AIAA J | 香港理工大学王旭等:目标导向的特征提取-以特征构建增强数据驱动模型
我们的目标是提出一种通用的特征学习方法,能够显著降低特征空间的维度并增强各种代理模型的泛化能力。高维问题的建模,输入特征要么依赖于知识驱动的特征组合与构造方法(例如几何表征的CST参数化,湍流建模特征设计等),要么基于数据驱动的降维方法(如POD等)进行降维,缺乏与输出耦合的设计方法。模型对比了克里金、随机森林、深度神网络方法,预测结果表明:特征提取可以有效降低系统的维度,训练算例和测试算例间的特
目标导向的特征提取-以特征构建增强数据驱动模型
Goal-oriented Feature Extraction: a novel approach to enhance data-driven surrogate models
王旭,黄睿颀,寇家庆,唐辉,张伟伟*
香港理工大学 机械工程系
西北工业大学 航空学院

引用格式:
Wang X, Huang R, Kou J, Tang H, Zhang W. Goal-oriented Feature Extraction: a novel approach to enhance data-driven surrogate models [J]. AIAA Journal. 2025. 1-15.(doi.org/10.2514/1.J065638)
![]()
编者按
---------
高维问题的建模,输入特征要么依赖于知识驱动的特征组合与构造方法(例如几何表征的CST参数化,湍流建模特征设计等),要么基于数据驱动的降维方法(如POD等)进行降维,缺乏与输出耦合的设计方法。该论文通过对比学习方法理清潜在输入特征与目标输出的关联性,提出了输出驱动的输入特征构造方法。所构造的特征在数值算例、翼型、机翼的高维代理模型构建中起到显著的增强效果。
一、研究背景
数据驱动的代理模型广泛应用于飞行器的设计、优化过程,这可以显著提高优化的效率并降低工程系统的复杂性。然而,由于效率和准确性的限制,高维代理模型的应用仍然具有挑战性。在本研究中,我们提出了一种提取隐藏特征的方法,以简化高维问题并提高代理模型的准确性和鲁棒性。准确来说,我们建立了一个目标导向的特征提取(GFE)神经网络。然后,我们基于目标输出的差异来约束隐藏特征之间的距离。提出的隐特征学习方法可以显著降低代理模型的维度和非线性,以提高建模精度和泛化能力。针对数值算例、翼型、机翼的建模问题表明,在样本数量不足以直接建模的情况下,以目标为导向的特征提取显著提高了建模精度,这将有效提高模型的适用范围。针对多样化的数据驱动模型的对比发现,以目标为导向的特征提取还可以有效减少预测算例的误差分布,以及由不同数据驱动代理模型引起的收敛性和鲁棒性差异。
二、研究方法
尽管在代理模型的构造方法上进行了大量工作,但在数据驱动方法中必须解决两个重要问题:如何构建低维特征以减少数据需求,以及如何选取合适的建模方法(降维方法和数据驱动代理方法)以确保代理模型的泛化能力。结合特征构建的代理模型建模流程可以看作图1的思路。
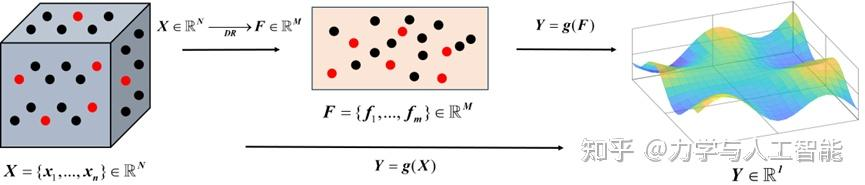
特征的差异将对建模的精度和效率造成显著影响,因此需要分析何种特征是对建模有利的,并以此为目标进行特征提取模型的优化。特别是对于非线性降维方法和代理模型,选择合适的低维特征非常困难,使得不同类型的代理模型对降维方法有不同的偏好。该问题导致降维方法与代理模型之间缺乏必要的相关性标准。从建模的角度来看,为了使基于特征的建模优于直接建模,降维方法引起的预测误差必须低于代理模型的误差容忍度。相反,如果我们从提高模型误差容忍度的角度寻找合适的低维特征,就可以提高建模精度。我们的目标是提出一种通用的特征学习方法,能够显著降低特征空间的维度并增强各种代理模型的泛化能力。
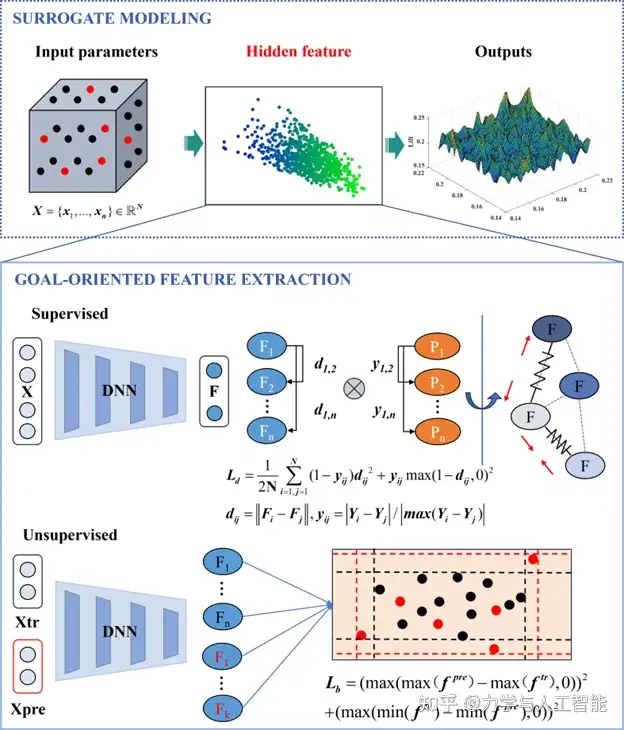
为此我们提出了针对隐藏特征的两种假设:1. 距离约束:在特征空间中,更接近的特征应该有更相似的输出结果。从误差传播结果来看,特征提取方法中的误差会被引入到代理模型中,并影响模型的预测过程。在预测过程中,特征模型的误差作为输入传递到已建立的代理模型中。在特征空间中,如果模型准确,当相邻输出更接近时,特征提取效果更好。2. 边界约束:训练数据的特征边界应覆盖测试数据的特征。这样模型的特征将得到有效利用,最大限度避免外插问题。
图2展示了所提出的目标导向特征提取方法。通过在隐藏特征空间应用约束,实现GFE模型的优化。以目标为导向的特征损失可以分为两部分。第一部分是因特征距离与输出距离不一致而产生的距离损失。第二部分是基于预测集与训练集之间边界差异的边界损失。这部分是无监督的,仅需要来自训练集和预测数据集的输入。
三、结果与讨论
为验证所提方法的有效性,我们在数值算例和气动案例上开展了代理模型构建。模型对比了克里金、随机森林、深度神网络方法,预测结果表明:特征提取可以有效降低系统的维度,训练算例和测试算例间的特征分布吻合,对不同建模方法,所构建的特征均可以提高建模精度,并且以目标导向提取的特征建模的精度不再受限于模型。
3.1 数值算例
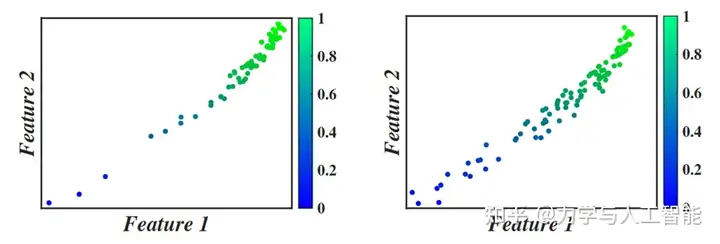
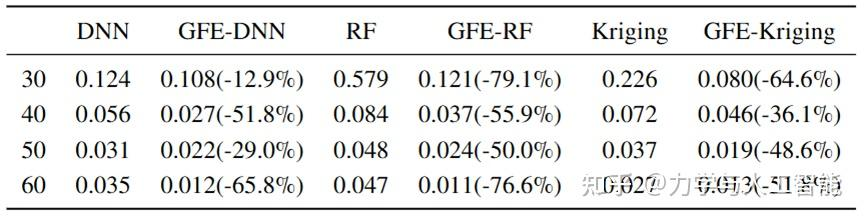
首先,我们验证了6维数值算例的建模能力。,X代表6个维度的输入,Y代表输出。图3显示了在50个训练数据点下GFE模型的特征空间。正如预期的那样,训练数据根据输出按顺序排列在隐藏特征空间中。从表中可以看出,GFE提高了模型的建模精度,并且对于不同方法具有相同的增强能力。在六维数学算例中,所提出的方法使代理模型的误差减少了超过60%。
3.2 跨声速翼型气动力建模
针对20维的CST参数拟合的跨声速翼型气动力建模问题,我们对比了不同训练样本(样本数N=[100, 150, 200])下的建模结果。
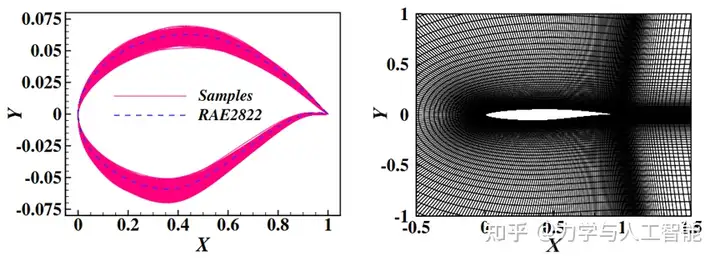
图6展示了误差统计结果的箱型图。通过特征提取构建的代理模型,在深度神经网络方法中将平均建模误差降低了13.4%,在随机森林方法中降低了61.3%,在克里金方法中降低了33.9%。

3.3 跨声速机翼气动力建模
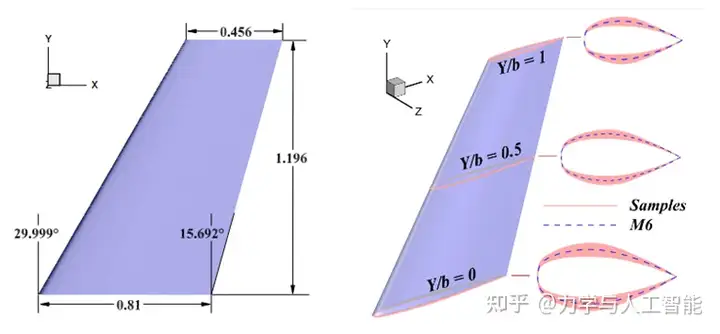
进一步,针对36维的CST参数拟合的三维机翼,我们测试了特征提取对模型构建的影响。同时我们也测试了不同的特征提取方法对建模结果的影响。如图8所示,两种专注于降维的方法(主动子空间、自编码器)显示出比基于CST参数的建模更高的误差。自编码器(AE)是一种广泛使用的无监督降维方法。编码器将高维输入压缩成低维潜在变量,迫使网络学习最具信息量的特征。然而,这些潜在特征代表了对输入特征的压缩和提取,与目标输出无关。至关重要的是,AE提取的特征无论具体输出如何(例如,亚音速与跨音速,升力与阻力)都保持不变。相比之下,提出的目标导向方法意味着特征提取是面向特定输出的。因此,为不同输出提取的特征可能完全不同。在预测升力时,目标导向特征关注影响升力的特性,而在预测阻力时,它们仅专注于影响阻力的参数。这一根本差异突显了每种方法的不同特点和优势:AE主要关注降低输入维度,而GFE旨在提高代理模型的准确性。AS方法仅保留具有较高输出敏感度的方向,并通过牺牲建模精度来实现降维。相比之下,GFE方法基于距离度量提取特征,确保这些特征直接与建模能力相关联。这解释了GFE在提高准确性方面的表现,同时突显了其与传统降维方法的区别。
各外形的法向力系数、力矩系数关联效果如下所示:
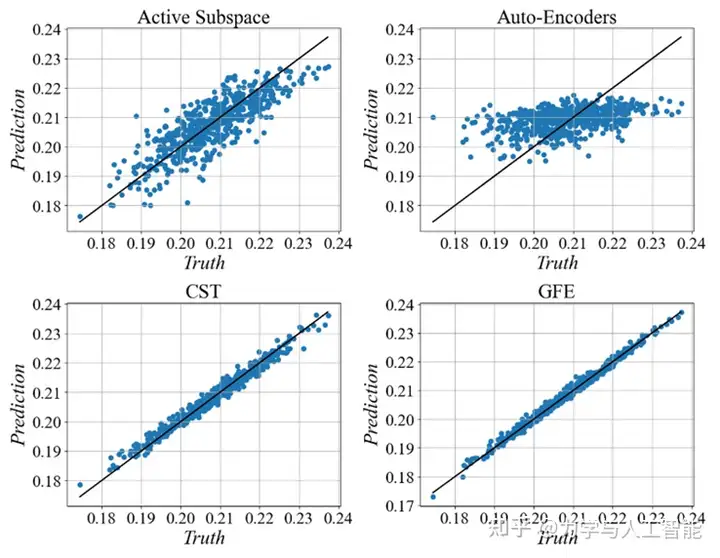
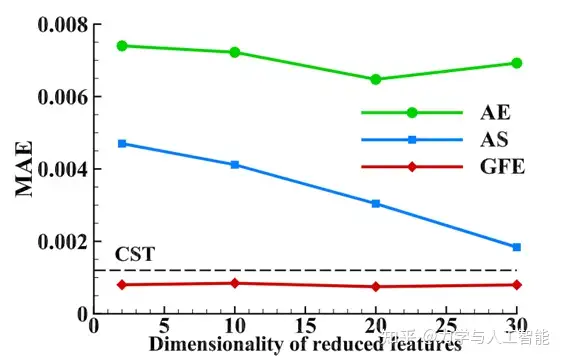
此外,我们还考虑了提取特征维度的影响。自编码器(AE)是一种典型的无监督降维方法。提取的特征与输出结果之间没有明显的联系,因此其准确性与特征维度无关。自适应采样(AS)和全局特征提取(GFE)是两种以目标为导向的方法。然而,AS方法倾向于降低维度,导致精度损失,而GFE则专注于提高建模精度。如图9所示,基于AS方法的建模精度随着维度的增加而增加,这是线性模型的一个典型特性。然而,AS方法的整体准确率低于CST参数化方法。这是因为AS会截断原始特征,从而导致整体精度的下降。在GFE的特征空间中,欧式距离表征了特征差异,使得特征维度变得不那么重要。研究结果显示,与AS方法不同,GFE对维度的变化不敏感。这些建模结果的比较充分展示了以目标为导向方法的独特性。从代理模型的准确性出发,GFE方法可以实现显著的精度提升。
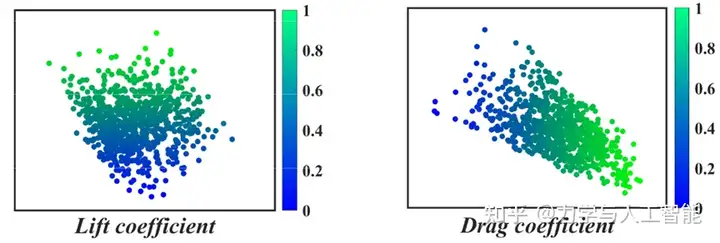
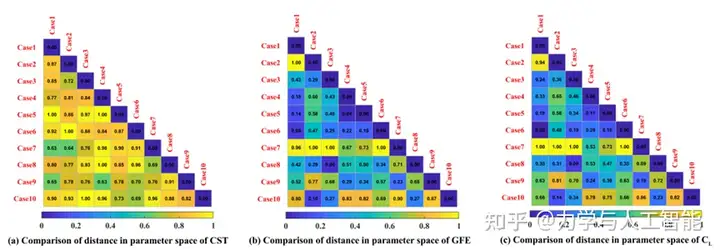
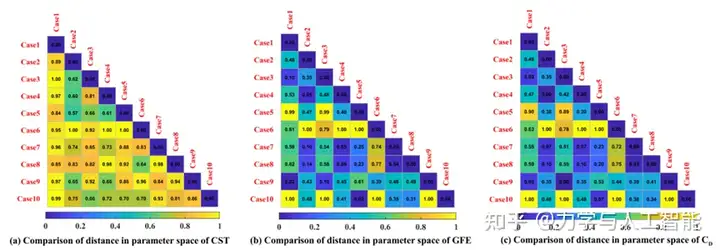
所提出的GFE方法通过限制隐藏特征之间的距离来训练神经网络。如图所示,传统CST参数之间的距离没有规律性,这使得CST参数与空气动力之间的映射关系是高维的和非线性的。使用建立的GFE模型,可以挖掘对应于CST参数的隐藏特征。如图10和图11中(b)和(c)之间的比较所示,提取的隐藏特征与目标气动力紧密相关。在这种情况下,代理模型的建模将得到增强。
我们分析了400个机翼的气动力预测结果,并比较了三种代理模型的建模精度。如图12和图13所示,横轴代表模型预测的平均绝对误差,纵轴代表误差区间内的统计结果。与原始的36维CST参数相比,通过GFE提取的二维特征构建的代理模型更为精确。通过比较,在提出的GFE方法下,最大预测误差显著降低,且误差区间更为集中。
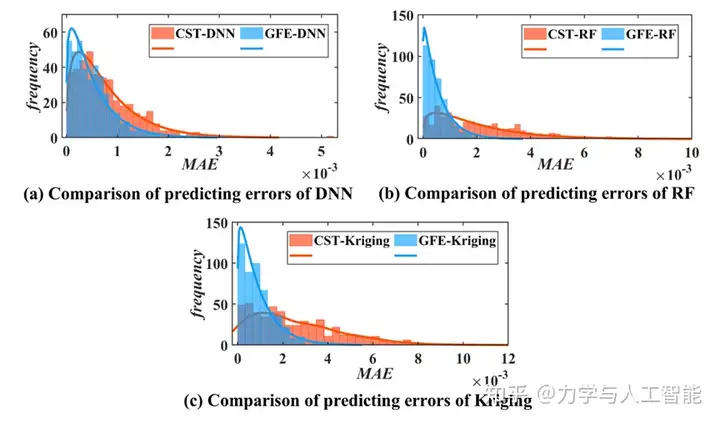
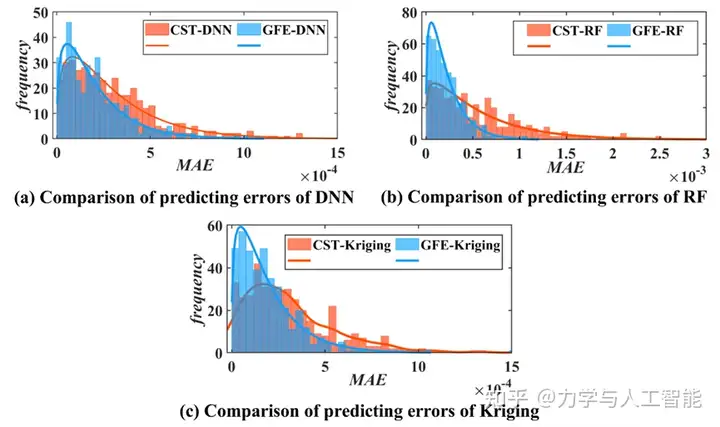
图14给出了预测误差的箱型图。GFE显著降低了整体预测误差。基于所提出的GFE的代理模型的准确性不依赖于所采用的方法类型和样本数量。针对目标导向的特征提取的有效性在不同的训练数据上得到了验证。
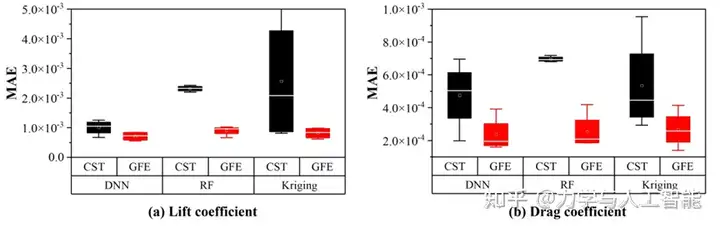
四、结论
在这项工作中,我们提出了一种通过提取隐藏特征来增强数据驱动代理模型的新思路。通过建立特征空间距离与目标输出之间的对比关系,提出了一个用于选择隐藏特征的标准。结合监督学习和无监督学习,我们建立了一个以目标为导向的特征提取神经网络。基于提取特征的数据驱动建模方法在数值和工程算例中得到验证。结果表明,所提出的特征提取方法可应用于各种代理模型。在数据不足的条件下,这些模型的建模精度和泛化能力也能获得显著提高。值得注意的是,这种方法不仅限于气动建模问题。GFE框架可以扩展到其他高维工程问题,为降维和小样本建模提供了一个通用解决方案。
- 在特征数据未知的情况下,可以通过对比学习实现GFE模型训练。与高维几何参数相比,GFE提取的特征之间的距离与输出数据的差异更为一致,即GFE降低了系统的维度和非线性。
- 基于提取的隐藏特征,各种数据驱动模型之间的泛化能力差异不再显著。各种建模方法之间的障碍减少,因此在数据驱动的建模问题中,模型选择将不再困难。因此,在数据驱动的代理模型建模中,特征提取应优先于模型选择。
- 工程算例表明,当样本不足时,基于特征提取的模型构建可以提高整体建模精度超过50%。同时,特征提取减少了数据驱动模型的数据需求,并帮助传统克里金模型在数据稀缺时达到最佳精度。
公众号原文链接(文末附论文资源):
AIAA J | 香港理工大学王旭等:目标导向的特征提取-以特征构建增强数据驱动模型
相关推荐:
AST |西北工业大学邬晓敬、左子俊等:基于多精度神经网络的电动飞机螺旋桨设计气动优化框架
ENG APPL COMP FLUID | 西工大马龙、邬晓敬等:无监督流形学习过滤几何特征的高效气动外形优化
注:文章由作者原创供稿,并获得作者授权发布。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)