MCP服务创建指南
本文探讨了大规模表格分析中的技术挑战,介绍了MCP(Model Context Protocol)作为解决方案。文章对比了FunctionCall和MCP两种工具调用方式,指出MCP通过标准化协议解决了生态兼容性问题。详细阐述了MCP的基本架构、通信协议(STDIO/SSE/HTTP)和核心流程,并以VsCode+Cline配置table-reader服务为例,展示了MCP在分块处理大规模表格数据
目录
4.2 在 Cline 中配置 table-reader(server)
一、问题原点
当分析大规模表格时,会遇到两个问题:
(1)如果一次性读取表格,则如果表格内容太多,非常容易超过基座大模型的上下文窗口限制,导致推理报错;
(2)如果用RAG进行内容截取,则不能了解数据的全貌,如问这个表格一共多少行数据,则无法得知。
因此,这里采用MCP的方式,可动态分析大规模表格数据。
二、MCP基础知识
MCP的本质是调用工具,那么调用工具的两种方式有:(1)Function Call (2)MCP
2.1 Function Call
Function Call 是 OPEN AI 在 2023 年推出的一个非常重要的概念:
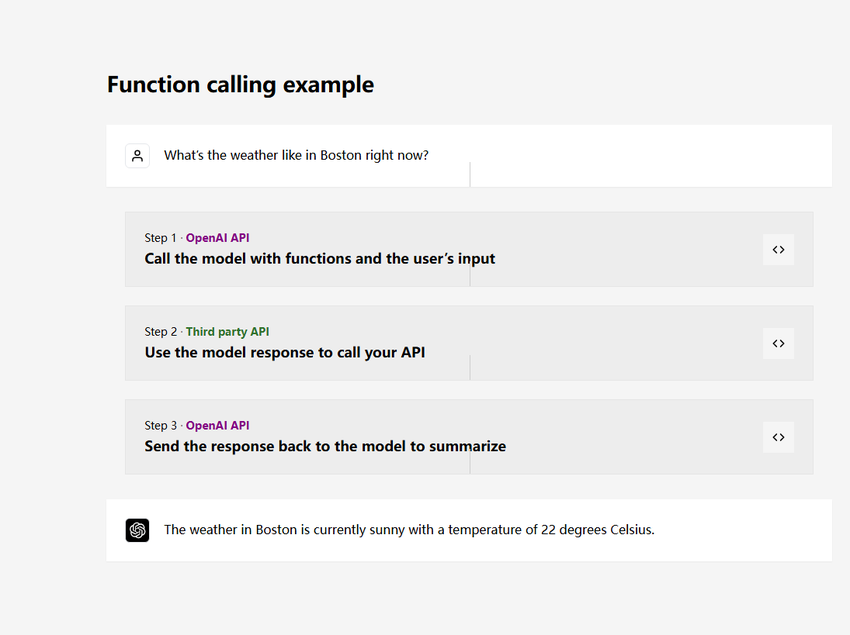
截图自:https://openai.com/index/function-calling-and-other-api-updates/
Function Call(函数调用) 本质上就是提供了大模型与外部系统交互的能力,类似于给大模型安装一个 “外挂工具箱”。当大模型遇到自己无法直接回答的问题时,它会主动调用预设的函数(如查询天气、计算数据、访问数据库等),获取实时或精准信息后再生成回答。
缺点:
(1)开发者想实现 Function Call 的成本是比较高的,首先得需要模型本身能够稳定支持 Function Call 的调用,比如我们在 Coze 中选择某些模型时提示,选择的模型不支持插件的调用,其实就是不支持 Function Call 的调用。
(2)OPEN AI 最开始提出这项技术的时候,并没有想让它成为一项标准,所以虽然后续很多模型也支持了 Function Call 的调用,但是各自实现的方式都不太一样。如果我们要发开一个 Function Call 工具,需要对不同的模型进行适配,比如参数格式、触发逻辑、返回结构等等,这个成本是非常高的。
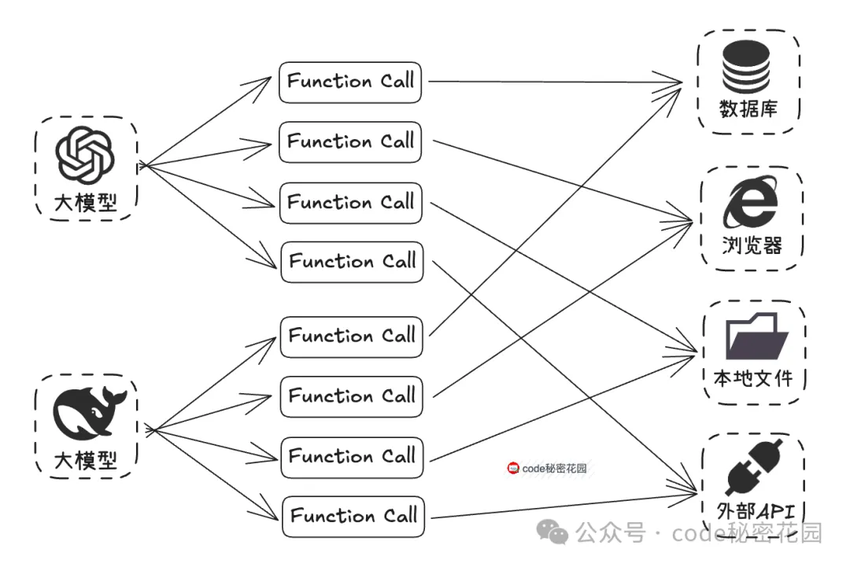
这也大大提高了 AI Agent 的开发门槛,所以在以前我们大部分情况下只能通过 Dify、Coze 这些平台来构建 Agent。
核心特点
-
模型专属:不同模型(GPT/Claude/DeepSeek)的调用规则不同
-
即时触发:模型解析用户意图后直接调用工具
-
简单直接:适合单一功能调用(如"查北京温度"→调用天气API)
痛点
-
协议碎片化:需为每个模型单独开发适配层
-
功能扩展难:新增工具需重新训练模型或调整接口
类比
-
不同品牌手机的充电接口(Lightning/USB-C),设备间无法通用
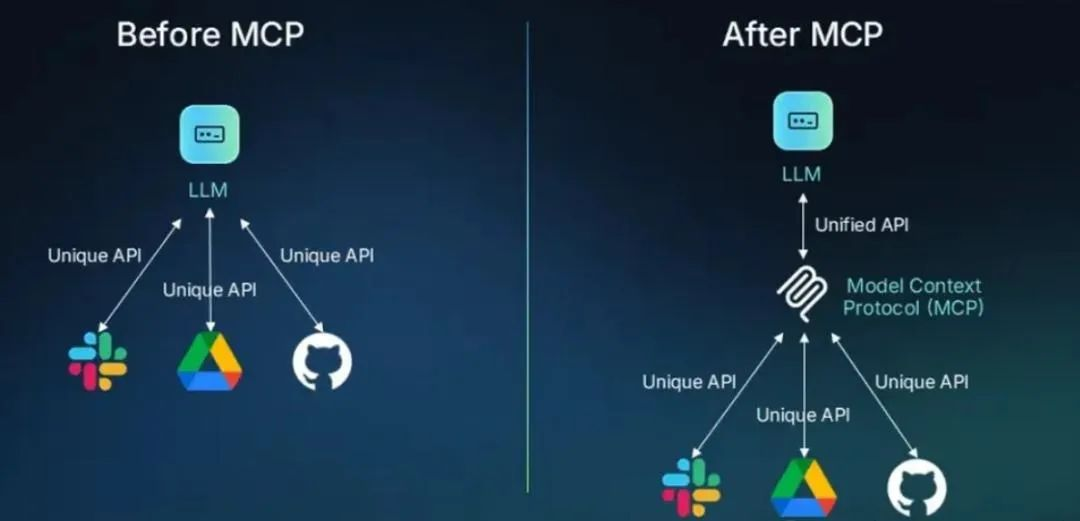
2.2 MCP
MCP(Model Context Protocol,模型上下文协议)是一种由 Anthropic 公司(也就是开发 Claude 模型的公司)推出的一个开放标准协议,目的就是为了解决 AI 模型与外部数据源、工具交互的难题。
Function Call的问题:每次要让模型连接新的数据源或使用新工具,开发者都得专门编写大量代码来进行对接,既麻烦又容易出错。
MCP的解决思路:MCP像是一个 “通用插头” 或者 “USB 接口”,制定了统一的规范,不管是连接数据库、第三方 API,还是本地文件等各种外部资源,都可以通过这个 “通用接口” 来完成,让 AI 模型与外部工具或数据源之间的交互更加标准化、可复用。
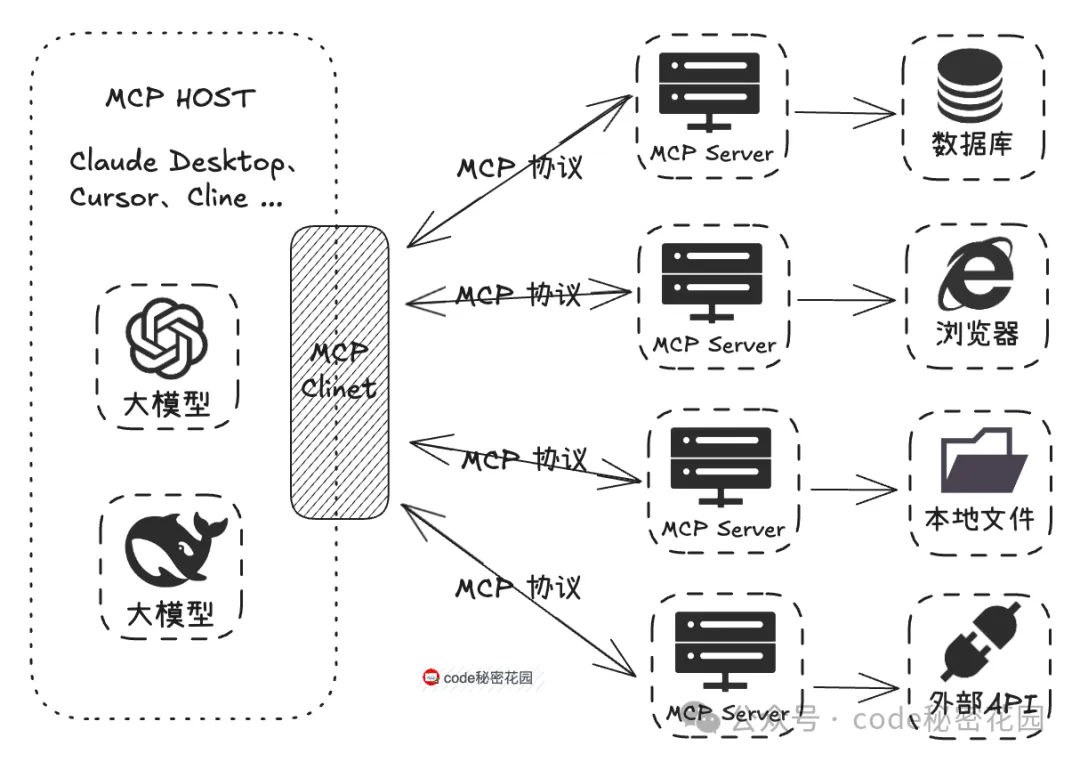
开发者按照 MCP 协议进行开发,无需为每个模型与不同资源的对接重复编写适配代码,可以大大节省开发工作量,另外已经开发出的 MCP Server,因为协议是通用的,能够直接开放出来给大家使用,这也大幅减少了开发者的重复劳动。
比如,你如果想开发一个同样逻辑的插件,你不需要在 Coze 写一遍,再去 Dify 写一遍,如果它们都支持了 MCP,那就可以直接使用同一个插件逻辑。
核心特点
-
协议标准化:统一工具调用格式(请求/响应/错误处理)
-
生态兼容性:一次开发即可对接所有兼容MCP的模型
-
动态扩展:新增工具无需修改模型代码,即插即用
核心价值,解决三大问题
-
数据孤岛 → 打通本地/云端数据源
-
重复开发 → 工具开发者只需适配MCP协议
-
生态割裂 → 形成统一工具市场
类比
-
USB-C 接口:手机/电脑/外设通过统一标准互联
2.3 MCP VS Function Call
|
对比维度 |
Function Calling |
MCP (Model Control Protocol) |
|
协议标准 |
私有协议(各模型自定规则) |
开放协议(JSON-RPC 2.0) |
|
工具发现 |
动态获取(initialize请求) |
静态预定义 |
|
调用方式 |
同进程函数或API |
stdio/sse/steamableHttp |
|
扩展成本 |
高(每新增工具需调整模型) |
低(工具热插拔,模型无需改动) |
|
适用场景 |
简单任务(单次函数调用) |
复杂流程(多工具协同+数据交互) |
|
工程复杂度 |
低(快速接入单个工具) |
高(需部署MCP服务器+客户端) |
|
生态协作 |
工具与模型强绑定 |
工具开发者与 Agent 开发者解耦 |
三、MCP基本概念
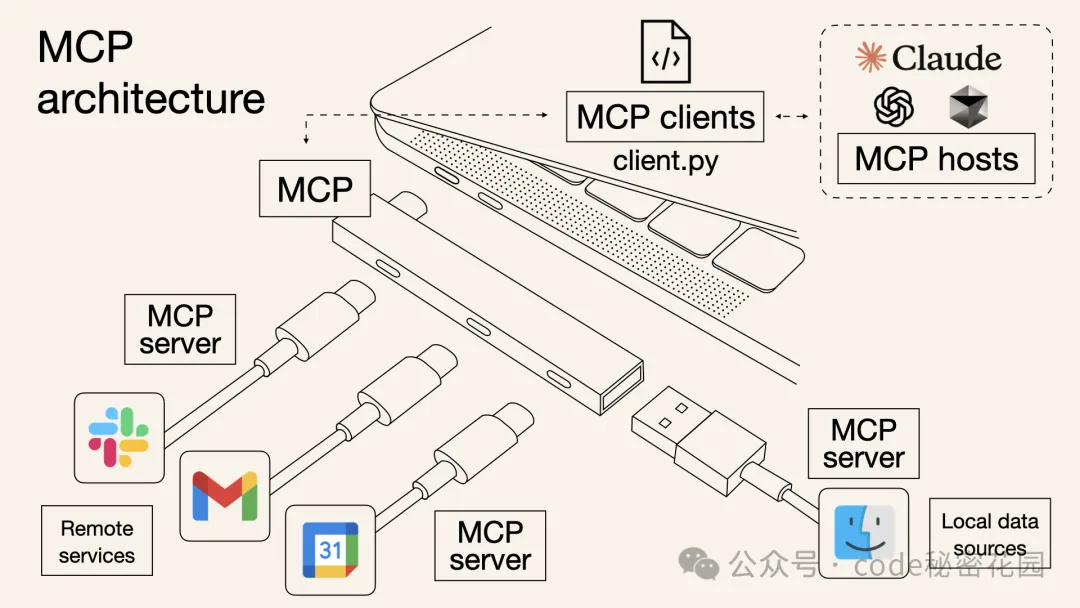
从上面 MCP 的架构图中我们可以看到,想要使用 MCP 技术,首先就是得找到一个支持 MCP 协议的客户端,然后就是找到符合我们需求到 MCP 服务器,然后在 MCP 客户端里调用这些服务。
3.1 MCP Host
在 MCP 官方文档中,我们看到已经支持了 MCP 协议的一些客户端/工具列表:
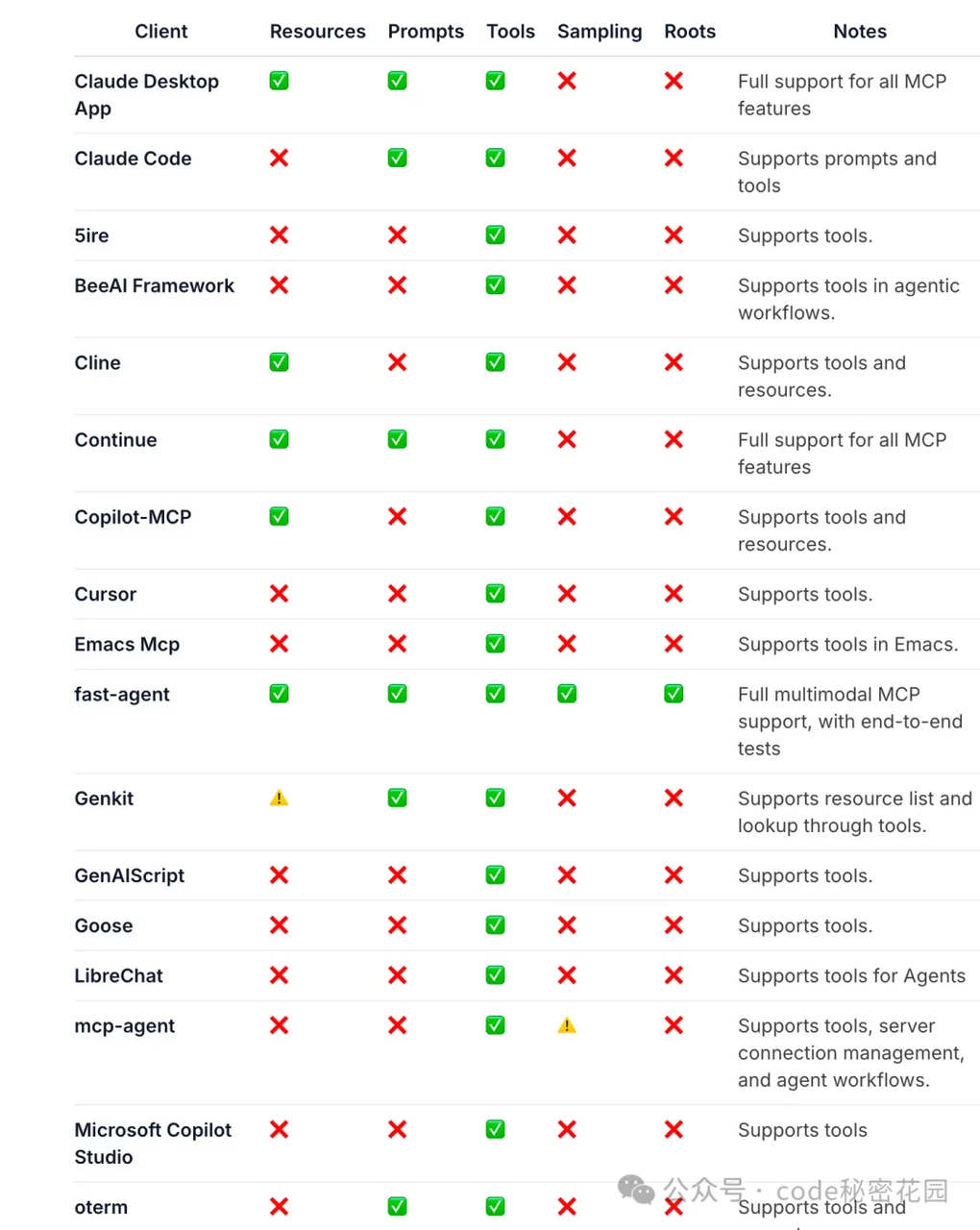
从表格里,我们可以看到,MCP 对支持的客户端划分了五大能力,这里我们先简单了解即可:
-
Tools:服务器暴露可执行功能,供 LLM 调用以与外部系统交互。
-
Resources:服务器暴露数据和内容,供客户端读取并作为 LLM 上下文。
-
Prompts:服务器定义可复用的提示模板,引导 LLM 交互。
-
Sampling:让服务器借助客户端向 LLM 发起完成请求,实现复杂的智能行为。
-
Roots:客户端给服务器指定的一些地址,用来告诉服务器该关注哪些资源和去哪里找这些资源。
目前最常用,并且被支持最广泛的就是 Tools 工具调用。
对于上面这些已经支持 MCP 的工具,其实整体划分一下就是这么几类:
-
AI 聊天工具:如 5ire、LibreChat、Cherry Studio
-
AI 编码工具:如 Cursor、Windsurf、Cline
-
AI 开发框架:如 Genkit、GenAIScript、BeeAI
3.2 MCP Server
MCP Server 的官方描述:一个轻量级程序,每个程序都通过标准化模型上下文协议公开特定功能。
简单理解,就是通过标准化协议与客户端交互,能够让模型调用特定的数据源或工具功能。常见的 MCP Server 有:
-
文件和数据访问类:让大模型能够操作、访问本地文件或数据库,如 File System MCP Server;
-
Web 自动化类:让大模型能够操作浏览器,如 Pupteer MCP Server;
-
三方工具集成类:让大模型能够调用三方平台暴露的 API,如 高德地图 MCP Server;
下面是一些可以查找 MCP Server 的途径:
-
官方示例:https://github.com/modelcontextprotocol/servers
-
三方MCP聚合:https://mcp.so/
-
魔塔MCP广场:https://modelscope.cn/mcp?name=ocr&page=1
-
百度MCP广场(带深度思考搜索):https://www.mcpworld.com/
3.3 通信协议
我们使用 Cherry Studio 中的 MCP 服务配置来举例,最前面的名称和描述比较好理解,都是用于展示的。
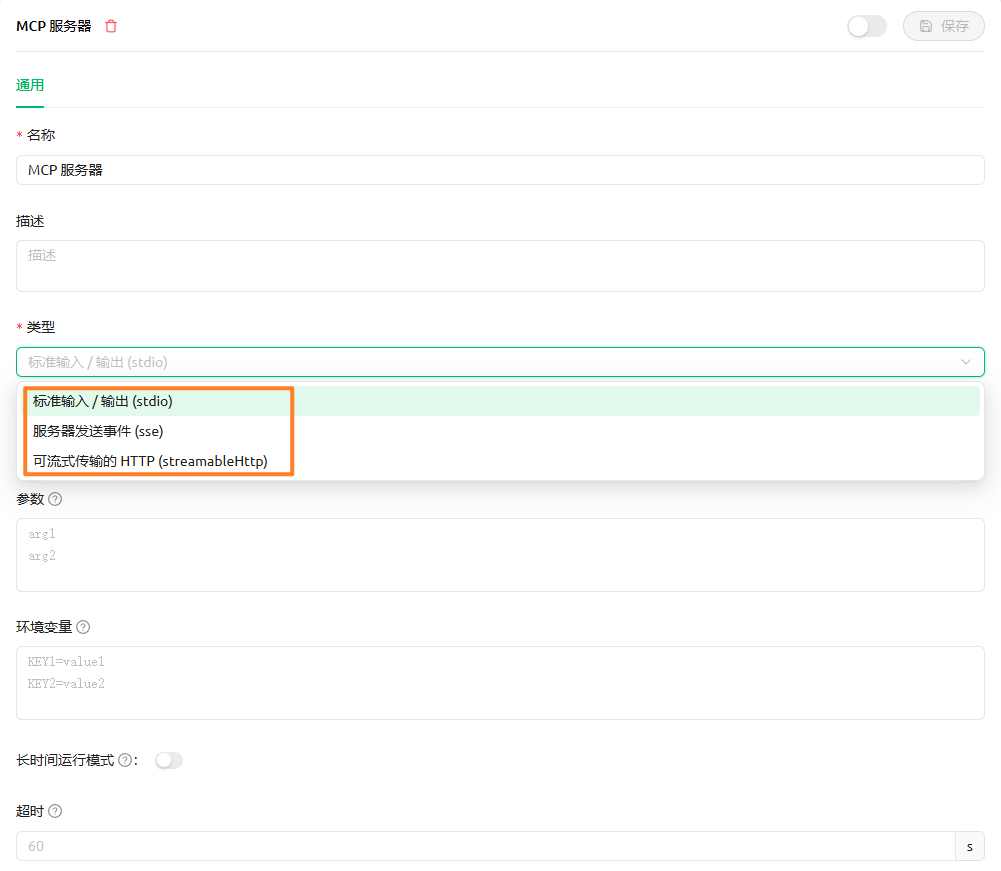
MCP 协议中的 STDIO/SSE/HTTP 其实就是是两种不同的(MCP Server 与 MCP Client)通信模式:
-
STDIO(标准输入输出):像「面对面对话」:客户端和服务器通过本地进程的标准输入和标准输出直接通信。例如:本地开发时,你的代码脚本通过命令行启动,直接与 MCP 服务器交换数据,无需网络连接。
-
SSE(服务器推送事件):像「电话热线」:客户端通过 HTTP 协议连接到远程服务器,服务器可以主动推送数据(如实时消息)。例如:AI 助手通过网页请求调用远程天气 API,服务器持续推送最新的天气信息。
-
streamableHttp(服务器推送事件):像「边说边回短信」:客户端发一次 HTTP 请求,服务器不是最后一次性返回结果,而是把结果分成多段 “一段段吐回来”。例如:AI 助手调用一个大模型生成 3000 字文档,不是等全都生成完再一次性返回,而是先把前几句先流回来,边生成边返回,就像 ChatGPT 的 token 流一样。
STDIO的两种启动方式
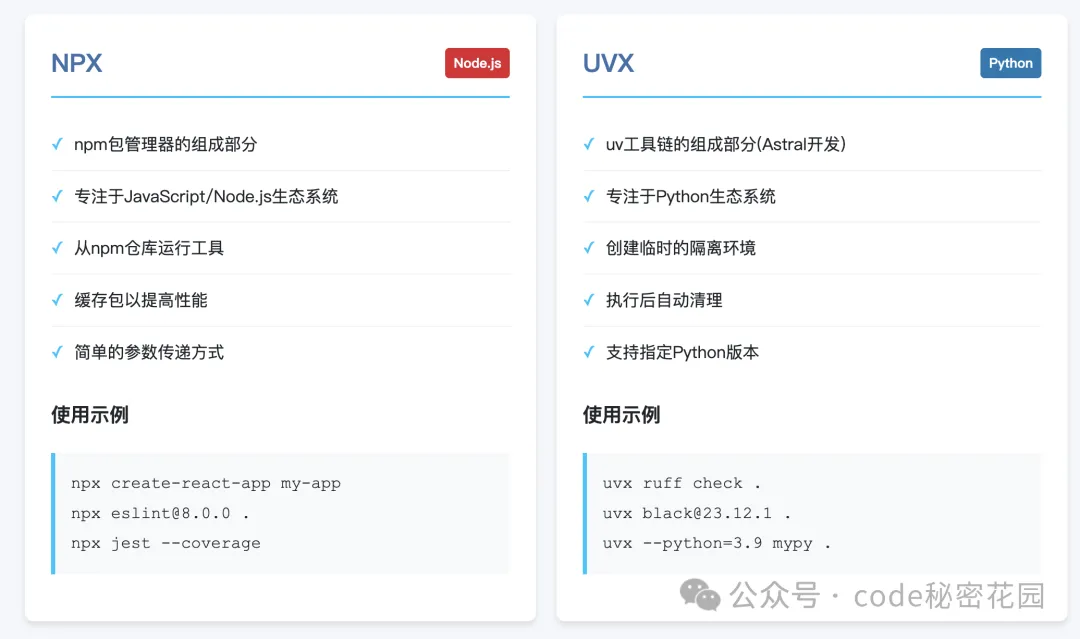
分为 npx 启动 和 nv 启动,分别对应不同的mcp服务编码,npx基于node.js,uv则是python的生态系统。
npm与npx
npm:npm 是 Node.js 的包管理工具,主要用来 安装、管理和发布包。
主要功能:
-
安装依赖:
npm install package-name(1) 如果不加 -g,会安装到当前项目的 node_modules 下。
(2) 如果加 -g,会全局安装。
- 管理依赖:
-
package.json会记录依赖版本。
-
- 发布包:
- 可以用
npm publish发布到 npm 仓库。
- 可以用
-
特点:
-
需要先安装包,然后才能执行。
-
安装的包会占用磁盘空间(本地或全局)。
-
npx:npx 是 npm 5.2+ 内置的一个 命令执行工具,主要用来 直接运行包里的可执行命令,不一定需要先全局安装。
主要功能:
-
直接执行本地或远程包:
npx create-react-app my-app会临时下载(如果本地没有),执行一次后就不用保留。
-
可以运行当前项目
node_modules/.bin下的包:
npx eslint .不需要在 package.json scripts 中定义,也不需要全局安装 eslint。
-
支持指定版本:
npx package@version-
特点:
-
不需要全局安装即可运行。
-
执行一次就可以,不占用长期磁盘空间。
-
适合临时使用或者试用新版本工具。
-
总结对比
| 特性 | npm | npx |
| 主要用途 | 安装、管理、发布包 | 运行包里的可执行命令 |
| 是否需要安装包 | 必须安装 | 可临时执行,无需安装 |
| 全局执行 | 需要 -g | 可直接执行 |
| 使用场景 | 项目依赖管理 | 快速执行脚手架或工具命令 |
💡 一句话理解:
-
npm = 安装和管理包
-
npx = 直接运行包(一次性或临时)
uv与uvx
先明确一点:这里的 uv 工具类似于 conda 或 venv,主要用来管理 隔离环境 和 项目运行,但它有自己的一套命令体系。
uv 启动
-
作用:在当前 uv 环境下直接运行一个项目或脚本。
-
特点:
-
使用的是 当前激活的 uv 环境。
-
没有额外的环境隔离。
-
类似于在 conda 环境中直接执行
python main.py。
-
-
适用场景:
-
你已经在某个 uv 环境中,想快速启动项目。
-
不需要为每次启动创建新的隔离环境。
-
uvx 启动
-
作用:为每次启动创建 独立的隔离运行环境。
-
特点:
-
会 自动隔离依赖,防止污染全局或其他 uv 环境。
-
类似
docker run -v .:/app python:3.11这种临时环境启动。 -
可以保证不同项目或不同版本的依赖不会冲突。
-
-
适用场景:
-
多项目并行,需要环境完全隔离。
-
测试不同依赖版本。
-
临时运行脚本,不想污染原环境。
-
总结对比
| 特性 | ux | uvx |
| 是否隔离环境 | 否 | 是 |
| 启动速度 | 快 | 相对慢(要创建隔离环境) |
| 依赖冲突风险 | 高 | 低 |
| 适用场景 | 单一项目、快速启动 | 多项目并行、测试不同版本 |
💡 一句话理解:
-
ux= 当前环境直接运行 -
uvx= 临时隔离环境运行
npx和nvx的对比
3.4 MCP 的核心流程
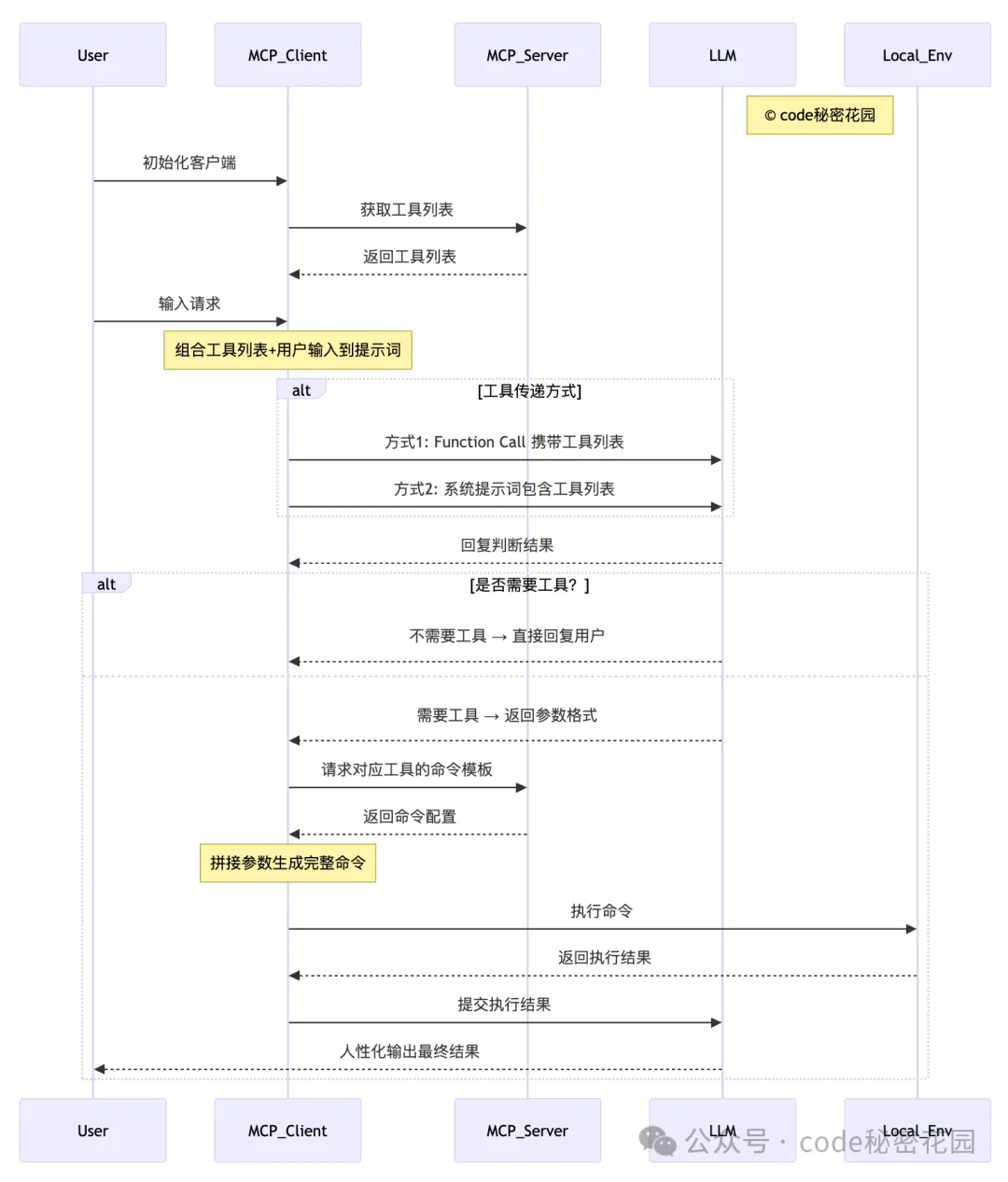
-
初始化与工具列表获取 用户首先对MCP客户端进行初始化操作,随后MCP客户端向MCP服务器发送请求以获取可用的工具列表,MCP服务器将工具列表返回给客户端。
-
用户输入与提示词构建 用户在客户端完成初始化后,向MCP客户端输入具体请求。客户端将此前获取的工具列表与用户输入内容相结合,共同组成用于询问LLM的提示词。
-
工具传递方式选择 MCP客户端通过两种方式之一将提示词传递给LLM:
-
方式1:使用Function Call(函数调用)直接携带工具列表信息;
-
方式2:在系统提示词(System Prompt)中包含工具列表。
-
-
LLM判断与响应 LLM接收到提示词后,返回判断结果:
-
无需工具:LLM直接将处理结果通过MCP客户端回复给用户;
-
需要工具:LLM先向客户端返回所需工具的参数格式要求。
-
-
工具命令生成与执行 若需要工具,MCP 客户端根据 LLM 提供的参数格式,以及 MCP Server 配置的命令模板进行拼接,生成完整的可执行命令,并在本地环境(Local_Env)中执行该命令。
-
结果处理与输出 本地环境执行命令后,将结果返回给 MCP 客户端。客户端将执行结果提交给 LLM,由 LLM 对技术化的执行结果进行处理,最终以人性化的语言形式输出给用户。
四、使用 MCP 分析大规模表格
4.1 VsCode + Cline
在 VsCode 插件市场搜索,Cline 找到后点击安装即可(注意这里还有很多非官方的版本,直接安装那个下载量最大的就好):
配置大模型(这里我用的deepseek测试,效果不错)
4.2 在 Cline 中配置 table-reader(server)
在服务器上任一位置获取table-reader服务代码
git clone https://gitee.com/thomacai/table_reader.git安装依赖
cd table_reader
uv sync注:这里使用uv工具,如果没有则安装
curl -LsSf https://astral.sh/uv/install.sh | sh试运行
uv run python table_reader.py这里能启动就行,然后关闭即可。
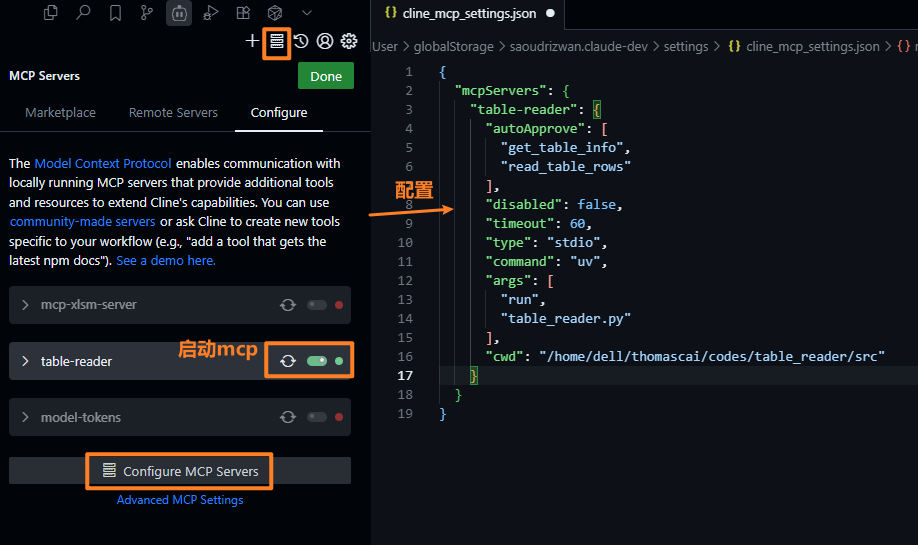
然后再cline上配置 table-reader服务:
{
"mcpServers": {
"table-reader": {
"autoApprove": [
"get_table_info",
"read_table_rows"
],
"disabled": false,
"timeout": 60,
"type": "stdio",
"command": "uv",
"args": [
"run",
"table_reader.py"
],
"cwd": "/home/XXX/XXX/codes/table_reader"
}
}
}
4.3 在cline上使用这个mcp
确保使用了这个mcp:
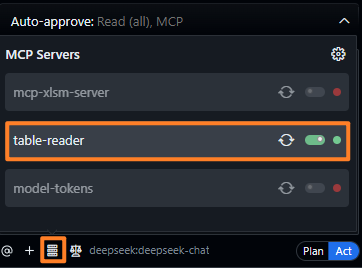
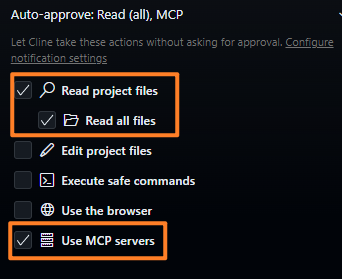
以及打开读取文件和使用mcp的权限:
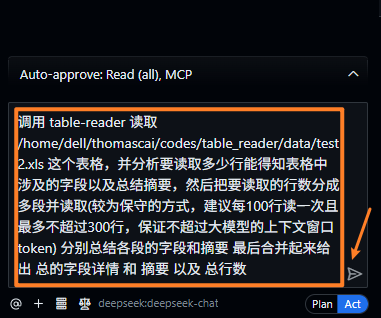
最后执行:
调用 table-reader 读取 /home/XXX/codes/table_reader/data/test2.xls 这个表格,并分析要读取多少行能得知表格中涉及的字段以及总结摘要,然后把要读取的行数分成多段并读取(较为保守的方式,建议每100行读一次且最多不超过300行,保证不超过大模型的上下文窗口token) 分别总结各段的字段和摘要 最后合并起来给出 总的字段详情 和 摘要 以及 总行数。
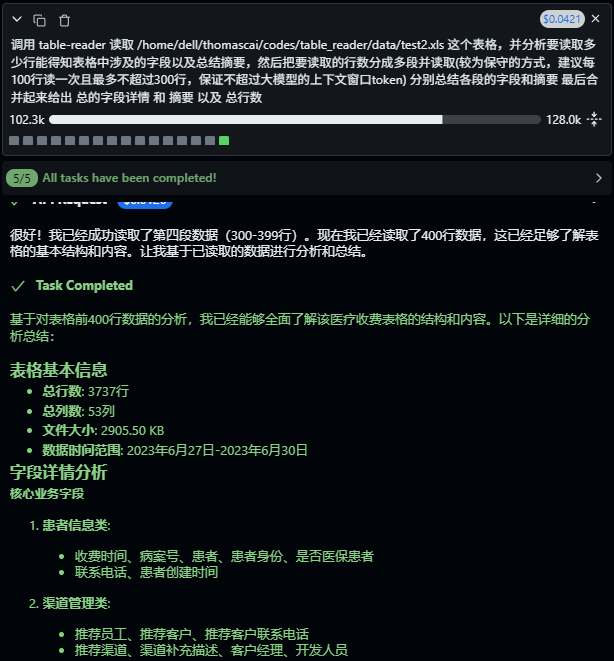
得到结果:
4.4 MCP的局限性
-
提示词要引导大模型“分批读取表格数据”,避免一次性让模型处理过大的数据量。若一次输入接近或超过模型上下文窗口,极容易触发报错,并导致 MCP 客户端直接崩溃。
-
使用 MCP 后 Token 耗费会显著上升——因为许多 MCP 客户端本身依赖大量系统提示词来维持与 MCP 工具的通信,所以在 MCP 模式下的每一次调用,都天然包含更重的系统级上下文。
五、参考资料
1. MCP官方服务:
https://modelcontextprotocol.io/docs/develop/build-server#claude-for-desktop-integration-issues
(仅支持uv直接启动mcp服务)
2. mcp基础知识:
https://mp.weixin.qq.com/s?__biz=Mzk0MDMwMzQyOA==&mid=2247503333&idx=1&sn=6f81fccb7bc19b3a18b4c590f055d757&scene=21&poc_token=HMa2CmmjVIQ0hJqkdDVfUGwY7O0bTVuKqrVXXiP-
3. mcp核心原理:
https://mp.weixin.qq.com/s/yP6D_mnxwFsL3SbC4qZnYg

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)