ChatBI:Agentar-Scale-SQL 通过编排式测试时扩展推进 Text-to-SQL
当前最先进(SOTA)的 Text-to-SQL 方法在 BIRD 等高难度基准上仍显著落后于人工专家。现有探索测试时扩展(test-time scaling)的方法缺乏统一的编排策略,也忽视了模型的内部推理过程。为弥合这一差距,我们提出 Agentar-Scale-SQL,一种利用可扩展计算能力提升表现的新框架。Agentar-Scale-SQL 实现了一种 编排式测试时扩展策略(Orchest
【原文】Agentar-Scale-SQL: Advancing Text-to-SQL through Orchestrated Test-Time Scaling
【摘要】当前最先进(SOTA)的 Text-to-SQL 方法在 BIRD 等高难度基准上仍显著落后于人工专家。现有探索测试时扩展(test-time scaling)的方法缺乏统一的编排策略,也忽视了模型的内部推理过程。为弥合这一差距,我们提出 Agentar-Scale-SQL,一种利用可扩展计算能力提升表现的新框架。Agentar-Scale-SQL 实现了一种 编排式测试时扩展策略(Orchestrated Test-Time Scaling),将三种不同视角有效协同:
内部扩展(Internal Scaling):通过基于强化学习优化的内部推理(RL-enhanced Intrinsic Reasoning)提升模型思考能力。
顺序扩展(Sequential Scaling):通过迭代式改写(Iterative Refinement)逐步增强 SQL 质量。
并行扩展(Parallel Scaling):利用多样化生成与锦标赛式选择(Diverse Synthesis + Tournament Selection)筛选最优答案。
1,引言
通过使用户能够用自然语言查询结构化数据库,从而民主化数据分析的访问,是人机交互领域长期以来的目标。这正是 Text-to-SQL 的核心任务——一个致力于将自然语言问题转换为可执行 SQL 查询的重要研究方向(Zhang et al., 2024; Li et al., 2024a; Liu et al., 2024; Luo et al., 2025)。Text-to-SQL 通过弥合人类语言与结构化数据之间的鸿沟,使非技术用户也能高效地与复杂数据库交互,因此受到自然语言处理(NLP)和数据库研究社区的广泛关注(Li et al., 2023; Yu et al., 2018; Pourreza et al., 2025a; Zhang et al., 2025b)。
Text-to-SQL 的最终愿景是构建能够匹敌甚至超越人类专家表现的系统。然而,这一目标与当前技术水平之间仍存在显著差距。在具有挑战性的 BIRD 基准(Li et al., 2023)上,人类专家可以达到 92.96% 的执行准确率(EX),而最先进的方法仍显著落后,前五名方法在测试集上大约只有 75%。要缩小这一巨大的性能差距,亟需创新突破。
当前 Text-to-SQL 研究大致分为三类:
Prompt 方法(如 OpenSearch-SQL (Xie et al., 2025)、DAIL-SQL (Gao et al., 2024))。
微调(fine-tuning)方法,代表性工作如 Arctic-Text2SQL-R1-32B (Yao et al., 2025)。
混合方法,包括 XiYan-SQL (Liu et al., 2025c)、CHASE-SQL + Gemini (Pourreza et al., 2025a)、Contextual-SQL (Agrawal & Nguyen, 2025)。
这些方法主要从不同角度探索 测试时扩展(test-time scaling):
Contextual-SQL 使用集成策略;
XiYan-SQL 和 CHASE-SQL 探索集成与顺序改写。
然而,这些研究存在共同局限:它们忽视了模型推理过程的内部维度,并缺乏将多种扩展策略进行编排式结合的整体设计。
为进一步提升 Text-to-SQL 的性能,本研究认为最具前景的方向在于充分践行 “The Bitter Lesson”(Sutton, 2019) 的原则:依托可扩展计算的一般方法最终会优于那些依赖复杂、人工指定知识的方法。基于这一理念,我们专注于 测试时扩展(test-time scaling),并未设计繁杂的 schema linking 策略,因为我们认为仅依靠扩展本身就足以带来性能提升。
为此,我们提出 Agentar-Scale-SQL,一种 编排式测试时扩展框架(Orchestrated Test-Time Scaling)。该框架表明,通往接近人类水平性能的道路不在于构建更复杂的启发式方法,而在于开发能够有效利用测试时扩展的一般性框架(Snell et al., 2024; Zhang et al., 2025a)。
Agentar-Scale-SQL 从三个独立视角实施编排式扩展策略:
内部扩展(Internal Scaling):通过强化学习增强的内部推理(RL-enhanced Intrinsic Reasoning)。
顺序扩展(Sequential Scaling):通过迭代式改写(Iterative Refinement)。
并行扩展(Parallel Scaling):通过多样化生成(Diverse Synthesis)与锦标赛式选择(Tournament Selection)。
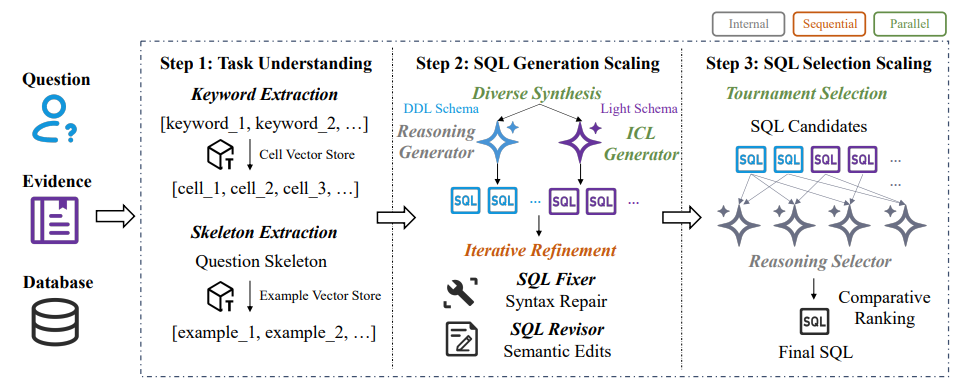
该策略在一个三阶段框架中实现,如图 1 所示:
步骤 1:任务理解(Task Understanding):建立对输入及其上下文的全面理解,这是后续扩展操作的基础。
步骤 2:SQL 生成扩展(SQL Generation Scaling):应用多样化生成与迭代改写,获得高质量且多样的 SQL 候选。其中,多样化生成依赖两个不同生成器(内部推理生成器和 ICL 生成器),并使用与各生成器对应的 schema 格式。
步骤 3:SQL 选择扩展(SQL Selection Scaling):通过锦标赛选择并微调内部推理选择器,确保最终结果的高准确性。
我们的主要贡献总结如下:
- 编排式测试时扩展(Orchestrated Test-time Scaling):我们提出一个编排式测试时扩展框架,通过在三个不同维度上进行扩展,将额外的推理计算直接转化为准确率提升:
- 内部扩展(基于强化学习增强的内部推理),
- 顺序扩展(迭代式改写),
- 并行扩展(多样化生成与锦标赛式选择)。
- 通用性与可扩展性(General Purpose and Scalability):整个框架完全通用、即插即用,并可轻松适配任何数据库。未来随着大型语言模型能力增强、计算成本进一步下降,Agentar-Scale-SQL 的性能上限将自动提高;我们只需在生成与选择阶段投入更多计算资源即可获得更高的准确率。
- 透明且可执行的洞察(Transparent and Actionable Insights):我们提出一个结构化的三阶段 Text-to-SQL 框架,明确区分每一阶段的具体角色与目标。关键在于,本研究首次同时对 SQL 生成阶段 和 SQL 选择阶段 进行扩展。上述贡献共同为未来 Text-to-SQL 研究提供了透明、清晰、可执行的指导路径。
2,相关工作
Text-to-SQL。 尽管大语言模型(LLMs)显著推动了 Text-to-SQL 的进展,但在处理复杂查询时仍面临挑战(Liu et al., 2024, 2025b)。近期研究通过提示(prompt)方法(Xie et al., 2025;Gao et al., 2024;Dong et al., 2023)、微调方法(Yao et al., 2025;Pourreza et al., 2025b;Li et al., 2025b, 2024b;Yang et al., 2024),或结合测试时扩展的混合策略(Liu et al., 2025c;Pourreza et al., 2025a;Agrawal and Nguyen, 2025)来解决这一问题。
与本文最相关的是这些扩展方法,它们通过并行生成与顺序改写等技术提升 SQL 生成质量。然而,这些方法存在一个共同局限:缺乏对不同扩展维度的 编排式组合。
测试时扩展(Test-time Scaling)。 测试时扩展通过策略性地增加推理阶段的计算量来提升 LLM 的性能,而无需修改模型权重(Zhang et al., 2025a;Snell et al., 2024;Kaplan et al., 2020)。
现有 TTS 研究可大致分为三类范式:
并行扩展(Parallel Scaling)
同时生成多个候选答案并聚合,以提高找到正确答案的概率。典型代表是自一致性(Self-consistency)(Wang et al., 2023)。
顺序扩展(Sequential Scaling)
模拟类似“系统2”的推理过程,通过逐步构建或不断改写来提升答案质量,典型方法包括 CoT(Chain-of-Thought)(Wei et al., 2022)和迭代改写(Madaan et al., 2023)。
内部扩展(Internal Scaling)
使模型能够自主分配自身的计算预算,并在无需外部 orchestrator 的情况下自行决定推理深度(DeepSeek-AI et al., 2025;Jaech et al., 2024)。
我们的工作 Agentar-Scale-SQL 基于上述基础概念,提出一个新的 编排式框架,将三种扩展范式协同融合,并专门针对 Text-to-SQL 领域推进 SOTA 性能。
3,方法论
3.1,总述
给定用户问题
、证据
(辅助信息,比如表结构等)和目标数据库
,我们的框架分为三个阶段,如图 1 所示。在在线框架运行之前,还包含一个离线预处理阶段。
【离线预处理】我们的方法在在线推理前包含三个离线预处理步骤。
第一,为了提升生成的多样性,我们将数据库的元数据构造成两种格式(见图 2)。我们创建了一种基于 Markdown 的轻量级 schema,用于与通用大模型进行高效的 In-Context Learning(ICL);同时使用标准的 DDL schema 来微调代码类专长模型,使其能够利用自身的训练特性实现更快的收敛。
第二,我们将数据库中所有文本类型的单元格内容索引到一个向量库
最后,我们也将训练集作为示例索引到向量库
中,以便在推理阶段,对经过 skeleton 抽取(把用户问题中的具体实体、数值、专有名词等可变内容去掉,只保留问题的结构化语义框架)的用户问题进行嵌入后开展相似度检索,从而获取相关的 few-shot 示例。
原问题: “列出 2023 年销售额大于 5000 的苹果手机。” skeleton: “列出 X 年销售额大于 Y 的 Z 类产品。”

【在线框架】Agentar-Scale-SQL 是一种编排式的测试时扩展框架(test-time scaling framework),通过跨三个不同维度的扩展策略,将额外的推理计算量转化为精度提升:
- 内部扩展(Internal Scaling,通过强化学习增强的内在推理)、
- 序列扩展(Sequential Scaling,通过迭代式改进)、
- 并行扩展(Parallel Scaling,通过多样化生成与锦标赛式选择)。
步骤 1(任务理解):目标是充分理解用户意图,并检索相关上下文信息。
步骤 2(SQL 生成扩展):通过多样化生成(diverse synthesis)和迭代式改进(iterative refinement)来获得高质量且多样化的 SQL 候选。其中,多样化生成特别依赖两个基于不同 schema 格式的独立生成器:
使用 DDL schema 的“推理型生成器”(reasoning generator)
使用 light schema 的“ICL 型生成器”(ICL generator)
步骤 3(SQL 选择扩展):采用锦标赛式选择方法(tournament selection),并结合内在推理选择器(intrinsic reasoning selector),以获得更高的选择准确率。
3.2,任务理解
数据库单元格至关重要(Pourreza 等,2025a;Liu 等,2025c),因为它们为 WHERE、HAVING 等 SQL 子句提供所需的具体取值。同样,精心挑选的 few-shot 示例已被证明能够显著提升 In-Context Learning(ICL)的效果(Gao 等,2024)。因此,Task Understanding 步骤的主要目标是识别并检索这两类关键上下文:相关的数据库单元格和有效的示例演示。这一过程通过两个并行的子流程完成:
- 关键词抽取:从问题
中检索相关单元格;
- 骨架抽取:从问题
3.3,SQL 生成扩展
本阶段使用两个互补的 SQL 生成器,并基于双视角 schema 来生成高质量且多样化的候选 SQL。第一个生成器
是一个通过强化学习(RL)训练的内在推理模型;第二个生成器
是一个由大型商用 LLM 驱动的 In-Context Learning(ICL)模型。随后,引入一个针对语法修复和语义修改的迭代式优化循环。最终,将生成一组包含
个 SQL 候选的集合:
【内在推理式SQL生成器】受 Arctic-Text2SQL-R1(Yao 等,2025)的启发,我们使用一个简单且基于执行反馈的强化学习(RL)框架,实现稳健的内在推理式 Text-to-SQL 生成。RL 流程概述:我们采用 GRPO(Shao 等,2024),因为其在结构化推理任务中已证明高效且有效。与 Arctic-Text2SQL-R1 不同,我们仅使用 BIRD 数据集中的训练数据,不引入任何额外数据。
形式化地,设
表示参数为
的策略模型。对于任意给定输入问题
。随后,每条候选都会被评估以获得明确的奖励信号(后文说明)。通过针对每个输入生成的一批 rollouts(模型在当前策略下生成的一条完整 SQL 查询。),我们可以计算相对优势,从而稳定训练并促进策略更新的鲁棒性。每个样本
的剪裁代理目标(clipped surrogate objective)定义为:
GRPO的整体目标是:
其中
表示似然比
,
为优势(advantage),
为 KL 散度惩罚项,用于将策略限制在接近参考模型(经监督微调模型)的范围内(Ouyang 等,2022)。参数
与
在实践中用于平衡探索与训练稳定性。
奖励设计:我们依据 Arctic-Text2SQL-R1,仅基于最终执行正确性和基本语法有效性来定义奖励函数 RGR_GRG:
【多样化合成】多样化合成策略旨在生成一个高质量且多样化的 SQL 候选池。该策略包含两个平行且互补的生成器:一个经过微调的推理生成器,以及一个 ICL 生成器。我们为 ICL 设计了基于 Markdown 的轻量级 schema,以便通用 LLM 更易处理;同时使用标准的 DDL schema 来微调代码型模型,使其能够利用自身训练优势实现更快的收敛。
- 推理生成器:该生成器使用 DDL schema,执行深度、逐步的推理。一方面,基于内部扩展(Internal Scaling)原则,它被设计用于构建复杂 SQL,以高准确率为主要目标;另一方面,它可以通过微调来适配目标基准任务的特定需求和特征。
- ICL 生成器:ICL 生成器并行运行,使用基于 Markdown 的轻量 schema(见图 2)以及 Task Understanding 阶段检索到的 few-shot 示例。为提升生成多样性,我们采用多策略组合:变化输入 prompt、随机化示例顺序、使用多种 LLM、调整温度等。
通常,我们将不同提示风格分为三类:
直接提示(无显式推理)
链式思维(CoT)提示(Wei 等,2022)
问题分解式提示
该生成器通过利用示例中的模式,能够快速生成一系列可行的 SQL 查询。结合推理生成器的深度分析能力与 ICL 生成器的示例驱动模式,可以最大化候选 SQL 的多样性。这种协同显著提高了候选池中至少存在一条正确或接近正确 SQL 的概率,从而提升后续选择阶段的效果。
【迭代式优化】为进一步提升 SQL 候选的质量,我们引入迭代式优化模块来修复错误。SQL 查询通常可能包含语法错误与语义错误(Yang 等,2025;Xu 等,2025)。我们采用双路径的方法分别处理两类问题。
- 语法错误:对于语法错误,我们使用 SQL fixer,这是一个基于 LLM 的组件,按需激活,用于修补无效的语法结构。
- 语义错误:对于语义错误,我们使用 SQL revisor,这是一个专门设计用于发现和修正查询逻辑缺陷的 LLM 代理。
为提高优化效率,我们首先按 SQL 的执行结果对候选进行分组,然后从每组中随机选择一个查询进行优化处理。
3.4,SQL选择扩展
多数投票方式的主要局限在于其隐含假设:出现频率最高的答案即为正确答案。然而,这一前提并不总是成立。为此,我们采用锦标赛式选择过程,由一个经过强化学习(RL)增强的推理选择器对候选 SQL 进行成对比较评估。最终排名最高的 SQL 查询将被选为最终结果。
【锦标赛式选择】我们通过两阶段流程选出最优 SQL 查询。
- 第一阶段:候选池压缩:先根据在数据库
。
- 第二阶段:两两对决的循环锦标赛:候选集合中的每个 SQL 都会与其他候选进行成对比拼。对于每一对
推理选择器
将根据问题、轻量 schema 和执行结果判定胜者,并为胜者的得分
加 1。最终得分最高者即为最终 SQL:
【内在推理式SQL选择器】我们对 SQL 选择器
RL 流程概述:遵循 3.3.1 节的方法,我们对选择任务使用 GRPO,以增强模型在 SQL 选择环节中的推理能力。基于训练集,我们构建了 8.5k 条用于强化学习的样本。
奖励设计:SQL 选择的目标是从候选集中识别出正确的查询。为此,我们提出了一个结果导向的奖励函数 RS,用于评估选择是否正确:
4,结论
我们提出了 Agentar-Scale-SQL,一个通过协同利用内部扩展、序列扩展和并行扩展策略来显著提升 Text-to-SQL 性能的全新框架。该方法在具有挑战性的 BIRD 基准上取得了 SOTA(最优)成绩,展示了迈向类人级准确率的一条有效路径。我们已开源代码和模型,以支持该领域的未来研究。
在成功利用 测试时扩展(Test-Time Scaling) 提升智能之后,我们正在开拓下一项工作:训练时扩展(Exercise-Time Scaling)。我们将赋能新一代智能体,让其能够通过行动学习,并从经验中持续进化。
尽管 Agentar-Scale-SQL 在性能上具有显著优势,其依赖多阶段、协同式的推理与生成带来了若干限制。
其主要缺点在于:由于在生成、优化与选择环节均需要多次调用 LLM,整体计算开销较大、延迟较高,因此不适合实时应用场景。
在我们的商业实践(B2B ChatBI 产品开发)中观察到,企业用户最重视的是准确性。在决策场景中,出现幻觉式 SQL 是不可接受的;相比之下,为生成复杂分析而等待数秒的延迟通常可以接受。Agentar-Scale-SQL 的设计目标正是为这些生产需求补齐“最后一公里”的准确性。
此外,其性能仍受底层基础模型能力的根本限制,并可能遭受级联式误差影响:例如如果任务理解阶段失败,后续整个流程都可能受到影响。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)