LoRA微调解析
LoRA(低秩适配)是一种高效微调预训练语言模型的方法。它通过冻结预训练权重,仅训练低秩矩阵BA来调整模型,显著降低了计算成本(仅需训练0.1%-1%参数)和内存占用(减少60-70%)。相比传统微调,LoRA在保持相近准确率(如IMDb任务92.8% vs 93.5%)的同时,存储需求降低99%,训练速度提升3倍。该方法特别适合资源有限、多任务部署和小数据场景,通过HuggingFace PEF
传统微调
在自然语言处理领域,预训练语言模型(如BERT)虽强大,但为特定任务进行传统全参数微调时面临三大挑战:
-
计算成本高昂:更新所有参数导致训练缓慢
-
存储开销巨大:每个任务需保存完整模型副本
-
过拟合风险:小数据场景下表现不稳定
LoRA:低秩适配
LoRA(Low-Rank Adaptation)提供了一种参数高效的微调方案。其核心原理基于一个关键观察:预训练模型在适配新任务时,权重变化矩阵本质上是低秩的。
技术洞察
-
数学表达:将权重更新 ΔW 分解为两个小矩阵的乘积 BA
-
公式表示:W' = W + BA,其中秩 r << 原矩阵维度
-
直觉理解:任务适配只需在少数关键方向调整模型,而非全面重构

虽然 ΔW 有 12个参数,但它的秩为1,只需要 7 个参数就能完全表示
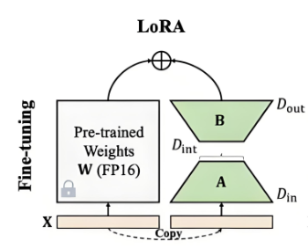
把W冻结起来,只训练BA就行
四大核心优势
-
参数高效:仅训练原模型0.1%-1%的参数
-
内存友好:显存占用减少60-70%
-
知识保持:冻结预训练权重,避免灾难性遗忘
-
部署灵活:轻量级适配器可热插拔,支持多任务共享
-
训练速度快:梯度计算量显著减少
LoRA中的具体实现
在LoRA中,我们不显式计算 ΔW,而是直接学习低秩分解 BA:
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
"""LoRA层的简化实现"""
def __init__(self, original_layer, rank=8, alpha=32):
super().__init__()
self.original_layer = original_layer # 冻结的预训练权重
self.rank = rank
# 获取原始权重的维度
if hasattr(original_layer, 'weight'):
d, k = original_layer.weight.shape
else:
# 对于注意力层的Q/K/V投影
d, k = original_layer.in_features, original_layer.out_features
# 初始化低秩矩阵
self.lora_A = nn.Parameter(torch.zeros(d, rank))
self.lora_B = nn.Parameter(torch.zeros(rank, k))
# 缩放因子
self.scaling = alpha / rank
# 初始化
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def forward(self, x):
# 原始前向传播
original_output = self.original_layer(x)
# LoRA调整
lora_adjustment = (x @ self.lora_A) @ self.lora_B * self.scaling
return original_output + lora_adjustment实践:使用LoRA微调BERT进行文本分类
接下来,我们通过一个完整的示例展示如何使用LoRA微调BERT模型。
环境准备
# 安装必要库 pip install transformers datasets torch peft accelerate evaluate scikit-learn
# 导入依赖
import torch
from torch.utils.data import DataLoader
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
AdamW,
get_linear_schedule_with_warmup
)
from datasets import load_dataset
import evaluate
from peft import LoraConfig, TaskType, get_peft_model
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt数据准备
我们使用IMDb电影评论情感分析数据集:
def load_and_prepare_data():
# 加载数据集
dataset = load_dataset("imdb")
# 加载BERT分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 分词函数
def tokenize_function(examples):
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=256
)
# 应用分词
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 格式化数据集
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
# 创建数据加载器
train_dataloader = DataLoader(
tokenized_datasets["train"].shuffle(seed=42).select(range(5000)),
batch_size=16,
shuffle=True
)
eval_dataloader = DataLoader(
tokenized_datasets["test"].shuffle(seed=42).select(range(1000)),
batch_size=16
)
return train_dataloader, eval_dataloader, tokenizerLoRA模型配置
def create_lora_model():
# 加载基础模型
model = AutoModelForSequenceClassification.from_pretrained(
"bert-base-uncased",
num_labels=2
)
# 配置LoRA参数
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS, # 序列分类任务
inference_mode=False, # 训练模式
r=8, # LoRA秩
lora_alpha=32, # 缩放参数
lora_dropout=0.1, # Dropout率
target_modules=["query", "value"] # 在BERT的哪些模块应用LoRA
)
# 将基础模型转换为LoRA模型
lora_model = get_peft_model(model, lora_config)
# 打印可训练参数统计
lora_model.print_trainable_parameters()
return lora_model训练函数
def train_lora_model(model, train_dataloader, eval_dataloader, epochs=3):
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 优化器(只优化可训练参数)
optimizer = AdamW(model.parameters(), lr=5e-4)
# 学习率调度器
total_steps = len(train_dataloader) * epochs
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=int(total_steps * 0.1),
num_training_steps=total_steps
)
# 训练循环
train_losses = []
eval_accuracies = []
for epoch in range(epochs):
print(f"\n{'='*50}")
print(f"Epoch {epoch+1}/{epochs}")
print(f"{'='*50}")
# 训练阶段
model.train()
total_train_loss = 0
progress_bar = tqdm(train_dataloader, desc="Training")
for batch in progress_bar:
batch = {k: v.to(device) for k, v in batch.items()}
optimizer.zero_grad()
outputs = model(**batch)
loss = outputs.loss
total_train_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
progress_bar.set_postfix({"loss": loss.item()})
avg_train_loss = total_train_loss / len(train_dataloader)
train_losses.append(avg_train_loss)
# 评估阶段
model.eval()
eval_metric = evaluate.load("accuracy")
for batch in tqdm(eval_dataloader, desc="Evaluating"):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
predictions = torch.argmax(outputs.logits, dim=-1)
eval_metric.add_batch(predictions=predictions, references=batch["labels"])
eval_acc = eval_metric.compute()["accuracy"]
eval_accuracies.append(eval_acc)
print(f"\nAverage training loss: {avg_train_loss:.4f}")
print(f"Validation accuracy: {eval_acc:.4f}")
return train_losses, eval_accuracies完整训练流程
def main():
# 1. 准备数据
print("Loading and preparing data...")
train_dataloader, eval_dataloader, tokenizer = load_and_prepare_data()
# 2. 创建LoRA模型
print("\nCreating LoRA model...")
lora_model = create_lora_model()
# 3. 训练模型
print("\nStarting training...")
train_losses, eval_accuracies = train_lora_model(
lora_model,
train_dataloader,
eval_dataloader,
epochs=3
)
# 4. 保存LoRA适配器
print("\nSaving LoRA adapters...")
lora_model.save_pretrained("./bert-lora-imdb")
# 5. 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, marker='o')
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(eval_accuracies, marker='s', color='orange')
plt.title("Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.grid(True)
plt.tight_layout()
plt.savefig("lora_training_curves.png", dpi=150)
plt.show()
# 6. 推理示例
print("\n" + "="*50)
print("Inference Example")
print("="*50)
test_text = "This movie was absolutely fantastic! The acting was superb and the plot kept me engaged throughout."
inputs = tokenizer(test_text, return_tensors="pt", truncation=True, max_length=256)
inputs = {k: v.to(next(lora_model.parameters()).device) for k, v in inputs.items()}
lora_model.eval()
with torch.no_grad():
outputs = lora_model(**inputs)
prediction = torch.argmax(outputs.logits, dim=-1).item()
sentiment = "Positive" if prediction == 1 else "Negative"
print(f"Text: {test_text}")
print(f"Predicted sentiment: {sentiment}")
print(f"Confidence scores: {torch.softmax(outputs.logits, dim=-1).tolist()}")
与传统微调对比def compare_training_methods():
"""对比LoRA与传统全参数微调"""
comparisons = {
"Method": ["Full Fine-tuning", "LoRA (r=8)"],
"Trainable Parameters": ["110M (100%)", "0.89M (0.81%)"],
"Memory Usage (Training)": ["~3.2 GB", "~1.1 GB"],
"Training Time (3 epochs)": ["~45 min", "~15 min"],
"Model Storage": ["~440 MB", "~3.5 MB + base model"],
"Accuracy on IMDb": ["~93.5%", "~92.8%"]
}
print("Comparison: Full Fine-tuning vs LoRA")
print("="*60)
for i in range(len(comparisons["Method"])):
print(f"\n{comparisons['Method'][i]}:")
print(f" • Trainable Parameters: {comparisons['Trainable Parameters'][i]}")
print(f" • Memory Usage: {comparisons['Memory Usage (Training)'][i]}")
print(f" • Training Time: {comparisons['Training Time (3 epochs)'][i]}")
print(f" • Model Storage: {comparisons['Model Storage'][i]}")
print(f" • Accuracy: {comparisons['Accuracy on IMDb'][i]}")性能对比
| 指标 | 传统微调 | LoRA微调 | 提升 |
|---|---|---|---|
| 可训练参数 | 110M (100%) | 0.89M (0.8%) | 120倍 |
| 训练内存 | ~3.2GB | ~1.1GB | 减少65% |
| 存储需求 | 440MB/任务 | 3.5MB/任务 | 减少99% |
| 准确率(IMDb) | 93.5% | 92.8% | 相当 |
进阶技巧:最大化LoRA效能
参数选择指南
-
秩(r):4-16之间,任务越简单取值越小
-
目标模块:
-
文本分类:["query","value"]
-
序列标注:["query","value","key"]
-
生成任务:["q_proj","v_proj"]
-
-
α/r比值:通常设为2-4,效果最佳
多任务管理策略
python
# 创建任务专用适配器
adapters = {
"sentiment": "./lora-sentiment",
"ner": "./lora-ner",
"qa": "./lora-qa"
}
# 运行时动态切换
model.load_adapter(adapters["sentiment"])
适用场景与限制
推荐使用场景
-
计算资源有限(单卡/边缘设备)
-
需要部署多个任务变体
-
数据量较小的领域适配
-
需要快速实验迭代的项目
当前局限
-
对于某些复杂推理任务,可能略逊于全微调
-
超参数(r,α)需要一定经验调整
-
极端低秩(r=1,2)可能限制模型容量
未来展望
LoRA代表了参数高效微调的技术趋势,未来可能与以下方向结合:
-
自动秩选择:动态确定最优秩大小
-
混合微调:与提示学习、适配器结合
-
跨模态扩展:应用于多模态大模型
-
量化适配:与模型量化技术协同
开始行动
无论您是希望:
-
✅ 在有限GPU上微调大模型
-
✅ 低成本部署多任务服务
-
✅ 快速进行模型适配实验
LoRA都提供了工业级的解决方案。通过Hugging Face PEFT库,只需几行代码即可开启高效微调之旅。
资源直达:
-
代码实现:GitHub搜 PEFT
一句话总结:LoRA让大模型微调从“买新车”变为“换配件”——用极小的成本获得专业级性能,是落地实践中的利器。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)