openi启智社区部署FoundationModel / DeepSeek-Coder-V2-Lite-Instruct大模型(max_model_len设小才可以,比如设为32k)
摘要:在OpenI启智社区尝试使用NPU和DCU环境运行DeepSeek-Coder-V2-Lite-Instruct大模型推理时遇到多重问题。首先NPU环境(CANN83)和DCU环境(DCUK100)均启动失败。随后在VLLM调用时发现模型配置文件存在语法错误(多一个右括号),通过创建软链接并修改配置文件解决。但最终因显存不足无法满足模型最大序列长度(163840)要求,即使将gpu_memo
openi启智社区提供npu和dcu环境,尝试进行大模型的推理。选模型的时候,就选DeepSeek-Coder-V2-Lite-Instruct这个模型
FoundationModel / DeepSeek-Coder-V2-Lite-Instruct
npu环境
npu ,选的cann83,但是没启动起来,放弃。
Dcu环境
创建dcu环境
选DCU K100环境
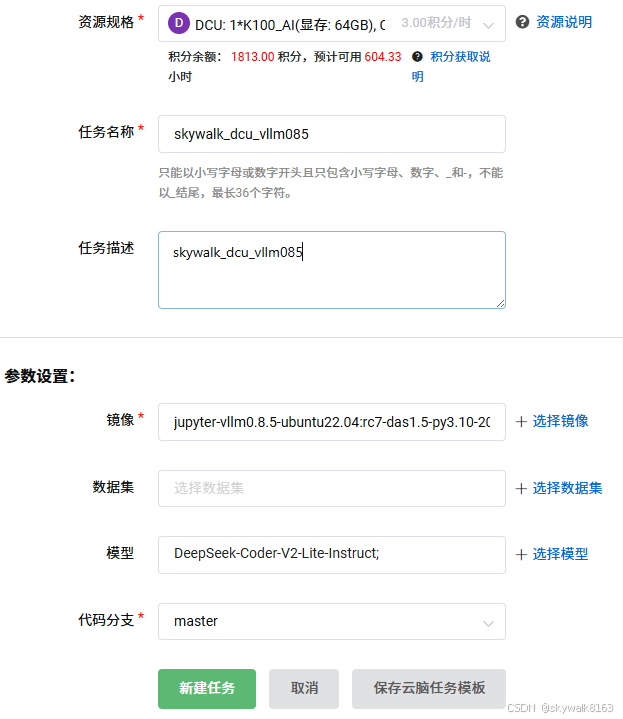
模型选好DeepSeek-Coder-V2-Lite-Instruct
白搭,这个dcu也启动不起来,以后再说吧。
第二天这个启动了
模型调用
创建的时候提示的模型调用语句
from c2net.context import prepare,upload_output
#初始化导入数据集和预训练模型到容器内
c2net_context = prepare()
#获取预训练模型路径
llama_model_7b_path = c2net_context.pretrain_model_path+"/"+"llama_model_7B"
deepseek_coder_v2_lite_instruct_path = c2net_context.pretrain_model_path+"/"+"DeepSeek-Coder-V2-Lite-Instruct"
#输出结果必须保存在该目录
you_should_save_here = c2net_context.output_path
#回传结果到openi,只有训练任务才能回传
upload_output()
但是我使用下来会报错:
ValueError: ❌ Failed to obtain environment variables. Please set the DATA_DOWNLOAD_METHOD environment variables.
确定模型的位置:
发现模型放在这里:/pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/
这样就好调用了
VLLM调用
vLLM API server version 0.8.5.post1
使用命令:
vllm serve /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/
--trust-remote-code总结
可以推理,但是需要把max_model_len设小才可以,比如设为32k
vllm serve /root/DeepSeek-Coder-V2-Lite-Instruct/ --trust-remote-code --gpu_memory_utilization 0.95 所以暂时是没法用了,除非能再降低显存占用。
调试
VLLM启动报错SyntaxError: unmatched ')'
Traceback (most recent call last):
File "/usr/local/bin/vllm", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/cli/main.py", line 53, in main
args.dispatch_function(args)
File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/cli/serve.py", line 27, in cmd
uvloop.run(run_server(args))
File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 82, in run
return loop.run_until_complete(wrapper())
File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 61, in wrapper
return await main
File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1078, in run_server
async with build_async_engine_client(args) as engine_client:
File "/usr/lib/python3.10/contextlib.py", line 199, in __aenter__
return await anext(self.gen)
File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 146, in build_async_engine_client
async with build_async_engine_client_from_engine_args(
File "/usr/lib/python3.10/contextlib.py", line 199, in __aenter__
return await anext(self.gen)
File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 166, in build_async_engine_client_from_engine_args
vllm_config = engine_args.create_engine_config(usage_context=usage_context)
File "/usr/local/lib/python3.10/dist-packages/vllm/engine/arg_utils.py", line 1110, in create_engine_config
model_config = self.create_model_config()
File "/usr/local/lib/python3.10/dist-packages/vllm/engine/arg_utils.py", line 998, in create_model_config
return ModelConfig(
File "/usr/local/lib/python3.10/dist-packages/vllm/config.py", line 452, in __init__
hf_config = get_config(self.hf_config_path or self.model,
File "/usr/local/lib/python3.10/dist-packages/vllm/transformers_utils/config.py", line 324, in get_config
config = AutoConfig.from_pretrained(
File "/usr/local/lib/python3.10/dist-packages/transformers/models/auto/configuration_auto.py", line 1121, in from_pretrained
config_class = get_class_from_dynamic_module(
File "/usr/local/lib/python3.10/dist-packages/transformers/dynamic_module_utils.py", line 558, in get_class_from_dynamic_module
final_module = get_cached_module_file(
File "/usr/local/lib/python3.10/dist-packages/transformers/dynamic_module_utils.py", line 383, in get_cached_module_file
modules_needed = check_imports(resolved_module_file)
File "/usr/local/lib/python3.10/dist-packages/transformers/dynamic_module_utils.py", line 199, in check_imports
imports = get_imports(filename)
File "/usr/local/lib/python3.10/dist-packages/transformers/dynamic_module_utils.py", line 182, in get_imports
tree = ast.parse(content)
File "/usr/lib/python3.10/ast.py", line 50, in parse
return compile(source, filename, mode, flags,
File "<unknown>", line 206
))
^
SyntaxError: unmatched ')'
我感觉是不是transformer版本太低了?
先测试json文件:
python -c "import json; json.load(open('/pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/config.json'))"
没报错,证明没有问题。
升级transformers
pip install transformers -U不管用
无语了,竟然源代码configuration_deepseek.py多了一个括号!无语
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
))关键在openi里,这是公开的模型,我没有权限修改。
我要自己建立一个模型,然后在环境启动的时候把它调进去。
发现限额13G,所以我没法自己上传模型了。
用非常规方法解决
想了个办法,先ln链接到自己设定的一个目录,然后删除configuration_deepseek.py文件,再重新创建一个正确的文件即可:
root@notebook-1999710264909160450-denglf-10993:~# cd /tmp/code
root@notebook-1999710264909160450-denglf-10993:/tmp/code# ls
airoot Untitled.ipynb
root@notebook-1999710264909160450-denglf-10993:/tmp/code# mkdir DeepSeek-Coder-V2-Lite-Instruct
root@notebook-1999710264909160450-denglf-10993:/tmp/code# cd DeepSeek-Coder-V2-Lite-Instruct/
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# ln -s /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/* .
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# ls
config.json model-00001-of-000004.safetensors model-00004-of-000004.safetensors openi_resource.version tokenization_deepseek_fast.py
configuration_deepseek.py model-00002-of-000004.safetensors modeling_deepseek.py README tokenizer_config.json
generation_config.json model-00003-of-000004.safetensors model.safetensors.index.json README.md tokenizer.json
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# ls -la
total 4
drwxr-xr-x 2 root root 4096 Dec 13 15:06 .
drwxr-xr-x 5 root root 127 Dec 13 15:06 ..
lrwxrwxrwx 1 root root 58 Dec 13 15:06 config.json -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/config.json
lrwxrwxrwx 1 root root 72 Dec 13 15:06 configuration_deepseek.py -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/configuration_deepseek.py
lrwxrwxrwx 1 root root 69 Dec 13 15:06 generation_config.json -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/generation_config.json
lrwxrwxrwx 1 root root 80 Dec 13 15:06 model-00001-of-000004.safetensors -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/model-00001-of-000004.safetensors
lrwxrwxrwx 1 root root 80 Dec 13 15:06 model-00002-of-000004.safetensors -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/model-00002-of-000004.safetensors
lrwxrwxrwx 1 root root 80 Dec 13 15:06 model-00003-of-000004.safetensors -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/model-00003-of-000004.safetensors
lrwxrwxrwx 1 root root 80 Dec 13 15:06 model-00004-of-000004.safetensors -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/model-00004-of-000004.safetensors
lrwxrwxrwx 1 root root 67 Dec 13 15:06 modeling_deepseek.py -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/modeling_deepseek.py
lrwxrwxrwx 1 root root 75 Dec 13 15:06 model.safetensors.index.json -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/model.safetensors.index.json
lrwxrwxrwx 1 root root 69 Dec 13 15:06 openi_resource.version -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/openi_resource.version
lrwxrwxrwx 1 root root 53 Dec 13 15:06 README -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/README
lrwxrwxrwx 1 root root 56 Dec 13 15:06 README.md -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/README.md
lrwxrwxrwx 1 root root 76 Dec 13 15:06 tokenization_deepseek_fast.py -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/tokenization_deepseek_fast.py
lrwxrwxrwx 1 root root 68 Dec 13 15:06 tokenizer_config.json -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/tokenizer_config.json
lrwxrwxrwx 1 root root 61 Dec 13 15:06 tokenizer.json -> /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/tokenizer.json
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# cp configuration_deepseek.py configuration_deepseek.pybak
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# rm configuration_deepseek.py
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# vi configuration_deepseek.pybak
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# mv configuration_deepseek.pybak configuration_deepseek.py
root@notebook-1999710264909160450-denglf-10993:/tmp/code/DeepSeek-Coder-V2-Lite-Instruct# 把最后一行的右括号去掉一个。
self.attention_bias = attention_bias
self.attention_dropout = attention_dropout
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
)mkdir DeepSeek-Coder-V2-Lite-Instruct
cd DeepSeek-Coder-V2-Lite-Instruct/
ln -s /pretrainmodel/DeepSeek-Coder-V2-Lite-Instruct/* .
cp configuration_deepseek.py configuration_deepseek.pybak
rm configuration_deepseek.py
问题解决!
VLLM启动报错The model's max seq len (163840) is larger than the maximum number of tokens that can be stored in KV cache (25056).
ValueError: The model's max seq len (163840) is larger than the maximum number of tokens that can be stored in KV cache (25056). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
Traceback (most recent call last):
设了0.95,还是报错:ValueError: The model's max seq len (163840) is larger than the maximum number of tokens that can be stored in KV cache (35408). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
看来实在不够用啊。显存不够....
0.99 ValueError: The model's max seq len (163840) is larger than the maximum number of tokens that can be stored in KV cache (43696). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
最高到不了64k啊,这样太受限制了
vllm serve /root/DeepSeek-Coder-V2-Lite-Instruct/ --trust-remote-code --max_num_seqs=4 --gpu_memory_utilization 0.8 不行,可能以前就是1
改成以前的:
vllm serve /root/DeepSeek-Coder-V2-Lite-Instruct/ --trust-remote-code --gpu_memory_utilization 0.95 0.99还是43696
尝试加个环境变量
export LMCACHE_USE_EXPERIMENTAL=True0.95还是35408
看来必须用两块卡了,openi只有1块卡的,所以看来openi是没法推理了。或者勉强推理,但是token要小于43k,这样几乎没法用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)