利用遗传算法求解混合流水车间调度问题
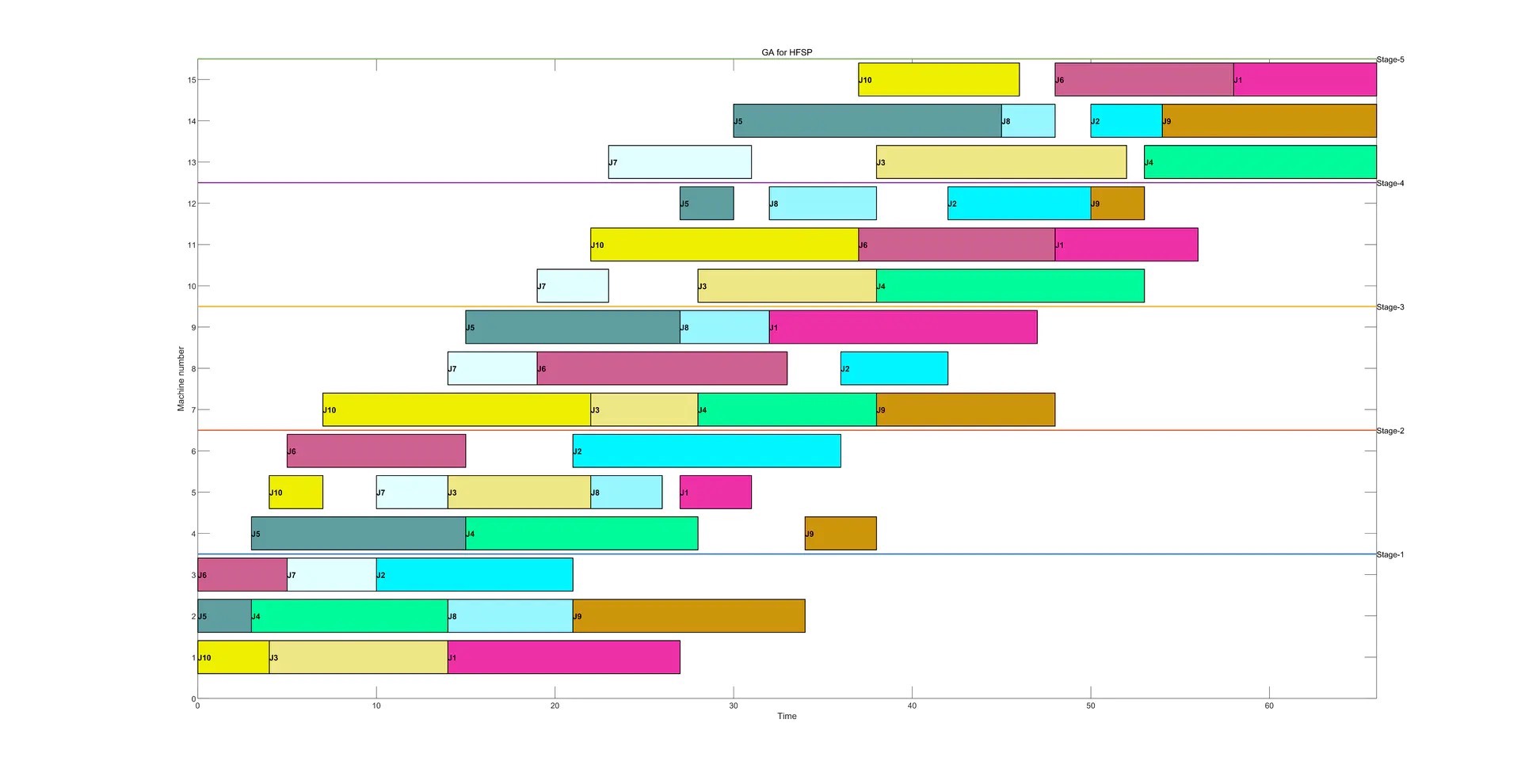
利用遗传算法(GA)求解混合流水车间调度问题(Hybrid flow-shop scheduling problem, HFSP) 其中:main.m是主函数运行即可;GA.m是算法的代码;colorplus.p是一个颜色补充包,用于获得甘特图的颜色配置;cheatsheet.png是colorplus.p颜色补充包中的颜色参考示范以及调用方法说明;gantt_chart.m用来绘制甘特图;objective.m是目标函数,即计算Makespan;data.xlsx是HFSP的测试案例,行数为机器数,列数为阶段数,最后一行为每个阶段的并行机器数 输出结果包括:Makespan、每个加工阶段的工件排序、计算时间、最优适宜度收敛曲线、平均适宜度收敛曲线、甘特图 利用GA得到的\"j10c5d1\"算例的调度结果甘特图演示如下(随机运行一次的结果):
在工业生产调度领域,混合流水车间调度问题(HFSP)一直是个备受关注的难题。而遗传算法(GA)凭借其强大的全局搜索能力,成为解决这类问题的有效手段。今天就来和大家分享下如何利用遗传算法求解HFSP。
一、整体框架
我们整个项目由多个文件协同完成。其中 main.m 是主函数,运行它就可以启动整个求解流程。就像整个项目的指挥官,一声令下,各部分就开始各司其职。
% main.m 主函数示例框架
% 初始化参数
pop_size = 100; % 种群大小
gen_num = 200; % 遗传代数
% 读取数据
data = readtable('data.xlsx');
% 调用遗传算法
[best_solution, best_fitness, avg_fitness, elapsed_time] = GA(pop_size, gen_num, data);
% 计算Makespan
makespan = objective(best_solution, data);
% 绘制收敛曲线
figure;
subplot(2,1,1);
plot(1:gen_num, best_fitness);
title('最优适宜度收敛曲线');
xlabel('代数');
ylabel('最优适宜度');
subplot(2,1,2);
plot(1:gen_num, avg_fitness);
title('平均适宜度收敛曲线');
xlabel('代数');
ylabel('平均适宜度');
% 绘制甘特图
gantt_chart(best_solution, data);1. GA.m - 遗传算法核心代码
这个文件包含了遗传算法的具体实现,从种群初始化到选择、交叉、变异等一系列操作。以种群初始化部分为例:
% GA.m 种群初始化部分
function population = initialize_population(pop_size, num_jobs, num_stages, parallel_machines)
population = zeros(pop_size, sum(parallel_machines));
for i = 1:pop_size
job_sequence = repmat(1:num_jobs, 1, length(parallel_machines));
population(i, :) = job_sequence(randperm(num_jobs * length(parallel_machines)));
end
end这里我们随机生成初始种群,每个个体表示一种工件加工顺序。通过 randperm 函数对工件序列进行随机排列,为后续的遗传操作提供初始的多样性。
2. objective.m - 目标函数
objective.m 负责计算Makespan,也就是完成所有工件加工所需的总时间,这是我们衡量调度方案优劣的关键指标。
function makespan = objective(solution, data)
% 根据solution和data计算每台机器每个阶段的加工时间
% 核心计算逻辑
% 假设已经有计算好的各阶段各机器加工时间矩阵processing_time
num_stages = size(data, 2) - 1;
num_jobs = length(unique(solution));
completion_time = zeros(num_jobs, num_stages);
for stage = 1:num_stages
for job = 1:num_jobs
job_index = find(solution == job, 1, 'first');
% 省略具体查找机器和计算时间逻辑
if stage == 1
completion_time(job, stage) = processing_time(job_index, stage);
else
% 考虑前一阶段完成时间
completion_time(job, stage) = max(completion_time(job, stage - 1), prev_job_completion) + processing_time(job_index, stage);
end
end
end
makespan = max(completion_time(:, end));
end这段代码通过对每个工件在每个阶段的加工时间进行计算,最终得到整个调度方案的Makespan。
3. gantt_chart.m - 绘制甘特图
这个函数用于将我们得到的调度结果以甘特图的形式可视化展示出来。
function gantt_chart(solution, data)
% 计算各阶段开始时间和结束时间等数据
% 获取颜色配置
color_config = colorplus;
% 绘制甘特图
figure;
% 假设有计算好的各阶段开始时间start_time和结束时间end_time
for stage = 1:num_stages
for job = 1:num_jobs
barh(machine_index, end_time - start_time, 'FaceColor', color_config(job));
text(machine_index, start_time + (end_time - start_time)/2, ['J', num2str(job)]);
end
end
% 设置坐标轴标签等
xlabel('时间');
ylabel('机器');
title('甘特图');
end这里通过 colorplus 这个颜色补充包来获取不同工件在甘特图上显示的颜色配置,让甘特图更加直观清晰。
4. colorplus.p - 颜色补充包
这个包提供了甘特图的颜色配置。虽然没有具体代码展示,但是 cheatsheet.png 对其颜色参考示范以及调用方法做了详细说明。在 gantt_chart.m 中就通过调用它来给不同工件在甘特图上赋予不同颜色,增强可视化效果。
二、输出结果
1. Makespan
通过 objective.m 计算得出,它反映了整个调度方案的优劣,越小说明调度越高效。
2. 每个加工阶段的工件排序
这直接体现在遗传算法生成的最优解 best_solution 中,每个位置对应一个工件编号,按照顺序就是工件在各阶段的加工顺序。
3. 计算时间
在 main.m 中通过记录算法开始和结束时间差来获取,例如 elapsed_time = toc; 这能帮助我们评估算法的效率。
4. 最优适宜度收敛曲线、平均适宜度收敛曲线
通过 GA.m 中每代计算的最优适宜度和平均适宜度数据,在 main.m 中利用 plot 函数绘制得出,能直观看到算法的收敛情况。
5. 甘特图
由 gantt_chart.m 根据最优解和数据绘制而成,以图形化方式展示每个工件在各台机器上的加工时间分布,方便我们理解调度方案。
以 “j10c5d1” 算例随机运行一次得到的甘特图为例,我们能清晰看到不同工件在各个阶段机器上的加工顺序和时间占用情况,从而评估调度方案是否合理。
通过这些文件和操作,我们就利用遗传算法实现了对混合流水车间调度问题的求解,并得到了一系列有价值的结果。希望这篇博文能给同样在研究这类问题的朋友一些启发和帮助。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)