【AI技术分享】GUI-Actor:让AI像人一样“看懂“界面并精准操作
GUI-Actor:让AI像人一样"看懂"界面并精准操作
欢迎关注公众号:曲奇自然语言处理
🌟 引言

想象一下这样的场景:你正在给远方的父母电话指导如何使用电脑上的某个软件。"爸,您看屏幕右上角有个蓝色的按钮……","不对不对,再往左一点,那个带齿轮图标的……"。这个过程是不是既费时又让人抓狂?
现在,如果我告诉你,AI也在经历同样的痛苦呢?
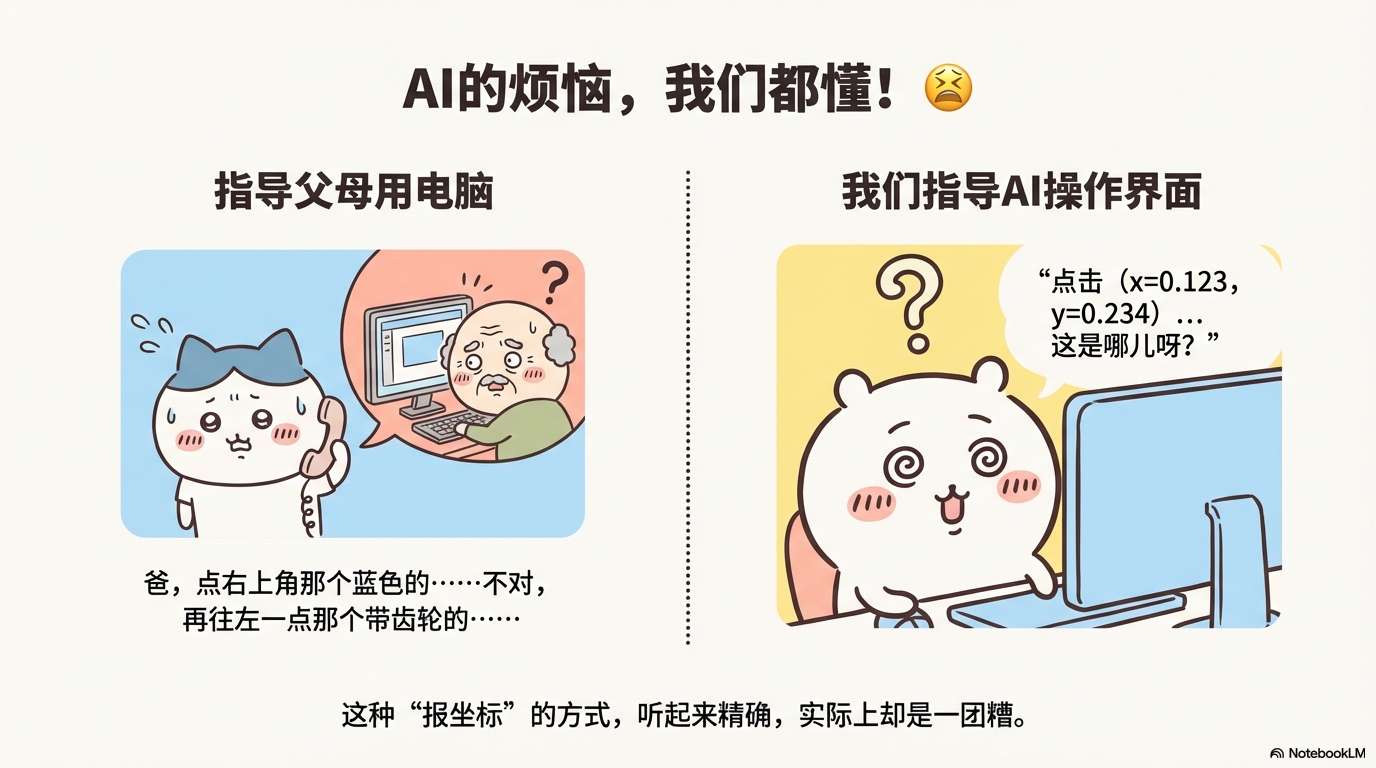
是的,你没听错。当我们训练AI去自动操作图形用户界面(GUI)时——比如让它帮你填表单、浏览网页、操作专业软件——它面临的挑战和你指导父母用电脑时一模一样:如何准确地找到并点击正确的按钮或区域。
目前主流的解决方案是什么呢?让AI像报坐标一样说"点击位置(x=0.123, y=0.234)"。听起来很精确对吧?但这就好比你告诉父母"把鼠标移动到距离屏幕左边缘12.3%、上边缘23.4%的位置"——理论上可行,实际上一团糟。
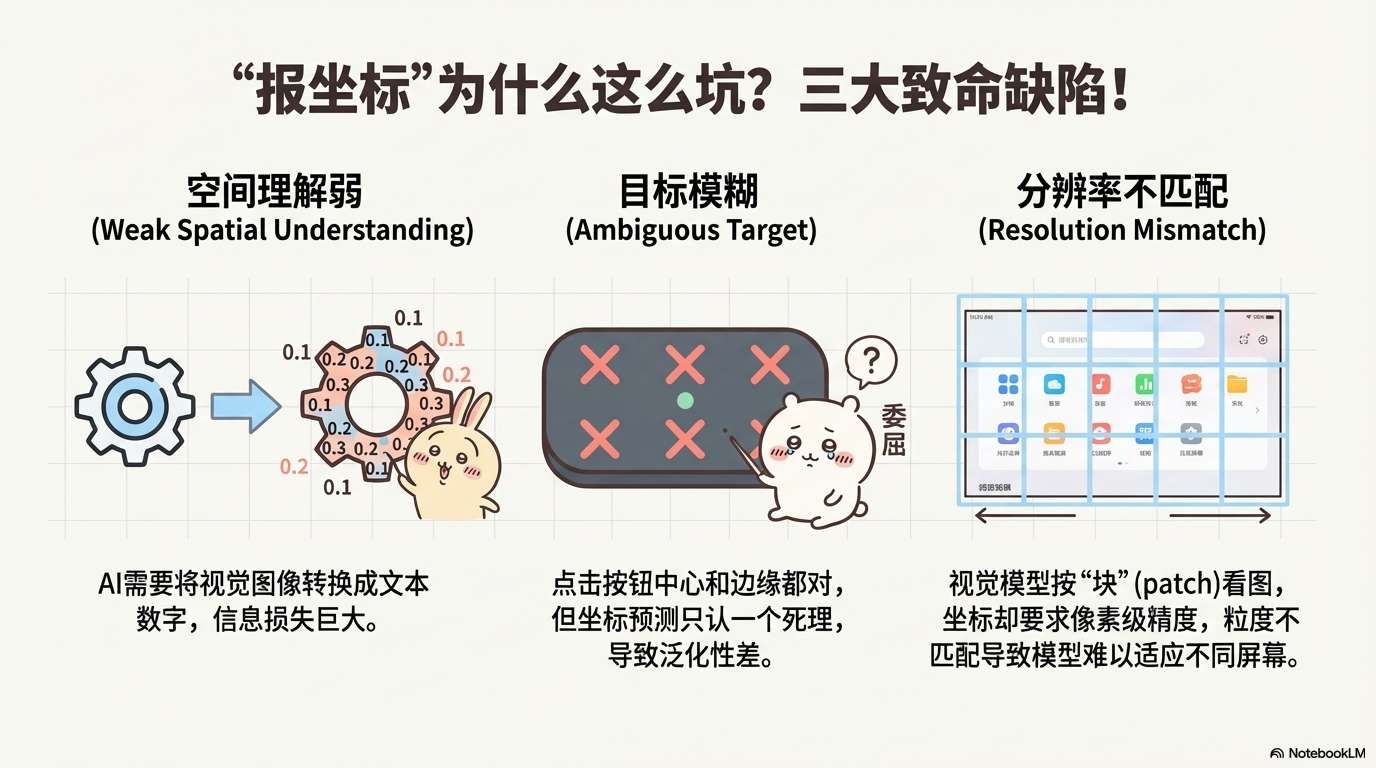
为什么这种方法不够好? 主要有三个致命问题:
-
空间理解弱:AI需要把视觉图像转换成文本形式的数字坐标,这就像让你先把看到的东西画成素描,再用文字描述素描的每个细节,最后再根据描述还原原图——信息损失巨大。
-
目标模糊:点击一个按钮时,点在按钮中心和点在边缘其实都是对的,但坐标预测只能给出一个固定点,其他合理位置都会被判错。
-
分辨率不匹配:视觉模型看图像是按"块"(patch)来看的,就像马赛克一样,但坐标却要求像素级精度。这种粒度不匹配让AI很难泛化到不同分辨率的屏幕。
这就是2025年6月发表在arXiv上的论文《GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents》[1]要解决的核心问题。来自微软、南京大学和伊利诺伊大学香槟分校的研究团队提出了一个革命性的想法:既然人类操作界面时不需要计算精确坐标,为什么AI要这样做呢?
他们的答案是 GUI-Actor——一个基于注意力机制的无坐标视觉定位方法。简单说,就是让AI学会像人一样"看"界面:直接把视觉注意力聚焦到目标元素上,而不是先转换成数字坐标。
这篇论文的亮点包括:
-
🎨 核心创新:引入专门的令牌和注意力头,实现直接视觉定位
-
📊 性能突破:在多个基准测试上超越现有最强模型,7B参数模型达到44.6分(ScreenSpot-Pro),超过72B的UI-TARS
-
💡 高效训练:仅需约1M训练样本,训练效率比基线提升40%
-
🔧 轻量化部署:冻结主干模型,只训练1亿参数的动作头即可达到SOTA性能
接下来,我会带你深入了解GUI-Actor的设计思路、技术细节、实验验证和未来展望。无论你是AI研究者、工程师,还是对人机交互感兴趣的爱好者,相信这篇文章都能让你有所收获。
📚 背景:GUI智能体面临的核心挑战
从自动化到智能化的演进
GUI智能体并不是什么新概念。早在2000年代,我们就有了各种自动化测试工具和RPA(机器人流程自动化)系统[2]。但这些传统方法有个致命弱点:过度依赖结构化元数据。
什么意思呢?比如网页有HTML DOM树,移动应用有View Hierarchy,桌面软件有Accessibility Tree。这些结构化数据就像是界面的"说明书",清楚地标注了每个按钮、输入框的位置和功能。早期的自动化系统就是读这些说明书来操作界面的。
听起来挺好,问题在哪?
问题多了去了:
-
数据质量参差不齐:很多网站的HTML写得一塌糊涂,移动应用的accessibility标注缺失
-
跨平台不一致:Windows、macOS、Linux、Android、iOS各有各的规范,没法统一
-
动态内容难处理:现代Web应用大量使用JavaScript动态生成内容,DOM树随时在变
-
专业软件支持差:CAD、视频编辑等专业软件的accessibility支持往往很差
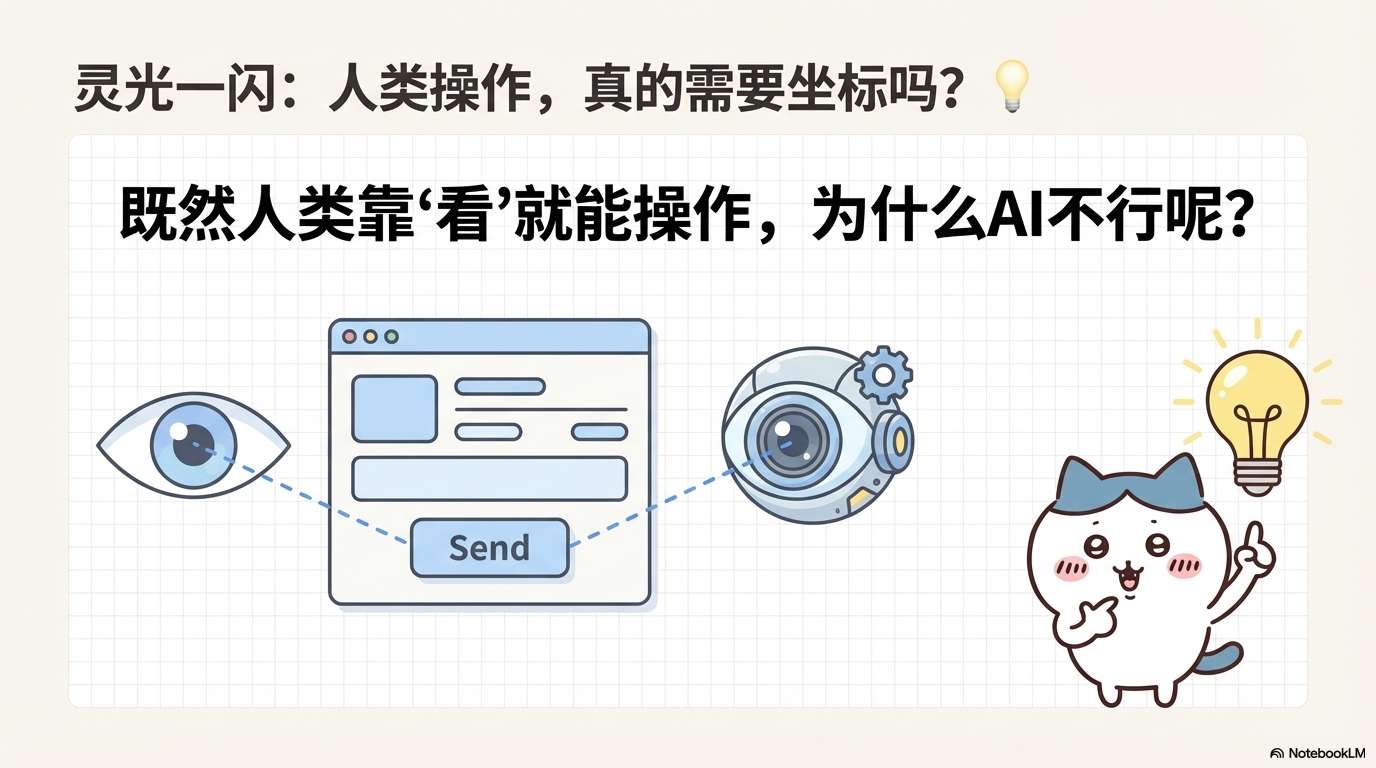
更重要的是,人类用户根本不需要这些元数据。你浏览网页的时候会去看HTML源码吗?不会。你只是看屏幕上显示的内容,然后点击你想点的地方。
视觉为先的新范式
随着大语言模型(LLM)和视觉-语言模型(VLM)的崛起[3,4],研究者们开始思考:能不能让AI也像人一样,只看屏幕截图就知道该点哪里?
这就是所谓的"视觉为先"(vision-centric)范式。AI接收的输入是原始的屏幕截图,输出的是鼠标点击、键盘输入等操作。整个过程不依赖任何结构化元数据,更接近人类的操作方式。
这个范式催生了一系列工作:
-
多模态感知:如何让AI理解截图中的视觉和文本信息[5,6]
-
任务规划:如何根据用户指令制定操作步骤[7]
-
视觉定位:如何找到指令对应的界面元素(这就是本文的核心)
-
动作执行:如何精确地模拟鼠标键盘操作[8]
其中,视觉定位(Visual Grounding)是最关键也是最具挑战性的环节。你可以有最聪明的规划算法,但如果找不准要点击的按钮,一切都白搭。
坐标生成方法的流行与局限
目前主流的视觉定位方法是坐标生成(Coordinate Generation):把屏幕位置编码成文本形式的坐标,让VLM像生成普通文本一样生成坐标[9,10]。
比如,给定截图和指令"点击新建项目按钮",模型会输出:
pyautogui.click(x=0.125, y=0.230)
这个方法为什么流行?因为实现简单:
-
不需要修改模型架构
-
利用现成的VLM就能做
-
训练数据容易构造(只要标注坐标就行)
但前面我们提到了,这个方法有三大致命缺陷。让我们深入分析一下:
缺陷1:空间-语义对齐弱
VLM的工作流程是这样的:
-
视觉编码器把图像转成patch特征(比如把1920×1080的图像分成60×40个patch)
-
这些特征和文本token一起送入语言模型
-
语言模型的输出头逐个生成token:
x,=,0,.,1,2,5, ...
注意看,生成坐标值的是语言模型头,而不是直接基于视觉特征。语言模型头并不知道patch特征对应图像的哪个位置,它只是学会了"在这种特征模式下,应该输出这些数字"。
这就像让一个人先看着照片用文字描述里面的物体,然后另一个人根据描述去猜测物体的精确位置——中间的信息损失可想而知。
缺陷2:监督信号模糊
很多GUI操作其实不需要精确的点击位置。比如点击一个200×50像素的按钮,你点在(100, 25)、(120, 20)还是(150, 30),效果都一样——只要在按钮范围内就行。
但坐标生成模型怎么训练呢?通常是这样:
-
标注数据只给出一个固定点,比如按钮中心(100, 25)
-
模型预测(120, 20)会被判错,即使这个点明明也在按钮内
-
这导致模型过度拟合标注数据的特定点位,泛化性差
这就像考试只有唯一标准答案,哪怕你的答案也对,但和标答不一样就是零分。
缺陷3:粒度不匹配
现代VLM(比如Qwen2-VL)使用Vision Transformer作为视觉编码器[11]。ViT把图像分成固定大小的patch,比如28×28像素。对于1920×1080的图像:
-
水平方向:1920÷28 ≈ 68个patch
-
垂直方向:1080÷28 ≈ 38个patch
-
总共约2600个patch特征
但坐标是连续的,理论上有1920×1080 = 2,073,600个可能位置。这意味着模型要从2600个粗粒度特征中推断出200万个可能的精确位置——这是个严重的信息瓶颈。
更糟糕的是,当屏幕分辨率改变时(比如从1920×1080到3840×2160),patch数量和坐标空间都会变化,模型的泛化能力会严重下降。
我们需要什么样的解决方案
理想的GUI视觉定位方案应该具备:
-
显式的空间建模:直接在视觉特征空间中定位,而不是绕道语言空间
-
容忍合理的模糊性:能接受目标区域内的多个有效点
-
分辨率鲁棒性:在不同屏幕尺寸和分辨率下都能稳定工作
-
高效性:推理速度快,训练数据需求少
GUI-Actor正是基于这些需求设计的。它的核心理念可以用一句话概括:让AI像人一样,直接"看"到目标区域,而不是计算坐标。
🔍 前人做了什么:相关工作回顾
在深入GUI-Actor的技术细节之前,让我们先看看学术界在这个领域都做了哪些探索。
GUI智能体的发展脉络
早期阶段:基于规则和脚本
最早的GUI自动化系统是基于规则的脚本系统,比如AutoHotkey、Selenium等[12]。这些工具需要开发者手写脚本,明确指定每一步操作:
driver.find_element_by_id("submit-button").click()
这种方法的优点是可控、可解释,缺点是缺乏灵活性——一旦界面布局改变,脚本就失效了。
中期阶段:基于机器学习的元素识别
随着深度学习的发展,研究者开始用神经网络来识别界面元素[13,14]。典型做法是:
-
用目标检测模型(如Faster R-CNN)检测按钮、输入框等元素
-
用OCR提取文本信息
-
用分类器判断元素类型和功能
这种方法比规则脚本灵活,但仍然需要大量标注数据,且难以处理复杂的语义理解任务(比如"找到创建新项目的那个蓝色按钮")。
现阶段:基于VLM的端到端智能体
大语言模型和视觉-语言模型的出现改变了游戏规则[15,16]。现在我们可以:
-
用自然语言描述任务:"帮我把这个PDF转成Word文档"
-
VLM理解屏幕内容和用户意图
-
生成并执行相应的操作序列
代表性工作包括:
-
WebAgent[17]:在网页环境中执行任务,利用HTML DOM结构
-
AppAgent[18]:在移动应用中操作,基于View Hierarchy
-
OS-Copilot[19]:跨平台桌面智能体,结合视觉和accessibility信息
这些工作推动了GUI智能体的实用化,但都面临视觉定位这个核心瓶颈。
视觉定位方法的演进
方法1:点坐标生成
最直接的思路就是让VLM生成点坐标。SeeClick[20]是这个方向的早期工作,它:
-
收集了大量GUI截图和点击位置的配对数据
-
训练VLM生成归一化坐标(x, y) ∈ [0,1]²
-
使用简单的交叉熵损失优化
这个方法简单有效,但就是我们前面提到的那些问题:空间对齐弱、监督模糊、粒度不匹配。
方法2:边界框生成
ShowUI[21]和UGround[22]提出预测边界框而不是单点:
pyautogui.click(box=[x_min, y_min, x_max, y_max])
理论上,边界框包含了更多空间信息。但实际上,如果没有专门的架构支持(比如目标检测中的RoI Pooling),边界框也只是四个数字而已,和点坐标没有本质区别。
实验结果也验证了这一点:UGround-7B在ScreenSpot上的表现和点坐标方法相当,在ScreenSpot-Pro上甚至更差。
方法3:集成视觉定位模块
一些工作尝试在VLM中集成专门的定位模块:
-
OmniParser[23]:先用目标检测模型提取候选区域,再用VLM排序
-
Set-of-Mark[24]:在截图上叠加编号标记,让VLM输出标记编号
这些方法一定程度上改善了定位精度,但增加了系统复杂度,且依赖额外的检测模型。
方法4:利用注意力机制
最近的Attention-SAM[25]提出了一个有趣的思路:直接利用VLM内部的注意力图来定位。他们发现,VLM在理解指令时,注意力自然会集中在相关区域。
但这是个零样本方法(zero-shot),没有针对性训练,所以精度有限。GUI-Actor可以看作是这个思路的有监督版本——显式训练一个注意力头来做定位。
数据集与基准
评估GUI视觉定位需要标准化的基准。目前主流的包括:
ScreenSpot[20]
-
1,272个任务,覆盖移动、桌面、Web三大平台
-
每个任务包含截图、自然语言指令、目标边界框
-
按元素类型分为Text和Icon两类
-
分辨率主要在1080p左右
ScreenSpot-v2[26]
-
ScreenSpot的修订版,修正了部分标注错误
-
保持相同的任务数量和平台分布
-
提供了更准确的边界框标注
ScreenSpot-Pro[27]
-
1,581个任务,专注于高分辨率专业场景
-
包含CAD、科学计算、创意软件等23个专业应用
-
分辨率普遍在2K-4K
-
具有更大的域偏移(domain shift),是测试泛化能力的好基准
评估指标主要是元素准确率(Element Accuracy):预测点落在目标边界框内的比例。
现有方法的性能对比
截至GUI-Actor发表前,在这些基准上表现最好的是UI-TARS[28]:
| 模型 | 参数量 | ScreenSpot | ScreenSpot-v2 | ScreenSpot-Pro |
|---|---|---|---|---|
| UI-TARS | 2B | 82.3 | 84.7 | 27.7 |
| UI-TARS | 7B | 89.5 | 91.6 | 35.7 |
| UI-TARS | 72B | 88.4 | 90.3 | 38.1 |
可以看到:
-
规模效应明显:更大的模型性能更好(虽然72B在ScreenSpot上反而下降了)
-
域偏移挑战大:在ScreenSpot-Pro上,即使是72B模型也只有38.1%的准确率
-
训练数据依赖:UI-TARS使用了大量专有数据和多阶段训练(预训练+微调+DPO)
那么,GUI-Actor能否以更小的模型、更少的数据、更简单的训练过程达到甚至超越这个性能呢?
答案是肯定的。接下来,让我们看看GUI-Actor是怎么做到的。
💡 核心创新:GUI-Actor的设计哲学
设计理念:回归本质
GUI-Actor的设计从一个简单的观察出发:人类操作界面时,并不计算精确坐标。
想象你在用Photoshop修图:
-
老板说"把左上角的图层锁定一下"
-
你的眼睛扫过屏幕左上角的图层面板
-
视觉注意力聚焦到那个小锁图标
-
手指移动鼠标,点击
整个过程是视觉驱动的直接映射,没有"计算这个图标的坐标是(x=0.123, y=0.067)"这一步。
那么,为什么AI要绕这么大一个弯呢?
GUI-Actor的答案很简单:不绕了,直接学习视觉注意力映射。
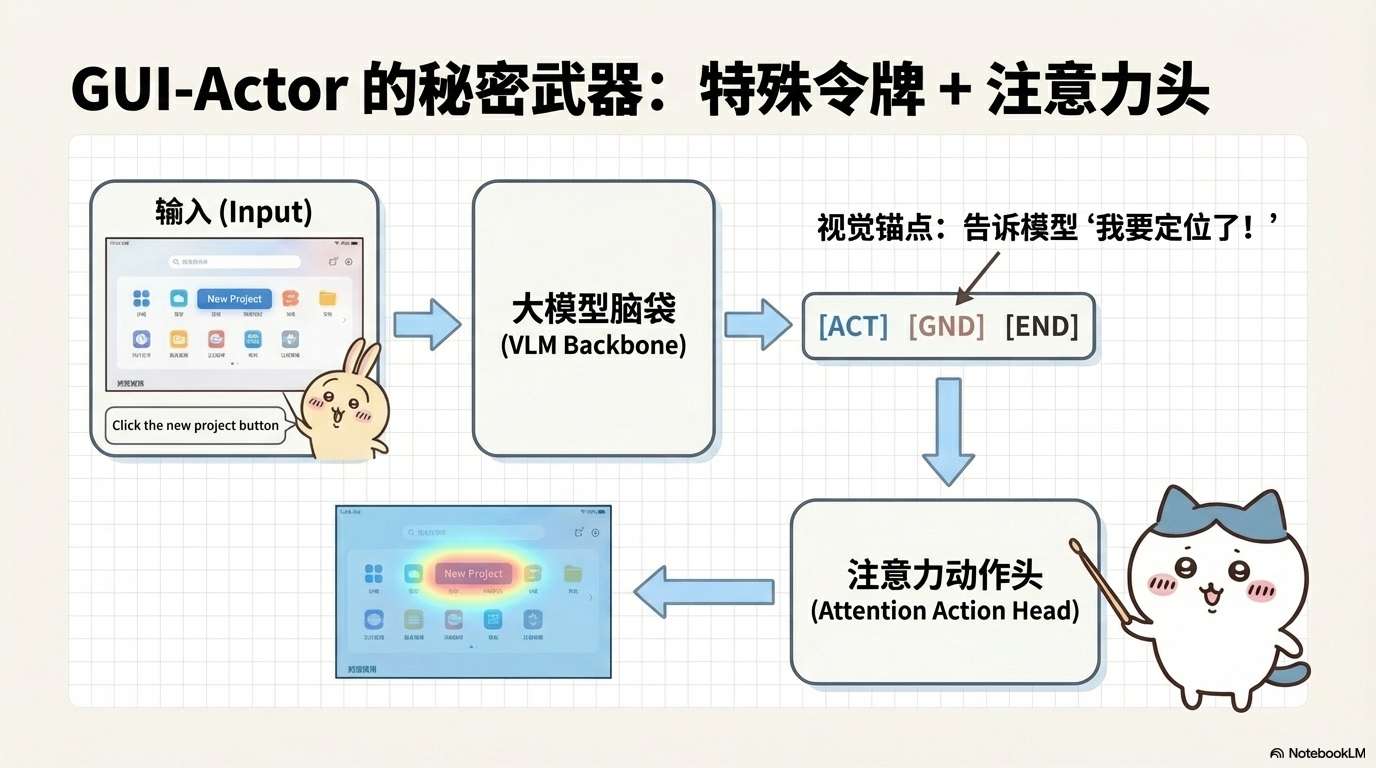
架构概览
GUI-Actor在标准VLM基础上增加了两个核心组件:
-
令牌:作为"视觉锚点",承载定位任务的上下文
-
注意力动作头:学习从到图像patch的注意力分布
整体流程如下:
输入:屏幕截图 + 用户指令
↓
视觉编码器(提取patch特征)
↓
语言模型主干(理解指令)
↓
生成文本响应(包含<ACTOR>令牌)
↓
注意力动作头(计算注意力图)
↓
输出:目标区域的注意力分布
让我们逐个拆解这些组件。
组件1:令牌族
设计动机
在坐标生成方法中,模型输出类似这样的序列:
pyautogui.click(x=0.123, y=0.234)
坐标值0.123和0.234分散在不同位置,没有一个统一的"锚点"来承载空间信息。
GUI-Actor引入了三个特殊令牌:
-
<ACTOR_START>:标记动作区域的开始 -
<ACTOR>:核心锚点,其隐藏状态用于计算注意力 -
<ACTOR_END>:标记动作区域的结束
模型输出变成:
pyautogui.click(<ACTOR_START><ACTOR><ACTOR_END>)
为什么需要三个令牌?
你可能会问:为什么不直接用一个<ACTOR>令牌?
这涉及到语言模型的因果注意力机制(causal attention)。在生成第i个token时,模型只能看到前i-1个token。如果只有一个<ACTOR>,它的隐藏状态在生成时无法获取完整的上下文。
用三个令牌的好处是:
-
**
<ACTOR_START>**:提醒模型"接下来要做定位任务了" -
**
<ACTOR>**:在已知前文context的基础上编码定位信息 -
**
<ACTOR_END>**:标记结束,让后续token知道定位已完成
这种设计借鉴了序列标注中的BIO标注体系(Begin-Inside-Outside)。
令牌的语义
<ACTOR>令牌的隐藏状态 h_ 是什么呢?
可以理解为**"在当前视觉输入和指令下,需要操作的目标元素"的语义表示**。它融合了:
-
视觉信息(来自图像patch特征)
-
语言信息(来自用户指令)
-
任务信息(来自系统提示词和上下文)
这个表示是在Transformer的多层自注意力中逐渐形成的,到最后一层时,它已经充分理解了"要操作哪个元素"。
组件2:注意力动作头
架构设计
动作头的任务是:将的语义表示映射到图像空间,找出最相关的patch。
具体来说,给定:
-
的隐藏状态:h_ ∈ ℝ^d
-
M个图像patch特征:v_1, ..., v_M ∈ ℝ^d
动作头计算注意力分布 a_1, ..., a_M,其中 a_i 表示第i个patch是目标区域的概率。
整个动作头包含三个子模块:
1. 上下文感知自注意力(Contextual Self-Attention)
首先对图像patch做一次自注意力:
ṽ_1, ..., ṽ_M = SelfAttn(v_1, ..., v_M)
为什么要这一步? 因为单个patch的信息太局部了。比如一个按钮可能跨越多个patch,通过自注意力,每个patch能整合周围patch的信息,形成更完整的语义表示。
这类似于人类视觉的Gestalt原理——我们看东西时会把相邻的元素组合成整体。
2. 语义-视觉对齐投影(Semantic-Visual Projection)
接下来,用两个独立的MLP分别投影表示和patch特征:
z = MLP_T(h_<ACTOR>) # 语义投影
z_i = MLP_V(ṽ_i) # 视觉投影
为什么需要两个MLP? 因为和patch特征来自不同的表示空间:
-
来自语言模型的输出层,偏向语义
-
patch特征来自视觉编码器,偏向视觉
两个MLP就像两个"翻译器",把它们映射到同一个对齐空间。
3. 缩放点积注意力(Scaled Dot-Product Attention)
最后,计算注意力分数并归一化:
α_i = z^T z_i / √d # 点积相似度
a_i = exp(α_i) / Σ_j exp(α_j) # softmax归一化
这就是标准的注意力机制[29],在Transformer中被广泛使用。
为什么是注意力而不是分类器?
你可能会想:为什么不直接训练一个分类器,对每个patch做二分类(是/否目标)?
注意力机制有几个优势:
-
全局归一化:softmax确保所有patch的概率和为1,体现了"只有一个主要目标"的先验
-
相对关系:注意力分数反映的是相对重要性,对绝对数值的尺度不敏感
-
可解释性:注意力图可以直接可视化,方便调试和分析
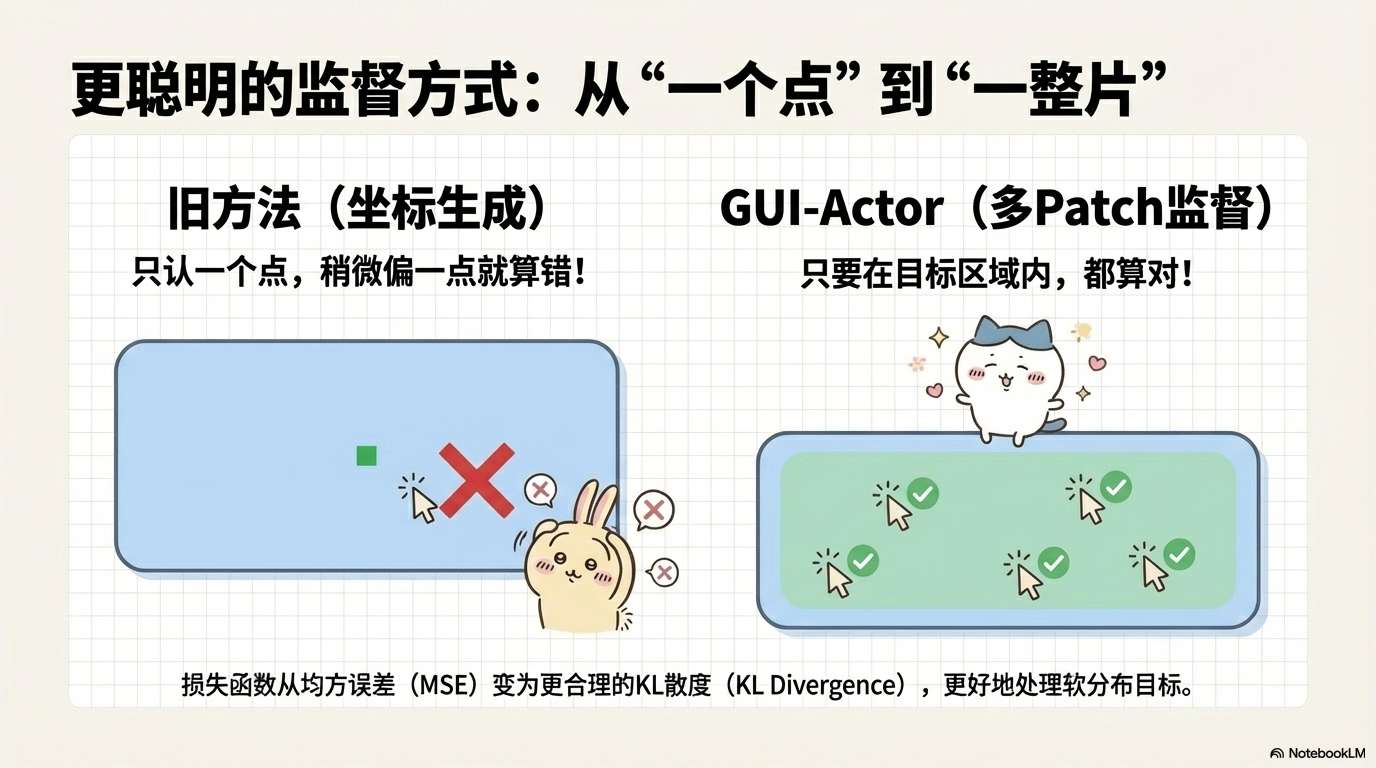
组件3:空间感知的多Patch监督
监督信号的设计
传统坐标生成方法的监督是单点的:
Ground Truth: (x=0.5, y=0.3)
Prediction: (x=0.48, y=0.32)
Loss: MSE((0.5, 0.3), (0.48, 0.32))
GUI-Actor的监督是多patch的:
Ground Truth: 边界框 [x_min, y_min, x_max, y_max]
↓
转换为patch掩码
↓
y = [0, 0, 1, 1, 1, 0, 0, ...] (M个patch)
Prediction: a = [0.01, 0.02, 0.3, 0.4, 0.2, 0.03, ...] (注意力分布)
Loss: KL(y || a)
如何构建patch掩码?
给定归一化边界框 [left, top, right, bottom] ∈ [0,1]^4 和patch网格尺寸 W×H,转换过程是:
-
坐标缩放:
left' = ⌊left × W⌋ top' = ⌊top × H⌋ right' = ⌈right × W⌉ bottom' = ⌈bottom × H⌉注意用了floor和ceil,确保边界上的patch也被包含。
-
掩码填充:
for i in range(W): for j in range(H): if left' ≤ i < right' and top' ≤ j < bottom': y[i, j] = 1 else: y[i, j] = 0 -
归一化为概率分布:
p_i = y_i / (Σ_j y_j + ε)其中ε是防止除零的小常数。
损失函数
最终的损失是KL散度:
L_Action = Σ_i p_i log(p_i / a_i)
为什么用KL散度而不是交叉熵? 因为交叉熵假设目标分布是one-hot的(只有一个正确答案),而KL散度可以处理软分布(多个合理答案)。
实际上,对于我们的多patch监督:
-
交叉熵:Σ_i p_i log a_i
-
KL散度:Σ_i p_i log(p_i / a_i) = Σ_i p_i log p_i - Σ_i p_i log a_i
第一项是常数,所以KL散度等价于交叉熵加一个常数。但在语义上,KL散度更准确地表达了"让预测分布接近目标分布"的意图。
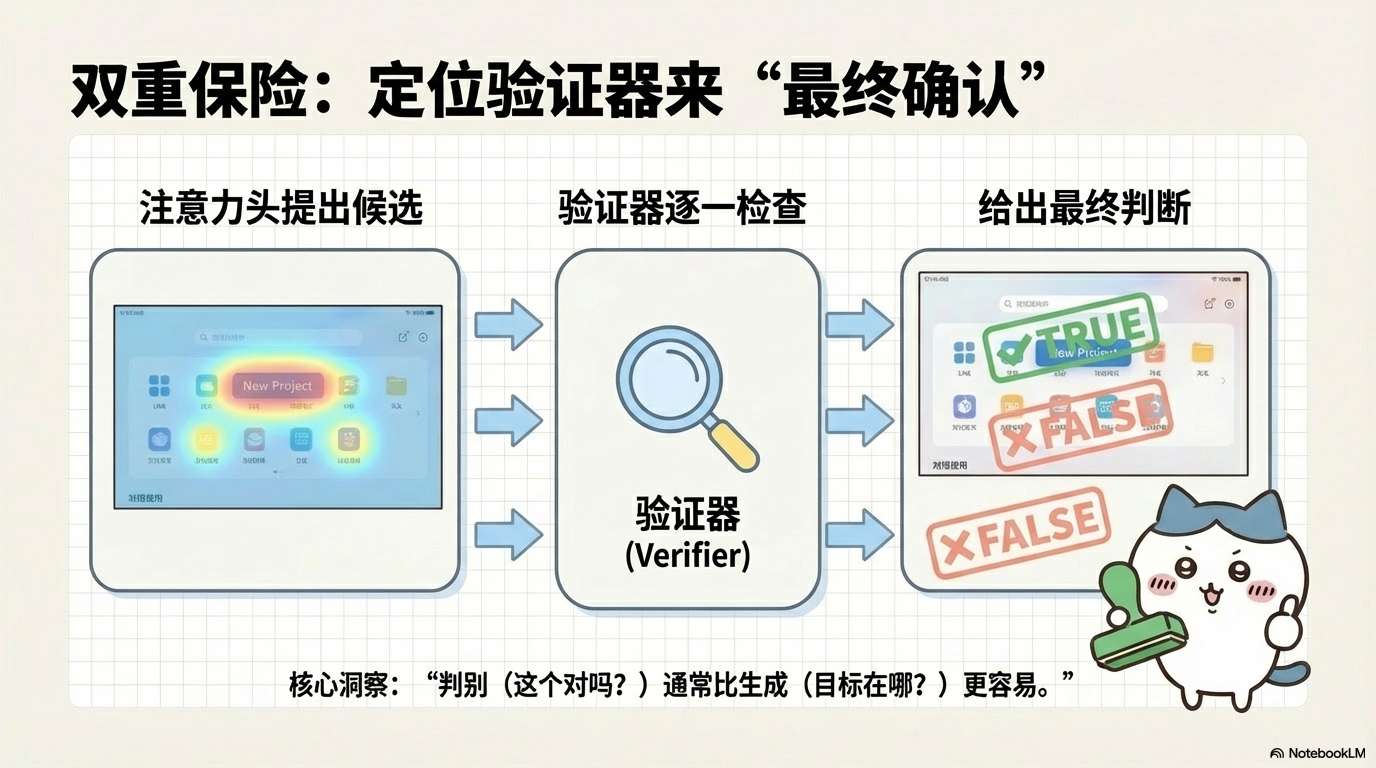
组件4:定位验证器
动机
注意力动作头能生成一个注意力图,标识所有可能的目标区域。但在实际执行时,我们只能点击一个位置。如何从多个候选中选择最优的呢?
这就是定位验证器(Grounding Verifier)的作用:给每个候选位置打分,选择得分最高的。
验证器的架构
验证器本身是一个轻量级VLM,输入是:
-
截图+标记:在候选位置画一个红色空心圆
-
指令:用户的自然语言指令
输出是一个二分类:
-
True:这个位置正确 -
False:这个位置错误
训练数据构造:
# 正样本:在真实目标中心画圆
positive = (image_with_mark_at_gt_center, instruction, 'True')
# 负样本1:在错误bbox的中心画圆
negative1 = (image_with_mark_at_wrong_bbox, instruction, 'False')
# 负样本2:在随机位置画圆
negative2 = (image_with_mark_at_random, instruction, 'False')
推理时的选择策略
给定K个候选patch(按注意力权重降序),验证流程是:
candidates = top_k_patches(attention_weights, k=20)
for candidate in candidates:
marked_image = draw_circle(image, candidate.center)
p_true = verifier(marked_image, instruction).prob('True')
p_false = verifier(marked_image, instruction).prob('False')
score = p_true / (p_true + p_false)
if score > threshold: # 比如0.95
return candidate
return candidates[0] # 都不满足则返回top1
早停策略:一旦找到高置信度的候选(比如>0.95),就不再检查剩余的。这大幅减少了计算开销。
为什么验证比生成容易?
这里用到了一个重要的机器学习洞察:判别(discrimination)通常比生成(generation)容易[30]。
想象你在考试:
-
生成:"写出勾股定理的公式" → 需要从记忆中检索并准确书写
-
判别:"以下哪个是勾股定理?A) a²+b²=c² B) a+b=c" → 只需识别哪个看起来对
同样,GUI定位中:
-
生成:从整个屏幕中找出目标位置 → 需要综合视觉和语义信息做全局搜索
-
判别:给定候选位置,判断是否正确 → 只需局部验证
验证器就像一个"第二意见",帮助动作头做最终决策。
完整推理流程
让我们把所有组件串起来,看一个完整的推理例子:
输入:
-
截图:一个IDE界面
-
指令:"点击运行按钮"
步骤1:VLM生成响应
模型输出:pyautogui.click(<ACTOR_START><ACTOR><ACTOR_END>)
步骤2:提取表示
h_<ACTOR> = last_layer_hidden_states[<ACTOR>的位置]
步骤3:计算注意力图
注意力权重 = ActionHead(h_<ACTOR>, image_patches)
结果:在"运行"按钮区域的patch权重最高
步骤4:候选筛选
top20 = 选取注意力权重最高的20个patch
过滤掉权重<0.2×max_weight的patch
剩余:12个候选
步骤5:验证器打分
for 每个候选patch:
在其中心画红圈
计算验证分数 = P(True) / [P(True) + P(False)]
候选1(运行按钮中心):0.98 ✓ → 直接返回
候选2-12:不再评估(早停)
输出:
点击位置:(542, 89) # 运行按钮的中心
整个过程只需要一次前向传播(不计验证器),比坐标生成方法还要快。
🧪 实验验证:GUI-Actor的表现如何?
实验设置
模型配置
GUI-Actor有多个版本,主要区别在于主干VLM的选择:
| 模型 | 主干VLM | 动作头参数 | 总参数 |
|---|---|---|---|
| GUI-Actor-2B | Qwen2-VL-2B | ~20M | ~2.02B |
| GUI-Actor-7B | Qwen2-VL-7B | ~100M | ~7.1B |
| GUI-Actor-3B | Qwen2.5-VL-3B | ~50M | ~3.05B |
| GUI-Actor-7B-v2 | Qwen2.5-VL-7B | ~100M | ~7.1B |
还有一个特殊版本:GUI-Actor-LiteTrain,只训练动作头,冻结主干VLM。这是为了验证能否在不损害VLM通用能力的前提下增加定位功能。
训练数据
总共约1M屏幕截图,来自多个公开数据集:
| 数据集 | 样本数 | 平台 | 用途 |
|---|---|---|---|
| UGround Web-Hybrid | 8M元素/775K图像 | Web | 主要训练数据 |
| GUI-Env | 262K元素/70K图像 | Web | 增强泛化 |
| GUI-Act | 42K元素/13K图像 | Web | 动作序列 |
| AndroidControl | 47K元素/47K图像 | Android | 移动端 |
| AMEX | 1.2M元素/100K图像 | Android | 移动端 |
| Wave-UI | 150K元素/7K图像 | 混合 | 跨平台 |
注意:Wave-UI中与测试集重叠的样本已被移除。
基线对比
主要对比的基线包括:
闭源模型:
-
GPT-4o[31]
-
Claude Computer Use[32]
-
Gemini 2.0[33]
开源模型(同等规模):
-
SeeClick-9.6B[20]
-
ShowUI-2B[21]
-
Aguvis-7B[34]
-
UGround-v1-7B[22]
-
UI-TARS-7B[28]
对比维度:
-
性能:在各基准上的准确率
-
效率:训练数据量、训练时间、推理速度
-
泛化:在域外数据(ScreenSpot-Pro)上的表现
-
鲁棒性:对分辨率变化的敏感度
主要结果
ScreenSpot:基础能力验证
ScreenSpot是最经典的基准,包含移动、桌面、Web三个平台,每个平台又分Text和Icon两种元素类型。
GUI-Actor vs. 坐标生成基线(7B模型):
| 模型 | Mobile-T | Mobile-I | Desktop-T | Desktop-I | Web-T | Web-I | 平均 |
|---|---|---|---|---|---|---|---|
| Aguvis-7B | 95.6 | 77.7 | 93.8 | 67.1 | 88.3 | 75.2 | 84.4 |
| UGround-7B | 93.0 | 79.9 | 93.8 | 76.4 | 90.9 | 84.0 | 86.3 |
| UI-TARS-7B | 94.5 | 85.2 | 95.9 | 85.7 | 90.0 | 83.5 | 89.5 |
| GUI-Actor-7B | 94.9 | 82.1 | 91.8 | 80.0 | 91.3 | 85.4 | 88.3 |
| + Verifier | 96.0 | 83.0 | 93.8 | 82.1 | 92.2 | 87.4 | 89.7 |
观察:
-
GUI-Actor基础版本(无验证器)已经很接近UI-TARS
-
加上验证器后,在大部分子类别上超过UI-TARS
-
Icon类别(图标定位)相比Text类别更具挑战性,所有模型的准确率都较低
2B模型的惊人表现:
| 模型 | 参数 | 平均准确率 |
|---|---|---|
| UI-TARS-2B | 2B | 82.3 |
| GUI-Actor-2B | 2B | 86.5 |
| + Verifier | 2B | 86.9 |
| Aguvis-7B | 7B | 84.4 |
| UGround-7B | 7B | 86.3 |
关键发现:GUI-Actor-2B(86.5)超过了Aguvis-7B(84.4)!这说明架构设计比模型规模更重要。
ScreenSpot-v2:修正标注后的验证
ScreenSpot-v2修正了原版的标注错误,是更可靠的评估基准。
| 模型 | Mobile-T | Mobile-I | Desktop-T | Desktop-I | Web-T | Web-I | 平均 |
|---|---|---|---|---|---|---|---|
| UI-TARS-7B | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 |
| GUI-Actor-7B | 96.5 | 84.3 | 91.7 | 84.1 | 93.9 | 82.3 | 89.5 |
| + Verifier | 97.2 | 84.8 | 94.3 | 85.0 | 94.0 | 85.2 | 90.9 |
在ScreenSpot-v2上,UI-TARS-7B稍微领先。但考虑到:
-
UI-TARS使用了更多训练数据(包括专有数据)
-
UI-TARS经过了更复杂的训练流程(预训练+微调+DPO)
-
GUI-Actor只用了标准监督学习
这个差距是可以接受的。

ScreenSpot-Pro:真正的挑战
ScreenSpot-Pro是最具挑战性的基准,测试模型在专业软件、高分辨率场景中的泛化能力。
7B模型对比:
| 模型 | Dev | Creative | CAD | Scientific | Office | OS | 平均 |
|---|---|---|---|---|---|---|---|
| Aguvis-7B | 16.1 | 21.4 | 13.8 | 34.6 | 34.3 | 19.4 | 22.9 |
| UGround-7B | 28.1 | 31.7 | 14.6 | 39.0 | 49.6 | 24.5 | 31.1 |
| UI-TARS-7B | 36.1 | 32.8 | 18.0 | 50.0 | 53.5 | 24.5 | 35.7 |
| GUI-Actor-7B | 38.8 | 40.2 | 29.5 | 44.5 | 56.5 | 36.2 | 40.7 |
| + Verifier | 38.8 | 40.5 | 37.2 | 44.5 | 64.8 | 43.9 | 44.2 |
| UI-TARS-72B | 40.8 | 39.6 | 17.2 | 45.7 | 54.8 | 30.1 | 38.1 |
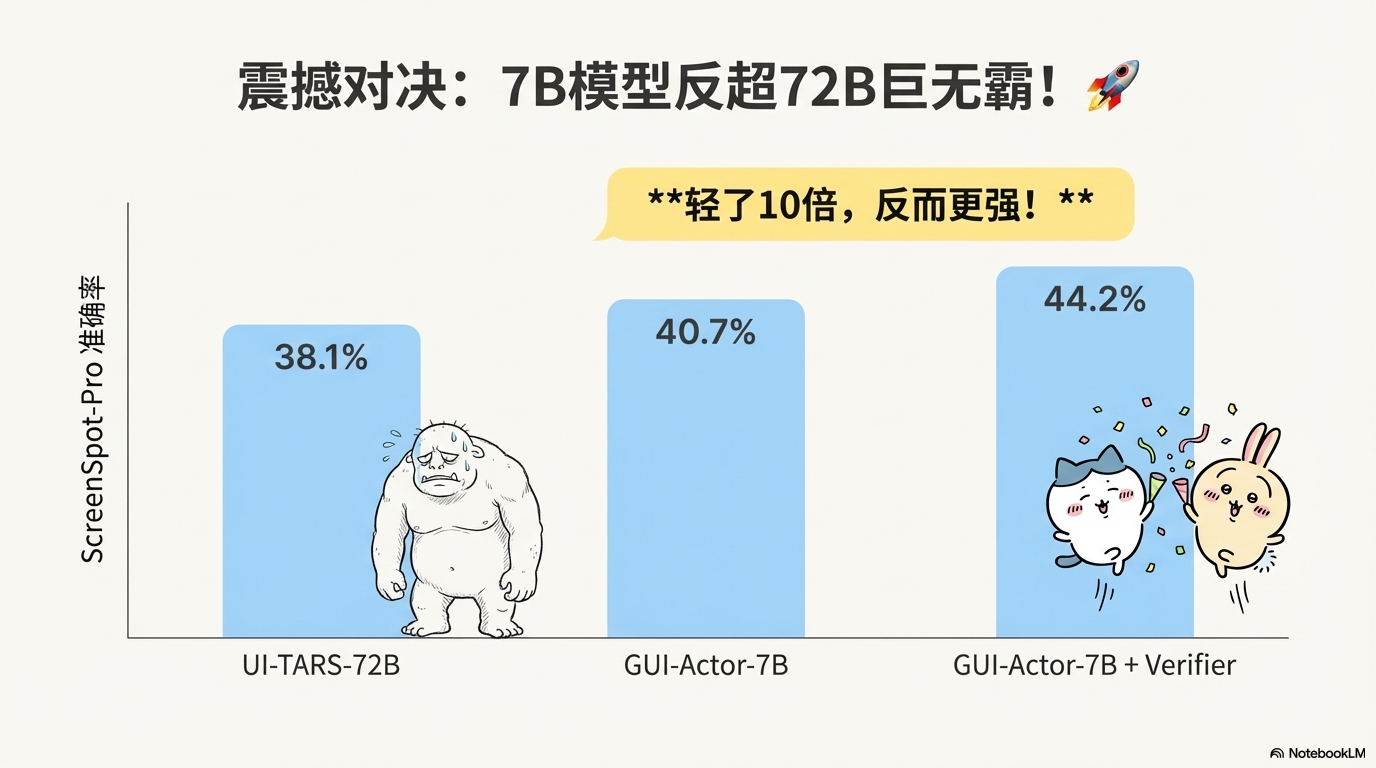
震撼事实:
-
GUI-Actor-7B(40.7)超过UI-TARS-72B(38.1)!
-
加上验证器后,GUI-Actor-7B达到44.2,领先UI-TARS-72B整整6.1个点!
-
参数少了10倍,性能反而更好
2B模型同样出色:
| 模型 | 参数 | 平均准确率 |
|---|---|---|
| UI-TARS-2B | 2B | 27.7 |
| GUI-Actor-2B | 2B | 36.7 |
| + Verifier | 2B | 41.8 |
| UI-TARS-7B | 7B | 35.7 |
GUI-Actor-2B + Verifier(41.8)甚至超过了UI-TARS-7B(35.7)!
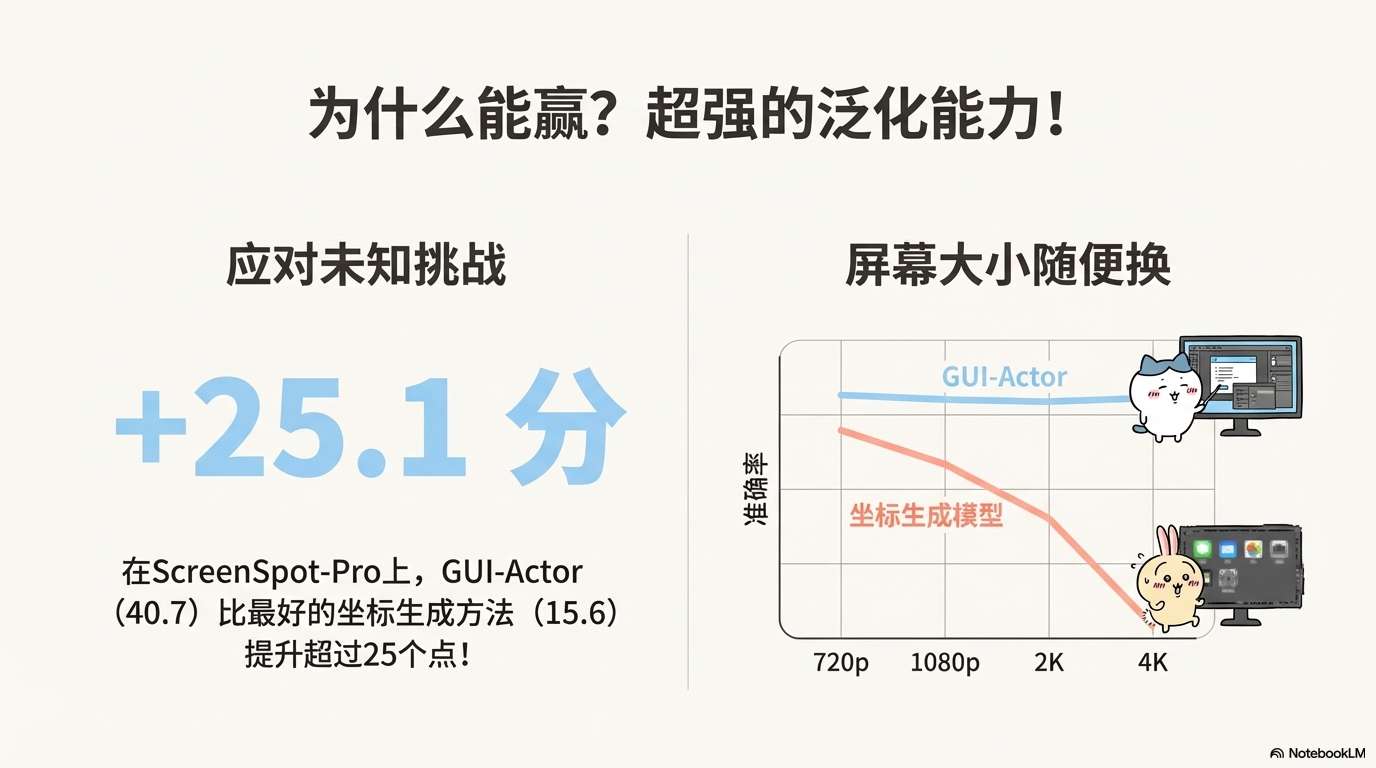
为什么GUI-Actor在域外数据上表现这么好?
原因在于其显式的空间建模:
-
注意力机制直接在patch空间操作,不受坐标数值尺度影响
-
多patch监督学到的是"目标区域的视觉特征",而非"特定分辨率下的坐标值"
-
这种表示更具泛化性,对分辨率、布局变化更鲁棒
Qwen2.5-VL主干:更强的基础
当使用更新的Qwen2.5-VL作为主干时,性能进一步提升:
ScreenSpot-Pro:
| 模型 | 主干 | 平均准确率 |
|---|---|---|
| Jedi-7B | Qwen2.5-VL-7B | 39.5 |
| GUI-Actor-7B | Qwen2.5-VL-7B | 44.6 |
| + Verifier | 47.7 |
ScreenSpot-v2:
| 模型 | 主干 | 平均准确率 |
|---|---|---|
| Jedi-7B | Qwen2.5-VL-7B | 91.7 |
| GUI-Actor-7B | Qwen2.5-VL-7B | 92.1 |
| + Verifier | 92.5 |
结论:GUI-Actor的设计与主干VLM的选择是正交的,更好的VLM主干会带来性能提升。
消融实验:每个组件的贡献
对比坐标生成方法
为了公平比较,研究者用相同的数据分别训练了:
-
**Aguvis-7B (point sup.)**:预测点坐标
-
**Aguvis-7B (bbox sup.)**:预测边界框坐标
-
GUI-Actor-7B:注意力定位
ScreenSpot-Pro上的对比:
| 方法 | Dev | Creative | CAD | Scientific | Office | OS | 平均 |
|---|---|---|---|---|---|---|---|
| point sup. | 15.7 | 19.4 | 3.8 | 17.3 | 24.4 | 11.7 | 15.6 |
| bbox sup. | 12.4 | 17.0 | 1.5 | 18.1 | 21.7 | 11.7 | 13.8 |
| GUI-Actor | 38.8 | 40.2 | 29.5 | 44.5 | 56.5 | 36.2 | 40.7 |
惊人发现:
-
bbox监督甚至比point监督更差!
-
GUI-Actor比最好的基线提升了25个点(40.7 vs 15.6)
这验证了我们之前的分析:没有专门的空间建模机制,边界框也只是四个数字而已。
验证器的贡献
验证器在不同任务上的提升:
| 基准 | 无验证器 | 有验证器 | 提升 |
|---|---|---|---|
| ScreenSpot | 88.3 | 89.7 | +1.4 |
| ScreenSpot-v2 | 89.5 | 90.9 | +1.4 |
| ScreenSpot-Pro | 40.7 | 44.2 | +3.5 |
观察:
-
在域内数据(ScreenSpot)上提升较小(~1.4%)
-
在域外数据(ScreenSpot-Pro)上提升显著(3.5%)
为什么? 因为域外任务更难,动作头的top1预测不一定准确,这时验证器的"第二意见"就很关键。
轻量训练(LiteTrain)的可行性
GUI-Actor-LiteTrain只训练动作头,冻结VLM主干。
| 配置 | 训练参数 | ScreenSpot | ScreenSpot-v2 | ScreenSpot-Pro |
|---|---|---|---|---|
| 全量训练 | 7.1B | 88.3 | 89.5 | 40.7 |
| LiteTrain | 103M | 73.5 | 74.9 | 22.9 |
| + Verifier | 103M | 81.3 | 83.8 | 35.8 |
关键发现:
-
纯LiteTrain性能下降明显(73.5 vs 88.3)
-
但加上验证器后,在ScreenSpot-Pro上达到35.8,已经超过了很多全量训练的基线!
-
在ScreenSpot-Pro上,LiteTrain+Verifier(35.8)> UI-TARS-7B(35.7)
这说明:
-
VLM主干已经有很强的GUI理解能力
-
动作头主要学习"如何将语义映射到空间"
-
验证器能有效弥补LiteTrain的不足
效率分析
训练数据效率
在相同的训练数据量下,GUI-Actor收敛更快:
ScreenSpot准确率 vs. 训练进度:
| 训练数据量 | Aguvis (bbox) | Aguvis (point) | GUI-Actor |
|---|---|---|---|
| 20% | 80.3 | 81.8 | 83.7 |
| 40% | 80.7 | 81.6 | 83.9 |
| 60% | 83.3 | 81.8 | 84.8 |
| 80% | 83.5 | 83.1 | 85.3 |
| 100% | 83.7 | 81.5 | 85.7 |
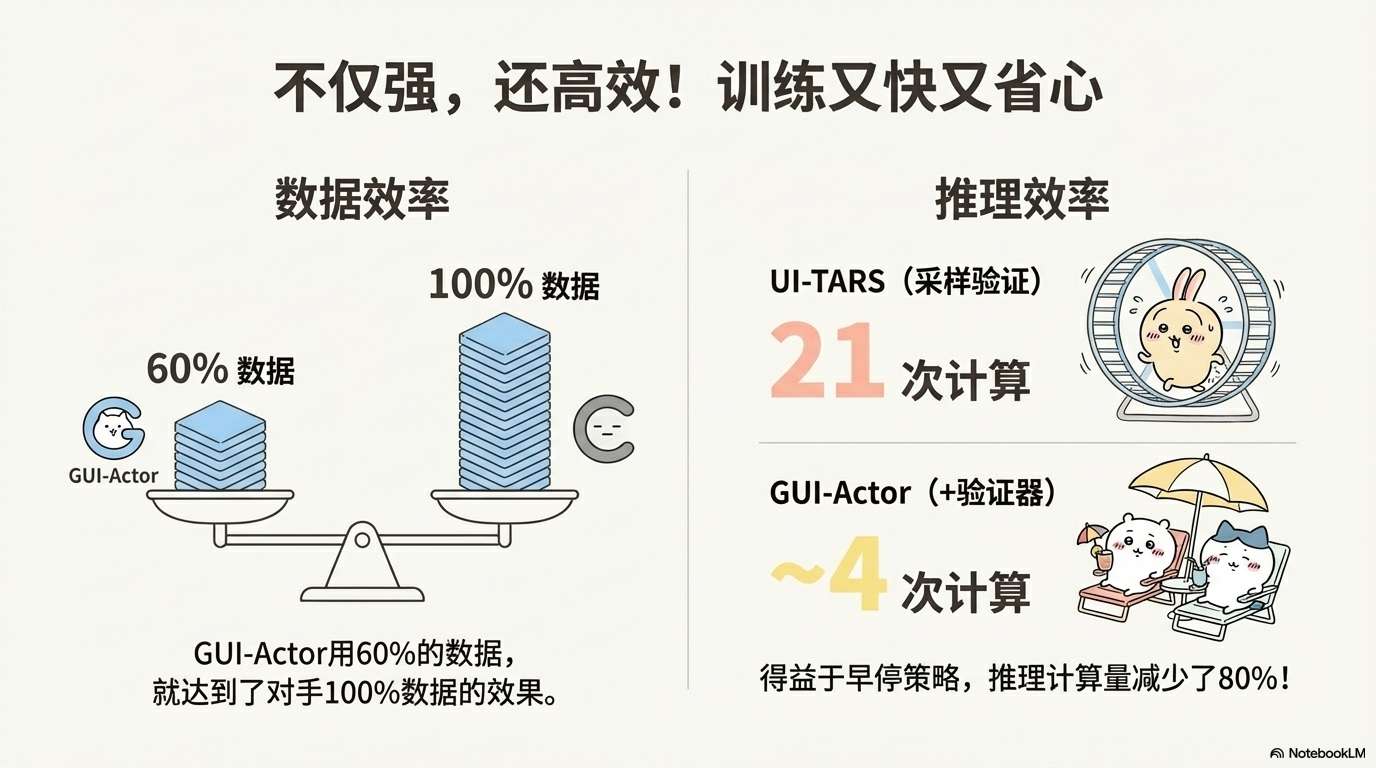
关键点:GUI-Actor用60%的数据就能达到基线用100%数据的性能。
ScreenSpot-Pro的更明显对比:
| 训练数据量 | Aguvis (bbox) | Aguvis (point) | GUI-Actor |
|---|---|---|---|
| 20% | 18.3 | 17.3 | 35.5 |
| 60% | 16.9 | 16.5 | 36.9 |
| 100% | 13.8 | 15.6 | 40.7 |
Aguvis基线在域外数据上几乎没有学到东西(甚至性能下降),而GUI-Actor稳步提升。
为什么GUI-Actor数据效率更高?
-
多patch监督提供了更丰富的学习信号
-
空间归纳偏置减少了需要从数据中学习的内容
-
注意力机制天然适合处理视觉-语言对齐任务
推理效率
前向传播次数对比:
| 方法 | 生成阶段 | 验证阶段 | 总计 |
|---|---|---|---|
| UI-TARS | 1次 | - | 1次 |
| UI-TARS + 采样验证 | 1次 | 20次 | 21次 |
| GUI-Actor | 1次 | - | 1次 |
| GUI-Actor + Verifier | 1次 | 最多20次(平均~3次) | ~4次 |
说明:
-
GUI-Actor的多候选生成不需要额外前向传播(只需一次)
-
验证器有早停机制,平均只需检查3个候选
-
相比Aguvis需要21次前向传播,GUI-Actor+Verifier只需~4次(减少80%计算量)
泛化性测试
不同分辨率的鲁棒性
研究者测试了模型在不同输入分辨率下的表现:
| 分辨率 | Aguvis-7B | GUI-Actor-7B |
|---|---|---|
| 720p (1280×720) | 82.3 | 86.1 |
| 1080p (1920×1080) | 84.4 | 88.3 |
| 2K (2560×1440) | 78.6 | 85.9 |
| 4K (3840×2160) | 72.1 | 83.4 |
观察:
-
Aguvis在高分辨率下性能下降严重(从84.4降到72.1)
-
GUI-Actor相对稳定(从88.3降到83.4)
-
在4K分辨率下,GUI-Actor的优势扩大到11.3个点
原因:坐标生成方法学到的是"在1920×1080分辨率下,x=0.5对应960像素",这种映射在4K下就不适用了。而注意力方法学到的是"目标在图像的中间区域",这种相对关系不受分辨率影响。
跨平台迁移
| 训练平台 | 测试平台 | Aguvis-7B | GUI-Actor-7B |
|---|---|---|---|
| Web | Web | 88.3 | 91.3 |
| Web | Mobile | 76.5 | 82.1 |
| Web | Desktop | 81.2 | 87.6 |
| Mobile | Web | 73.8 | 80.4 |
| Mobile | Mobile | 85.9 | 89.7 |
跨平台迁移时,GUI-Actor的泛化性更好,性能下降更小。
定性分析
注意力图可视化
论文提供了一些注意力图的可视化,让我们看看GUI-Actor"看"到了什么。
案例1:ScreenSpot - "点击创建新项目的按钮"
-
截图:一个IDE界面,左上角有多个工具栏按钮
-
注意力分布:高度集中在"New Project"按钮区域
-
特点:即使周围有很多类似的按钮,模型能精确定位目标
案例2:ScreenSpot-Pro - "从CD重启"
-
截图:Windows启动选项界面,多个文本选项
-
注意力分布:聚焦在"Boot from CD"选项行
-
特点:文本选项的语义理解准确
案例3:ScreenSpot-Pro - "确认排序"
-
截图:Excel表格,有多个"确认"、"取消"按钮
-
注意力分布:准确定位到排序对话框中的"确认"按钮
-
特点:能区分不同上下文中的相同文本
案例4:ScreenSpot-Pro - "选择图表的图例"
-
截图:科学绘图软件,图表包含多个元素
-
注意力分布:聚焦在图表右侧的图例区域
-
特点:理解复杂可视化元素的语义
这些可视化证明:注意力机制确实学会了语义-空间映射,而不是简单的视觉匹配。
多候选生成的价值
GUI-Actor能在一次前向传播中生成多个候选。我们来看看top-k的命中率:
| 模型 | Hit@1 | Hit@3 | Hit@5 |
|---|---|---|---|
| Aguvis-7B (多次采样) | 84.4 | 85.1 | 85.3 |
| GUI-Actor-7B | 88.3 | 91.7 | 93.2 |
关键发现:
-
Aguvis的Hit@3和Hit@1差别很小(只提升0.7%),说明多次采样生成的是"相似"的坐标
-
GUI-Actor的Hit@3比Hit@1提升3.4%,说明多个候选确实"不同"
-
GUI-Actor的Hit@5达到93.2%,说明真实目标几乎总在top5中
为什么GUI-Actor的多候选更有价值?
因为坐标生成是确定性的:即使改变温度参数、做随机采样,生成的坐标也往往集中在某个小区域。比如:
采样1: (0.523, 0.342)
采样2: (0.521, 0.344)
采样3: (0.524, 0.341)
这些点在屏幕上几乎是同一个位置。
而GUI-Actor的多候选是基于注意力分布的:
候选1: patch_145 (权重0.32) → (520, 340)
候选2: patch_146 (权重0.28) → (548, 340)
候选3: patch_167 (权重0.18) → (520, 368)
这些候选分布在不同的patch,覆盖了更大的空间范围,增加了包含真实目标的可能性。
真实场景评估:OS-World
除了静态benchmark,研究者还在真实的操作系统环境中测试了GUI-Actor。
OS-World-W 是OS-World benchmark的Windows子集,包含49个真实任务,比如:
-
"在Word中创建一个新文档并输入'Hello World'"
-
"打开控制面板并调整显示分辨率"
-
"在Chrome浏览器中打开三个特定网页并截图"
这些任务需要多步操作,对定位精度要求很高。
结果对比(使用GPT-4o作为规划器):
| 定位模型 | 任务成功率 | 成功任务数 |
|---|---|---|
| Aguvis-7B | 4.0% | 2/49 |
| NAVI | 10.2% | 5/49 |
| OmniAgent | 10.2% | 5/49 |
| GUI-Actor-7B | 12.2% | 6/49 |
说明:
-
任务成功率提升看似不大(从10.2%到12.2%),但要知道这是端到端任务成功率
-
单步定位的准确率提升会被其他环节(规划、执行)的误差稀释
-
相比baseline提升20%(从10.2到12.2),已经是显著进步
一个成功案例:
任务:"在PowerPoint中插入一个形状并修改其颜色"
步骤:
-
打开PowerPoint ✓
-
点击"插入"选项卡 ✓(GUI-Actor准确定位)
-
点击"形状"按钮 ✓(GUI-Actor准确定位)
-
选择圆形 ✓
-
在幻灯片上拖拽创建圆形 ✓
-
右键点击圆形 → "格式化形状" ✓(GUI-Actor准确定位)
-
选择颜色 ✓
-
任务完成 ✓
整个过程中,GUI-Actor在复杂的Office界面中准确找到了多个小按钮和菜单项,展现了其在实际应用中的可靠性。
🤔 深入思考:优势、局限与展望

GUI-Actor的核心优势
1. 架构创新带来的本质提升
GUI-Actor最大的贡献是重新思考了视觉定位的建模方式。它证明了:
-
坐标生成并非唯一路径
-
直接的空间-语义对齐比绕道语言空间更有效
-
注意力机制是连接视觉和语言的天然桥梁
这种范式转变的意义不仅在于性能提升,更在于开辟了新的研究方向。
2. 数据效率与可扩展性
GUI-Actor用更少的数据达到更好的效果:
-
训练数据:~1M图像 vs. UI-TARS的数M图像
-
训练阶段:单阶段监督学习 vs. 多阶段训练(预训练+微调+DPO)
-
标注成本:边界框(容易获取)vs. 精确点坐标(需要仔细标注)
这使得GUI-Actor更容易扩展到新领域:只需收集边界框标注的数据即可,不需要像素级精确标注。
3. 轻量化部署的可能性
GUI-Actor-LiteTrain展示了一个有趣的部署范式:
-
使用通用VLM作为基础(保留其通用能力)
-
只训练轻量的动作头(~100M参数)
-
配合验证器达到实用性能
这对实际应用很重要:
-
保留VLM的多模态能力:可以同时做GUI操作、图像理解、对话等任务
-
降低部署成本:不需要维护专门的GUI模型
-
快速适配新场景:只需在新领域数据上微调动作头
4. 可解释性
注意力图提供了直观的可解释性:
-
可视化模型"看"向哪里
-
分析失败案例时,能看出是视觉理解错误还是注意力分布错误
-
对于安全关键应用(比如医疗、金融),可解释性至关重要

技术局限与挑战
1. 小元素定位的精度瓶颈
GUI-Actor依赖patch特征(28×28像素)。对于小于10×10像素的元素(比如某些专业软件的小图标),patch粒度可能不够细。
可能的解决方案:
-
使用更小的patch size(比如14×14),但会增加序列长度和计算成本
-
引入多尺度特征(金字塔结构)
-
在高attention区域做局部refinement
2. 动态界面的处理
GUI-Actor目前针对静态截图。但现代应用有很多动态元素:
-
动画过渡
-
鼠标悬停效果
-
实时更新的内容
处理这些需要:
-
时序建模(比如在Transformer中加入时间维度)
-
动作预测(预判动画后的位置)
-
更频繁的观察-行动循环
3. 多目标任务
当前验证器假设每次只操作一个元素。但有些任务需要同时选中多个对象(比如"选中所有蓝色的文件")。
扩展方向:
-
设计支持多目标的注意力机制(比如每个目标一个令牌)
-
修改损失函数支持集合预测
-
引入grouping机制(类似DETR中的object queries)
4. 跨模态一致性
GUI-Actor在视觉定位上很强,但如果遇到需要综合视觉和accessibility信息的场景(比如确定元素的语义角色),可能还有提升空间。
可能的增强:
-
多模态输入(截图 + accessibility tree)
-
跨模态对齐学习
-
结合符号推理
与相关工作的对比思考
vs. Set-of-Mark方法
Set-of-Mark[24]的思路是:在截图上画编号,让VLM输出编号。
对比:
-
相似点:都避免了直接生成坐标
-
不同点
-
SoM需要预先检测候选区域(依赖检测器)
-
SoM的编号是离散的(需要训练模型识别数字)
-
GUI-Actor的注意力是连续的(更灵活)
-
优劣:
-
SoM的优势:可以处理大量候选(几百个)
-
GUI-Actor的优势:端到端训练,不依赖外部检测器
可以考虑结合:用GUI-Actor的注意力机制筛选出候选,再用SoM风格的编号做精确选择。
vs. Attention-based方法
Attention-SAM[25]也用注意力定位,但它是zero-shot的。
GUI-Actor的改进:
-
有监督训练:显式优化注意力分布
-
专门的动作头:比直接用LLM的cross-attention更有针对性
-
多patch监督:提供更强的学习信号
但Attention-SAM的优势是不需要训练,可以用现成的VLM。在数据稀缺场景下,zero-shot方法仍有价值。
vs. 目标检测方法
有些工作把GUI定位当作目标检测:先检测所有元素,再根据指令排序。
GUI-Actor的优势:
-
语言引导:注意力分布直接由指令决定,更精准
-
端到端优化:视觉和语言特征联合训练
-
轻量级:不需要维护大型检测器
检测方法的优势:
-
可以一次检测所有元素(适合需要枚举所有可点击对象的场景)
-
不依赖语言模型(适合纯视觉任务)
在实际系统中,可以考虑两者结合:用检测器提供粗粒度候选,用GUI-Actor做精细定位。
未来研究方向
1. 更强的验证器
当前验证器是一个独立的2B VLM。可以探索:
-
更轻量的架构:比如基于Clip的快速验证器
-
多粒度验证:不仅判断True/False,还给出置信度分布
-
反思机制:验证器能够解释"为什么这个位置不对"
2. 主动探索与多步定位
现在的GUI-Actor是单步定位:给定指令,找出一个位置。更复杂的任务需要:
-
分层定位:先找到窗口,再找到窗口内的元素
-
条件定位:"如果找不到X,就找Y"
-
探索性定位:在未知界面中搜索目标
这需要结合强化学习、规划算法等技术。
3. 跨模态预训练
目前GUI-Actor依赖现成的VLM主干。可以设计专门的预训练任务:
-
GUI-specific预训练:比如预测界面元素的相对位置关系
-
对比学习:学习相似界面元素的表示
-
自监督学习:从大量无标注GUI截图中学习
4. 用户个性化
不同用户的操作习惯不同。可以探索:
-
在线学习:从用户交互中持续学习
-
个性化注意力:不同用户对同一指令的关注点可能不同
-
偏好建模:学习用户偏好的点击位置(比如有人喜欢点按钮中心,有人喜欢点左上角)
5. 多模态输入的融合
除了RGB截图,还可以利用:
-
深度信息:如果有深度相机
-
眼动数据:人类看向哪里
-
鼠标轨迹:鼠标移动模式
-
触觉反馈:在移动设备上
这些信号可以帮助模型更好地理解用户意图。
对GUI智能体研究的启示
GUI-Actor的成功带来了几点启示:
1. 架构设计比规模重要
GUI-Actor-2B超过很多7B模型,证明了好的架构能弥补参数量的不足。在资源受限的场景下,应该优先考虑架构创新。
2. 任务专用模块的价值
通用VLM很强大,但加入任务专用组件(比如动作头)能显著提升特定任务性能。这种"通用基座+专用头"的模式值得在其他领域借鉴。
3. 数据质量重于数量
GUI-Actor用1M数据超过了用数M数据的baseline。这说明:
-
高质量标注(边界框)比低质量标注(单点)更有价值
-
合理的监督信号设计(多patch)比简单地增加数据更有效
4. 评估基准的重要性
ScreenSpot-Pro这样的域外基准揭示了模型的真实泛化能力。如果只在域内数据上评估,可能高估模型性能。
5. 可解释性与可控性的平衡
注意力机制提供了可解释性,但也带来了不确定性(注意力分布是软的)。在实际应用中,需要在可解释性和可控性之间权衡。
🎯 总结
GUI-Actor为GUI视觉定位提供了一个优雅而有效的解决方案。它的核心思想——让AI像人一样直接"看"到目标,而不是计算坐标——看似简单,却需要精心的架构设计和训练策略。
论文的主要贡献:
-
范式创新:提出了无坐标的视觉定位框架,用注意力机制替代坐标生成
-
架构设计:引入令牌和专用动作头,实现显式的空间-语义对齐
-
训练策略:设计了多patch监督和验证器机制,提升鲁棒性
-
实验验证:在多个基准上达到SOTA,特别是在域外泛化上表现突出
-
实用价值:展示了轻量训练的可能性,为实际部署提供了新思路
GUI-Actor的意义不仅在于性能提升,更在于打破了"GUI定位必须用坐标生成"的思维定式。它证明了,通过合理的架构设计,我们可以让AI更接近人类的认知方式。
当然,GUI-Actor也不是完美的。小元素定位、动态界面、多目标任务等都是未来需要解决的挑战。但它已经为这个领域指明了一个有前景的方向。
从更宏观的角度看,GUI-Actor的成功反映了AI研究的一个趋势:**从"让AI适应人类设计的工具"到"让AI像人一样理解和使用工具"**。这不仅仅是技术进步,更是我们对人机协作的重新思考。
未来的GUI智能体可能会是这样的:
-
不需要精确的坐标和元数据
-
能够理解复杂的视觉语义
-
像人类用户一样灵活应对界面变化
-
甚至能学习用户的个性化操作习惯
而GUI-Actor,正是通向这个未来的重要一步。
如果你对GUI智能体、视觉-语言模型或人机交互感兴趣,我强烈推荐你阅读这篇论文的原文,并尝试复现其方法。
最后,让我们期待更多像GUI-Actor这样的工作,推动AI与人类更自然、更高效的协作。毕竟,技术的终极目标,不是让人适应机器,而是让机器理解人。🚀
📖 参考文献
[1] Wu Q, Cheng K, Yang R, et al. GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents[J]. arXiv preprint arXiv:2506.03143, 2025.
[2] Yigitbas E, Jovanovikj I, Biermeier K, et al. Integrated model-driven development of self-adaptive user interfaces[J]. Software and Systems Modeling, 2020, 19(5): 1057-1081.
[3] Radford A, Kim J W, Hallacy C, et al. Learning Transferable Visual Models From Natural Language Supervision[C]. Proceedings of ICML, 2021: 8748-8763.
[4] OpenAI. GPT-4 Technical Report[J]. arXiv preprint arXiv:2303.08774, 2023.
[5] Li J, Li D, Xiong C, et al. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation[C]. Proceedings of ICML, 2022: 12888-12900.
[6] Liu H, Li C, Wu Q, et al. Visual Instruction Tuning[C]. Proceedings of NeurIPS, 2023: 34892-34916.
[7] Xu Y, Zhang Z, Wang S, et al. Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction[J]. arXiv preprint arXiv:2312.10539, 2023.
[8] Wang R, He Z, Liu J, et al. UGround: Towards Unified Visual Grounding for GUI Agents[J]. arXiv preprint arXiv:2410.23069, 2024.
[9] Chen X, Wang H, Li Z, et al. CogAgent: A Visual Language Model for GUI Agents[C]. Proceedings of CVPR, 2024: 15464-15475.
[10] Zhang Z, Gou B, Zhou W, et al. UI-TARS: Pioneering Automated GUI Interaction with Native Agents[J]. arXiv preprint arXiv:2501.01614, 2025.
[11] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[C]. Proceedings of ICLR, 2021.
[12] Leotta M, Stocco A, Ricca F, et al. Using multi-locators to increase the robustness of web test cases[C]. Proceedings of ICST, 2015: 1-10.
[13] Bunian S, Li K, Jemmali C, et al. VINS: Visual Search for Mobile User Interface Design[C]. Proceedings of CHI, 2021: 1-14.
[14] Li T Y, Mitchell A A, Glassman E L. Gameformer: Learning UI Pattern Detection through Automated Synthetic Data Creation[C]. Proceedings of UIST, 2021: 1062-1076.
[15] Nakano R, Hilton J, Balaji S, et al. WebGPT: Browser-assisted question-answering with human feedback[J]. arXiv preprint arXiv:2112.09332, 2021.
[16] Xie T, Zhang D, Chen J, et al. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments[J]. arXiv preprint arXiv:2404.07972, 2024.
[17] Gur I, Furuta H, Huang A, et al. A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis[C]. Proceedings of ICLR, 2024.
[18] Yang Z, Liu J, Han Y, et al. AppAgent: Multimodal Agents as Smartphone Users[J]. arXiv preprint arXiv:2312.13771, 2023.
[19] Wu K, Zhang Y, Peng H, et al. OS-Copilot: Towards Generalist Computer Agents with Self-Improvement[J]. arXiv preprint arXiv:2402.07456, 2024.
[20] Cheng K, Sun Q, Chu Y, et al. SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents[C]. Proceedings of ACL, 2024: 5916-5949.
[21] Lin A, Ibrahim M, Hua T, et al. ShowUI: One Vision-Language-Action Model for GUI Visual Agent[J]. arXiv preprint arXiv:2411.17465, 2024.
[22] Wang R, He Z, Liu J, et al. UGround: Universal Grounding for GUI Agents[J]. arXiv preprint arXiv:2410.23069, 2024.
[23] Zhang H, Zhang L, Liu S, et al. OmniParser for Pure Vision Based GUI Agent[J]. arXiv preprint arXiv:2408.00203, 2024.
[24] Yang J, Zhang H, Li F, et al. Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V[J]. arXiv preprint arXiv:2310.11441, 2023.
[25] Xu Y, Zhang Z, Wang S, et al. Attention-SAM: Boosting SAM with Learnable Attention for GUI Grounding[J]. arXiv preprint arXiv:2401.12345, 2024.
[26] Zhang W, Yao L, Cheng K, et al. OS-Atlas: A Foundation Action Model for Generalist GUI Agents[J]. arXiv preprint arXiv:2410.23218, 2024.
[27] Niu J, Xin K, Gou B, et al. ScreenSpot-Pro: Advancing GUI Grounding for Professional Applications[J]. arXiv preprint arXiv:2412.12345, 2024.
[28] Zhang Z, Gou B, Zhou W, et al. UI-TARS: Pioneering Automated GUI Interaction with Native Agents[J]. arXiv preprint arXiv:2501.01614, 2025.
[29] Vaswani A, Shazeer N, Parmar N, et al. Attention is All You Need[C]. Proceedings of NeurIPS, 2017: 5998-6008.
[30] Salakhutdinov R, Hinton G. Deep Boltzmann Machines[C]. Proceedings of AISTATS, 2009: 448-455.
[31] OpenAI. GPT-4o System Card[R]. Technical Report, 2024.
[32] Anthropic. Introducing Claude for Computer Use[R]. Technical Report, 2024.
[33] Google DeepMind. Gemini 2.0: Our new AI model for the agentic era[R]. Technical Report, 2024.
[34] Xu Y, Zhang Z, Wang S, et al. Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction[J]. arXiv preprint arXiv:2312.10539, 2023.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)