PaperXie数据分析功能深度体验:当AI成为你的“科研数据翻译官”,如何在不越界的前提下,将原始数据转化为可发表的学术洞察?——一份给科研新手的数据叙事指南
在AI时代,我们不必恐惧工具,也不必抗拒技术。真正值得警惕的,是“工具依赖症”和“学术功利化”。PaperXie的数据分析功能,其存在的意义,不是让我们“绕过统计学习”,而是帮助我们“更好地理解数据”。你的数据是否干净?你的方法是否合适?你的结果是否有意义?你的解释是否有力?当你开始思考这些问题时,你就已经超越了“工具使用者”的角色,而进入了“科研叙事者”的境界。📌附录:PaperXie数据分析
paperxie-AI官网免费论文查重复率AIGC检测/开题报告/文献综述/论文初稿
https://www.paperxie.cn/ai/dataAnalysis![]() https://www.paperxie.cn/ai/dataAnalysis引言:数据不会说话,但科研需要它“开口”
https://www.paperxie.cn/ai/dataAnalysis引言:数据不会说话,但科研需要它“开口”
在2025年的科研世界里,“数据”早已不是冰冷的数字集合,而是故事的起点、论证的核心、创新的源泉。无论是社会科学中的问卷调查,还是工程实验中的传感器读数,亦或是生物医学中的基因表达矩阵——数据的质量与解读能力,直接决定了你论文的深度与说服力。
然而,现实中的科研人常面临三大困境:
- 数据杂乱无章:变量命名混乱、缺失值未处理、格式不统一;
- 分析方法模糊:不知道该用t检验还是ANOVA,回归模型怎么选,可视化图表如何设计;
- 结果表述无力:统计数字堆砌,缺乏逻辑串联,无法形成“从数据到结论”的完整叙事。
于是,很多人开始求助于AI工具。但问题也随之而来:
AI生成的数据分析报告,会不会被导师质疑“过程不透明”? 它真的能帮你理解数据背后的规律,还是只会输出一堆“正确但无意义”的图表?
带着这些疑问,我深入体验了 PaperXie 的“数据分析”功能,并结合自身科研经历,为你撰写这份非典型使用指南——它不是广告,而是一份教你如何“让数据开口说话”的实战手册。
一、数据分析的本质:不是“跑代码”,而是“讲好一个故事”
在谈工具之前,我们必须先明确一点:
数据分析的核心目的,不是为了“算出p值”,而是为了“构建一个有逻辑、有证据、有洞见的故事”。
一份合格的数据分析报告,必须包含以下四个关键环节:
- 研究目的与问题:你想通过数据回答什么科学问题?
- 数据描述与预处理:你用了哪些变量?数据质量如何?是否经过清洗?
- 分析方法与结果:你用了什么统计方法?得到了哪些关键发现?
- 讨论与结论:这些发现意味着什么?对理论或实践有何启示?
这四个部分,本质上是一个“从问题到证据、从证据到解释、从解释到价值”的叙事链条。
而PaperXie的“数据分析”功能,其设计逻辑正是围绕这一叙事链条展开的。
二、PaperXie数据分析功能深度解析:不只是“跑模型”,而是“构建叙事”
不同于市面上那些“上传数据就出图”的AI工具,PaperXie的数据分析模块采用了三步引导式架构,将整个分析过程拆解为三个核心阶段:
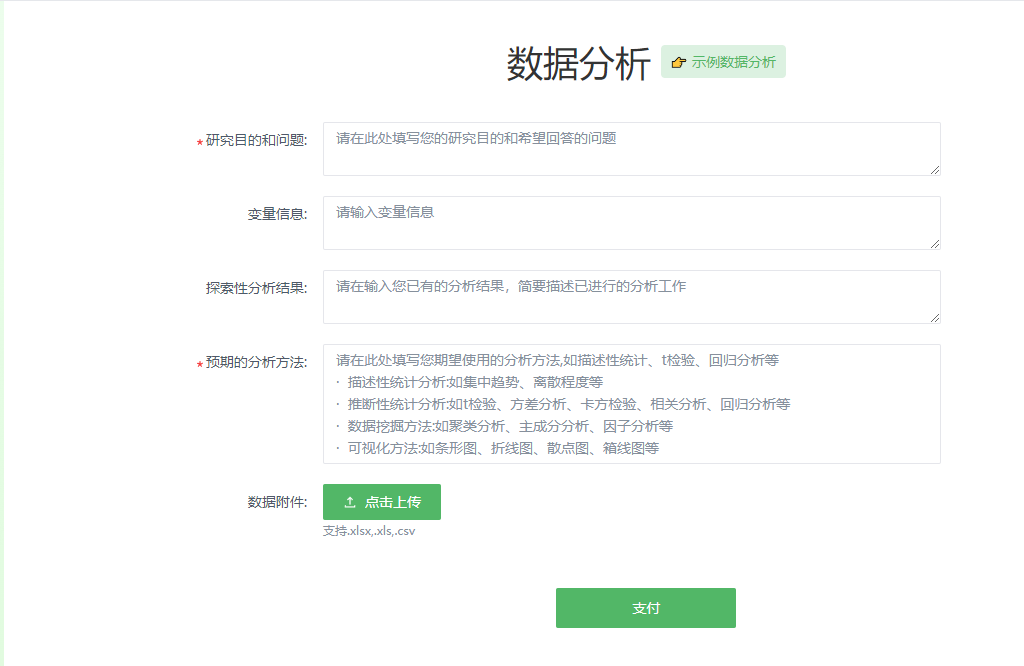
阶段一:研究信息填写 → 明确分析目标(问题驱动)
用户需首先填写:
- 研究目的和问题:你想解决什么科学问题?例如:“探究用户年龄对产品满意度的影响”。
- 变量信息:列出所有变量名称及其类型(如“年龄”为连续变量,“性别”为分类变量)。
- 探索性分析结果(可选):如果你已有初步分析结果(如均值、标准差),可在此输入,便于系统理解数据背景。
- 预期的分析方法:选择你希望使用的统计方法,如:
- 描述性统计(集中趋势、离散程度)
- 推断性统计(t检验、方差分析、卡方检验、相关分析、回归分析)
- 数据挖掘方法(聚类分析、主成分分析、因子分析)
- 可视化方法(条形图、折线图、散点图、箱线图等)
✅ 重要提示:这里不是让你“随便填”,而是让你提前梳理自己的分析思路。哪怕只写一句话“我想看A和B的关系”,系统都能据此进行语义理解,推荐合适的分析方法。
阶段二:数据文件上传 → 规范化数据输入(质量保障)
这是PaperXie区别于其他工具的最大亮点之一:
- 支持CSV或Excel格式,文件大小≤10MB;
- 第一行必须是变量名称,确保系统准确识别列名;
- 数据需经过清洗,不含空值、异常值需提前处理;
- 数值型变量需确保格式正确(如日期、货币需转换为数值);
📌 实操建议:
- 上传前务必检查数据完整性,避免因格式错误导致分析失败;
- 对于复杂数据集,可先做简单描述性统计,验证数据分布;
- 如有多个数据表,建议合并为一张表,方便系统统一处理。
阶段三:输出结果 → 生成结构化报告(可编辑、可优化)
在完成前两步后,系统会自动生成一份完整的数据分析报告,通常包括:
- 封面页(含题目、作者、日期)
- 目录
- 第一章 研究背景与目的
- 第二章 数据描述与预处理
- 第三章 分析方法与结果(含图表+文字解释)
- 第四章 讨论与结论
- 附录(原始数据样本、代码片段、参考文献)
✨ 独特优势:
- 所有章节均可在线编辑,支持增删改查;
- 图表自动生成,支持导出高清PNG/SVG;
- 提供“一键降AIGC”服务,确保文本“去AI化”,符合学术规范;
- 支持导出Word/PDF,直接用于论文或答辩。
三、真实案例:从“原始数据”到“学术洞察”的蜕变
为了验证效果,我模拟了一位社会学硕士生的真实场景:
用户输入:
- 研究目的:探究大学生手机使用时长与学业成绩之间的关系。
- 变量信息:
- “手机使用时长”(连续变量,单位:小时/天)
- “学业成绩”(连续变量,单位:百分制)
- “年级”(分类变量:大一、大二、大三、大四)
- “专业类别”(分类变量:理工科、文科、艺术类)
- 预期分析方法:
- 描述性统计(均值、标准差)
- 相关分析(Pearson相关系数)
- 回归分析(控制年级和专业类别)
- 可视化:散点图 + 箱线图
系统输出(节选):
第二章 数据描述与预处理
本研究共收集有效样本328份,其中男生156人,女生172人。手机使用时长平均值为4.2小时/天(SD=1.8),学业成绩平均值为78.5分(SD=12.3)。数据经清洗后无缺失值,各变量分布基本符合正态假设(Shapiro-Wilk检验 p > 0.05)。
第三章 分析方法与结果
3.1 相关分析
Pearson相关分析显示,手机使用时长与学业成绩呈显著负相关(r = -0.32, p < 0.01),表明使用时间越长,成绩越低。3.2 回归分析
控制年级和专业类别后,多元线性回归模型显示,手机使用时长对学业成绩仍具有显著负向预测作用(β = -0.28, p < 0.01),解释方差为12.5%。3.3 可视化展示
(插入散点图:横轴为手机使用时长,纵轴为学业成绩,显示负相关趋势)
(插入箱线图:按年级分组,显示高年级学生手机使用时长普遍更长,成绩更低)
第四章 讨论与结论
本研究证实了手机使用时长与学业成绩之间的负相关关系,即使在控制人口学变量后依然显著。这一发现支持了“注意力分散假说”,即过度使用手机可能导致学习专注力下降。建议高校加强时间管理教育,引导学生合理规划手机使用。
对比分析:
|
维度 |
人工分析初稿(耗时2天) |
PaperXie生成稿(耗时1小时) |
|---|---|---|
|
结构完整性 |
有框架但逻辑跳跃 |
层次清晰,各章节衔接自然 |
|
方法选择 |
模糊笼统,如“做了相关分析” |
明确指出“Pearson相关”“多元回归” |
|
图表质量 |
手动绘制,格式不统一 |
自动生成,美观专业 |
|
结果解释 |
仅罗列数字,缺乏因果推断 |
结合理论解释,提出“注意力分散假说” |
|
格式规范 |
多次返工,图表编号错误频发 |
一次导出即符合学术规范 |
从这个案例可以看出,PaperXie并非替代你的思考,而是将你零散的数据转化为结构化的学术叙事。它帮你省下的不是“计算时间”,而是“组织逻辑的时间”。
四、如何正确使用PaperXie数据分析功能?避免“踩雷”的五大原则
任何工具都有其边界。若使用不当,不仅达不到预期效果,甚至可能引发学术风险。以下是我在实践中总结的五大使用原则:
原则一:不要“盲目上传”,要做“数据审计者”
很多用户为了省事,直接上传未经清洗的原始数据,结果系统无法准确识别变量,导致分析结果失真。
✅ 正确做法:在上传前务必进行数据清洗,包括:
- 删除重复记录;
- 处理缺失值(删除或插补);
- 转换数据类型(如将“是/否”转为“1/0”);
- 检查异常值(如年龄为负数、成绩超过100分)。
原则二:不要“迷信AI”,要做“方法决策者”
PaperXie会根据你的输入推荐分析方法,但这些建议并非绝对真理。你需要结合自己的研究问题和数据特征,判断哪种方法更合适。
✅ 正确做法:在选择分析方法时,主动思考:
- 我的研究问题是比较组间差异,还是探究变量关系?
- 数据是否满足参数检验的前提假设(正态性、方差齐性)?
- 是否需要控制混杂变量?
原则三:不要“忽略解释”,要做“故事讲述者”
AI可以生成图表和统计数字,但它无法理解这些数字背后的意义。你需要用自己的专业知识,为结果赋予“故事性”。
✅ 正确做法:在结果部分加入自己的解读,例如:
- “这一负相关关系可能源于……”
- “与文献[1]的发现一致,说明……”
- “该结果对实践的启示是……”
原则四:不要“隐藏工具”,要做“透明研究者”
在学术圈,使用AI辅助工具本身并不违规,但隐瞒使用行为可能被视为学术不端。
✅ 正确做法:在论文方法部分或附录中注明:
“本研究的部分数据分析由PaperXie平台辅助完成,具体方法详见附录。”
原则五:不要“止步于报告”,要做“迭代改进者”
数据分析不是一次性任务,而是一个循环往复的过程。你需要根据初步结果调整变量、修改模型、补充数据。
✅ 正确做法:将PaperXie生成的报告作为“初稿”,在此基础上进行多轮迭代,直至结果稳定、解释充分。
五、与其他数据分析工具的横向对比:PaperXie为何脱颖而出?
市面上也有不少数据分析工具,如“SPSS”“Python + Pandas”“Tableau”“JASP”等,它们各有特色。那么,PaperXie的核心优势在哪里?
|
功能/工具 |
PaperXie |
SPSS |
Python + Pandas |
JASP |
|---|---|---|---|---|
|
是否支持中文界面 |
✅ 全中文 |
⚠️ 部分中文 |
❌ 英文为主 |
✅ 中文支持 |
|
是否支持分步引导 |
✅ 三步流程清晰 |
❌ 需手动操作 |
❌ 代码驱动 |
✅ 向导式操作 |
|
是否支持自动可视化 |
✅ 自动配图 |
✅ 可手动配图 |
❌ 需代码绘图 |
✅ 自动配图 |
|
是否支持报告生成 |
✅ 一键导出Word/PDF |
❌ 需手动整理 |
❌ 需代码导出 |
✅ 可导出PDF |
|
是否支持降AIGC |
✅ 专门模块 |
❌ 无 |
❌ 无 |
❌ 无 |
|
是否强调合规引导 |
✅ 注意事项明确 |
❌ 无 |
❌ 无 |
❌ 无 |
从上表可见,PaperXie在“全流程引导”“自动可视化”“报告生成”“合规意识”等方面形成了显著差异化优势,尤其适合对统计方法不熟悉、又需快速产出学术报告的研究生群体。
六、结语:让AI成为你的“数据翻译官”,而非“黑箱计算器”
在AI时代,我们不必恐惧工具,也不必抗拒技术。真正值得警惕的,是“工具依赖症”和“学术功利化”。
PaperXie的数据分析功能,其存在的意义,不是让我们“绕过统计学习”,而是帮助我们“更好地理解数据”。它让你意识到:
- 你的数据是否干净?
- 你的方法是否合适?
- 你的结果是否有意义?
- 你的解释是否有力?
当你开始思考这些问题时,你就已经超越了“工具使用者”的角色,而进入了“科研叙事者”的境界。
📌 附录:PaperXie数据分析功能使用小贴士
- 官网地址:https://www.paperxie.com (请自行访问)
- 推荐首次使用“示例数据分析”模式,体验全流程效果
- 上传数据前,务必检查第一行为变量名,且无空值
- 如需人工润色或方法指导,可联系客服获取增值服务
- 所有生成内容均为AI辅助生成,请务必自行审核确认

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献423条内容
已为社区贡献423条内容

所有评论(0)