在Ubuntu系统上部署GPUStack从节点加入集群教程【亲测成功】
在同一集群内整合 NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程 等异构 GPU/NPU,兼容 Linux、Windows、macOS,把分散设备汇聚为可共享的算力池,提升资源利用率并降低 TCO。提供 OpenAI 兼容 API、RBAC 认证与访问控制、配额/计量、全链路可观测,支持从 Hugging Face 快速部署开源模型,业务侧几乎零改造接入。平台侧进行最佳
0.引言
GPU集群部署的重要意义在以下三点:
(1)异构算力统一纳管与共享
在同一集群内整合 NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程 等异构 GPU/NPU,兼容 Linux、Windows、macOS,把分散设备汇聚为可共享的算力池,提升资源利用率并降低 TCO。
(2)企业级 LLMaaS 能力
提供 OpenAI 兼容 API、RBAC 认证与访问控制、配额/计量、全链路可观测,支持从 Hugging Face 快速部署开源模型,业务侧几乎零改造接入。
(3)面向生产的性能与弹性
平台侧进行最佳引擎选择与配置调优,并集成 vLLM、SGLang、MindIE 等推理引擎;支持多机分布式推理,可承载 Qwen3-235B-A22B、DeepSeek R1/V3 等超大模型;结合 AWS/阿里云/DigitalOcean 实现弹性扩缩容,兼顾吞吐、延迟与成本
——————————————————————
为了满足业务需求,选择部署GPUStack集群,也是利用docker工具,因此有了本教程。
部署GPUStack集群的原理如下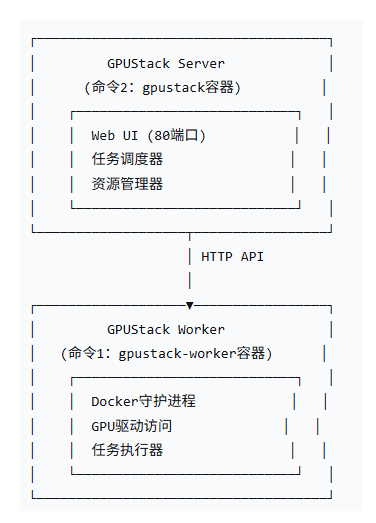
1.部署GPUStack
具体的部署过程和注意事项,不会的可以参考博文在Ubuntu系统上使用docker部署GPUStack教程
BTW,需要注意的是部署完成之后,也就是成功执行到2.2.2安装NVIDIA Container Toolkit 即可!
2.作为从节点启动(十分重要)
————————————————————————————
这里非常重要,主节点和从节点的启动方式不一样
| 节点角色 | 典型 Docker 运行命令(关键参数部分) | 核心差异 |
|---|---|---|
| 主节点 (Server) | docker run ... gpustack/gpustack |
命令中不带 --server-url 参数,容器将默认启动为管理服务器。 |
| 从节点 (Worker) | docker run ... gpustack/gpustack --server-url http://主节点IP --token xxx |
命令中必须包含 --server-url 和 --token 参数,容器会以工作节点模式启动并向主节点注册。 |
2.1设置主机名称
查看主机名称
hostname
设置主机名称
sudo hostnamectl set-hostname [Gpustack_BackUp6]
————————————————————
注意:[ ]里面的内容可以根据自己实际情况替换。
由于集群部署,是在一个GPUStack页面管理众多节点,所以一定要注意各个节点的名称以方便管理。
————————————————————
成功如下图所示
2.2在主节点上面添加从节点
2.2.1登录主节点上面的GPUStack
2.2.2点击“节点”选项
2.2.3选择“添加节点”

2.2.4按序操作如下步骤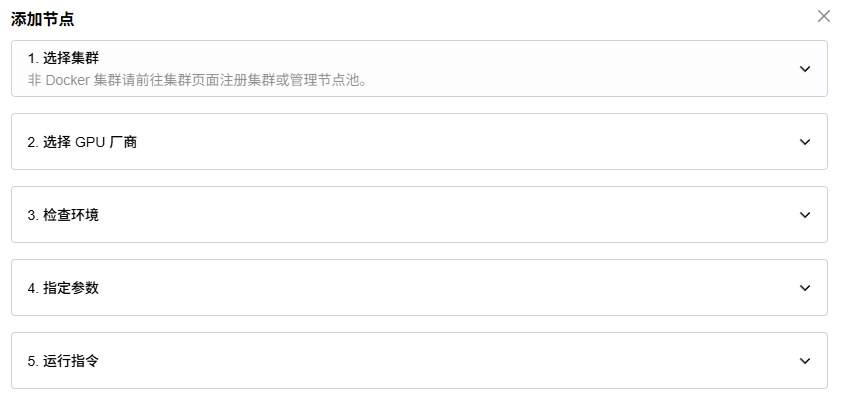
(1)根据自己实际情况选择所在的集群和GPU厂商
(2)检查环境
将给出的命令复制到ubuntu系统上进行检查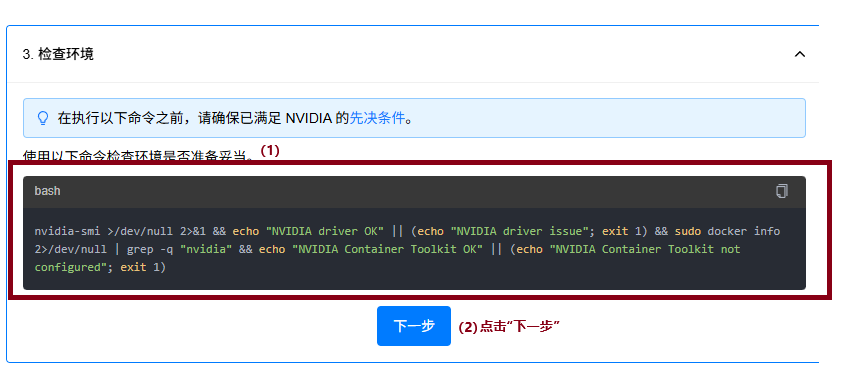
nvidia-smi >/dev/null 2>&1 && echo "NVIDIA driver OK" || (echo "NVIDIA driver issue"; exit 1) && sudo docker info 2>/dev/null | grep -q "nvidia" && echo "NVIDIA Container Toolkit OK" || (echo "NVIDIA Container Toolkit not configured"; exit 1)
————————————————————————
如果检查环境命令运行之后,报错如下:
NVIDIA Container Toolkit not configured

解决办法:
(1)编辑文件/etc/docker/daemon.json
sudo vi /etc/docker/daemon.json
将以下内容复制进去,注意格式,特别是{ }的使用
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
},
"exec-opts": ["native.cgroupdriver=cgroupfs"]
}
内容解释
| 配置项 | 说明 |
|---|---|
| runtimes.nvidia | 定义了 NVIDIA GPU 支持的运行时,使用 nvidia-container-runtime |
| exec-opts | 设置 Docker 使用 cgroupfs 作为 cgroup 驱动 |
| args | 可选参数,用于传递给运行时 |
| path | 指定运行时的可执行文件路径 |
复制进去之后,完整的/etc/docker/daemon.json文件内容如下
{
"registry-mirrors": [
"https://docker.1panel.live",
"https://docker.1ms.run",
"https://dytt.online",
"https://docker-0.unsee.tech",
"https://lispy.org",
"https://docker.xiaogenban1993.com",
"https://666860.xyz",
"https://hub.rat.dev",
"https://docker.m.daocloud.io",
"https://demo.52013120.xyz",
"https://proxy.vvvv.ee",
"https://registry.cyou"
],
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
},
"exec-opts": ["native.cgroupdriver=cgroupfs"]
}
截图如下,一定要注意格式,你可以选择将完整的/etc/docker/daemon.json文件内容重新粘贴一遍。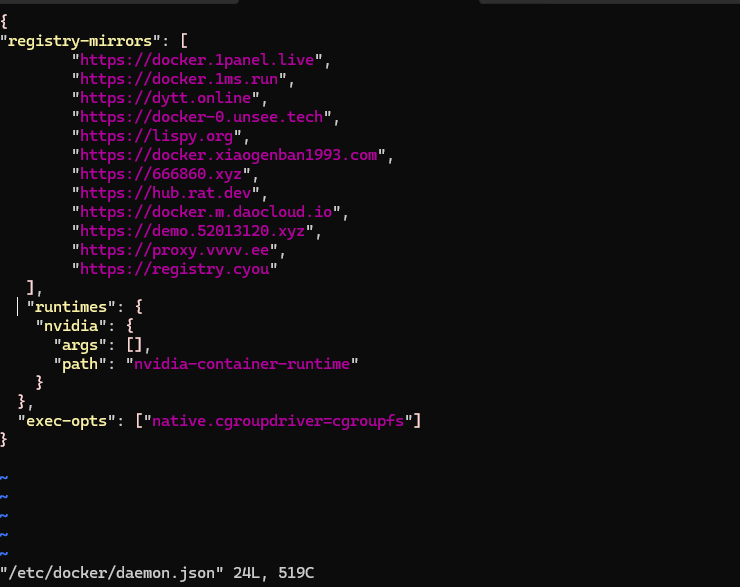
重启docker服务以及重新加载配置
sudo systemctl daemon-reload
sudo systemctl restart docker
sudo systemctl status docker
如下图所示,docker再次成功启动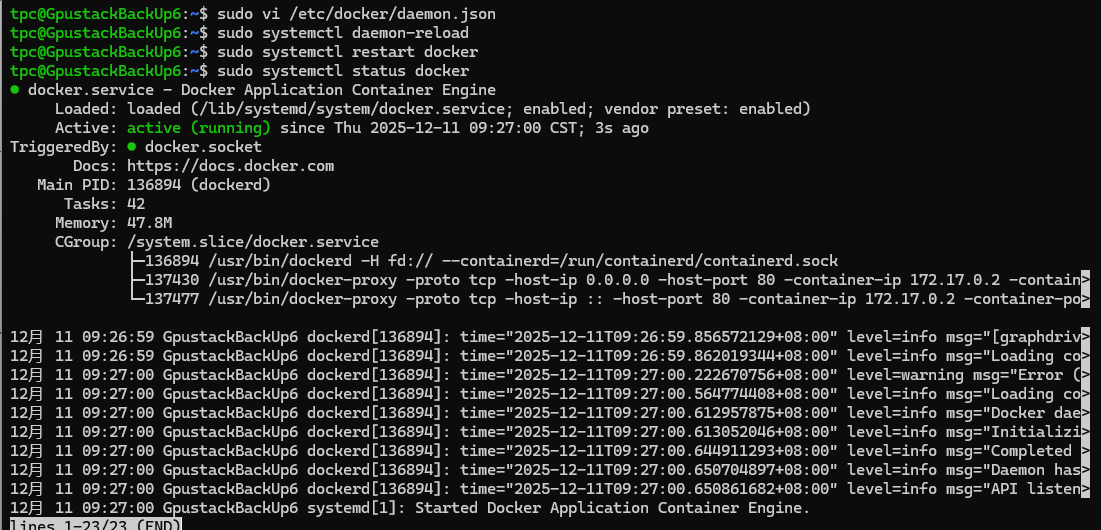
再次检查环境
nvidia-smi >/dev/null 2>&1 && echo "NVIDIA driver OK" || (echo "NVIDIA driver issue"; exit 1) && sudo docker info 2>/dev/null | grep -q "nvidia" && echo "NVIDIA Container Toolkit OK" || (echo "NVIDIA Container Toolkit not configured"; exit 1)
截图如下即为成功
———————————————————
(3)指定参数,填写从节点IP
也就是填写刚刚部署GPUStack这台服务器的IP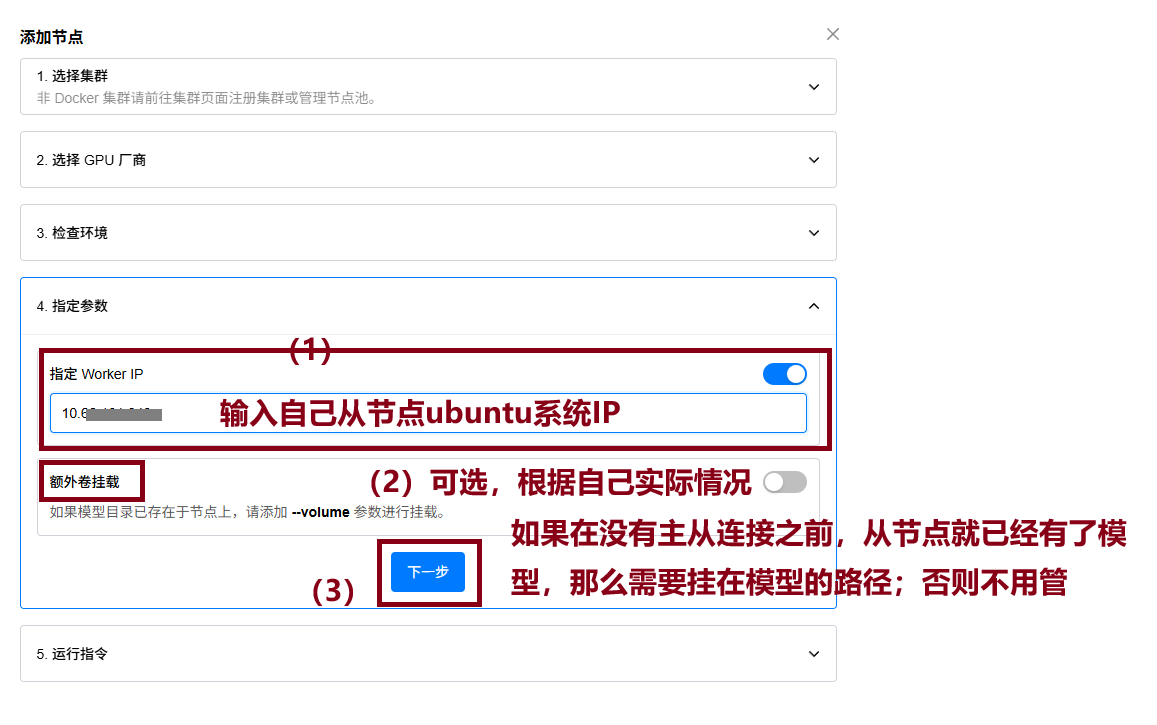
(4)运行指令启动从节点并加入集群
sudo docker run -d --name CJDX-GPU-BackUp6 \
--restart=unless-stopped \
--privileged \
--network=host \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume gpustack-data:/var/lib/gpustack \
--runtime nvidia \
quay.io/gpustack/gpustack:v2.0.0 \
--server-url http://<主节点IP> \
--token gpustack_2757b3a2a3933ed3_ba592b6fcf6d1316882dd66d473a080d \
--advertise-address <从节点IP> \
--worker-name CJDX-GPU-BackUp6
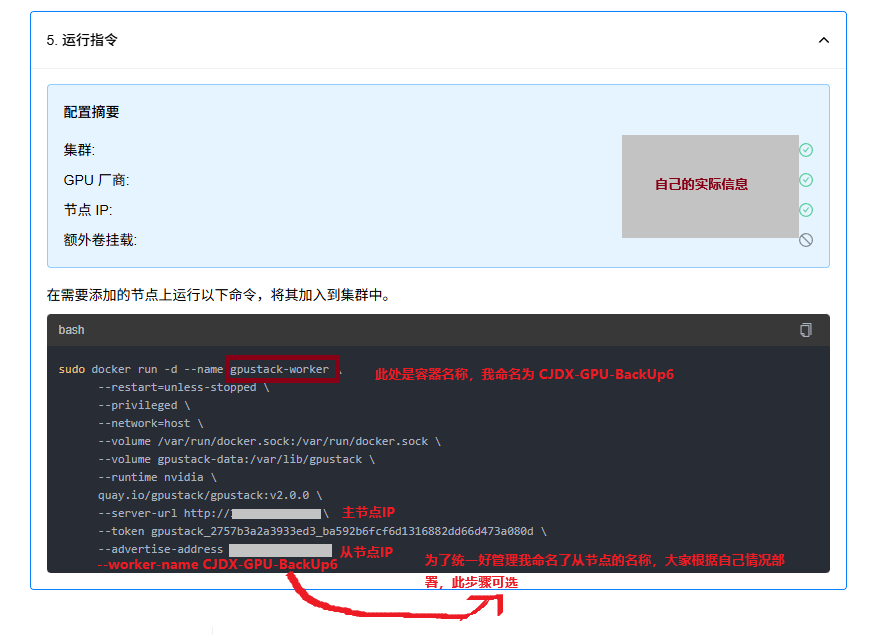
正在拉取截图如下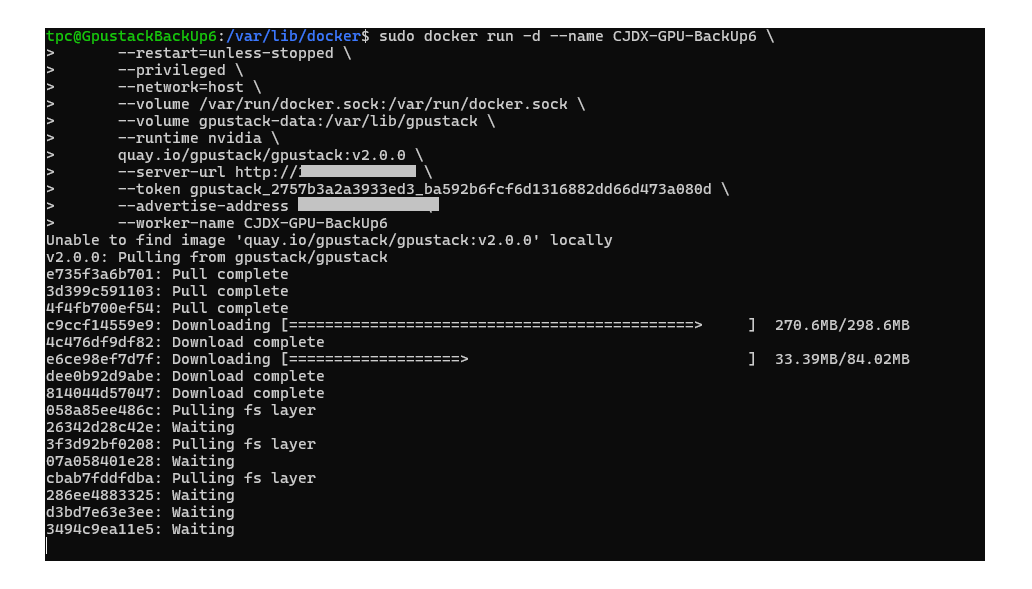
成功截图如下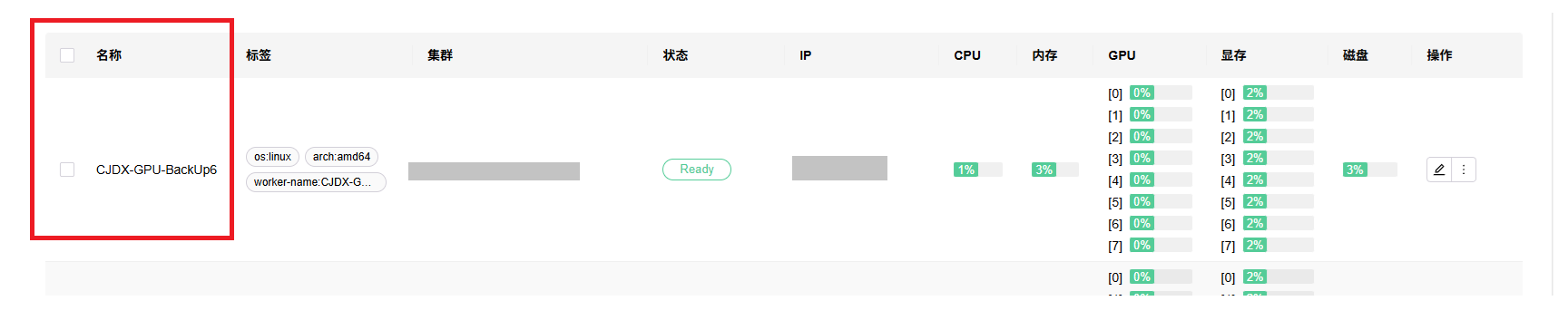
到此,添加从节点成功!
——————————————————————
之前连接上了,但是由于节点名称不对,又删除了,再次运行启动从节点的命令时候,就无法正常启动了。
解决办法:
(1)将错误的从节点docker容器停止且删掉
sudo docker stop [CJDX-GPU-BackUp6]
sudo docker rm [CJDX-GPU-BackUp6]
备注:[ ]中的内容为你自己的容器名称,也可以是容器ID
(2)查看所有相关GPUStack相关的数据卷
docker ps -a | grep gpustack-data
(3)删除所有相关数据卷
docker volume rm gpustack-data

(4)再次添加节点,即以从节点方式启动
sudo docker run -d --name CJDX-GPU-BackUp6 \
--restart=unless-stopped \
--privileged \
--network=host \
--volume /var/run/docker.sock:/var/run/docker.sock \
--volume gpustack-data:/var/lib/gpustack \
--runtime nvidia \
quay.io/gpustack/gpustack:v2.0.0 \
--server-url http://<主节点IP> \
--token gpustack_2757b3a2a3933ed3_ba592b6fcf6d1316882dd66d473a080d \
--advertise-address <从节点IP> \
--worker-name CJDX-GPU-BackUp6
到此,这个问题解决了!
就是因为即使删掉容器本身,但是它的数据一直存在,所以不能再次启动成功,删除了原来的数据卷,再次启动即可!
再次启动成功后,查看/var/lib/docker/volumes/gpustack-data/_data,你会发现还是有数据的,这就是新的初始化好的。
这里需要注意:如果你只是删除了 _data 文件夹rm -rf _data,但未通过 Docker 命令docker volume rm gpustack-data 删除数据卷,Docker 仍会认为该数据卷存在,但无法访问其内容。
——————————————————————

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)