Python常用标准库及文件操作
附上一张语法速查表
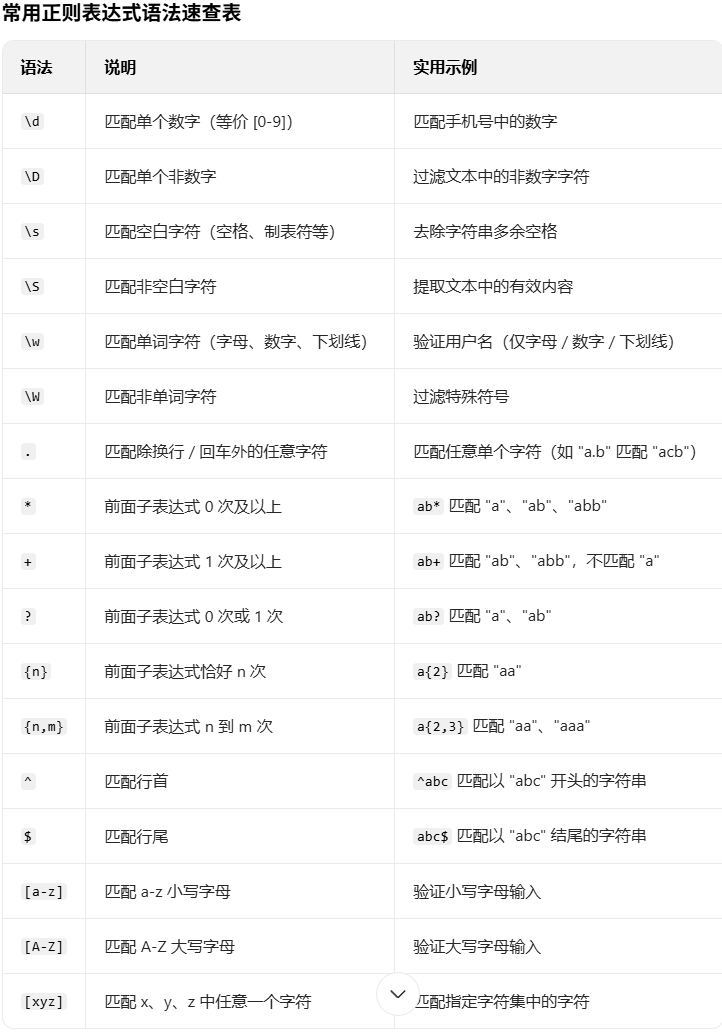
=========================================================================
上一节,我们讲述了库的本质是函数的集合,通常包含预编译的代码模块,为我们提供可复用的功能,减少我们的重复劳动,是一个很方便的东西。现在这一节来让我们看看究竟有那些比较实用的第三方库。为了方便记忆,我会标出重要性以及常见的应用场景辅助记忆。
标准库
就像Python本体就自带诸多函数一样,也有许多库也被Python本体携带着。这些库我们称之为标准库,它们无需额外下载即可使用。
一、time库
time.time()——获取1970年1月1日0时0分0秒到当前时间所经过的秒数。
import time
start = time.time()
i = 0
while i < 10000000:
i += 1
end = time.time()
print("程序运行耗时:", start-end)time.sleep()——控制程序暂停一段时间,默认为1秒。
import time
time.sleep(10)
print("现在是十秒之后")常见场景:软件测试工程师在测试代码功能时,代码运行耗时往往也是一项重要指标。通过time库可以获取时间,监测代码状态。
二、random库
生成随机数。
import random
array = [random.random(), random.uniform(1, 2), random.randint(0, 9)]
# 生成0~1之间的随机小数 生成1~2之间的随机小数 生成0~9之间的随机整数
print(array)random.seed()——设置一个随机数种子(种子名字可以任意填写),记录下一次随机函数给出的值。以后运行该随机函数时将会给出同样的值,可以复现结果。
import random
ls = ['一等奖', '二等奖', '三等奖', '谢谢惠顾']
random.seed(123)
print(ls[random.randint(0, 3)] # 不论该代码运行多少次最终结果都会和第一次一样常见场景:在训练AI时常有随机切分数据集,做成训练集和测试集的需求。使用random库以随机切分,同时random.seed()记录随机状态,方便复现最佳训练成果。
三、re库
1)用于匹配特定字符的方法
import re
mes = '张三、李四、王五、赵六、李四'
rs1 = re.match('张三', mes) # 从参数2的起始位置开始查找满足参数1的内容,起始位置不满足则返回None
rs2 = re.search('李四', mes) # 从参数2查找满足参数1的内容,若匹配多个结果则只返回第一个
rs3 = re.findall('李四', mes) # 从参数2查找满足参数1的内容,若匹配多个结果则全部返回
printr(rs1, rs2, rs3)2)正则表达式
#较为繁杂,建议结合代码练习
匹配字符的范围:
[xyz]:字符集合,即匹配所包含的任意一个字符。例如[abc]可以匹配plain中的a。
[a-z]:字符范围,即匹配指定范围内的任意字符。例如[a-z]可以匹配a到z范围内的任意小写字母。
import re
mes ='Python93,C87,Java63,C++88'
rs1= re.search('[cn]',mes)
rs2= re.findall('[0-9]',mes)
rs3 = re.findall('[cn][0-9]',mes)
print(rs1)
print(rs2)
print(rs3)匹配字符次数:
*:匹配前面的子表达式任意次(大于等于0次)。例如z0*能匹配"z"、"zo"和"z00",*等价于{0,}。
+:匹配前面的子表达式一次或多次。例如"z0+"能匹配"z0"和"z00”,但不能匹配"z",+等价于{1,}
?:匹配前面的子表达式0次或一次。例如"do(es)?"可以匹配"do"或"does",?等价于{0,1}。
^:匹配输入行首。相当于re.match()的功能。
$:匹配输入行尾。
{n}:匹配n次,n为非负整数。例如"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个"o”。
{n,}:至少匹配n次,n为非负整数。例如"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有"o"。"o{1,}"等价于"o+","o{0,}"则等价于"o*"。
{n,m}:最少匹配n次且最多匹配m次,m和n均为非负整数且n<m。例如"o{1,3}"将匹配"fo0000od"中的前3个"o"和后3个"o"。"o{0,1}"等价于"o?"。请注意,逗号和两个数之间不能有空格。
import re
mes ='da2a7ddbre77yifed777t3fefd7777b'
rs = re.findall('[a-z]*[0-9][a-z]',mes)
print(rs)
phone_num= input("请输入您的手机号码:")
rs2 =re.findall('^1[0-9]{10}$',phone_num)
print(rs2)
QQ_number = input("请输入您的QQ号:")
rs3 = re.match('[1-9][0-9]{4,10}$',QQ_number)
print(rs3)匹配字母类型:
\d:匹配一个数字类字符,等价于[0-9]。
\D:匹配一个非数字类字符,等价于[^0-9]。^在方括号中表示非,即不匹配输入字符的首位字符。
\s:匹配任何不可见字符,包括空格、制表符、分页符等,等价于[\f\n\r\t\v]。
\S:匹配任何可见字符,等价于[^\f\n\r\t\v]。
\w:匹配包括下画线的任何单词字符,等价于"[A-Za-z0-9_]"。
\W:匹配任何不包括下画线的非单词字符,等价于"[^A-Za-z0-9_]"。
\b:匹配一个单词的边界,即单词中与空格邻接的字符。
\B:匹配非单词边界。例如"er\B"能匹配"verb"中的"er",但不能匹配"never"中的"er",因为"er"是"never"的单词边界。
\f:匹配一个分页符。
\n:匹配一个换行符。
\r:匹配一个回车符。
\t:匹配一个制表符。
\v:匹配一个垂直制表符。
.:匹配除"\n"和"r"之外的任何单个字符。
import re
user_name = input("请输入您的用户名:")
rs = re.findall('^[A-Za-z_]\w{7,}$',user_name)
print(rs)
mes ='verb very never every'
rs2 = re.findall(r'\w+er\B',mes)
rs3 = re.findall('.e', mes)
print(rs2)
print(rs3)3)贪婪/非贪婪模式
在使用正则表达式匹配字符时,默认一般是贪婪模式。贪婪模式一般指,在符合正则表达式的前提下,会一直匹配直到无法再满足正则表达式为止。与之对应的非贪婪模式则是指,只要能满足正则表达式就立刻停止匹配。非贪婪模式可以通过额外添加'?'使用。
import re
mes = 'ccc739134792hd'
rs = re.findall('ccc\d+',mes)
rs2 = re.findall('ccc\d+?',mes)
print(rs)
print(rs2)4)或和组
或:用'|'表示。用作将两个匹配条件做逻辑“或”运算。
import re
mes ='verb very never every'
rs = re.findall(r'\w+ev|\w+ry',mes)
print(rs)组:用'()'表示。括号内的正则表达式所捕捉的内容将会被单独输出。
import re
mes ='verb very never every'
rs = re.findall(r'e(.+)(.)r',mes)
print(rs)
# [('rb very never ev', 'e')]
# 组工作时会创建一个元组,将所捕捉到的内容挨个存入然后一并输出,最多捕捉九个。元组返回给findall后会被套上一层列表输出,所以各位读者看到的输出会如上一行所示。四、读取文件
1)打开文件
这里要用到的函数是open()。不过需要注意的是,此处的打开并不是我们常规意义上的打开,并不会突然有个什么界面,比如txt文本编辑器之类东西冒出来。打开只是代表着这份文件被引入了缓存,建立起了一个数据交换的通道。
file = opoen(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
虽然参数很多,但是需要用的其实很少。
file:以字符串的形式填入文件名/或文件路径,文件路径既可以按照函数的导入一样使用../之类的语法,也可以使用 r'绝对路径',把整条路径填进来。
# 绝对路径 是从根目录(如C:\或/)开始的完整路径,例如C:\Users\file.txt或/home/user/file.txt,能唯一指向文件位置。所以r往往是建议的,否则\U就会被当作一个转义字符处理。当然你也可以采取'\\'来正常表达\。
# 相对路径 是相对于当前工作目录的路径,例如./subdir/file.txt(当前目录下的子目录)或../file.txt(上级目录),依赖当前目录的上下文。
mode:读取模式,主要的模式有以下几种。
'r' 只读模式。如果计算机中此文件不存在则会出现异常错误;如果此文件存在则只允许对文件进行读取操作
'w' 覆盖写模式。只允许对文件进行写入操作,如果计算机中此文件已存在,则先清除此文件中的内容再写入;如果此文件不存在则创建一个新文件再写入
'a' 追加写模式。只允许对文件进行写入操作,如果计算机中存在此文件,则在该文件的未尾继续写入(不删除文件原来的内容),如果不存在此文件,则创建一个新文件再写入
'+' 增加模式。与'r'、'w'、'a'模式一同使用,可在原功能基础上增加读写功能,例如'r+'表示文件可读可写encoding:解码方法。我们知道,不论什么文件,存储到计算机里面时,最后都会被转化为0/1.虽然计算机能识读但是显然我们不行。于是我们此时就需要一本“字典”让计算机可以对照着它,将我们不认识的二进制数值转化为熟悉的汉字或英语。我们常用的一般是'UTF-8'。当然,世界上有很多种类的“字典”,并非所有的内容都是采用'UTF-8'翻译的。所以有些时候如果我们在翻译的时候用了不恰当的字典可能会导致意外情况,比如乱码之类的。
重要的是务必记得即时关闭文件,避免文件遭遇不必要的篡改。
file.close()所以为了安全起见,我们更推荐的方法是使用关键字with。后续操作文件的代码块进行缩进,表示从属于with。缩进代码全部运行完后,with语句将会自动关闭文件,甚至在代码出现Error,程序终止时with也能很好的关闭文件,非常的推荐。
with open(file_path, ...) as file2)读取文件
file.read(size=-1) #从文件当前位置中读取size个字符的内容,默认值为读取全部。
file.readline(size=-1) #从文件当前行读取size个字符的内容,默认值为读取全部。
file.readlines(hint=-1) #从文件当前行读取hint个字符的内容。默认值为读取全部行,并返回一个列表,列表中每一个元素为文件内一行的内容。小文件可以通过read()函数直接读取,但是文件较大时建议采用后两种方式逐行读取以提高效率。或者采用如下for循环方式也可以逐行读取。
for line in file:
代码块需要注意的是虽然肉眼不可见,但是每一行的末尾都会有一个换行符'\n'存在。
3)写入文件
write(text) # 在指针位置将text字符串写入文件
writelines(lines) #把字符串列表(列表中每个元素都为字符串)写入文件,不会自动添加'\n'4)指针
在前文中,无论是读取还是写入操作,我都多次提到了"指针"这个概念。那么究竟什么是指针呢?通俗地说,就像你打开一个txt文本文件时,输入光标就相当于指针。指针指向的位置,也就是你当前鼠标光标所在的位置。对于操作当前指针所在位置Python也提供了函数。
seek(cookie, whence=0)cookie:表示相对于whence位置的偏移量,如果为正数表示向右偏移,如果是负数表示向左偏移。一个汉字的偏移量是3。
whence:表示文件指针设定的位置,默认值为0,表示从文件开头处开始计算,值为1表示从当前位置开始计算,值为2表示从文件结尾处开始计算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)