大模型使用成本和效率——大家是怎么选的?
摘要:研究通过双对数坐标分析AI工作负载的成本-用量关系,揭示了四类典型分布:1)高端工作负载(高成本高用量,如技术领域);2)大众市场驱动者(低成本高用量,如编程和角色扮演);3)专业领域(高成本低用量,如金融和健康);4)利基工具(低成本低用量,如翻译)。开源模型主导低成本区域,而闭源模型占据高价值市场。研究发现存在"杰文斯悖论"效应:成本降低反而刺激总用量增长,同时模型质
模型的使用成本是影响用户行为的关键因素。本节将重点分析不同人工智能工作负载类别在成本-使用量关系图上的分布情况。通过观察各类别在双对数坐标的成本-使用量散点图中的聚集位置,我们识别出工作负载是集中于低成本-高用量区域,还是高成本-专业化细分市场的规律。我们也将类比杰文斯悖论效应,即低成本类别通常对应更高的总使用量,尽管我们并不试图正式分析该悖论或因果关系。
按类别划分的人工智能工作负载细分分析
上方的散点图揭示了人工智能用例的明显细分,根据其总使用量(总令牌数)与单位成本(每百万令牌成本)进行映射。一个重要的初步观察是,两个坐标轴都是对数坐标。这种对数缩放意味着图表上微小的视觉距离对应着现实世界中数量与成本的巨大倍数差异。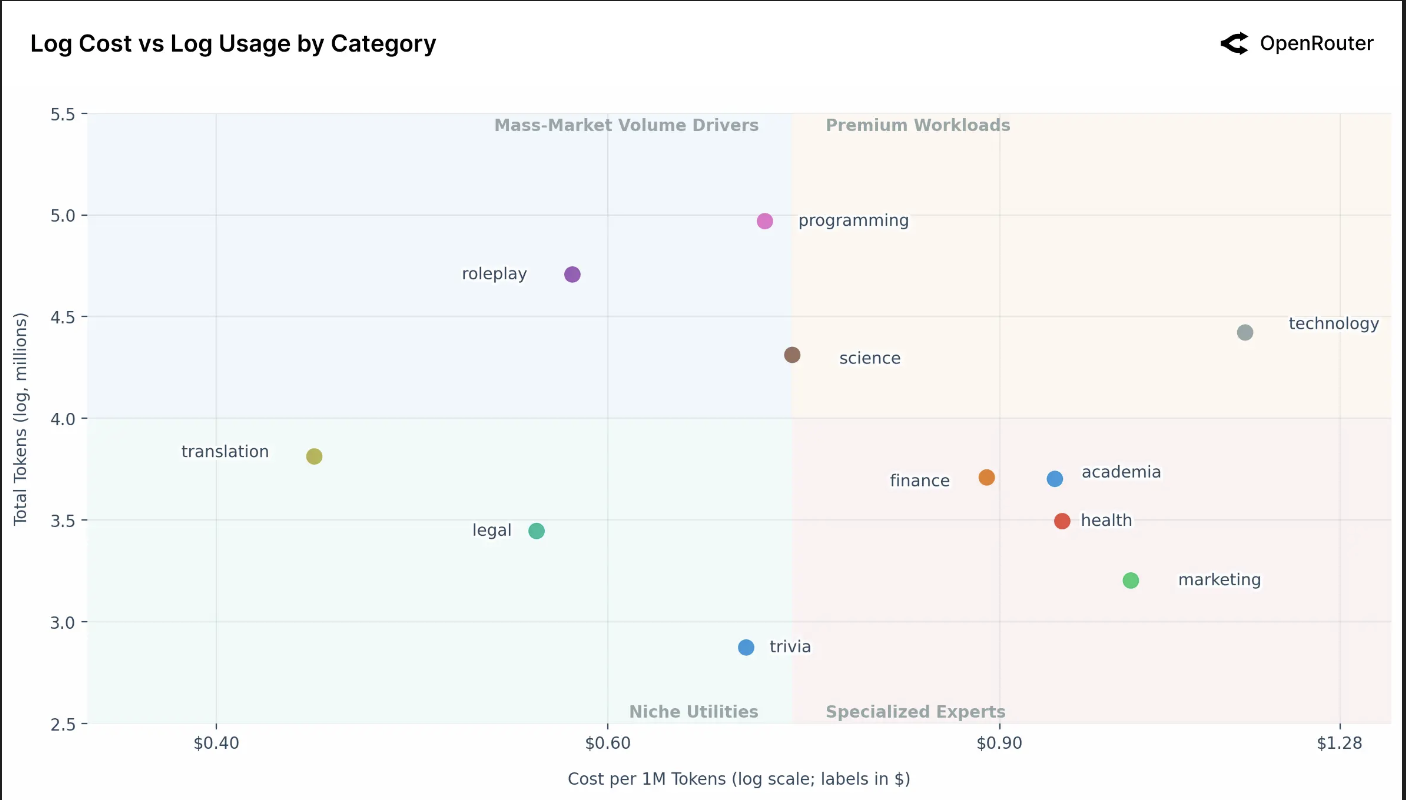
图表被中位成本线(每百万令牌 0.73 美元)垂直分割,有效地创建了一个四象限框架,以简化跨类别的人工智能市场分析。
请注意,这些终端成本与公布的标价不同。高频工作负载受益于缓存,这降低了实际支出,产生的有效价格远低于公开列出的价格。图中显示的成本指标综合了提示词和补全令牌的混合费率,更准确地反映了用户实际支付的总成本。数据集也排除了自带密钥活动,以隔离标准化的、平台中介的使用情况,避免自定义基础设施设置造成的扭曲。
高端工作负载(右上象限):此象限包含高成本、高使用量的应用,现在包括技术和科学类别,正好位于交界处。这些代表了高价值且被大量使用的专业工作负载,用户愿意为性能或专业能力支付溢价。技术类别是一个显著的异常值,其成本远高于任何其他类别。这表明作为用例的技术(可能与复杂的系统设计或架构有关)可能需要更强大且昂贵的模型进行推理,但它仍保持着高使用量,表明了其不可或缺的本质。
大众市场用量驱动者(左上象限):此象限定义为高使用量和低于或等于平均水平的低成本。该区域由两个巨大的用例主导:角色扮演、编程以及科学。
- 编程作为"杀手级专业"类别脱颖而出,展现了最高的使用量,同时具有高度优化的中位成本。
- 角色扮演的使用量巨大,几乎可与编程匹敌。这是一个惊人的洞见:面向消费者的角色扮演应用驱动的参与量与顶级专业应用相当。
这两个类别的庞大规模证实了专业生产力与会话娱乐都是人工智能主要且巨大的驱动力。该象限的成本敏感性,如前所述,正是开源模型已找到显著优势的领域。
专业专家领域(右下象限):此象限容纳了使用量较低、成本较高的应用,包括金融、学术、健康和市场营销。这些都是高风险、利基的专业领域。较低的总使用量是合理的,因为人们咨询人工智能处理"健康"或"金融"问题的频率可能远低于"编程"。用户愿意为这些任务支付显著溢价,很可能是因为对准确性、可靠性和领域特定知识的需求极高。
利基工具应用(左下象限):此象限包含低成本、低使用量的任务,包括翻译、法律和冷知识。这些是功能性、成本优化的工具应用。翻译是该组中使用量最高的,而冷知识是最低的。它们的低成本和相对较低的使用量表明,这些任务可能已被高度优化、"解决"或商品化,存在廉价且足够好的替代方案。
如前所述,图表上最显著的异常值是技术类别。它以相当大的幅度占据了最高的每令牌成本,同时保持着高使用量。这强烈表明存在一个愿意为高价值、复杂答案(例如系统架构、高级技术问题解决)支付高额费用的细分市场。一个关键问题是,这种高价格是由高用户价值("需求侧"机会)驱动,还是由高服务成本("供给侧"挑战)驱动,因为这些查询可能需要最强大的前沿模型。技术领域的"玩法"正是服务于这个高价值市场。一个能够服务该细分市场的提供商,或许通过高度优化的专业模型,有可能抢占一个利润率更高的市场。
人工智能模型的有效成本与使用量对比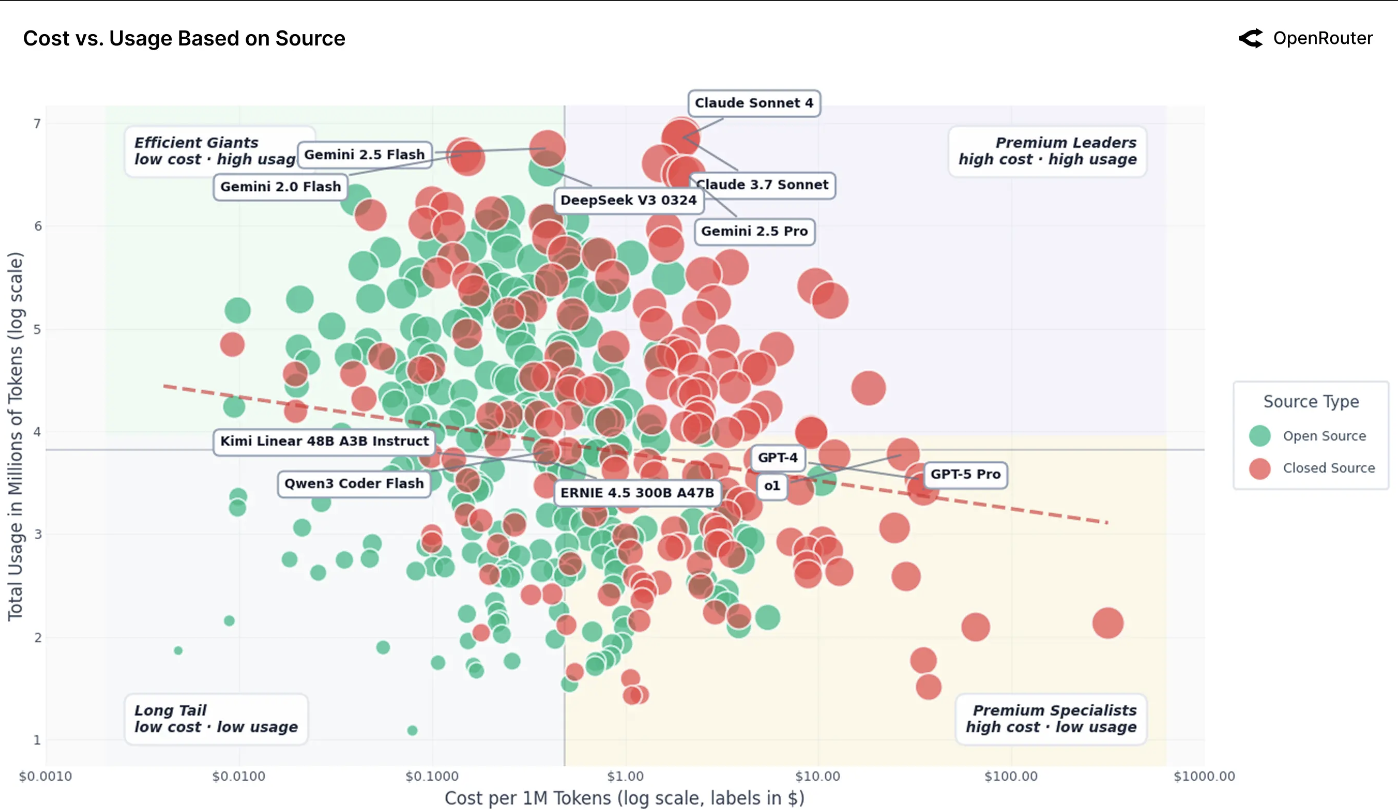
开源与闭源模型格局:成本 vs. 使用量(双对数坐标)。每个点代表 OpenRouter 上提供的一个模型,按来源类型着色。闭源模型聚集在高成本、高使用量象限,而开源模型主导低成本、高用量区域。虚线趋势线几乎平坦,显示成本与总使用量之间相关性有限。注:该指标综合了提示词和补全令牌的平均值,且由于缓存,有效价格通常低于标价。自带密钥活动已排除。
出现了两种明显的模式:来自 OpenAI 和 Anthropic 的专有模型占据高成本、高使用量区域,而像 DeepSeek、Mistral 和 Qwen 这样的开放模型则集中在低成本、高用量区域。这种模式支持一个简单的启发式判断:闭源模型捕获高价值任务,而开源模型捕获高用量、低价值任务。较弱的价格弹性表明,即使成本差异巨大,也并不能完全转移需求;专有提供商对于关键任务应用保留了定价权,而开放生态系统则吸收了成本敏感型用户的大量用量。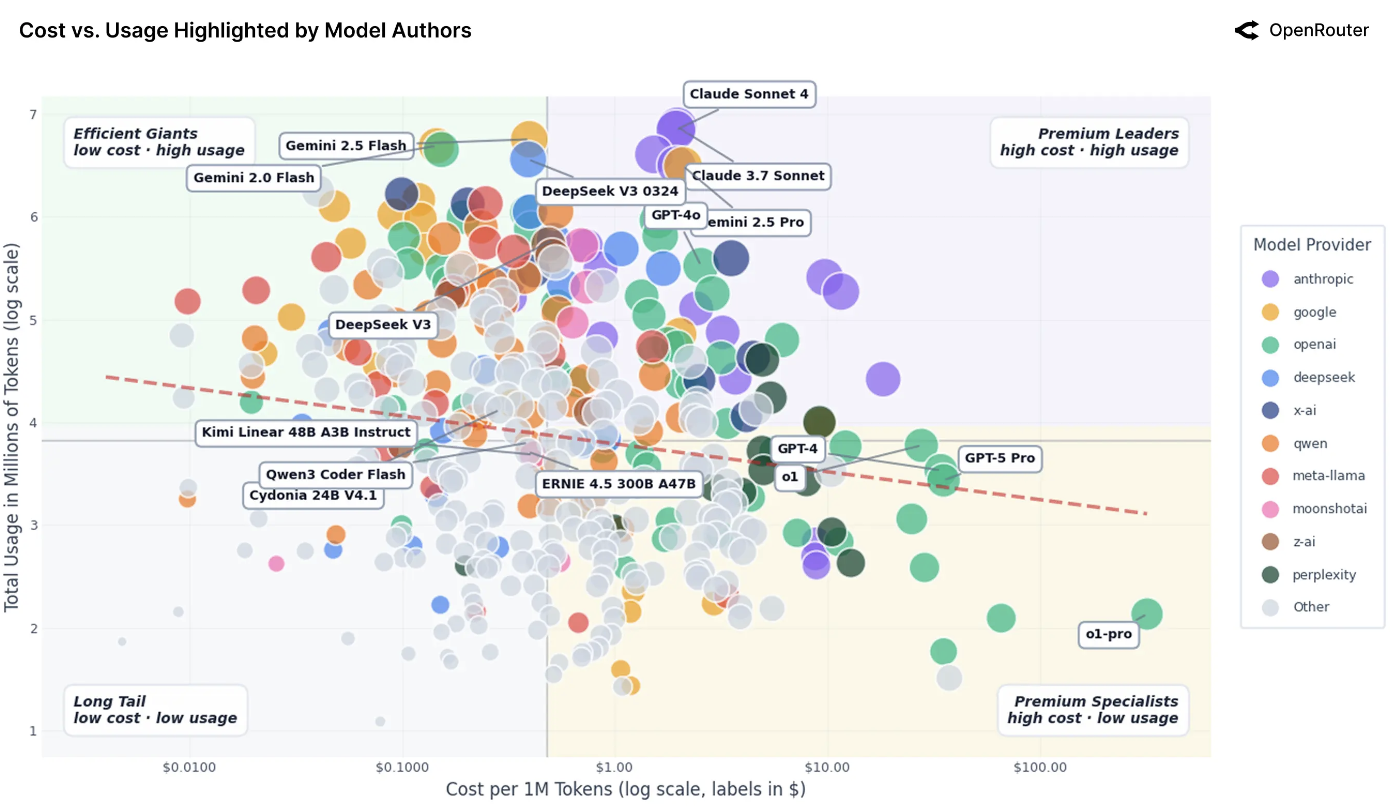
上图与前图类似,但显示了模型作者。四种使用量-成本原型应运而生。高端领导者,如 Anthropic 的 Claude 3.7 Sonnet 和 Claude Sonnet 4,每百万令牌成本约 2 美元,仍能达到高使用量,表明用户愿意为大规模应用的卓越推理和可靠性付费。高效巨头,如 Google 的 Gemini 2.0 Flash 和 DeepSeek V3 0324,将强劲性能与每百万令牌低于 0.40 美元的价格相结合,并达到相似的使用水平,使其成为高用量或长上下文工作负载极具吸引力的默认选择。长尾模型,包括 Qwen 2 7B Instruct 和 IBM Granite 4.0 Micro,每百万令牌价格仅为几分钱,但总使用量在 10^2.9 左右,反映了性能较弱、可见度有限或集成较少带来的限制。最后,高端专业模型,如 OpenAI 的 GPT-4 和 GPT-5 Pro,占据高成本、低使用量象限:每百万令牌约 35 美元,使用量接近 10^3.4,它们被谨慎地用于利基、高风险的工作负载,在这些场景中输出质量远比边际令牌成本重要。
- 在宏观层面,需求缺乏弹性,但这掩盖了不同的微观行为。有关键任务需求的企业愿意支付高价(因此这些模型使用量高)。另一方面,爱好者和开发流程对成本非常敏感,会涌向更便宜的模型(导致高效模型用量巨大)。
- 有迹象表明存在杰文斯悖论:使某些模型变得非常便宜(且快速)导致人们将其用于更多任务,最终消耗了更多的总令牌数。我们在高效巨头群体中看到了这一点:随着每令牌成本下降,这些模型被集成到各处,总消耗量飙升(人们运行更长的上下文、更多的迭代等)。
- 质量和能力通常胜过成本:昂贵模型(Claude、GPT-4)的大量使用表明,如果一个模型明显更好或具有信任优势,用户愿意承担更高的成本。通常这些模型被集成到工作流中,其成本相对于它们所产生的价值来说微不足道(例如,节省开发者一小时时间的代码,其价值远超过几美元的 API 调用费)。
- 反之,仅仅便宜是不够的,一个模型还必须有差异化且能力足够强。许多定价接近零的开放模型使用量仍然不高,因为它们只是"足够好",但没有找到工作负载-模型的契合点,或者不够可靠,因此开发者不愿深度集成它们。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)