【第一阶段—数学基础】第十四章:AI数学入门:微积分基础—梯度下降算法
梯度下降是AI训练的核心算法,通过沿负梯度方向逐步调整参数寻找函数最小值。本文系统讲解梯度下降原理、学习率影响和多维应用:1)一维示例展示参数更新过程,离目标越近步幅越小;2)学习率实验表明0.1适中(收敛快),0.01过小(收敛慢),0.5过大(震荡),1.1导致发散;3)多维梯度下降扩展至参数向量更新,通过偏导数计算各维度步长。最后给出学习率选择指南和实践建议,为理解神经网络优化奠定数学基础。
·

学习目标:掌握梯度下降算法,理解AI训练的核心原理
预计时间:20-25分钟
前置知识:导数基础、偏导数与梯度、链式法则与优化
📋 本篇内容
梯度下降原理 → 学习率影响 → 多维梯度下降 → AI应用 → 实践练习
🚀 1. 梯度下降的原理
生活类比:闭着眼睛下山,每次朝最陡的方向走一小步
核心思想:
- 目标:找到函数的最小值
- 方法:沿着梯度的反方向(负梯度)移动
- 步骤:每次走一小步,直到到达最低点
更新公式:
x_new = x_old - 学习率 × 梯度
1.1 一维梯度下降示例
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'Microsoft YaHei', 'STHeiti']
plt.rcParams['axes.unicode_minus'] = False
# 例子:最小化 f(x) = (x - 3)²
def f(x):
return (x - 3) ** 2
def f_prime(x):
return 2 * (x - 3)
# 梯度下降
def gradient_descent(start_x, learning_rate=0.1, n_iterations=20):
x = start_x
history = [x]
for i in range(n_iterations):
grad = f_prime(x)
x = x - learning_rate * grad # 核心公式!
history.append(x)
if i < 5: # 打印前5步
print(f"步骤{i+1}: x={x:.4f}, f(x)={f(x):.4f}, 梯度={grad:.4f}")
return history
# 从x=0开始
print("从 x=0 开始梯度下降:")
history = gradient_descent(start_x=0, learning_rate=0.1, n_iterations=20)
# 可视化
x_range = np.linspace(-1, 6, 100)
y_range = f(x_range)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(x_range, y_range, 'b-', linewidth=2, label='f(x)')
plt.plot(history, [f(x) for x in history], 'ro-', markersize=8, label='梯度下降路径')
plt.plot(3, 0, 'g*', markersize=20, label='最小值')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('梯度下降过程')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(range(len(history)), history, 'ro-', markersize=8)
plt.axhline(y=3, color='g', linestyle='--', label='最优值 x=3')
plt.xlabel('迭代次数')
plt.ylabel('x的值')
plt.title('x的收敛过程')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"\n最终结果: x = {history[-1]:.4f}, f(x) = {f(history[-1]):.6f}")
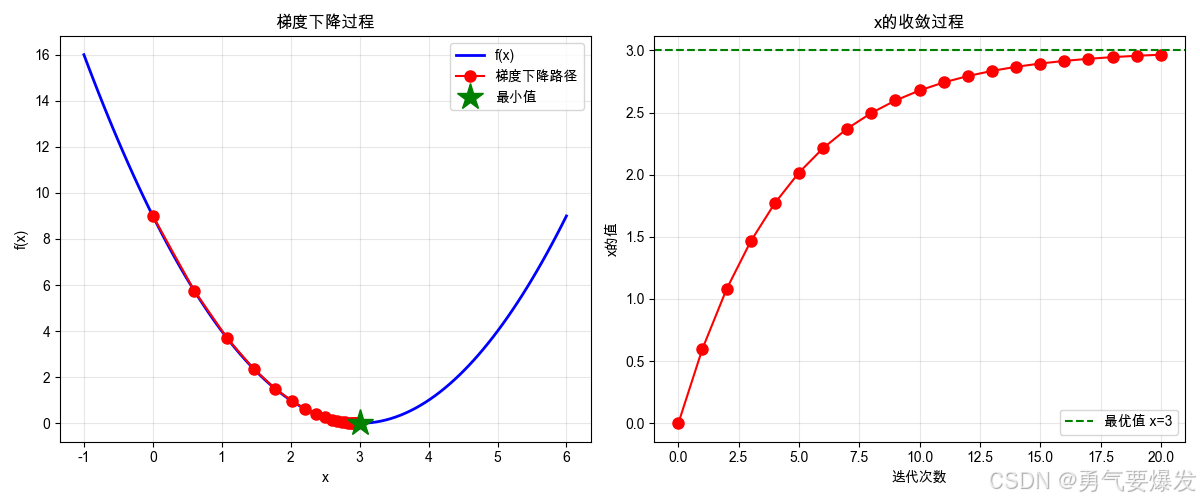
💡 关键洞察:
-
梯度下降的过程
步骤1: x=0.6 → 往右走一大步 步骤2: x=1.08 → 继续往右 步骤3: x=1.46 → 步子变小了 ... 步骤20: x≈3.0 → 到达目标! -
为什么步子越来越小?
- 离目标远时:梯度大 → 步子大 → 走得快
- 离目标近时:梯度小 → 步子小 → 走得慢
- 到达目标时:梯度=0 → 停止
-
这就是AI训练的过程!
- 损失函数 = 这条抛物线
- 模型参数 = x的位置
- 训练过程 = 梯度下降找最小值
- 训练完成 = 到达最优点
⚙️ 2. 学习率的影响
生活类比:下山的步伐大小
场景:你在山上想下山(找到最低点)
步伐太小(学习率0.01):
- 每次只走一小步
- 很安全,不会摔倒
- 但是太慢了,天黑都下不了山
步伐适中(学习率0.1):
- 每次走正常步伐
- 既安全又快速
- 很快就能下山 ✓
步伐太大(学习率0.5):
- 每次跨一大步
- 容易越过山谷,在两边来回跳
- 反而下不去
步伐过大(学习率1.1):
- 每次跳得太远
- 越跳越高,越来越远
- 永远下不了山!
2.1 不同学习率的对比
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'Microsoft YaHei', 'STHeiti']
plt.rcParams['axes.unicode_minus'] = False
def f(x):
return (x - 3) ** 2
def f_prime(x):
return 2 * (x - 3)
def gradient_descent(start_x, learning_rate, n_iterations=50):
x = start_x
history = [x]
for _ in range(n_iterations):
x = x - learning_rate * f_prime(x)
history.append(x)
return history
# 测试不同的学习率
learning_rates = [0.01, 0.1, 0.5, 1.1]
start_x = 0
plt.figure(figsize=(12, 8))
for i, lr in enumerate(learning_rates, 1):
history = gradient_descent(start_x, lr, n_iterations=20)
plt.subplot(2, 2, i)
plt.plot(range(len(history)), history, 'o-', markersize=6)
plt.axhline(y=3, color='r', linestyle='--', alpha=0.5, label='最优值')
plt.xlabel('迭代次数')
plt.ylabel('x的值')
# 根据学习率添加不同的标题说明
if lr == 0.01:
plt.title(f'学习率 = {lr}(太小:收敛慢)')
elif lr == 0.1:
plt.title(f'学习率 = {lr}(适中:完美!✓)')
elif lr == 0.5:
plt.title(f'学习率 = {lr}(太大:震荡)')
else:
plt.title(f'学习率 = {lr}(过大:发散)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.ylim(-5, 10)
plt.tight_layout()
plt.show()
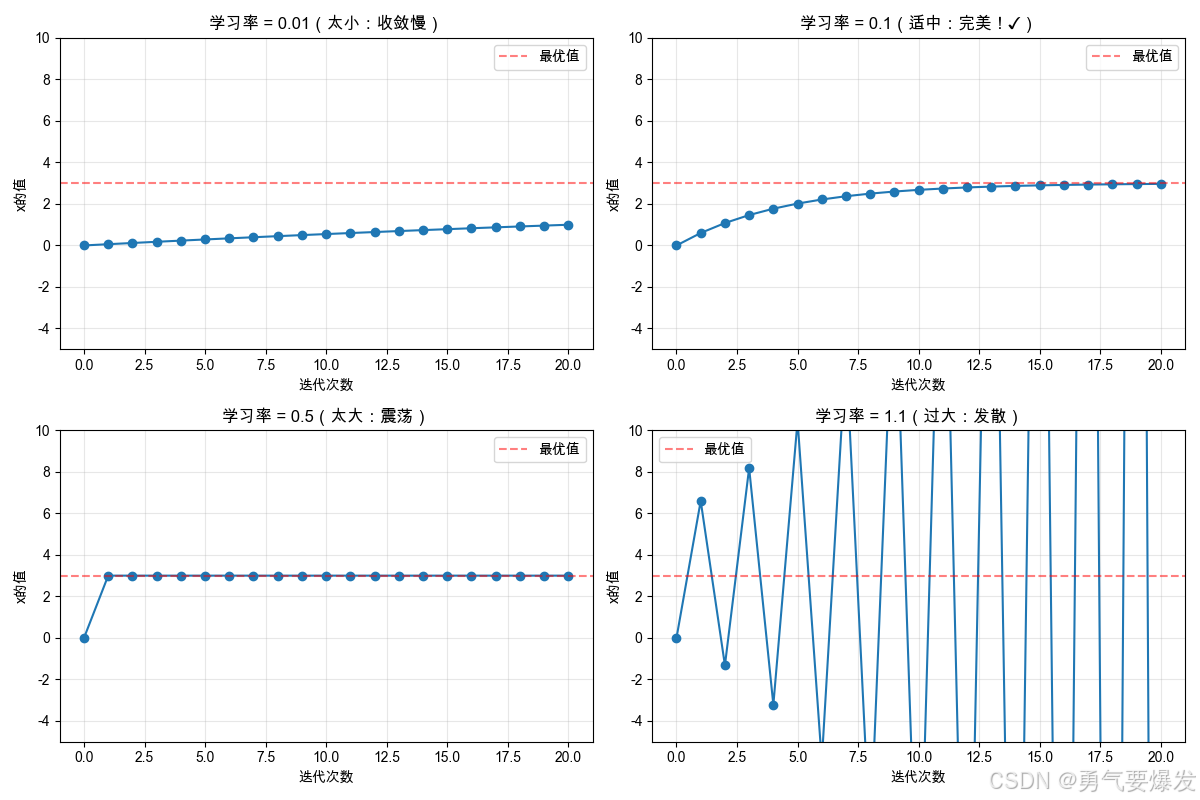
💡 学习率选择指南:
| 学习率 | 现象 | 类比 | 结果 |
|---|---|---|---|
| 太小 (0.01) | 慢慢爬 | 蜗牛下山 | 太慢 ❌ |
| 适中 (0.1) | 稳步走 | 正常下山 | 完美 ✓ |
| 太大 (0.5) | 来回跳 | 跳过头又跳回来 | 震荡 ❌ |
| 过大 (1.1) | 越跑越远 | 跳下悬崖 | 发散 ❌ |
实际应用建议:
- 从 0.1 或 0.01 开始尝试
- 如果收敛太慢 → 增大学习率
- 如果出现震荡 → 减小学习率
- 现代优化器(Adam)会自动调整学习率
🌐 3. 多维梯度下降
从一维到多维
一维梯度下降(前面学的):
- 只有一个参数 x
- 在一条线上移动
- 就像在山谷里沿着一条路走
多维梯度下降(现在要学的):
- 有多个参数 (x, y) 或 (w₁, w₂, …, wₙ)
- 在平面或空间中移动
- 就像在山谷里可以任意方向走
3.1 核心思想
一维情况:
x_new = x_old - 学习率 × 导数
多维情况:
x_new = x_old - 学习率 × ∂f/∂x
y_new = y_old - 学习率 × ∂f/∂y
或者用向量表示:
[x_new] [x_old] [∂f/∂x]
[y_new] = [y_old] - lr × [∂f/∂y]
↑ ↑ ↑ ↑
新位置 旧位置 学习率 梯度向量
3.2 二维梯度下降示例
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'Microsoft YaHei', 'STHeiti']
plt.rcParams['axes.unicode_minus'] = False
# 例子:二维函数 f(x, y) = (x-3)² + (y-2)²
def f(x, y):
return (x - 3)**2 + (y - 2)**2
def gradient(x, y):
df_dx = 2 * (x - 3)
df_dy = 2 * (y - 2)
return np.array([df_dx, df_dy])
# 梯度下降
def gradient_descent_2d(start_point, learning_rate=0.1, n_iterations=50):
point = np.array(start_point, dtype=float)
history = [point.copy()]
for i in range(n_iterations):
grad = gradient(point[0], point[1])
point = point - learning_rate * grad
history.append(point.copy())
if i < 3:
print(f"步骤{i+1}: ({point[0]:.3f}, {point[1]:.3f}), "
f"f={f(point[0], point[1]):.3f}")
return np.array(history)
# 从(0, 0)开始
print("从 (0, 0) 开始梯度下降:")
history = gradient_descent_2d([0, 0], learning_rate=0.1, n_iterations=30)
# 可视化
x_range = np.linspace(-1, 6, 100)
y_range = np.linspace(-1, 5, 100)
X, Y = np.meshgrid(x_range, y_range)
Z = f(X, Y)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
contour = plt.contour(X, Y, Z, levels=20, cmap='viridis')
plt.colorbar(contour)
plt.plot(history[:, 0], history[:, 1], 'ro-', markersize=6, linewidth=2)
plt.plot(3, 2, 'g*', markersize=20, label='最小值(3, 2)')
plt.xlabel('x')
plt.ylabel('y')
plt.title('梯度下降路径')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
losses = [f(p[0], p[1]) for p in history]
plt.plot(range(len(losses)), losses, 'b-', linewidth=2)
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title('损失函数收敛曲线')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"\n最终点: ({history[-1][0]:.4f}, {history[-1][1]:.4f})")
print(f"最终损失: {f(history[-1][0], history[-1][1]):.6f}")
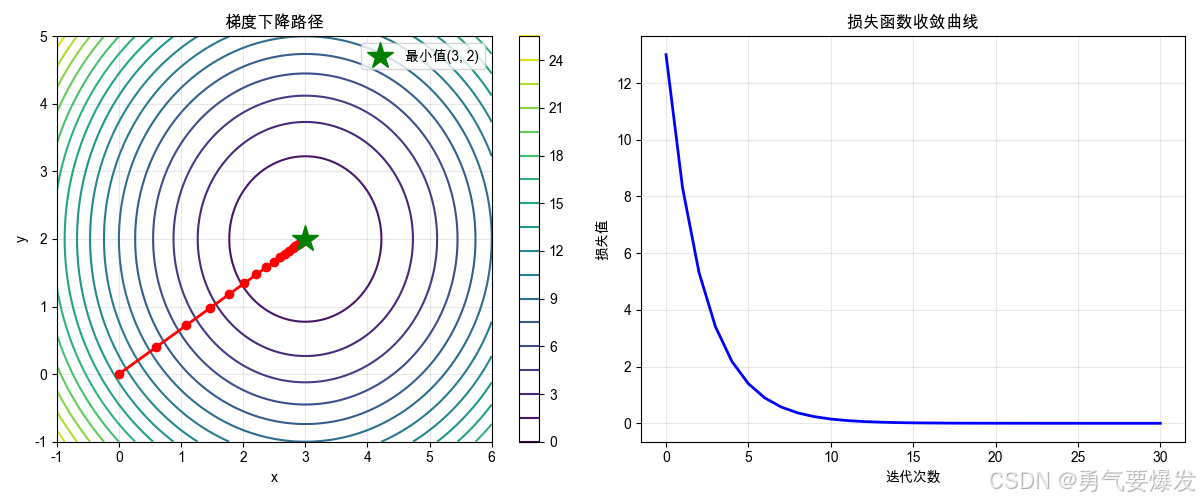
💡 关键洞察:
-
二维 vs 一维
一维:在一条线上移动 二维:在平面上移动,更灵活 -
梯度的作用
- 告诉我们往哪个方向走(垂直于等高线)
- 告诉我们走多快(梯度大=步子大)
-
实际应用
- 线性回归:优化 w 和 b(2维)
- 神经网络:优化成千上万个参数(高维)
- 原理相同:都是沿着梯度方向更新
-
收敛特点
- 开始快:离目标远,梯度大
- 后来慢:接近目标,梯度小
- 最终稳定:到达最优点,梯度≈0
🤖 4. 微积分在AI中的应用
4.1 神经网络训练
import numpy as np
# 简单的神经网络:y = w*x + b
# 目标:找到最佳的w和b
# 训练数据
X_train = np.array([1, 2, 3, 4, 5])
y_train = np.array([2, 4, 6, 8, 10]) # y = 2x
# 初始化参数
w = 0.0
b = 0.0
learning_rate = 0.01
n_epochs = 100
print("训练神经网络...")
for epoch in range(n_epochs):
# 前向传播
y_pred = w * X_train + b
# 计算损失(均方误差)
loss = np.mean((y_pred - y_train) ** 2)
# 计算梯度(反向传播)
dL_dw = np.mean(2 * (y_pred - y_train) * X_train)
dL_db = np.mean(2 * (y_pred - y_train))
# 更新参数(梯度下降)
w = w - learning_rate * dL_dw
b = b - learning_rate * dL_db
if epoch % 20 == 0:
print(f"Epoch {epoch}: w={w:.4f}, b={b:.4f}, loss={loss:.4f}")
print(f"\n最终参数: w={w:.4f}, b={b:.4f}")
print(f"理论值: w=2, b=0")
这个例子展示了:
- 前向传播:计算预测值
- 计算损失:衡量预测误差
- 反向传播:计算梯度
- 梯度下降:更新参数
这就是所有深度学习框架(PyTorch、TensorFlow)的核心流程!
4.2 梯度下降的变体
常见的优化算法:
| 算法 | 特点 | 适用场景 |
|---|---|---|
| SGD | 基础梯度下降 | 简单问题 |
| Momentum | 加入动量,加速收敛 | 一般问题 |
| Adam | 自适应学习率 | 大多数深度学习 |
| RMSprop | 适应性调整学习率 | RNN训练 |
Adam优化器(最常用):
- 自动调整学习率
- 结合了Momentum和RMSprop的优点
- 是深度学习的默认选择
🎯 总结
核心概念
- ✅ 梯度下降 = 沿着负梯度方向更新参数
- ✅ 学习率控制收敛速度和稳定性
- ✅ 多维梯度下降是AI训练的核心
- ✅ 梯度下降有多种变体(SGD、Adam等)
微积分是AI优化的语言,掌握它就能理解神经网络如何学习! 🚀✨

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)