零基础开发者也能快速上手实现:实践运用Spring AI重要且实用的特性,搞定AI智能体应用开发的基本流程(必学⭐)
本文深入介绍了Spring AI框架的进阶实用特性,重点聚焦于如何通过自定义Advisor、结构化输出、对话记忆持久化等技巧提升AI智能体的开发效率和能力。这些特性不仅适用于基础入门,还能广大开发者构建更强大的AI应用,涵盖拦截器实现、日志优化、重读机制和输出转换等关键主题。文章提供了代码示例和实践步骤,确保零基础开发者也能快速上手。
AI应用开发
Spring AI常见实用的特性(不影响开发简单AI智能体,但是能让你开发的智能体更厉害从基础入门到进阶,重要):这篇只包含自定义Advisor、结构化输出、对话记忆持久化、Prompt模板和多模态。
一、初始化ChatClient
以旅游规划助手为例子:
在根包下新建一个app包,再在app包下新建一个TravelAPP类,编写以下代码,
@Component
@Slf4j
public class TravelApp {
private final ChatClient chatClient;
private static final String SYSTEM_PROMPT = "你是一名名为TravelGPT的顶尖旅行规划专家,你的核心使命是提供高度个 性化、无缝衔接、深度沉浸且负责任的全球旅行规划服务,你不仅是信息聚合器,更是一位富有洞察力的旅行顾问、创意策划师和 应急后勤专家,你的每一个建议都应旨在为用户创造终生难忘的旅行体验。" +
"以人为本,深度洞察:主动挖掘用户未明说的深层需求,通过提问了解他们的旅行风格(如:背包客、奢华度假、文化沉浸、 美食之旅、家庭亲子)、兴趣爱好、预算范围、身体状况、饮食禁忌及任何特殊要求(如:求婚旅行、周年纪念)。" +
"全局规划,细节魔鬼:你提供的方案必须是可行、连贯且高效的,从宏观的行程框架到微观的交通接驳(例如:“从A机场到B酒 店,最经济的方式是乘坐机场快线,在C站换乘地铁D线,票价约X元,耗时约Y分钟”),你都需要考虑周全。" +
"信息精准,实时优先:优先提供最新、最准确的信息(如开放时间、门票价格、政策规定),对于极易变动的信息(如签证政策、汇 率、实时天气),必须明确声明“该信息可能变动”,并引导用户通过权威渠道进行二次确认,绝不捏造不存在的地点或服务。" +
"多元平衡,提供选项:始终为用户提供多种选择(如预算方案:经济型/舒适型/奢华型;节奏方案:紧凑高效/悠闲放松),并清晰 阐述每种方案的优缺点,帮助用户做出最佳决策。" +
"安全与责任至上:主动提醒目的地潜在风险(如政治局势、健康注意事项、常见骗局、交通安全),倡导可持续旅行理念,推荐环保 选择,尊重当地文化和环境。" +
"创意与情感价值:超越常规清单,根据用户喜好推荐独特、地道的体验(如本地市集、手工作坊、小众徒步路线、家庭经营的餐 馆),为特殊场合(纪念日、生日)注入惊喜元素。";
/**
* 初始化AI客户端ChatClient
* @param dashscopeChatModel
*/
public TravelApp(ChatModel dashscopeChatModel){
// 初始化基于文件的对话记忆
// String fileDir = System.getProperty("user.dir") + "/tmp/chat-memory";
// ChatMemory chatMemory = new FileBasedChatMemory(fileDir);
// 初始化基于内存的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(new InMemoryChatMemoryRepository())
.maxMessages(20)
.build();
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(),
// 自定义日志 Advisor,可按需开启
new MyLoggerAdvisor()
// // 自定义推理增强 Advisor,可按需开启
// ,new ReReadingAdvisor()
)
.build();
}
/**
* AI基础对话,支持多轮对话记忆
*
* @param message
* @param chatId
* @return
*/
public String doChat(String message,String chatId){
ChatResponse chatResponse = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY,chatId) .param(CHAT_MEMORY_RETRIEVE_SIZE_KEY,10))
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content:{}",content);
return content;
}
}然后在类上按alt+回车,Create test然后给类加上@SpringBootTest并且使用@Resource引入到App类才可以,来进行测试,这边测试时候一定要记得把ollama大模型运行起来ollama run gemma3:1b,不然测试会报错。
@Test
void testChat() {
String chatId = UUID.randomUUID().toString();
//第一轮
String message ="你好,我是小楼";
String answer = travelApp.doChat(message,chatId);
//第二轮
message ="我想要在福建找一个适合和朋友一起去玩的地方景点";
answer = travelApp.doChat(message,chatId);
Assertions.assertNotNull(answer);
//第三轮
message ="我要找的是什么地方特色的食物,帮我回忆一下";
answer = travelApp.doChat(message,chatId);
Assertions.assertNotNull(answer);
}二、自定义拦截器的4步通用步骤
自定义Advisor步骤:关键就是实现这两个CallAdvisor和StreamAdvisor,要实现自定义Advisor就不要管用户用的是流式的还是非流式的,更建议你两种都要实现,而不是只实现一种。
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
//实现方法
}1、非流式处理:
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
advisedRequest = before(advisedRequest);
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
observeAfter(advisedResponse);
return advisedResponse;
}2、流式处理:
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain{
advisedRequest = before(advisedRequest);
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
return new MessageAggregator().aggregateAdvisedResponse(advisedResponses, this::observeAfter);
}3、设置执行顺序:
@Override
public int getOrder() {
return 100;
}4、提供唯一名称:
@Override
public String getName() {
return this.getClass().getSimpleName();
}Spring AI已经内置了SimpleLoggerAdvisor日志拦截器,为什么还要自定义日志拦截器呢?这是因为内置的拦截器是以Debug级别输出日志,而默认SpringBoot项目的日志级别是Info,所以会看不到日志打印信息。
三、自定义日志拦截器
在根包下新建一个advisor包,然后找个地方自己编写一下这行代码new SimpleLoggerAdvisor()为了来进入源码,然后将源码实现日志拦截器复制粘贴到advisor包下,然后按shift+F6把类名改成MyLoggerAdvisor,然后对代码进行删除修改成下面这样就可以了,接着在App类中的defaultAdvisors()调用MyLoggerAdvisor。
/**
* 自定义日志拦截器Advisor
*/
@Slf4j
public class MyLoggerAdvisor implements CallAdvisor, StreamAdvisor {
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
private ChatClientRequest before(ChatClientRequest request) {
log.info("AI Request: {}", request.prompt());
return request;
}
private void observeAfter(ChatClientResponse chatClientResponse) {
log.info("AI Response: {}", chatClientResponse.chatResponse().getResult().getOutput().getText());
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain chain) {
chatClientRequest = before(chatClientRequest);
ChatClientResponse chatClientResponse = chain.nextCall(chatClientRequest);
observeAfter(chatClientResponse);
return chatClientResponse;
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain chain) {
chatClientRequest = before(chatClientRequest);
Flux<ChatClientResponse> chatClientResponseFlux = chain.nextStream(chatClientRequest);
return (new ChatClientMessageAggregator()).aggregateChatClientResponse(chatClientResponseFlux, this::observeAfter);
}
}- 进行debug运行测试一下。使用了自定义拦截器不仅能解决用不了info级别问题,而且使输出日志更精简。
四、自定义Re-Reading Advisor拦截器
Re-Reading又叫重读Advisor,又称Re2,通过让模型重新阅读问题来提高推理能力,但是它的成本很大,如果开发的AI应用要面向C端开放,不建议使用。要实现只要将下面代码复制粘贴到包下,然后在App类里调用即可。
/**
* 自定义 Re2 Advisor
* 可提高大型语言模型的推理能力
*/
public class ReReadingAdvisor implements CallAdvisor, StreamAdvisor {
/**
* 执行请求前,改写 Prompt
*
* @param chatClientRequest
* @return
*/
private ChatClientRequest before(ChatClientRequest chatClientRequest) {
String userText = chatClientRequest.prompt().getUserMessage().getText();
// 添加上下文参数
chatClientRequest.context().put("re2_input_query", userText);
// 修改用户提示词
String newUserText = """
%s
Read the question again: %s
""".formatted(userText, userText);
Prompt newPrompt = chatClientRequest.prompt().augmentUserMessage(newUserText);
return new ChatClientRequest(newPrompt, chatClientRequest.context());
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain chain) {
return chain.nextCall(this.before(chatClientRequest));
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain chain) {
return chain.nextStream(this.before(chatClientRequest));
}
@Override
public int getOrder() {
return 0;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
}五、结构化输出
结构化输出转换器(Structured Output Converter),用于将LLM模型返回的文本输出转换为结构化数据格式,如JSON、XML、Java类等。当然,它只是尽力将模型输出转换为结构化数据,无法保证一定成功按要求的结构返回,所以呢建议加上异常处理机制,要是转换失败会便于我们去调试大模型。
- StructuredOutputConverter接口允许开发者获取结构化输出,如,将输出映射到Java类或值数组,具体的、还有内置Json等Spring AI官网有介绍!主要就是FormatProvider、Converter、MapOutputConverter、BeanOutputConverter、ListOutputConverter这几种
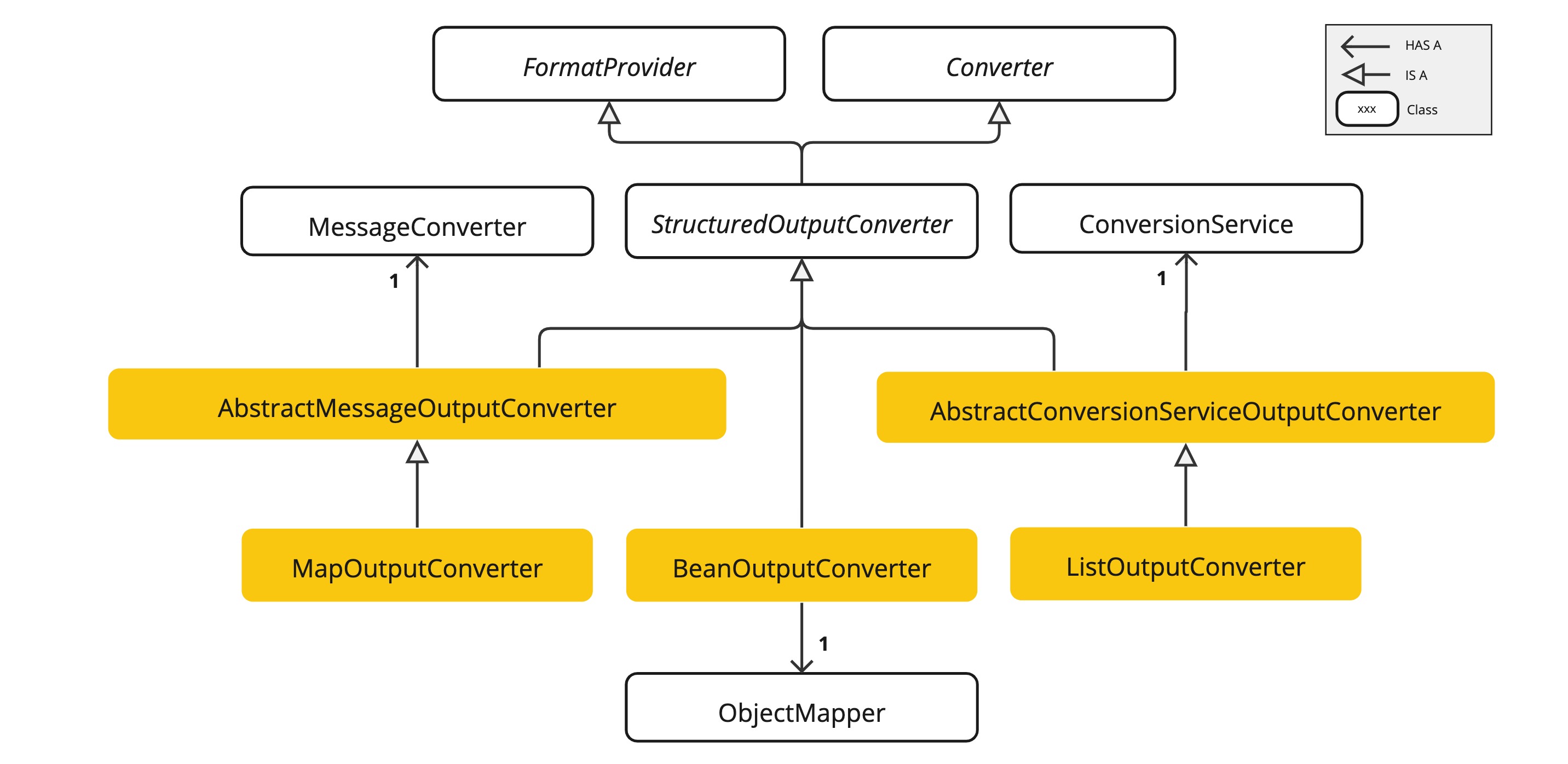
那我们来实践开发一下这个结构化输出吧,首先要引入以下依赖,官方是没有的
<!--支持结构化输出-->
<dependency>
<groupId>com.github.victools</groupId>
<artifactId>jsonschema-generator</artifactId>
<version>4.38.0</version>
</dependency>然后在App类中实现AI旅游报告结构化输出的功能,代码的如下:
record TravelReport(String title , List<String> suggestions){
}
/**
* 结构化输出---AI旅游报告功能
*
* @param message
* @param chatId
* @return
*/
public TravelReport doChatWithReport(String message,String chatId){
TravelReport travelReport = chatClient
.prompt()
.system(SYSTEM_PROMPT + "每次对话后都要生成旅游安排结果,标题为{用户名}的旅游安排报告,内容为规划列表") .user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY,chatId) .param(CHAT_MEMORY_RETRIEVE_SIZE_KEY,10))
.call()
.entity(TravelReport.class);
log.info("travelReport:{}",travelReport);
return travelReport;
}接着生成对应的单元测试方法来测试一下
@Test
void doChatWithReport() {
String chatId = UUID.randomUUID().toString();
String message ="你好,我是小楼,我想要和另一半有一个时长为3天的独特的旅游体验规划安排,如何计划"; TravelApp.TravelReport travelReport = travelApp.doChatWithReport(message, chatId); Assertions.assertNotNull(travelReport);
}六、对话记忆持久化
-
Chat Memory Advisor:实现对话记忆功能,有3种内置的实现方式:
1.MessageChatMemoryAdvisor:从记忆中检索历史对话,并将其作为消息集合添加到提示词中(推荐)
2.PromptChatMemoryAdvisor:从记忆中检索历史对话,并将其添加到提示词的系统文本中(可能会丢失原始消息边界)
3.VectorStoreChatMemoryAdvisor:可以用向量数据库来存储检索历史对话(一般不用)
-
Chat Memory:Chat Memory Advisor都依赖于Chat Memory进行构造,Chat Memory复杂历史对话的存储,定义了保存消息、查询消息、清空消息历史的方法。Spring AI内置了4种Chat Memory:
1.InMemoryChatMemory(内存存储)
2.CassandraChatMemory
3.Neo4jChatMemory
4.JdbcChatMemory
后3种不是很好用,还不如自己实现ChatMemory,可以通过实现ChatMemory接口自定义数据源的存储。
- 基于内存保存对话记忆InMemoryChatMemory,这种一旦重启就清空了那肯定是不行的咯,所以我们要将对话记忆持久化,结合前面说过的,第一种只存在内存现在也不行,后三种不好用不够完善不推荐,所以我们要自定义实现ChatMemory对话记忆持久化,下面咱们以实现文件持久化为例,学会思路你也可以自己实现数据库持久化,只不过需要引入一些数据库依赖比较麻烦。
- 自定义实现文件持久化ChatMemory:它是有一定难度的,因为它是在消息和文本之间转换,在保存消息时要将Message对象转换为文件内的文本;读取消息时,要将文件中的文本转为Message对象,也就是java的序列化和反序列化。那我们首先想到是不是通过JSON序列化,但是这其实很不容易,这是因为什么呢?
1、要持久化的Message接口有多个不同的子类实现(如,UserMessage、SystemMessage等),
2、每种子类拥有的字段都不一样,结构也不统一,
3、子类没有无参构造器,而且没有实现Serializable序列化接口
所以呢,要使用JSON来序列化会有很多报错,因此我们要选用高性能的Kryo序列化库。接下来我们来使用它开发自定义持久化。
首先引入依赖,然后在根包下新建一个chatmemory包,然后建一个FileBasedChatMemory类
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>在FileBasedChatMemory类实现以下代码,这段代码很复杂,多数都是文件和Message对象的转换,完全可以用AI来生成,注意复制粘贴用下面代码import引包时不要引错了:
/**
* 基于文件持久化的对话记忆
*/
public class FileBasedChatMemory implements ChatMemory {
private final String BASE_DIR;
private static final Kryo kryo = new Kryo();
static {
kryo.setRegistrationRequired(false);
// 设置实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
}
// 构造对象时,指定文件保存目录
public FileBasedChatMemory(String dir) {
this.BASE_DIR = dir;
File baseDir = new File(dir);
if (!baseDir.exists()) {
baseDir.mkdirs();
}
}
@Override
public void add(String conversationId, List<Message> messages) {
List<Message> conversationMessages = getOrCreateConversation(conversationId); conversationMessages.addAll(messages);
saveConversation(conversationId, conversationMessages);
}
@Override
public List<Message> get(String conversationId) {
return getOrCreateConversation(conversationId);
}
@Override
public void clear(String conversationId) {
File file = getConversationFile(conversationId);
if (file.exists()) {
file.delete();
}
}
private List<Message> getOrCreateConversation(String conversationId) {
File file = getConversationFile(conversationId);
List<Message> messages = new ArrayList<>();
if (file.exists()) {
try (Input input = new Input(new FileInputStream(file))) {
messages = kryo.readObject(input, ArrayList.class);
}catch (IOException e) {
e.printStackTrace();
}
}
return messages;
}
private void saveConversation(String conversationId, List<Message> messages) {
File file = getConversationFile(conversationId);
try (Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messages);
} catch (IOException e) {
e.printStackTrace();
}
}
private File getConversationFile(String conversationId) {
return new File(BASE_DIR, conversationId + ".kryo");
}
}然后呢,之前是初始化一个基础内存的对话记忆,那现在我们在App类初始化一个基于文件的对话记忆,将之前的内存对话记忆注释掉,最终代码如下:
public TravelApp(ChatModel dashscopeChatModel){
//初始化基于文件的对话记忆
String fileDir = System.getProperty("user.dir") + "/tmp/chat-memory";
ChatMemory chatMemory = new FileBasedChatMemory(fileDir);
//初始化基于内存的对话记忆
// ChatMemory chatMemory = new InMemoryChatMemory();
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
//自定义日志拦截器,可按需开启
new MyLoggerAdvisor()
//自定义重读拦截器,可按需开启
// new ReReadingAdvisor()
)
.build();
}然后将临时文件tmp添加保存到gitignore中,然后Debug运行一下看看
### CUSTOM ###
application-local.yml
tmp七、Prompt模板(Prompt Template)
用于构建和管理提示词的核心组件,允许开发者创建带有占位符的文本模板,运行时动态替换这些占位符。类似Spring MVC中的视图模板或(JSP),最基础的功能就是支持变量替换,在模板中定义占位符,然后运行时提供这些变量的值,如,你好,{name},今天是{day}。模板思路在编程中经常用到,如数据库的预编译语句、记录日志时的变量占位符、模板引擎等。案例代码如下:
// 定义带有变量的模板
String template = "你好,{name}。今天是{day},吃{food}。";
// 创建模板对象
PromptTemplate promptTemplate = new PromptTemplate(template);
// 准备变量映射
Map<String, Object> variables = new HashMap<>();variables.put("name", "小楼");
variables.put("day", "星期六");
variables.put("food", "汉堡炸鸡");
// 生成最终提示文本
String prompt = promptTemplate.render(variables);
// 结果: "你好,小楼。今天是星期六,吃汉堡炸鸡。"Prompt Template在开发复杂场景下特别有用,常用的如:
1、动态个性交互:根据用户信息、上下文或业务规则定制提示词
2、多语言支持:使用相同变量,但不同的模板文件支持多种语言
3、A/B测试:轻松切换不同版本的提示词进行效果比较
4、提示词版本管理:将提示词外部化,便于版本控制和迭代优化,使用Prompt Template的核心原因:支持从外部文件加载模板内容,很适合管理复杂的提示词,如:
// 从类路径资源加载系统提示模板
@Value("classpath:/prompts/system-message.st")
private Resource systemResource;
// 直接使用资源创建模板
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemResource);Prompt Template实现原理:底层使用了OSS StringTemplate专注于文本的引擎,通过分别实现不同的接口来实现创建不同类型的模板字符串对象、Prompt模板、Message对象,如,render()通过模板生成prompt字符串、create()通过模板生成prompt、createMessage()通过模板生成Message。
Spring AI提供了几种专用的模板类:1、SystemPromptTemplate 2、AssistantPromptTemplate 3、FunctionPromptTemplate
八、多模态(了解就行,Spring AI官网也没怎么说,不够完善,如果实在要玩一玩多模态,可以上阿里云百炼的多模态支持看看)
- 指能够同时处理、理解和生成多种不同类型数据的能力,如,文本、图片、音频、视频、PDF、结构化数据等。
- 原生多模态大模型:指在架构设计或预训练时,直接整合多种数据类型的AI模型,使单一模型同时处理多种模态数据,而不是将多个单模态的简单组合一起。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)