MySQL索引性能分析
sql的执行计划:explain select s., c. from student s, course c , student_course sc where s.id = sc.studentid and sc.courseid= c.id。表示select的类型,常见的取值有SIMPLE(简单表,即不使用表连接或子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第
a) 如何查看数据库sql语句的访问频次
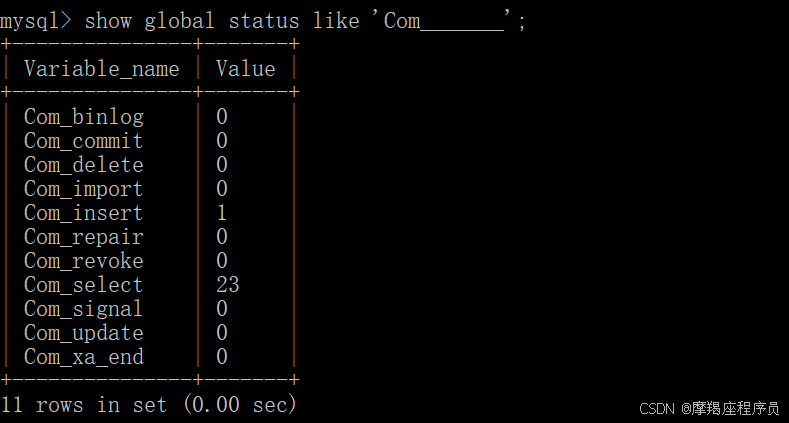
通过show [session | global] status 命令可以提供服务器状态信息;
通过 SHOW GLOBAL STATUS LIKE ‘Com_______'(7个下划线) 命令,可以查看当前数据库INSERT、UPDATE、 DELETE、SELECT的访问频次。
b) 慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time, 单位: 秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在MySQL的配置文件(etc/my.cnf)中配置如下信息
慢查询日志记录指定参数:
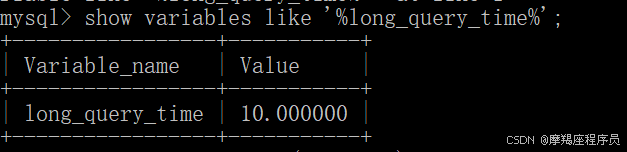
查看慢查询开关

SQL性能分析
a)profile详情
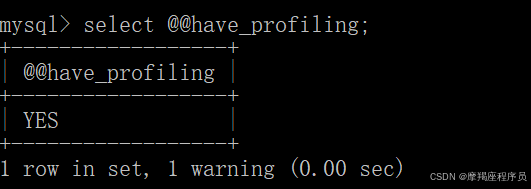
show profiles能够在做SQL优化时帮忙我们了解时间都耗费到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作。
SELECT @@have_profiling;
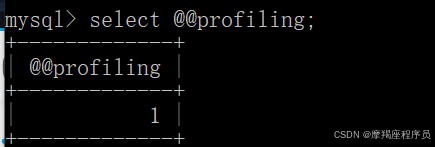
查看profiles信息
show profiles;
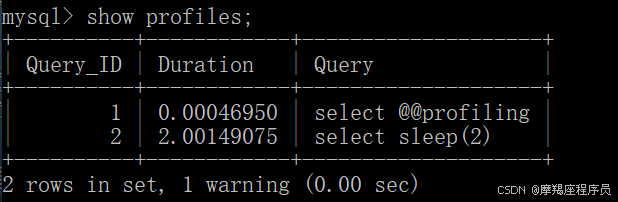
#查看每一条SQL的耗时基本情况 show profiles; #查看指定query_id的SQL语句各个阶段的耗时情况 show profile for query query_id; #查看指定query_id的SQL语句CPU的使用情况 show profile cpu for query query_id;
explain 执行计划
explain或者desc命令获取MySQL如何执行select语句的信息,包括在select语句执行过程中表如何连接和连接的顺序:
直接在select语句之前加上关键字explain/desc
explain select 字段列表 from 表名 where 条件
explain select * from tb_user where id=1;

explain执行计划各字段含义:
1) id
select 查询的序列号,表示查询中执行select子句或者时操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。
素材:
student表、course表、student_course表
-- 学生表
CREATE TABLE student (
id INT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(10) COMMENT '姓名',
no VARCHAR(10) COMMENT '学号'
);
-- 课程表
CREATE TABLE course (
id INT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(10) COMMENT '课程名称'
);
-- 学生课程中间表(多对多关系)
CREATE TABLE student_course (
id INT PRIMARY KEY COMMENT '主键',
studentid INT COMMENT '学生ID',
courseid INT COMMENT '课程ID',
FOREIGN KEY (studentid) REFERENCES student(id),
FOREIGN KEY (courseid) REFERENCES course(id)
);
INSERT INTO course (id, name) VALUES
(1, 'Java'),
(2, 'PHP'),
(3, 'MySQL'),
(4, 'Hadoop');
-- 忽略重复主键冲突
INSERT IGNORE INTO course (id, name) VALUES
(1, 'Java'),
(2, 'PHP'),
(3, 'MySQL'),
(4, 'Hadoop');
INSERT INTO student_course (id, studentid, courseid) VALUES
(1, 1, 1),
(2, 1, 2),
(3, 1, 3),
(4, 2, 2),
(5, 2, 3),
(6, 3, 4);联表查询学生选修的课程:
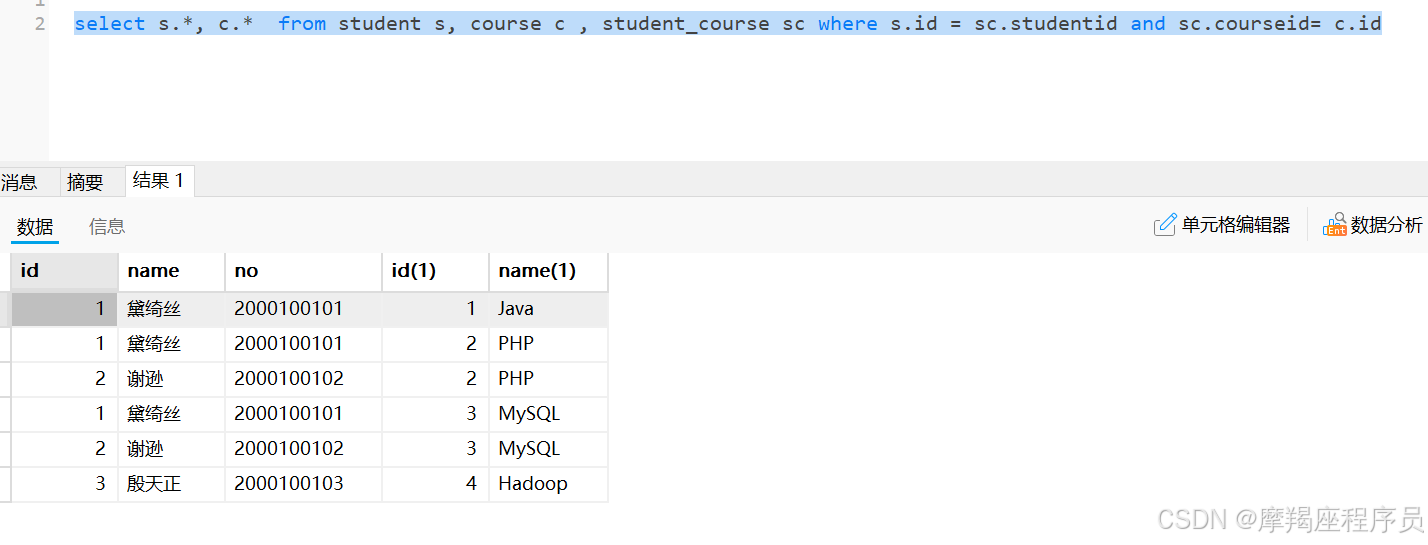
sql的执行计划:explain select s., c. from student s, course c , student_course sc where s.id = sc.studentid and sc.courseid= c.id
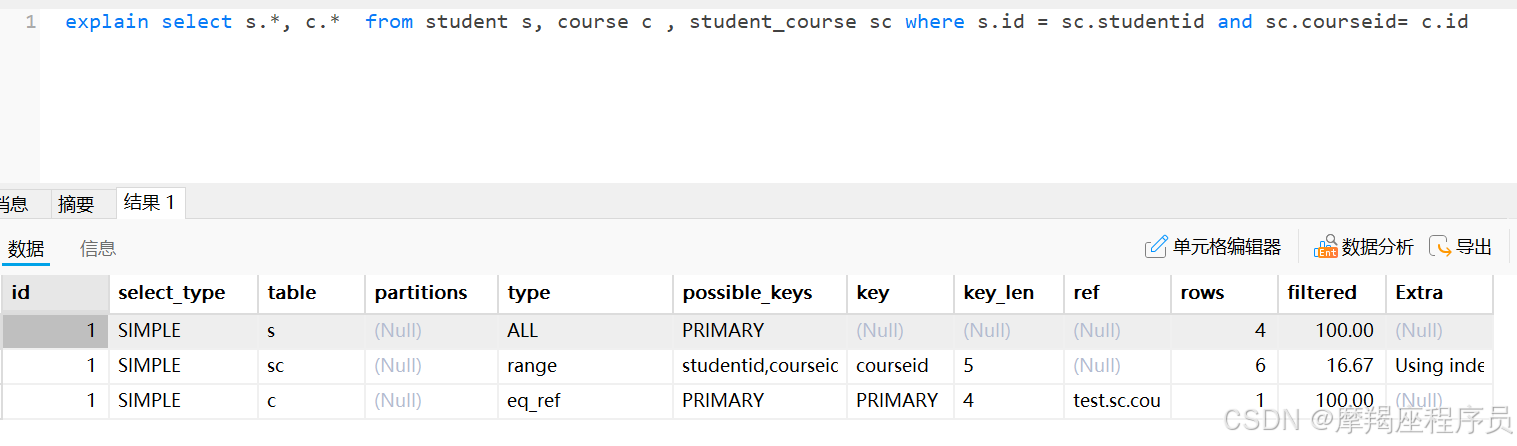
id相同,说明执行顺序从上往下;先执行student表,再执行student_course表,最后执行course表;
子查询例子:
select * from student s where s.id in (select studentid from student_course sc where sc.courseid = (select id from course c where c.name = 'MySQL'));
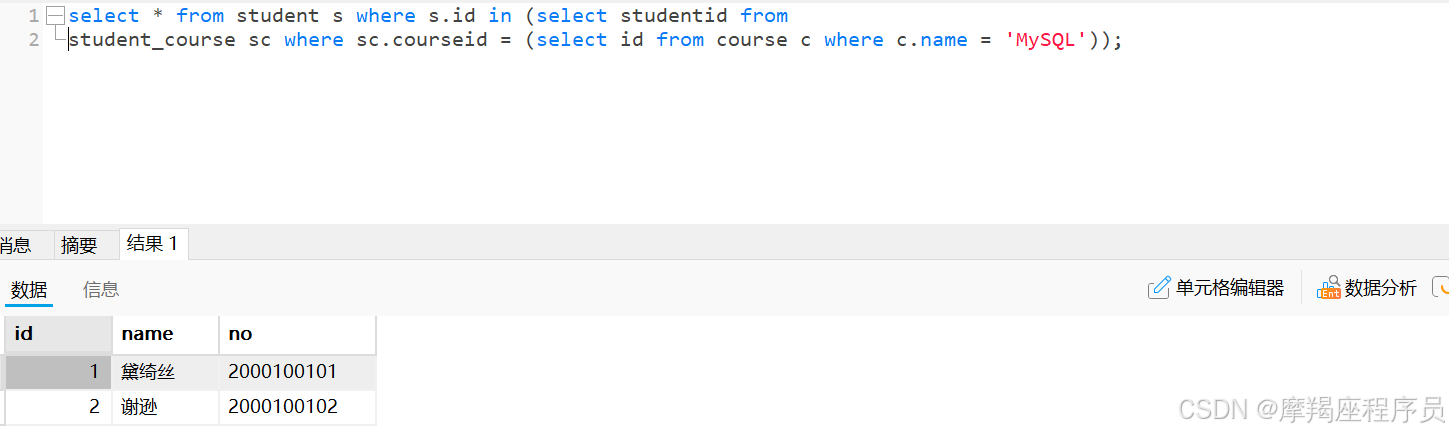
查看sql的执行计划
explain select * from student s where s.id in (select studentid from student_course sc where sc.courseid = (select id from course c where c.name = 'MySQL'));
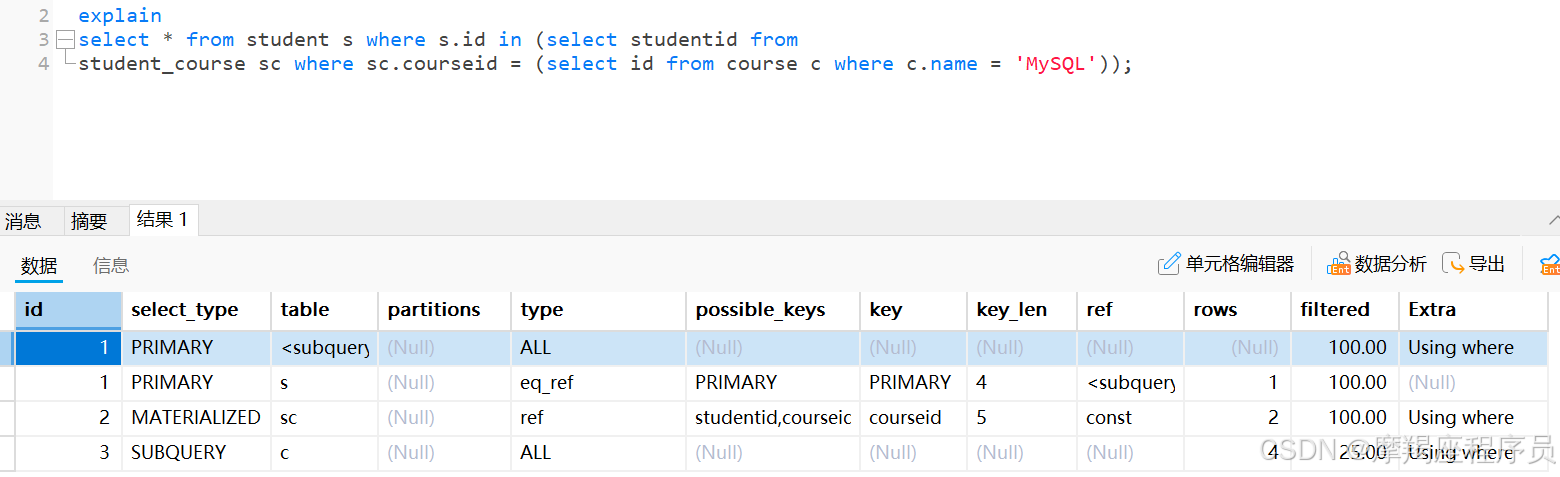
id越大,越先执行:
select_type
表示select的类型,常见的取值有SIMPLE(简单表,即不使用表连接或子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等。
type:
表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、index、all
只有在不查询表的情况下, type才会等于NULL

tb_user表的索引情况

使用主键或者唯一索引进行查询的情况下,type会是const

使用主键或唯一索引进行等值连接时,type会是eq_ref

使用到非唯一索引查询的情况下,type会是ref

使用范围查询、in查询、Like前缀匹配、日期/时间范围查询的情况下,type会是range

全索引扫描, type=index
possible_keys, key, key_len分别代表的是:
possible_keys: 可能会用到的索引
key: 实际用到的索引
key_len: 表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精准性的前提下,长度越短越好。
rows:mysql认为必须要执行的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。
filtered:表示返回结果的行数占需读取行数的百分比,filtered的值越大越好。
存储过程创建1000万条数据
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_10m_records`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE batch_size INT DEFAULT 10000; -- 每批插入10000条
DECLARE total INT DEFAULT 10000000;
WHILE i <= total DO
INSERT INTO tb_sku (sn, name, price, num, alert_num, image, update_time, category_name, brand_name, spec, sale_num, comment_num, status)
VALUES (
CONCAT('SN', LPAD(i, 10, '0')),
CONCAT('商品名称_', i),
ROUND(RAND() * 9900 + 100, 2), -- 价格 100-10000
FLOOR(RAND() * 10000),
FLOOR(RAND() * 500) + 50,
CONCAT('https://img.example.com/product_', i, '.jpg'),
DATE_ADD('2023-01-01', INTERVAL FLOOR(RAND() * 730) DAY), -- 2年内随机时间
CASE FLOOR(RAND() * 5)
WHEN 0 THEN '电子产品'
WHEN 1 THEN '服装鞋帽'
WHEN 2 THEN '食品饮料'
WHEN 3 THEN '家居用品'
ELSE '图书文具'
END,
CASE FLOOR(RAND() * 6)
WHEN 0 THEN '华为'
WHEN 1 THEN '苹果'
WHEN 2 THEN '小米'
WHEN 3 THEN '耐克'
WHEN 4 THEN '阿迪达斯'
ELSE '优衣库'
END,
CONCAT('规格_', FLOOR(RAND() * 100)),
FLOOR(RAND() * 10000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 2)
);
SET i = i + 1;
-- 每10000条提交一次
IF i % batch_size = 0 THEN
COMMIT;
SELECT CONCAT('已插入: ', i, ' 条记录') AS Progress;
END IF;
END WHILE;
COMMIT;
SELECT '插入完成' AS Result;
END调用存储过程 call insert_10m_records(); mysql数据库在生产上不建议使用存储过程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)