用通俗简单的语言说最新发布的deepseek V3.2大模型的底层技术和原理
用通俗简单的语言说最新发布的deepseek V3.2大模型的底层技术和原理
我会用盖房子、开公司这些比喻,尽量通俗地解释DeepSeek-V3.2的底层原理和新技术。
你可以把它理解成一个公司推出了一款新一代的“全能员工”。这个员工不仅知识更渊博(海量数据训练),关键是他的工作方法彻底升级了,变得更高效、更擅长处理复杂任务。
下面我们用一张总览图来理解它的核心架构和工作流程:
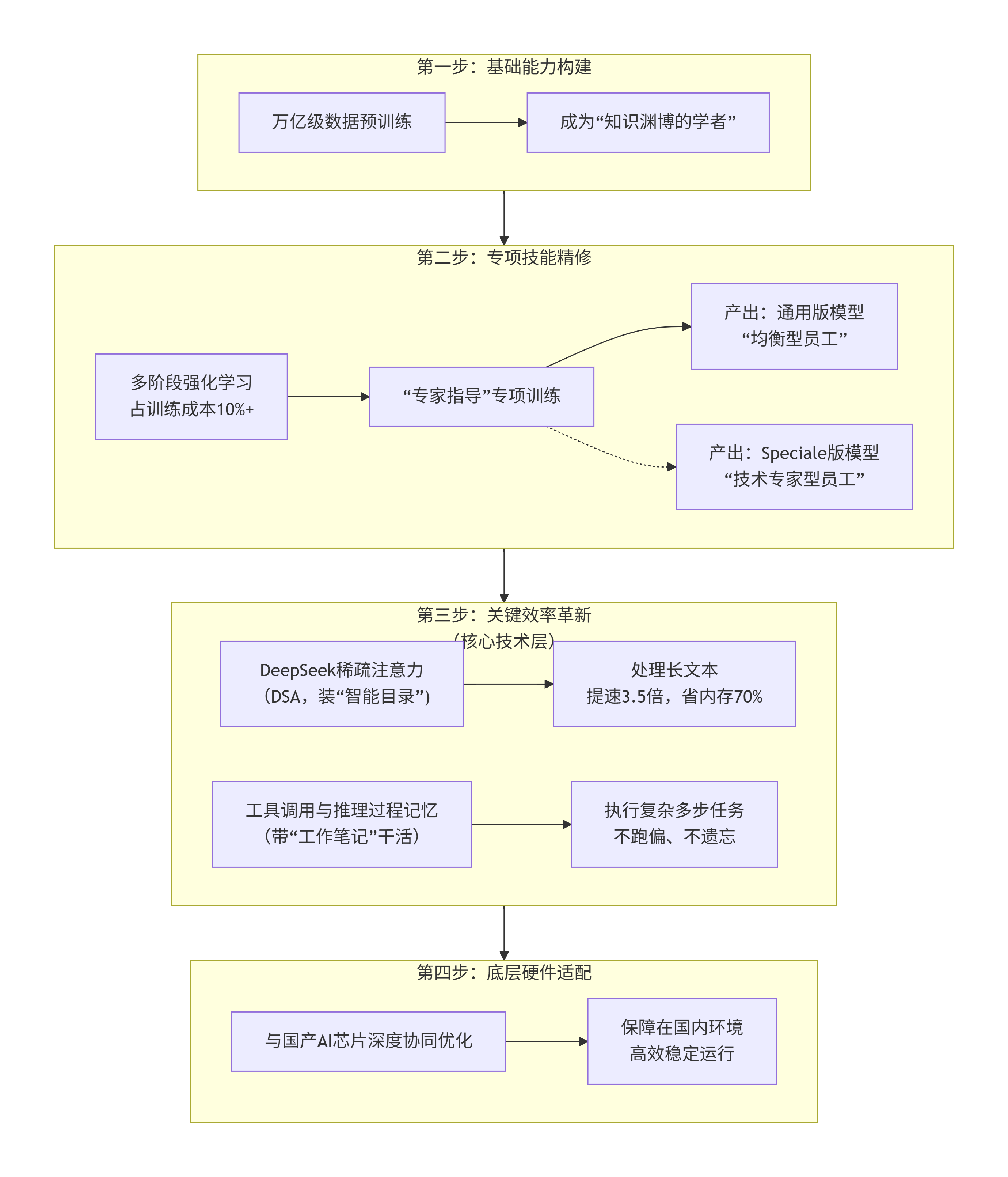
下面,我们来详细拆解图中第三步的两个最核心的新技术。
🧠 新技术一:DeepSeek稀疏注意力 (DSA)
-
通俗比喻:给大脑装一个“智能目录”
-
以前的“笨”办法:想象一下,让你读一本1000页的书,每次看到新一页,为了理解上下文,你都需要从头到尾快速翻阅前面所有999页。这非常累,而且大部分翻阅是无效的。
-
现在的“巧”办法:V3.2给这本“书”建立了智能目录和索引。当它读到第1000页时,这个“智能目录”会瞬间告诉它:“这一页的内容,主要和第5页、第230页、第780页这几处关键地方强相关。”于是,它只需要精读这几页,就能完美理解上下文,完全不用去管其他不相关的页面。
-
-
详细解释:
-
这个“智能目录”技术,学术上称为 “稀疏注意力” 。传统大模型在处理文本时,每一个字(token)都需要关注之前的所有字,计算量随文本长度呈平方级增长(即长度翻倍,计算量变四倍)。这是处理长文本(如整本书、长代码文件)时又慢又贵的主要原因。
-
DeepSeek的DSA技术,通过精密的算法设计,能智能地筛选出最需要关注的一小部分关键信息,让计算量从平方级增长降到接近线性增长。这就是为什么它能实现处理长文本时推理速度提升3.5倍,内存占用减少70% 的惊人效果。这项技术是它高效处理海量信息的基石。
-
🔧 新技术二:工具调用与推理过程记忆
-
通俗比喻:带着“工作笔记”和“工具箱”去干活
-
以前的尴尬情况:假设这个AI员工接到任务:“为我70岁的父母规划一次北京5日游”。它开始思考:“老人出行,要少走路、住宿要方便...”。然后它去“查地图”(调用工具),查完回来却忘了核心前提是‘老人出行’,可能就开始推荐登山路线了。
-
现在的聪明做法:V3.2在思考时,会把核心目标(“为老人规划”)和每一步的推理结果写在 “工作笔记” 上。无论它中途去“查地图”、“查天气”还是“订酒店”,只要看一眼笔记,就能立刻回到主线上。并且,它会熟练使用“工具箱”里的各种工具(搜索、计算器、代码解释器),并把工具返回的结果也记在笔记里,作为下一步推理的依据。
-
-
详细解释:
-
这项技术让V3.2从一个单纯的“文本生成器”,进化成了一个真正的 “智能体”。
-
推理过程记忆:模型在思考多步骤任务时,会生成并维护一个内部的“思维链”状态。这个状态在调用工具时不会被重置或覆盖,从而保证了任务执行的连贯性和一致性。
-
工具调用集成:模型被深度训练,知道在什么情况下该调用什么工具(比如遇到数学问题就用计算器,需要实时信息就用搜索),并理解工具的返回结果。这使得它能完成写代码、分析数据、联网查询等复杂、开放的任务。
-
这项技术是它能够成为强大AI智能体的关键,使其能像人类助手一样,有条不紊地执行复杂指令。
-
🚀 其他重要的技术支撑
除了以上两大革新,V3.2的成功还依赖于坚实的“地基”:
-
海量而高质量的数据训练:它使用了万亿级的高质量代码和文本数据进行预训练,这是其广博知识的来源。
-
强化学习的专项特训:在基础训练后,它花费了超过总训练成本10% 的资源进行“专项特训”。特别的是,它采用了 “专家蒸馏” 策略:先训练出多个在数学、编程、逻辑等方面各有所长的“专家模型”,然后用这些专家的“解题思路”去指导最终模型的训练,使其各项能力更均衡、更突出。
-
与国产硬件的深度协同:模型设计之初就考虑了与国产AI芯片(如寒武纪、昇腾)的适配,通过软硬件协同优化,确保在国产算力平台上也能高效运行,这是非常关键的工程实践。
✨ 两个版本的不同定位
最后,DeepSeek-V3.2有两个版本,你可以根据需求选择:
-
V3.2 (通用版):像一位能力均衡的全科优等生,适用于大多数日常对话、写作、分析任务,综合能力强。
-
V3.2 Speciale (强化版):更像一位数理逻辑和编程领域的顶尖专家,专门针对复杂数学推理、代码生成、学术研究等需要深度思考的任务进行了极致优化。
希望这个解释能帮助你理解DeepSeek-V3.2的强大之处。它不仅仅是通过“读更多书”变得更聪明,更重要的是通过革命性的工作方法,变得更高效、更可靠、更擅长解决实际问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)