 调用都有用。 Toolformer 提出了一个完全自监督的、基于语言建模损失(perplexity)。
具体做法:对于一个在位置 i 插入的 API 调用及其结果 r,计算两种情况下的损失:
L+: 将完整的 API 调用(包括结果)作为前缀,计算模型预测后续 token 的损失。
L-: 计算a) 完全不插入任何东西;b) 只插入 API 调用,但不包含结果两种基线损失的最小值:。
过滤标准: 如果 L- - L+ >= τf(一个阈值),说明提供这个 API 调用及其结果,显著降低了模型预测后续文本的难度(即降低了困惑度)。那么这个 API 调用就被认为是“有用的”,会被保留下来。
(4)模型微调 (Finetuning):将所有被过滤后保留下来的、带有真实 API 调用和结果的文本,组成一个新的增强数据集 C。在这个新数据集 C上对原始 LLM 进行微调。推理时:当模型生成到时,系统会暂停解码,调用相应的API获取结果,然后将结果和结束标记插回,继续生成。

Toolformer和MCP都是赋予大模型调用外部工具的能力,MCP和Toolformer的比较如下:

大模型如何知道自己应该调用外部函数?这是个极其深刻的问题,也是当前AI研究的前沿难点。答案是:大模型其实并不真正“知道”自己不知道,它只是在模仿人类在类似情境下的行为模式。
具体来说,有以下几种机制在起作用:
1. 基于训练数据的模式匹配 (Pattern Matching)
在训练数据中,存在大量这样的模式:
“今天的日期是? → [查询日历 API]”
“计算 123×456 = ? → [使用计算器]”
“巴黎的天气如何? → [调用天气服务]”
当模型看到一个高度结构化、明确指向外部信息的问题时(如包含“今天”、“计算”、“最新股价”等关键词),它会激活这些记忆中的模式,从而生成工具调用。
本质: 不是“我知道我不知道”,而是“当问题长成这样时,人类通常会去查一下,所以我也会”。
2. 基于不确定性信号(Uncertainty Heuristics)
虽然 LLM 没有显式的置信度输出,但它的token 概率分布可以反映不确定性。如果模型对某个事实的答案概率很低(如多个候选实体概率接近),它可能会倾向于生成一个模糊回答,或者生成一个查询动作。在 Toolformer 的过滤机制中,这一点被巧妙利用:只有当 API 调用能显著降低后续 token 的预测损失(即让答案更确定)时,该调用才会被保留。这相当于在训练阶段就教会了模型:“当你卡住时,查一下会让后面更好写”。
3. 通过 Prompt / 微调进行行为塑造(Behavior Shaping)
在 Function Calling 的设定中,训练数据会明确展示:
用户: “现在几点?”
助手: {"function": "get_current_time"}
系统: "2025-12-10 14:00"
助手: “现在是下午两点。”
模型通过学习这种三段式交互,内化了一种策略:对于某些类型的问题,不直接回答,而是先请求工具。这不是“自知之明”,而是一种习得的响应策略。
4. 当前局限:模型无法真正评估自身知识边界
① 幻觉问题依然存在:如果一个问题看起来很普通(如“爱因斯坦哪年出生?”),但模型记错了(比如记成1880年而非1879年),它不会主动去查,因为它“自信”地认为自己知道。
② 过度调用 or 调用不足:模型可能在不需要时调用工具(浪费资源),也可能在需要时没调用(给出错误答案)。
③ 真正的“元认知”缺失:人类会说“我不确定,让我查一下”。LLM 只会说“让我查一下”——但它并不真的“不确定”,它只是在复现一个成功的对话模板。
大模型并非通过自我反思来决定调用工具,而是通过统计学习,识别出“哪些问题在历史上常被人类外包给工具”,并模仿这一行为。未来的研究方向(如 Self-Refine, Reflexion, Active Tool Retrieval)正试图赋予模型更强的元认知能力,让它能基于内部状态(如预测熵、一致性检查)主动判断是否需要外部帮助。但在当前阶段,这一切仍是高级的模式模仿,而非真正的“意识”或“自知”。
五 Plan and Solve
原论文:《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》旨在解决当时主流零样本推理方法(Zero-shot-CoT)的三大核心缺陷。
论文首先指出,尽管“Let's think step by step”这种 Zero-shot-CoT 提示非常简单有效,但它在实践中存在三个主要错误类型:
1)计算错误(Calculation Errors, 7%):LLM 在执行算术运算时出错。
2)步骤缺失错误(Missing-Step Errors, 12%):在复杂的多步推理中,模型跳过了关键的中间步骤。
3)语义误解错误(Semantic Misunderstanding Errors, 27%):模型未能正确理解问题的含义或上下文。
为了解决上述问题,特别是“步骤缺失”,作者提出了 Plan-and-Solve(PS) 提示法。其核心思想非常直观,模仿人类解决问题的过程:先制定计划,再执行计划。
PS 提示包含两个明确的阶段:
1)规划 (Plan):让 LLM 首先理解问题,并制定一个解决该问题的分步计划。
2)求解(Solve):让 LLM 严格按照这个计划,一步步执行并得出最终答案。
示例:
Zero-shot-CoT: "Let's think step by step."
Plan-and-Solve(PS): "Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step."
这个简单的替换,会引导模型从“边想边做”转变为“先想好再做”,从而生成更完整、更有条理的推理链。
六 ReAct
原论文:《REACT: SYNERGIZING REASONING AND ACTING INLANGUAGE MODELS》
这篇论文的核心思想是将人类解决问题的两种基本能力:“思考”(Reasoning)和“行动”(Acting,融合到大语言模型(LLM)解决问题的过程中。它超越了之前仅关注内部推理(如 Chain-of-Thought)或仅关注外部行动(如Toolformer)的方法,提出了一种交替进行思考-行动,思考-行动相互促进的新智能体范式。







理论上智能体的上下文越长,信息越丰富,智能体采取正确行动的概率越大,但是过长的上下文会使推理关键线索困难,这也是为什么ReAct要采取思考->行动->观察流程的原因,及时的总结更正自己,好过于错误已经累积无法挽回再行动。

七 AgentVerse
原论文:《AGENTVERSE: FACILITATING MULTI-AGENT COLLABORATION AND EXPLORING EMERGENT BEHAVIORS》
这篇论文的核心目标是构建一个通用、可扩展的多智能体(Multi-Agent)框架,以解决那些开放性、复杂且需要跨领域知识的任务。它超越了单个LLM单智能体的局限,通过模拟人类团队协作的方式,让多个专业化智能体共同工作。
单智能体的局限性: 单个 LLM 虽然强大,但在处理开放域、多步骤、需要专业领域知识或多方协商的任务时,容易出现幻觉、逻辑不一致或能力不足的问题。
现有 Agent 系统的不足:
1)大多专注于单智能体或固定角色的协作,缺乏灵活性。
2)难以处理动态、开放式的任务,这些任务没有预定义的解决路径或明确的角色分工。
AgentVerse 的设计灵感来源于人类团队的组织结构,其核心是一个分层、模块化的架构,主要包含以下关键组件:
(1) Role Assigner (角色分配器)
功能:作为整个团队的“领导者”或“项目经理”。
工作流程:
-
接收用户的开放性任务描述(例如,“为一家新咖啡店制定开业计划”)。
-
分析任务需求,识别出完成该任务所需的专业知识领域。
-
动态招募(recruit)一组最合适的专家智能体,并为每个智能体分配清晰的角色和职责(例如,“市场营销专家”、“财务分析师”、“室内设计师”)。
关键点: 角色分配是按需、动态的,而非预设的。
(2) Solvers (求解器/专家智能体)
功能: 执行具体工作的“专家”。
特点:
-
每个 Solver 是一个 LLM 实例,被赋予了特定的角色描述(role description),这引导其从该领域的视角思考问题。
-
它们可以独立工作(解决分配给自己的子任务),也可以相互交流(通过共享的对话历史)。
-
在 AgentVerse 中,Solver 的工作通常遵循 ReAct 或类似的范式,即生成 Thought -> Action -> Observation 的轨迹。
(3) Reviewers (评审员)
功能: 负责质量控制和迭代改进。
工作流程:
-
审查由 Solvers 生成的初步解决方案。
-
基于其专业知识,提供具体的、建设性的批评意见(critic opinions)。
-
这些意见会被反馈给 Solvers,用于生成改进后的新方案。
关键点: 引入了多轮、闭环的反馈机制,确保最终输出的质量。
(4) Evaluator (评估员)
功能: 对最终的解决方案进行全面、多维度的评估。
评估维度: 通常包括 Completeness(完整性)、Functionality(功能性)、Readability(可读性)、Robustness(鲁棒性)等,并给出 0-9 的分数。
作用: 不仅用于衡量性能,其详细的评估报告也可以作为未来改进的指导。


AgentVerse不仅是一个多智能体框架,它更是一种新的问题解决范式。它认识到,对于现实世界中最棘手的开放性问题,答案往往不是来自一个无所不知的“神谕”,而是来自一个多元化、专业化且善于沟通协作的团队。通过巧妙地结合动态角色分配、专业化智能体、以及基于评审的迭代改进,AgentVerse 成功地将 LLM 的能力从单点突破扩展到了系统集成,为处理复杂、真实世界的任务提供了一个强大而灵活的基础设施。
八 AutoGen
AutoGen 提供了一个功能强大、灵活且易于使用的开源框架,它的目标是极大地简化下一代基于 LLM 的复杂应用的开发过程。
LLM 应用开发的复杂性: 虽然 LLM 能力强大,但构建一个能可靠解决复杂任务(如代码生成、研究分析、自动化工作流)的应用,需要处理大量工程细节:
1.如何管理多个 LLM 实例之间的对话?
2.如何将 LLM 与外部工具、人类用户、自定义逻辑集成?
3.如何调试和优化多轮、多参与者的交互流程?
AutoGen 的核心是一个围绕 ConversableAgent 类构建的面向对象框架。其关键设计理念是 “一切皆为代理”(Everything is an Agent)。
(1) 核心抽象:ConversableAgent
定义: 任何可以参与对话的实体都是一个 ConversableAgent。这包括:
1.LLM-based Agents:由 LLM 驱动的智能体(如 AssistantAgent)。
2.Tool-based Agents:封装了特定工具或 API 的代理(如 UserProxyAgent 可以执行代码、调用函数)。
3.Human User:人类用户本身也被视为一个特殊的代理(UserProxyAgent 在需要时会将控制权交还给人类)。
关键属性:
System Message: 定义代理的角色、能力和行为准则(这是引导 LLM 行为的核心)。
Ability to Send/Receive Messages: 所有代理通过统一的消息传递接口进行通信。
(2) 灵活的对话模式
无预设模式: AutoGen 不强制任何特定的对话流程(如 ReAct 的 Thought->Action)。相反,它提供了强大的底层原语,让用户可以自由定义任意复杂的对话拓扑和逻辑。
内置常用模式: 框架也预置了一些高效的模式,例如:
1.Two-Agent Chat: 最简单的 Assistant (提供建议/代码) + UserProxy (执行/验证) 模式。
2. Group Chat: 一个 GroupChatManager 协调多个专家代理进行讨论,直到达成共识或完成任务。
3.Teachable Agent: 一个可以向人类学习并记住反馈的代理。
(3) 强大的可扩展性与集成能力
1.Code Execution: UserProxyAgent 可以内置一个代码执行器,自动运行 LLM 生成的代码,并将结果(包括错误信息)作为消息反馈回去,形成一个强大的代码生成-执行-调试闭环。
2.Function/Tool Calling: 可以轻松地将任意 Python 函数注册为代理可以调用的工具。
3.Human-in-the-Loop: 可以在对话流程中的任何一点无缝地引入人类输入,实现人机协同。
4.Multi-Modal & Custom LLMs: 支持多种模型后端(OpenAI, Azure, Hugging Face, Llama.cpp 等)和多模态模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)