[Extreme Programming]通讯录项目开发博客
(Ai提取)本项目开发了一个基于Flask框架的通讯录管理系统,实现了联系人新建/修改/删除/收藏、Excel导入导出等功能。团队采用前后端分离架构,使用SQLAlchemy进行数据库操作,pandas处理Excel文件。开发过程中解决了应用上下文缺失、Excel依赖库安装等技术问题,最终完成了一个功能完善的Web应用。项目培养了团队成员在Flask框架使用、数据库操作和团队协作方面的能力。系统已
通讯录项目开发博客
小队成员:
夏鹏 832302221(FZU) 23125993(MU)
郭祺域 832302223(FZU) 23125519(MU)
| Course for This Assignment | Web应用开发实践 |
| Team Name | 六六六队 |
| Assignment Requirements | 联系人新建/修改(多联系方式)/删除/收藏功能 Excel导入与导出 |
| Objectives of This Assignment | 熟悉Flask框架及SQLAlchemy数据库操作,掌握Web应用开发流程,提升团队协作与版本控制能力 |
| Other References | Flask官方文档、SQLAlchemy文档 |
1.项目地址:
项目地址:https://contactproject-phi.vercel.app/ (需要魔法)
GITHUB地址:https://github.com/1525028626/contact_project
2.Github提交截图:
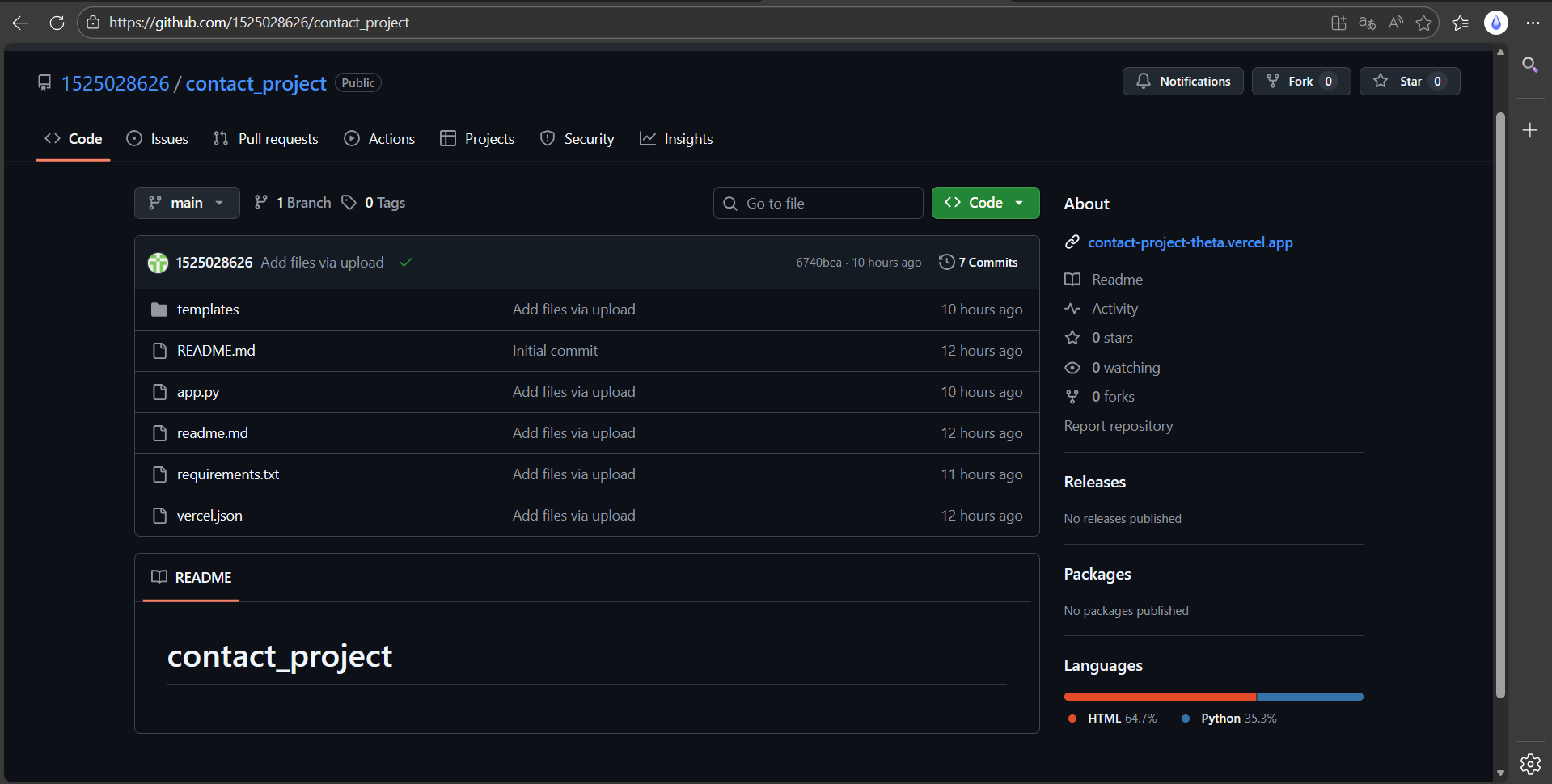
3.功能实现思路:
3.1 数据库模型:
id:主键(自增)
name用于存储联系人姓名(非空)
is_favorite用于存储收藏状态(布尔值,默认 False)(收藏功能)
details用于存储联系人详情(文本类型,存储 JSON 字符串)
3.2 数据导入导出(Excel):
导出 Excel:
查询所有联系人--遍历处理每一条数据--构建行数据(姓名、是否收藏)--解析details(遍历详情项, type作列名, val作列值)--使用pandas创建 DataFrame, 写入内存 BytesIO 对象--通过send_file返回 Excel 文件
导入 Excel:
接收前端上传的 Excel 文件--使用pandas读取 Excel 文件--遍历每一行数据(提取姓名、是否收藏)
--遍历非核心列(联系人详细信息)--构建详情列表(type作列名, val作列值)--实例化Contact对象--添加到数据库会话--提交数据库
3.3 联系人检索:
获取前端传入的参数:favorite(是否只看收藏)、'q'(搜索关键词)
构建基础查询对象:Contact.query
搜索逻辑:使用or_多条件查询,在name和details(详情 JSON 字符串)中包含关键词
筛选逻辑:如果favorite=true,只查询is_favorite=True的联系人
排序:优先按is_favorite降序(收藏的在前),再按id降序(最新的在前)
返回:将查询结果转换为字典列表,以 JSON 格式返回
3.4 异常处理思路:
经过多轮测试,我们在代码关键节点添加了异常处理,避免崩溃:
to_dict()方法中:捕获 JSON 解析异常,默认返回空列表
数据库初始化:捕获异常并打印错误信息
导入 Excel:捕获所有异常,返回错误信息给前端
详情解析(导出 / 导入):使用try-except处理 JSON 解析失败的情况
4.功能实现演示:
初始页面(三个示例为提前准备):
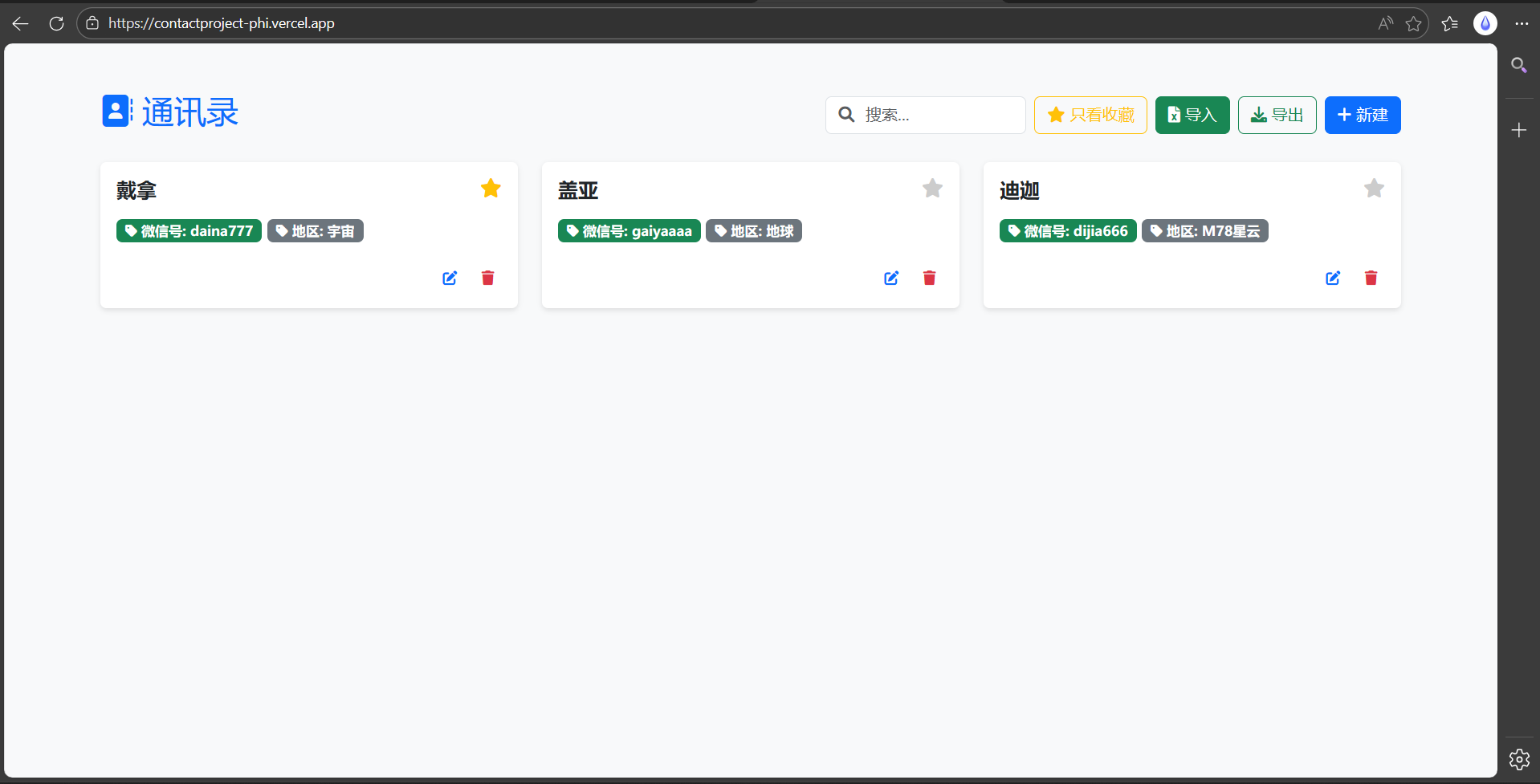
点击右上角蓝色“新建”,将弹出新建联系人窗口,在这里可以任意添加联系人相关信息:
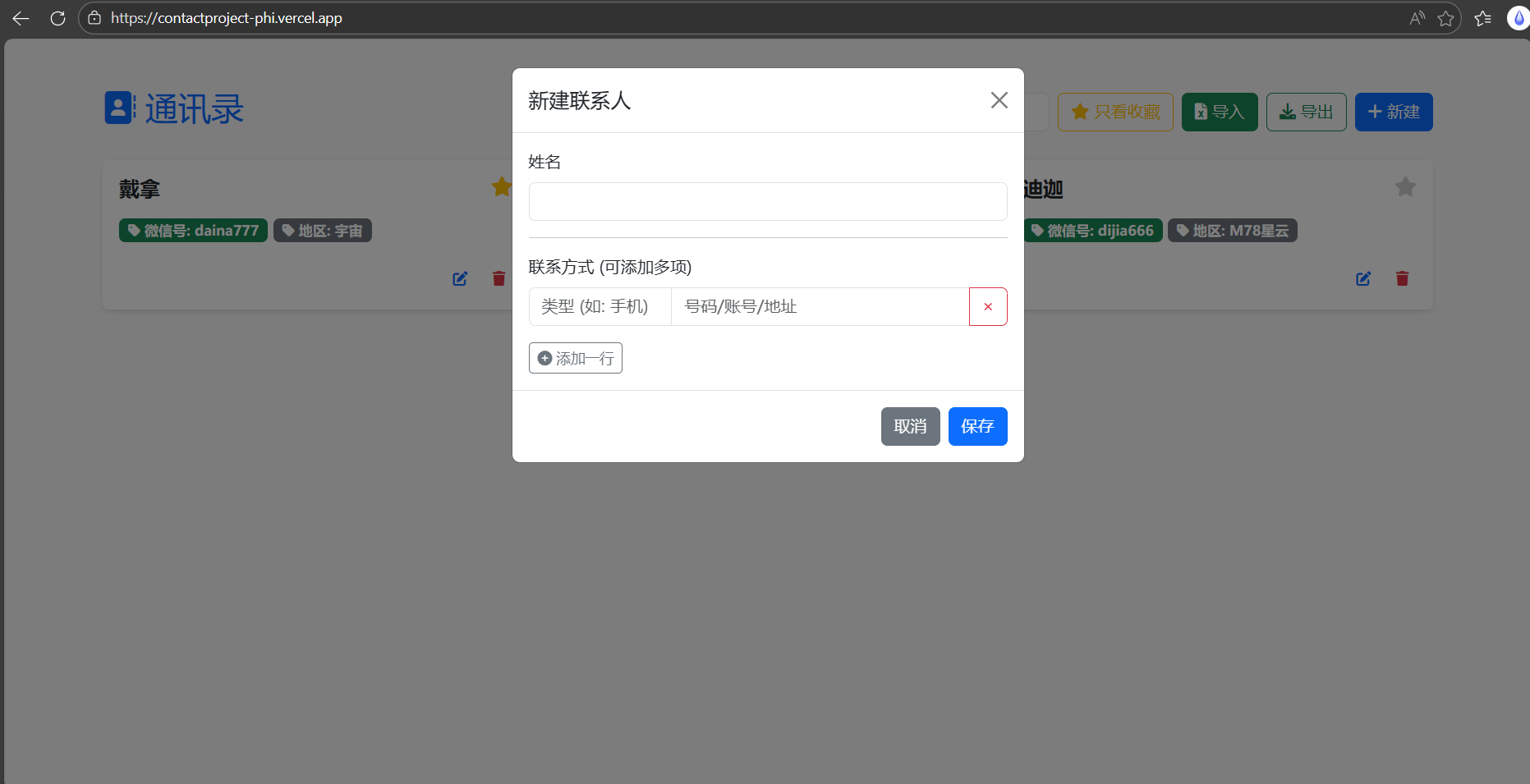
输入联系人姓名,联系方式可添加多项(不仅限于示例中的微信号与地区):
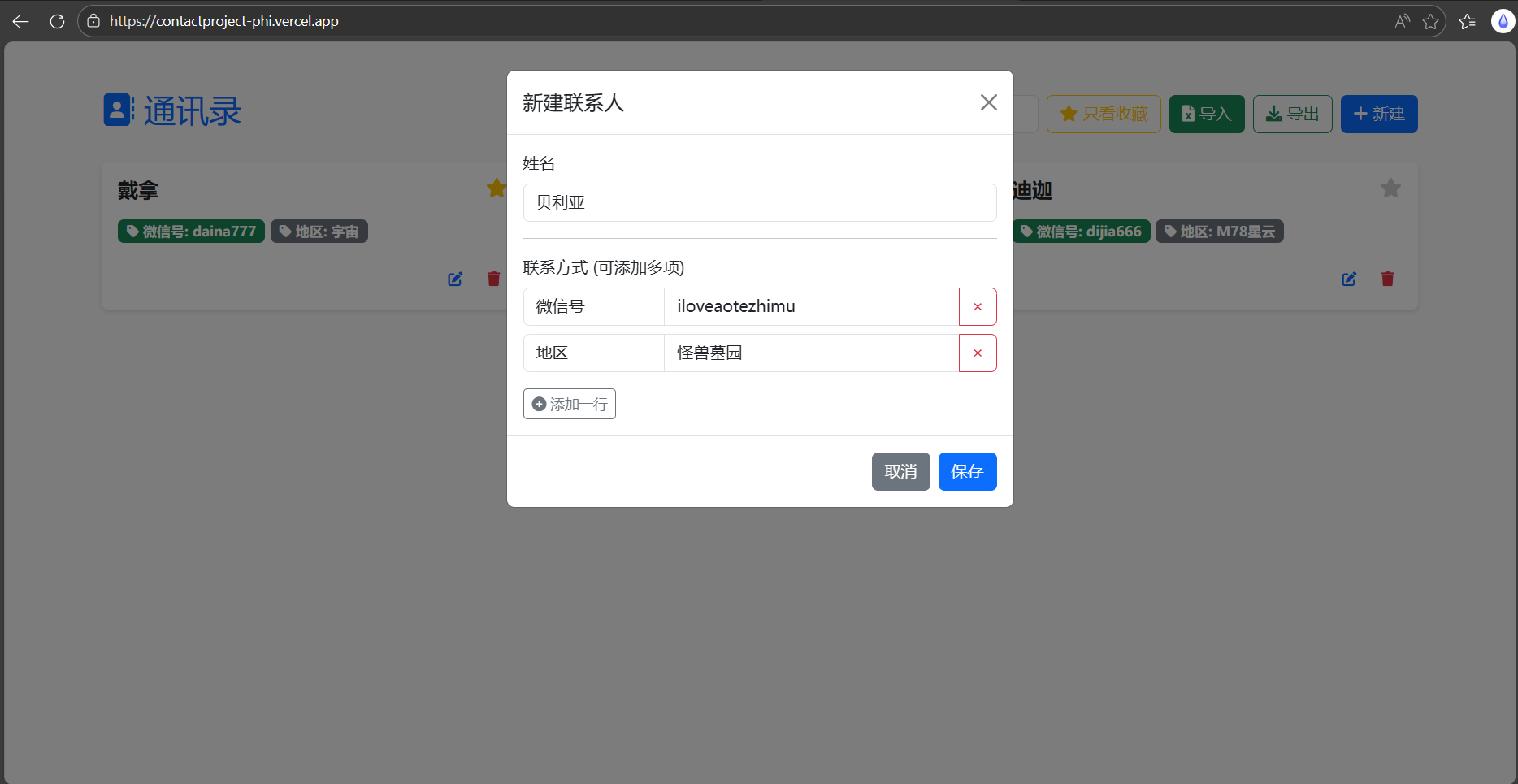
添加完成,可以看到“贝利亚”已经出现在列表中了:
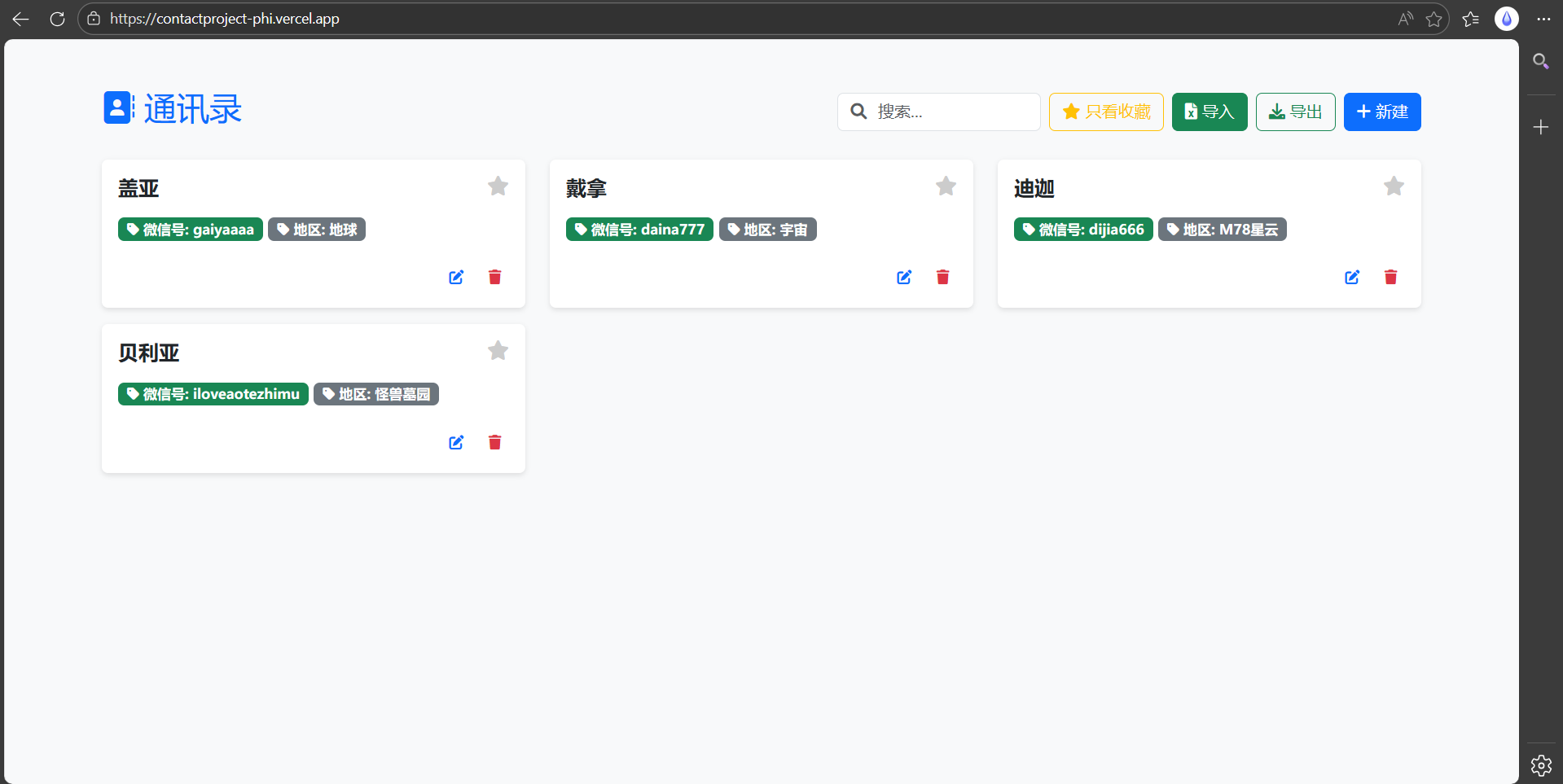
点亮对应联系人右上角的收藏键实现联系人收藏功能,被收藏联系人会自动排序到通讯录前排:
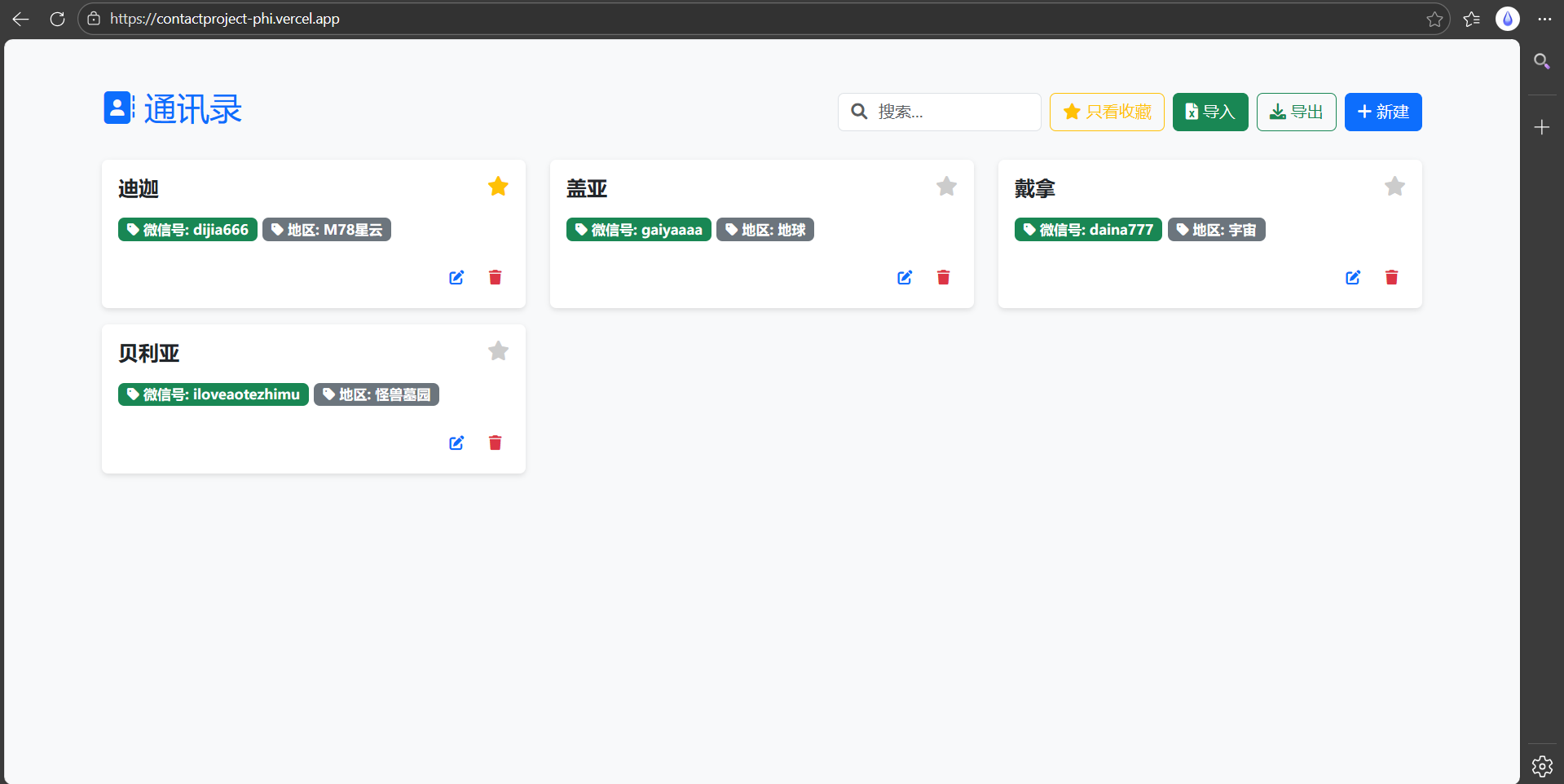
点击右上角“只看收藏”功能可以只显示已收藏的联系人:
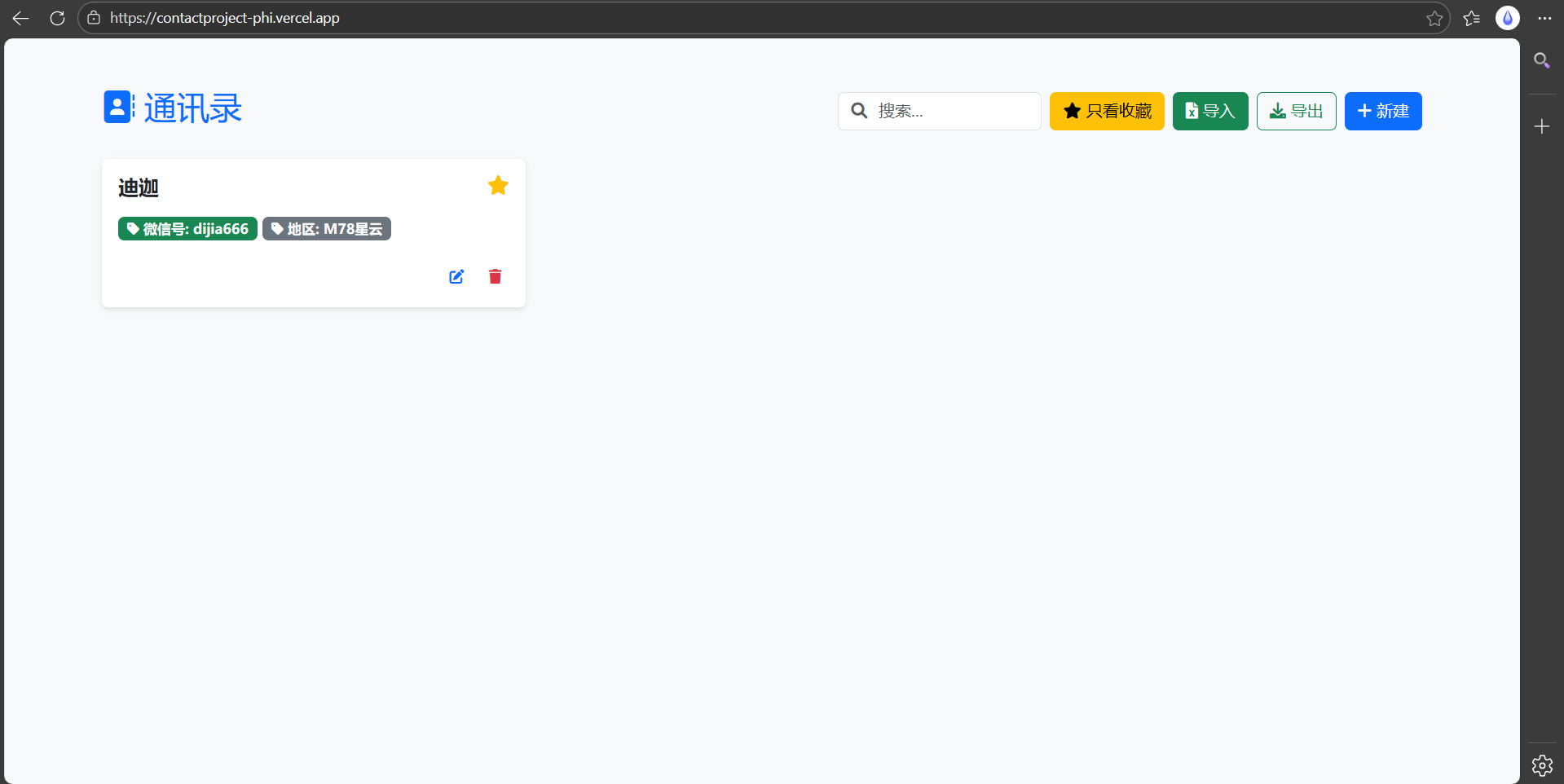
点击右上角“导出”,实现通讯录转换至Excel表格导出:
导出的Excel表格内容展示:
点击对应联系人的“删除”键,程序提醒再次确认,确认后实现联系人的删除功能:
将所有联系人删除后,可以再次导入刚才导出的Excel表格,恢复通讯录数据:
5.团队分工情况:
夏鹏:
初始化数据库
前后端交互
通讯录导出Excel与从Excel导入功能开发
联系人检索功能开发
测试、完善代码
项目服务器云部署
郭祺域:
阅读博客作业要求、设计整体架构
联系人新建、修改、删除功能开发
收藏联系人与只看收藏功能开发
前端界面排版美化与适配
项目演示、撰写报告
6.团队贡献值:
满分: (100)
夏鹏:50% 郭祺域:50%
7.开发中问题及其解决方式:
问题1:
通讯录运行导出 Excel 功能时提示[ModuleNotFoundError: No module named 'openpyxl']的ExcelWriter相关错误。
解决方法:
经过搜索资料,知道pandas 导出 Excel 需要依赖openpyxl引擎,未安装会导致功能失效。安装依赖库(执行pip install openpyxl),并在代码中指定引擎pd.ExcelWriter(output, engine='openpyxl')之后,Excel写入功能可以正常运行。
问题2:
运行代码时,提示RuntimeError: Working outside of application context.,数据库db.create_all()执行失败。
解决方法:
使用with app.app_context():包裹数据库初始化代码。确保Flask-SQLAlchemy操作在Flask应用上下文中进行。
问题3:
使用导出功能时,若数据库中没有联系人数据,执行pd.DataFrame(data_list)会出现空表格或列名缺失问题。
解决方法:
调试过程中发现,当data_list为空时pandas 创建的DataFrame没有预设的列名,导致导出的Excel会缺少 “姓名”“是否收藏” 核心列,添加逻辑判断后问题得到修复。
问题4:
使用导入功能前端上传 Excel 文件后,后端request.files.get('file')始终返回None,无法顺利导入通讯录列表。
解决方式:
原因一是因为前后端交互配置错误--
--设置请求方法为POST,请求头为ContentType:multipart/form-data。
原因二是因为文件名不匹配--
--修改代码使用request.files.get('file')获取文件,使得参数名与前端一致。
8.PSP表格:
| PSP(夏鹏) | 预估时间(min) | 实际时间(min) |
| 数据库搭建 | 20 | 10 |
| 前后端交互 | 45 | 30 |
| Excel导入导出功能 | 60 | 40 |
| 检索功能开发 | 60 | 50 |
| 测试及优化 | 120 | 150 |
| 云部署 | 60 | 100 |
| 总计 | 365 | 410 |
| PSP(郭祺域) | 预估时间(min) | 实际时间(min) |
| 设计整体架构 | 30 | 20 |
| 新建/编辑/删除功能 | 60 | 30 |
| 收藏功能开发 | 60 | 40 |
| 前端界面适配及美化 | 100 | 90 |
| 项目报告撰写 | 120 | 150 |
| 总计 | 370 | 330 |
9.心得体会&项目总结:
完成本次通讯录管理系统后端开发作业后,我们的技术应用与问题解决能力都有了提升。通过实践,我们熟练掌握了 Flask 框架的路由设计、SQLAlchemy ORM 的数据库操作以及 pandas 库实现 Excel 导入导出的核心用法。开发过程中,我们遇到了不少实际问题,比如数据库初始化时的应用上下文缺失、JSON 格式解析异常以及 Excel 功能依赖库缺失等。通过查阅官方文档、请教ai、添加异常捕获机制逐一解决了这些问题。软件开发不仅要实现核心功能,更要兼顾边界场景处理、跨环境适配等细节,才能保证系统的稳定性和可用性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)