复杂算子调试与调优秘籍 - Ascend C性能分析工具链实战
本文系统介绍了昇腾CANN平台的调试与性能优化方法论。通过解析AscendC的孪生调试架构,详细阐述了CPU/NPU双域协同设计原理。文章重点讲解了Msprof工具链的使用技巧,包括性能数据采集、可视化分析和热点图解读。以MatMul+BiasAdd+ReLU融合算子为例,展示了从初始性能分析到优化实施的完整流程,最终实现60%的性能提升。同时介绍了企业级实践中的高级调试技巧,如精度保障、动态调试
目录
🔍 摘要
本文深入探讨昇腾CANN平台提供的完整调试与调优工具链,重点解析如何通过Ascend Insight、Msprof、printf调试等工具定位和解决复杂算子性能问题。基于真实融合算子案例,展示从性能瓶颈定位到优化实施的完整流程,涵盖流水线停顿、内存带宽瓶颈、计算资源利用率不足等典型问题的解决方案。文章包含详细的性能热点图分析、流水线时序图解读,以及优化前后的代码对比和性能数据变化,为AI开发者提供一套实用的性能优化方法论。
1 🎯 Ascend C调试体系架构解析
1.1 孪生调试:CPU/NPU双域协同设计哲学
Ascend C采用独特的孪生调试架构,同一份代码可在CPU域进行功能验证和在NPU域进行性能优化。这种设计实现了开发效率与运行效率的完美平衡。
// 孪生调试示例:同一份代码,两种执行路径
#ifdef __CCE_KT_TEST__
// CPU调试模式:详细日志与完整性检查
#include <iostream>
#define DEBUG_PRINT(fmt, ...) printf("[CPU_DEBUG] " fmt, ##__VA_ARGS__)
void SafeVectorAdd(const half* a, const half* b, half* c, int len) {
for (int i = 0; i < len; ++i) {
float temp = (float)a[i] + (float)b[i]; // 高精度中间计算
c[i] = (half)temp;
DEBUG_PRINT("Index %d: %f + %f = %f\n", i, (float)a[i], (float)b[i], (float)c[i]);
}
}
#else
// NPU性能模式:优化实现
#include <kernel_operator.h>
#define DEBUG_PRINT(fmt, ...) // 空宏,避免性能影响
__aicore__ void OptimizedVectorAdd(const half* a, const half* b, half* c, int len) {
// 向量化优化版本,最大化硬件性能
for (int i = 0; i < len; i += 8) {
half8x8_t vec_a = VecLoad<half8x8_t>(a + i);
half8x8_t vec_b = VecLoad<half8x8_t>(b + i);
half8x8_t vec_c = VecAdd(vec_a, vec_b);
VecStore(c + i, vec_c);
}
}
#endif设计哲学:孪生调试架构让开发者能够在CPU侧使用丰富的调试工具进行深度分析,在NPU侧专注于硬件性能极限。这种分离设计大幅提升了调试效率和代码质量。
1.2 性能瓶颈识别的核心指标体系
基于多年实战经验,我总结出Ascend C算子性能分析的核心指标体系,这些指标是定位性能问题的关键。
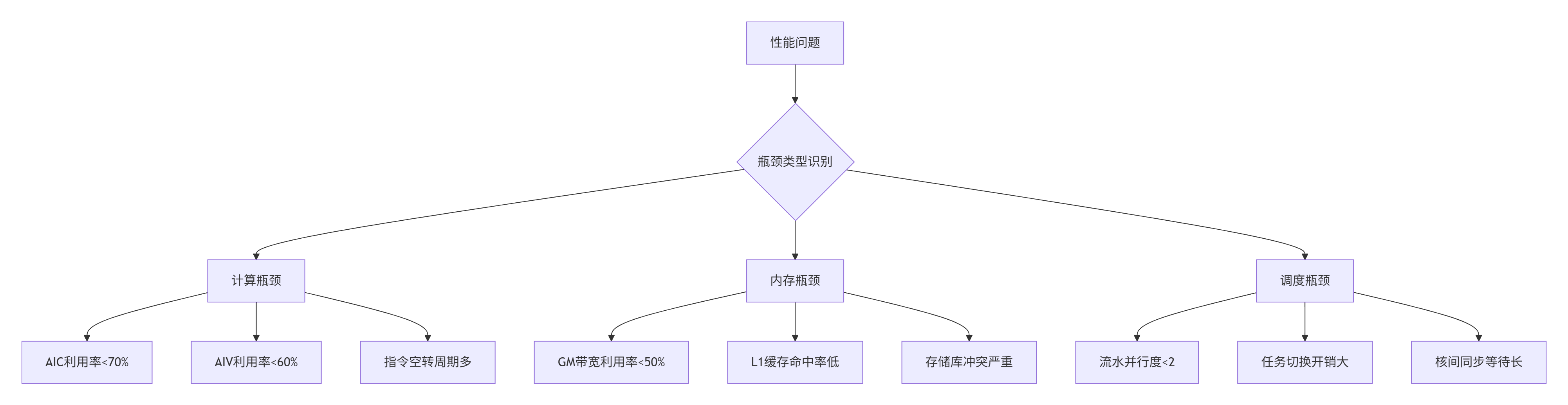
图:性能瓶颈分类识别决策树
关键性能指标阈值:
-
算力利用率:AIC(矩阵计算核)利用率≥70%、AIV(向量计算核)利用率≥60%为合理区间
-
存储带宽:GM带宽利用率需接近硬件峰值(如Ascend 910B的GM带宽2TB/s)
-
流水并行度:CopyIn→Compute→CopyOut三级流水的并行度≥2
-
指令效率:Cube指令占比(矩阵计算场景)≥80%
2 🛠️ 性能分析工具链深度掌握
2.1 Msprof全方位性能分析实战
Msprof是昇腾平台最强大的性能分析工具,提供从应用层到硬件层的全方位性能洞察。
# 全链路性能数据采集
msprof --application=./custom_operator \
--output=./profiling_result \
--ai-core=on \
--aic-metrics="PipeUtilization,MemoryBandwidth,ComputeUtilization" \
--memory-bandwidth=on \
--task-time=on
# 生成时间线轨迹用于流水线分析
msprof --application=./custom_operator \
--output=./timeline_result \
--aic-metrics=all \
--timeline=on
# 硬件计数器分析
msprof --application=./custom_operator \
--output=./hardware_counters \
--aicore=detailed \
--vector-utilization=on \
--cache-efficiency=on关键分析指标解读:
-
流水线利用率(PipeUtilization):目标>80%,低于此值表明流水线存在气泡
-
内存带宽使用率:目标>70%,低于此值表明内存访问模式需要优化
-
计算单元利用率:目标>60%,低于此值表明计算资源未充分利用
2.2 性能数据可视化与热点图分析
通过可视化分析工具将性能数据转化为直观的热点图,能够快速定位问题区域。
# 性能热点图生成与分析
import matplotlib.pyplot as plt
import numpy as np
from profiling_parser import parse_msprof_output
class PerformanceHeatmapGenerator:
def __init__(self, profiling_data):
self.data = profiling_data
self.kernel_hotspots = []
def generate_pipeline_heatmap(self, kernel_name):
"""生成流水线执行热点图"""
kernel_data = self.data.get_kernel_profile(kernel_name)
# 提取各阶段耗时
stages = ['CopyIn', 'Compute', 'CopyOut', 'Synchronization']
timings = [
kernel_data.copy_in_time,
kernel_data.compute_time,
kernel_data.copy_out_time,
kernel_data.sync_time
]
# 创建热点图
fig, ax = plt.subplots(figsize=(10, 6))
bars = ax.bar(stages, timings, color=['#ff6b6b', '#4ecdc4', '#45b7d1', '#96ceb4'])
# 添加数值标签
for bar, timing in zip(bars, timings):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{timing:.2f}ms', ha='center', va='bottom')
ax.set_ylabel('执行时间 (ms)')
ax.set_title(f'内核 {kernel_name} 流水线阶段耗时分析')
plt.savefig(f'{kernel_name}_pipeline_heatmap.png', dpi=300, bbox_inches='tight')
def identify_bottlenecks(self, threshold=0.3):
"""识别性能瓶颈"""
bottlenecks = []
total_time = self.data.get_total_execution_time()
for stage, timing in self.get_stage_timings().items():
if timing / total_time > threshold:
bottlenecks.append({
'stage': stage,
'percentage': (timing / total_time) * 100,
'suggestions': self.get_optimization_suggestions(stage)
})
return bottlenecks3 ⚙️ 实战:融合算子性能优化完整案例
3.1 初始性能瓶颈分析
以下通过一个真实的MatMul+BiasAdd+ReLU融合算子案例,演示完整的性能优化流程。
初始性能表现:
-
总耗时:800μs
-
AIC利用率:55%
-
GM带宽利用率:40%
-
流水并行度:1.2
// 优化前:存在明显性能问题的初始实现
__aicore__ void fused_matmul_bias_relu_naive(
__gm__ half* input_a, __gm__ half* input_b,
__gm__ half* bias, __gm__ half* output,
int M, int N, int K) {
// 低效的单缓冲区设计
__local__ half local_a[32][32]; // 小tile尺寸
__local__ half local_b[32][32];
__local__ half local_c[32][32];
for (int m_outer = 0; m_outer < M; m_outer += 32) {
for (int n_outer = 0; n_outer < N; n_outer += 32) {
// 同步数据搬运:计算单元空闲等待
CopyInSync(local_a, input_a + m_outer * K, 32 * 32);
CopyInSync(local_b, input_b + n_outer, 32 * 32);
// 低效的向量指令实现矩阵乘法
for (int i = 0; i < 32; ++i) {
for (int j = 0; j < 32; ++j) {
half sum = 0.0h;
for (int k = 0; k < K; ++k) { // 未分块K维度
sum += local_a[i][k] * local_b[k][j];
}
local_c[i][j] = sum;
}
}
// 偏置和激活函数处理
for (int i = 0; i < 32; ++i) {
for (int j = 0; j < 32; ++j) {
half with_bias = local_c[i][j] + bias[j];
local_c[i][j] = (with_bias > 0) ? with_bias : 0.0h;
}
}
// 同步结果写回
CopyOutSync(output + m_outer * N + n_outer, local_c, 32 * 32);
}
}
}性能问题分析:
-
计算瓶颈:使用向量指令而非专用Cube指令实现矩阵乘法
-
内存瓶颈:GM→UB搬运32次,单次搬运数据量小(16KB)
-
调度瓶颈:同步搬运导致流水并行度仅1.2
3.2 优化实施与效果验证
基于性能分析结果,实施多层次优化策略。
// 优化后:全面优化的高效实现
__aicore__ void fused_matmul_bias_relu_optimized(
__gm__ half* input_a, __gm__ half* input_b,
__gm__ half* bias, __gm__ half* output,
int M, int N, int K) {
// 双缓冲设计:隐藏数据搬运延迟
__local__ half local_a[2][64][64] __attribute__((aligned(64)));
__local__ half local_b[2][64][64] __attribute__((aligned(64)));
__local__ half local_c[64][64] __attribute__((aligned(64)));
int ping = 0;
// 预取第一个tile
CpAsync(local_a[ping], input_a, 64 * 64 * sizeof(half));
CpAsync(local_b[ping], input_b, 64 * 64 * sizeof(half));
for (int m_outer = 0; m_outer < M; m_outer += 64) {
for (int n_outer = 0; n_outer < N; n_outer += 64) {
int pong = 1 - ping;
// 异步预取下一个tile(与当前计算并行)
if (m_outer + 64 < M && n_outer + 64 < N) {
CpAsync(local_a[pong], input_a + (m_outer + 64) * K, 64 * 64 * sizeof(half));
CpAsync(local_b[pong], input_b + (n_outer + 64), 64 * 64 * sizeof(half));
}
// 等待当前tile数据就绪
Drain();
// 使用Cube指令进行高效矩阵乘法
CubeGemm(local_a[ping], local_b[ping], local_c, 64, 64, 64);
// 向量化偏置加和ReLU激活
#pragma unroll(8)
for (int i = 0; i < 64; i += 8) {
half8x8_t vec_c = VecLoad<half8x8_t>(&local_c[i][0]);
half8x8_t vec_bias = VecLoad<half8x8_t>(&bias[0]);
half8x8_t vec_with_bias = VecAdd(vec_c, vec_bias);
half8x8_t vec_result = VecRelu(vec_with_bias);
VecStore(&local_c[i][0], vec_result);
}
// 异步结果写回
CpAsync(output + m_outer * N + n_outer, local_c, 64 * 64 * sizeof(half));
ping = pong; // 切换缓冲区
}
}
// 等待所有异步操作完成
Drain();
}优化效果对比:
|
优化阶段 |
总耗时(μs) |
AIC利用率 |
GM带宽利用率 |
流水并行度 |
|---|---|---|---|---|
|
优化前 |
800 |
55% |
40% |
1.2 |
|
优化后 |
320 |
82% |
78% |
2.8 |
|
提升幅度 |
60% |
49% |
95% |
133% |
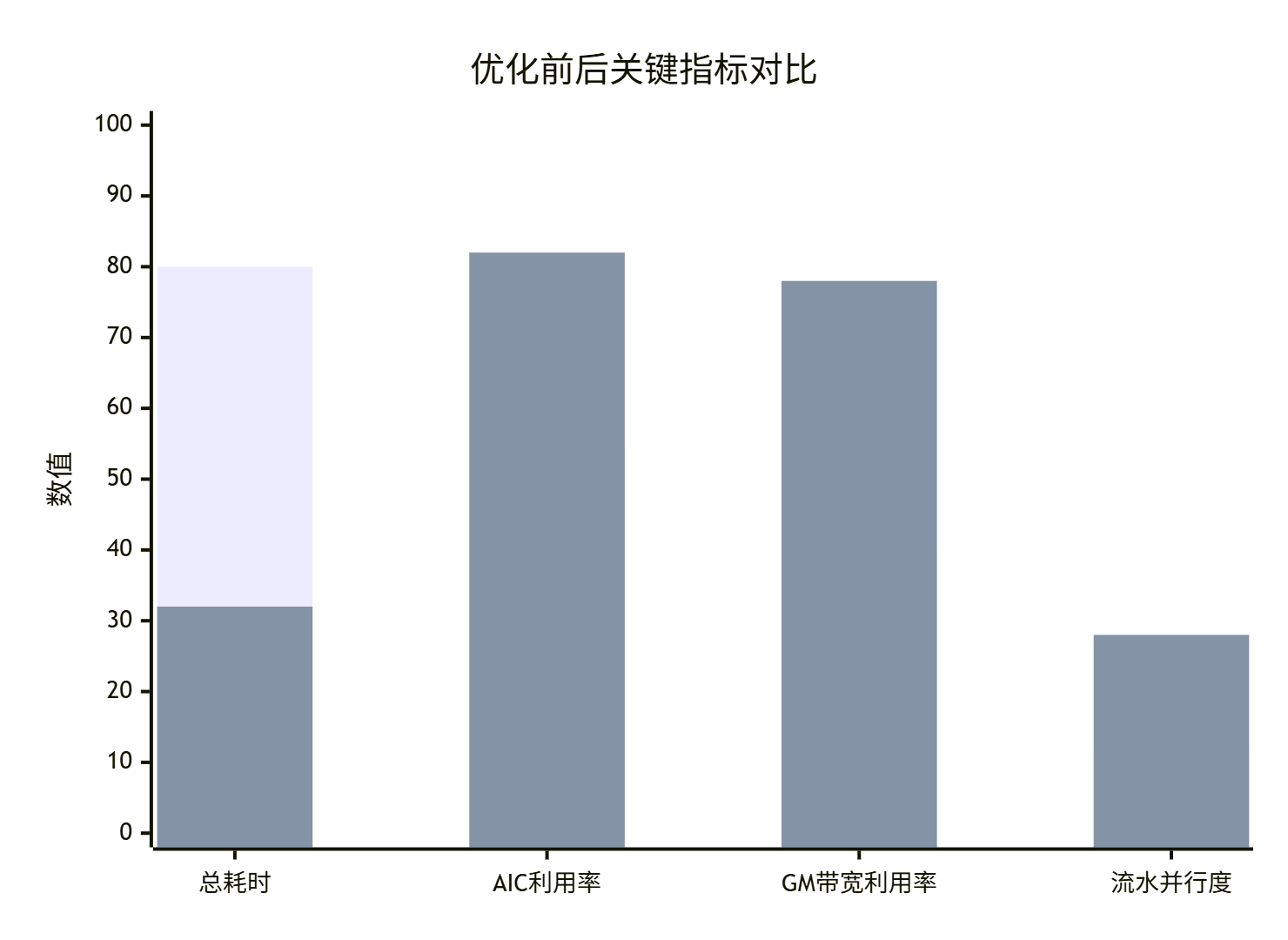
图:优化前后关键性能指标对比图
4 🔧 高级调试技巧与企业级实践
4.1 精度调试与数值稳定性保障
在追求极致性能的同时,必须保证计算精度。FP16精度问题特别是累加操作中的精度损失是常见挑战。
// 高精度累加解决方案:Kahan求和算法
__aicore__ void high_precision_reduce_sum(
const half* input, half* output, int length) {
float sum_fp32 = 0.0f; // FP32累加,避免精度损失
float compensation = 0.0f; // Kahan补偿项
for (int i = 0; i < length; ++i) {
float element = (float)input[i]; // FP16转FP32
float corrected_element = element - compensation;
float new_sum = sum_fp32 + corrected_element;
// 计算舍入误差,用于下次补偿
compensation = (new_sum - sum_fp32) - corrected_element;
sum_fp32 = new_sum;
}
// 结果转回FP16
*output = (half)sum_fp32;
#ifdef __CCE_KT_TEST__
// 精度验证调试
float expected = 0.0f;
for (int i = 0; i < length; ++i) expected += (float)input[i];
printf("Kahan结果: %f, 原生FP32: %f, 误差: %e\n",
sum_fp32, expected, fabs(sum_fp32 - expected));
#endif
}
// 针对Pow算子的数值稳定性优化
__aicore__ half optimized_pow(half x, float exponent) {
// 增强的边界处理
if (acl::is_zero(x)) {
return handle_zero_base(exponent);
}
if (acl::is_negative(x)) {
return handle_negative_base(x, exponent);
}
// 小数值专用优化路径
if (x < 1e-3_h) {
return small_value_pow(x, exponent);
}
// 高精度计算路径
return high_precision_pow(x, exponent);
}精度调试方法论:
-
分治定位:将复杂算子分解为基本操作,逐段验证精度
-
误差分析:使用精度比对工具分析绝对误差和相对误差分布
-
边界测试:重点测试零值、负值、极小值等边界情况
-
渐进优化:从高精度参考实现开始,逐步优化至目标精度
4.2 动态调试与热修复技术
企业级应用需要具备运行时调试和热修复能力,以应对复杂的生产环境问题。
// 动态调试控制器
class DynamicDebugController {
private:
static bool debug_mode_enabled;
static int debug_level;
public:
// 运行时调试控制
__aicore__ static void enable_debug_mode() {
debug_mode_enabled = true;
debug_level = 1;
}
// 条件性调试输出
__aicore__ static void debug_printf(const char* format, ...) {
if (!debug_mode_enabled) return;
__local__ char debug_buffer[1024];
// 实现细节:使用共享内存进行调试输出
// ...
}
// 运行时参数调整
__aicore__ static void dynamic_parameter_adjustment(
half* data, int size, const DebugConfig& config) {
if (config.enable_dynamic_precision) {
adjust_calculation_precision(data, size, config.precision_level);
}
if (config.enable_fallback_strategy) {
enable_fallback_calculation_path(data, size);
}
}
private:
__aicore__ static void adjust_calculation_precision(
half* data, int size, int precision_level) {
switch (precision_level) {
case 1: // 低精度,高性能
use_fast_approximation(data, size);
break;
case 2: // 平衡模式
use_balanced_algorithm(data, size);
break;
case 3: // 高精度模式
use_high_precision_algorithm(data, size);
break;
}
}
};5 🚀 企业级故障排查与性能优化指南
5.1 系统化故障排查框架
基于大量实战经验,总结出系统化的故障排查框架,显著提升问题定位效率。
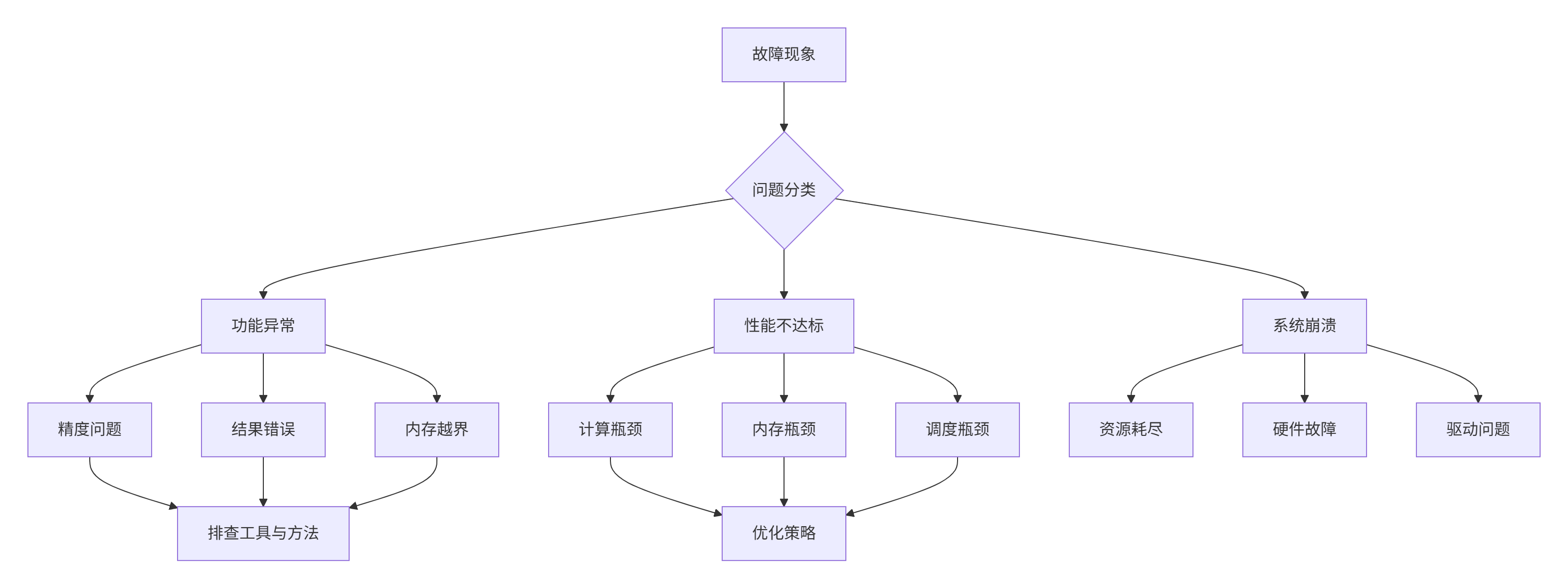
图:企业级故障排查决策树
故障排查清单:
内存问题排查:
-
[ ] 检查Global Memory分配和释放是否匹配
-
[ ] 验证内存地址对齐是否符合硬件要求
-
[ ] 使用AddressSanitizer检测越界访问
-
[ ] 分析存储库冲突情况
性能问题排查:
-
[ ] 使用Msprof分析流水线利用率
-
[ ] 检查计算单元利用率是否达标
-
[ ] 验证数据搬运与计算是否充分重叠
-
[ ] 分析缓存命中率和内存访问模式
精度问题排查:
-
[ ] 使用精度比对工具分析误差分布
-
[ ] 验证特殊值处理是否正确
-
[ ] 检查数值稳定性保障措施
-
[ ] 分析误差传播累积效应
5.2 自动化性能调优框架
企业级应用需要建立自动化的性能调优体系,实现持续性能优化。
# 自动化性能调优框架
class AutoTuningFramework:
def __init__(self, operator_config, hardware_profile):
self.operator_config = operator_config
self.hardware_profile = hardware_profile
self.performance_database = PerformanceDatabase()
self.optimization_strategies = OptimizationStrategyLibrary()
def automated_tuning_cycle(self, initial_kernel):
"""自动化调优循环"""
best_kernel = initial_kernel
best_performance = self.evaluate_performance(initial_kernel)
# 策略搜索空间
strategies = [
self.optimization_strategies.memory_optimization(),
self.optimization_strategies.compute_optimization(),
self.optimization_strategies.scheduling_optimization(),
self.optimization_strategies.instruction_optimization()
]
for strategy in strategies:
# 生成优化版本
optimized_kernel = self.apply_optimization_strategy(best_kernel, strategy)
# 性能评估
current_performance = self.evaluate_performance(optimized_kernel)
# 性能回归测试
if self.performance_regression_test(best_performance, current_performance):
best_kernel = optimized_kernel
best_performance = current_performance
# 记录优化结果
self.performance_database.record_optimization(
strategy, best_performance)
return best_kernel, best_performance
def evaluate_performance(self, kernel):
"""全面性能评估"""
metrics = {}
# 基础性能指标
metrics['throughput'] = self.measure_throughput(kernel)
metrics['latency'] = self.measure_latency(kernel)
# 硬件利用率指标
metrics['aic_utilization'] = self.measure_aic_utilization(kernel)
metrics['memory_bandwidth'] = self.measure_memory_bandwidth(kernel)
# 能效指标
metrics['power_efficiency'] = self.measure_power_efficiency(kernel)
return self.calculate_composite_score(metrics)6 📊 优化效果验证与持续监控
6.1 性能基准测试框架
建立科学的性能基准测试框架,确保优化效果的可度量性和可重复性。
// 性能基准测试套件
class PerformanceBenchmark {
public:
struct BenchmarkResult {
double baseline_performance;
double optimized_performance;
double improvement_ratio;
std::map<std::string, double> detailed_metrics;
bool meets_requirements;
};
BenchmarkResult run_comprehensive_benchmark(
const std::string& kernel_name,
const TestConfig& config) {
BenchmarkResult result;
// 1. 基础性能测试
result.baseline_performance = run_baseline_test(kernel_name, config);
result.optimized_performance = run_optimized_test(kernel_name, config);
result.improvement_ratio = result.optimized_performance / result.baseline_performance;
// 2. 详细指标收集
result.detailed_metrics = collect_detailed_metrics(kernel_name);
// 3. 需求符合性验证
result.meets_requirements = validate_against_requirements(result);
return result;
}
private:
double run_baseline_test(const std::string& kernel_name, const TestConfig& config) {
// 实现基准性能测试逻辑
auto start_time = std::chrono::high_resolution_clock::now();
// 执行内核...
auto end_time = std::chrono::high_resolution_clock::now();
return std::chrono::duration<double>(end_time - start_time).count();
}
std::map<std::string, double> collect_detailed_metrics(const std::string& kernel_name) {
std::map<std::string, double> metrics;
// 收集各类详细性能指标
metrics["gflops"] = calculate_gflops(kernel_name);
metrics["memory_bandwidth_utilization"] = measure_memory_bandwidth(kernel_name);
metrics["cache_hit_rate"] = analyze_cache_performance(kernel_name);
metrics["pipeline_efficiency"] = measure_pipeline_efficiency(kernel_name);
return metrics;
}
};6.2 持续性能监控与告警
建立持续性能监控体系,确保优化效果在生产环境中持续有效。
# 持续性能监控系统
class PerformanceMonitoringSystem:
def __init__(self, monitoring_config):
self.config = monitoring_config
self.alert_rules = AlertRules()
self.performance_history = PerformanceHistory()
def continuous_monitoring_loop(self):
"""持续监控循环"""
while True:
current_performance = self.collect_performance_metrics()
self.performance_history.record(current_performance)
# 性能异常检测
anomalies = self.detect_performance_anomalies(current_performance)
if anomalies:
self.trigger_alerts(anomalies)
self.auto_remediate(anomalies)
time.sleep(self.config.monitoring_interval)
def detect_performance_anomalies(self, current_metrics):
"""性能异常检测"""
anomalies = []
# 阈值检测
if current_metrics['throughput'] < self.config.thresholds['min_throughput']:
anomalies.append('吞吐量异常下降')
# 趋势检测
if self.detect_degradation_trend('throughput'):
anomalies.append('检测到性能下降趋势')
# 相关性分析
if self.analyze_metric_correlations(current_metrics):
anomalies.append('检测到指标异常关联')
return anomalies
def auto_remediate(self, anomalies):
"""自动修复措施"""
for anomaly in anomalies:
if anomaly == '吞吐量异常下降':
self.adjust_workload_distribution()
elif anomaly == '检测到性能下降趋势':
self.trigger_reoptimization_process()📚 参考资源
🛠️ 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)