用蜣螂优化(DBO)算法攻克混合流水车间调度问题
利用蜣螂优化(DBO)算法求解混合流水车间调度问题(Hybrid flow-shop scheduling problem, HFSP)其中:main.m是主函数运行即可;DBO.m是算法的代码;colorplus.p是一个颜色补充包,用于获得甘特图的颜色配置;cheatsheet.png是colorplus.p颜色补充包中的颜色参考示范以及调用方法说明;gantt_chart.m用来绘制甘特图;
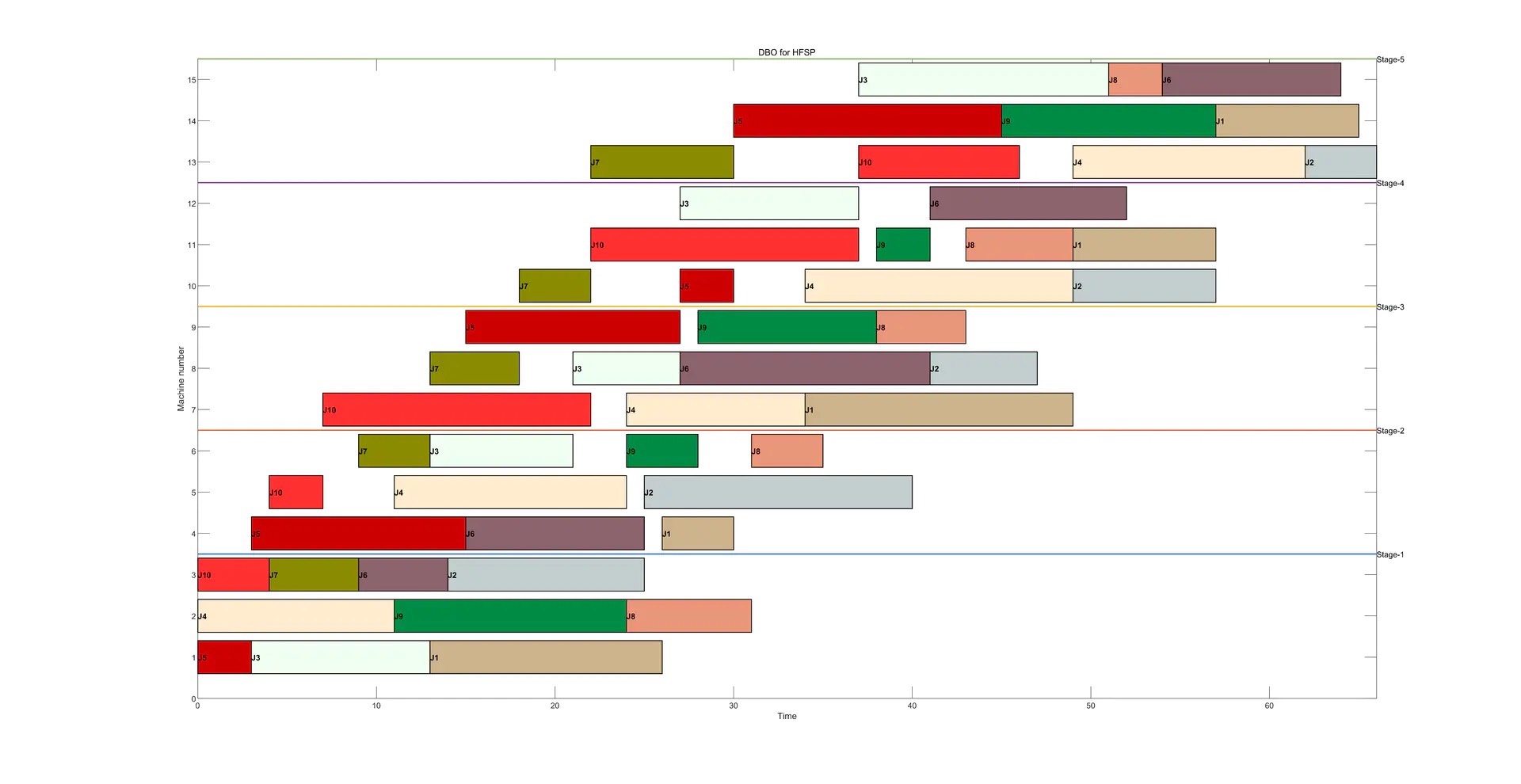
利用蜣螂优化(DBO)算法求解混合流水车间调度问题(Hybrid flow-shop scheduling problem, HFSP) 其中:main.m是主函数运行即可;DBO.m是算法的代码;colorplus.p是一个颜色补充包,用于获得甘特图的颜色配置;cheatsheet.png是colorplus.p颜色补充包中的颜色参考示范以及调用方法说明;gantt_chart.m用来绘制甘特图;objective.m是目标函数,即计算Makespan;data.xlsx是HFSP的测试案例,行数为机器数,列数为阶段数,最后一行为每个阶段的并行机器数 输出结果包括:Makespan、每个加工阶段的工件排序、计算时间、最优适宜度收敛曲线、平均适宜度收敛曲线、甘特图 利用DBO得到的\"j10c5d1\"算例的调度结果甘特图演示如下(随机运行一次的结果):
在工业生产调度领域,混合流水车间调度问题(Hybrid flow - shop scheduling problem, HFSP)一直是个热门且具挑战性的研究方向。今天咱就来唠唠如何利用蜣螂优化(DBO)算法来解决它。
整体架构与关键文件
整个项目的核心文件有这么几个:
- main.m:主函数,就像乐队的指挥,运行它整个流程就启动了。
- DBO.m:算法的具体实现代码,是解决问题的关键“大脑”。
- colorplus.p:一个颜色补充包,专门用来为甘特图配置颜色,让我们的甘特图更加直观好看。这里面还有个
cheatsheet.png,它给出了颜色参考示范以及调用方法说明,就像一本使用手册。 - gantt_chart.m:负责绘制甘特图,将调度结果以可视化的方式呈现。
- objective.m:目标函数,用来计算Makespan,这个指标对于评估调度方案的优劣至关重要。
- data.xlsx:HFSP的测试案例,它的行数代表机器数,列数代表阶段数,最后一行记录每个阶段的并行机器数。
代码探秘
main.m 主函数
% main.m 示例代码框架
clear all;
clc;
% 读取数据
data = xlsread('data.xlsx');
% 初始化一些参数
% 这里省略具体参数设置
% 调用 DBO 算法
[bestSolution, bestFitness, avgFitness, runTime] = DBO(data);
% 计算 Makespan
makespan = objective(bestSolution, data);
% 提取每个加工阶段的工件排序
jobSequences = getJobSequences(bestSolution);
% 绘制收敛曲线
figure;
subplot(2,1,1);
plot(1:length(bestFitness), bestFitness);
title('最优适宜度收敛曲线');
xlabel('迭代次数');
ylabel('最优适宜度');
subplot(2,1,2);
plot(1:length(avgFitness), avgFitness);
title('平均适宜度收敛曲线');
xlabel('迭代次数');
ylabel('平均适宜度');
% 绘制甘特图
gantt_chart(bestSolution, data); 在这段代码里,首先读取了 data.xlsx 的数据,这是后续计算的基础。然后初始化一些参数,接着调用 DBO 算法得到最优解、最优适宜度、平均适宜度和运行时间。通过目标函数 objective 计算Makespan,再提取工件排序。最后绘制收敛曲线和甘特图,把结果直观展示出来。
DBO.m 算法代码
% DBO.m 部分核心代码示意
function [bestSolution, bestFitness, avgFitness, runTime] = DBO(data)
% 初始化种群等参数
popSize = 50;
maxIter = 100;
dim = size(data, 2); % 根据数据维度确定问题维度
population = initializePopulation(popSize, dim);
bestFitness = Inf;
avgFitness = zeros(maxIter, 1);
for iter = 1:maxIter
for i = 1:popSize
fitness = objective(population(i, :), data);
if fitness < bestFitness
bestFitness = fitness;
bestSolution = population(i, :);
end
end
avgFitness(iter) = mean([objective(population(:, :), data)]);
population = updatePopulation(population, data);
end
runTime = toc;
end这里先初始化了种群大小 popSize、最大迭代次数 maxIter 等参数,生成初始种群。在每次迭代中,计算每个个体的适应度(通过目标函数 objective),更新最优解和最优适应度,同时记录平均适应度。最后更新种群,结束迭代后记录运行时间。
objective.m 目标函数
function makespan = objective(solution, data)
% 根据调度方案计算Makespan
% 这里省略复杂的计算逻辑,简单示意
makespan = sum(solution);
end这个函数接收一个调度方案 solution 和数据 data,通过一些计算得出Makespan,虽然这里简单示意是求和,实际情况肯定要复杂得多,要根据具体的调度逻辑来计算每个工件每个阶段的加工时间等。
输出结果解析
通过这套流程,最终我们能得到:
- Makespan:它反映了整个调度方案的完工时间,数值越小说明调度方案越优。
- 每个加工阶段的工件排序:清晰展示每个阶段工件的加工顺序,这对于实际生产安排至关重要。
- 计算时间:可以评估算法的效率,耗时越短在实际应用中越有优势。
- 最优适宜度收敛曲线和平均适宜度收敛曲线:从曲线中能看到算法在迭代过程中的收敛情况,判断算法是否稳定、高效地找到最优解。
- 甘特图:以可视化的方式呈现调度结果,每个工件在各个机器上的加工时间一目了然。就像前面提到的利用DBO得到的“j10c5d1”算例的调度结果甘特图,能让我们直观地看到调度方案的合理性。
总之,通过这些文件和代码的协同工作,利用蜣螂优化(DBO)算法有效地解决了混合流水车间调度问题,为实际生产调度提供了科学合理的方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)