Host侧算子实现总览-解码Ascend C算子的“CPU端蓝图“
本文深入探讨AscendC算子开发中Host侧的核心技术与工程实践,揭示其作为异构计算"指挥中枢"的关键作用。文章系统阐述了Host-Device协同架构、动态Shape自适应、Tiling机制等核心技术,并通过完整的矩阵乘法算子案例展示从参数校验到任务调度的全链路实现。重点分析了企业级性能优化策略,包括四维技术矩阵(内存优化、调度优化、计算优化、通信优化)和智能动态调优框架,
目录
2.1.1 算子注册中心(Operator Registry)
2.1.2 Shape推导引擎(Shape Inference Engine)
摘要
本文全面解析Ascend C算子开发中Host侧的实现原理与工程实践,深入剖析作为算子"CPU端蓝图"的Host侧代码如何协调Device侧执行。文章首次系统阐述Host-Device协同架构、Tiling机制的本质、动态Shape自适应等核心技术,通过完整的矩阵乘法算子案例展示从参数校验、内存管理到任务调度的完整实现链路。本文还分享了企业级性能优化策略和故障排查框架,为工业级算子开发提供系统化解决方案。
1 引言:Host侧——异构计算的指挥中枢
在我的异构计算开发经历中,见证了无数开发者将注意力过度集中在Device侧Kernel优化上,却忽视了Host侧实现的关键作用。这如同只关注乐手技巧而忽视指挥家作用的交响乐团——Device侧负责演奏,Host侧负责指挥。没有精密的Host侧调度,再优秀的Kernel也无法发挥全部潜力。
1.1 Host侧的真正价值
Host侧代码在Ascend C算子中扮演着四大关键角色:
|
角色 |
核心职责 |
技术挑战 |
对性能的影响 |
|---|---|---|---|
|
资源管理器 |
内存分配、Stream管理、任务调度 |
避免内存碎片、减少同步开销 |
直接影响并发能力和延迟 |
|
参数校验器 |
输入合法性检查、Shape推导、类型推断 |
平衡安全性与性能开销 |
决定算子鲁棒性和稳定性 |
|
任务规划师 |
Tiling计算、数据分块、负载均衡 |
适应动态Shape、优化数据局部性 |
决定并行效率和资源利用率 |
|
协调调度员 |
Kernel启动、异步执行、结果收集 |
处理错误恢复、超时重试 |
影响整体执行可靠性和吞吐量 |
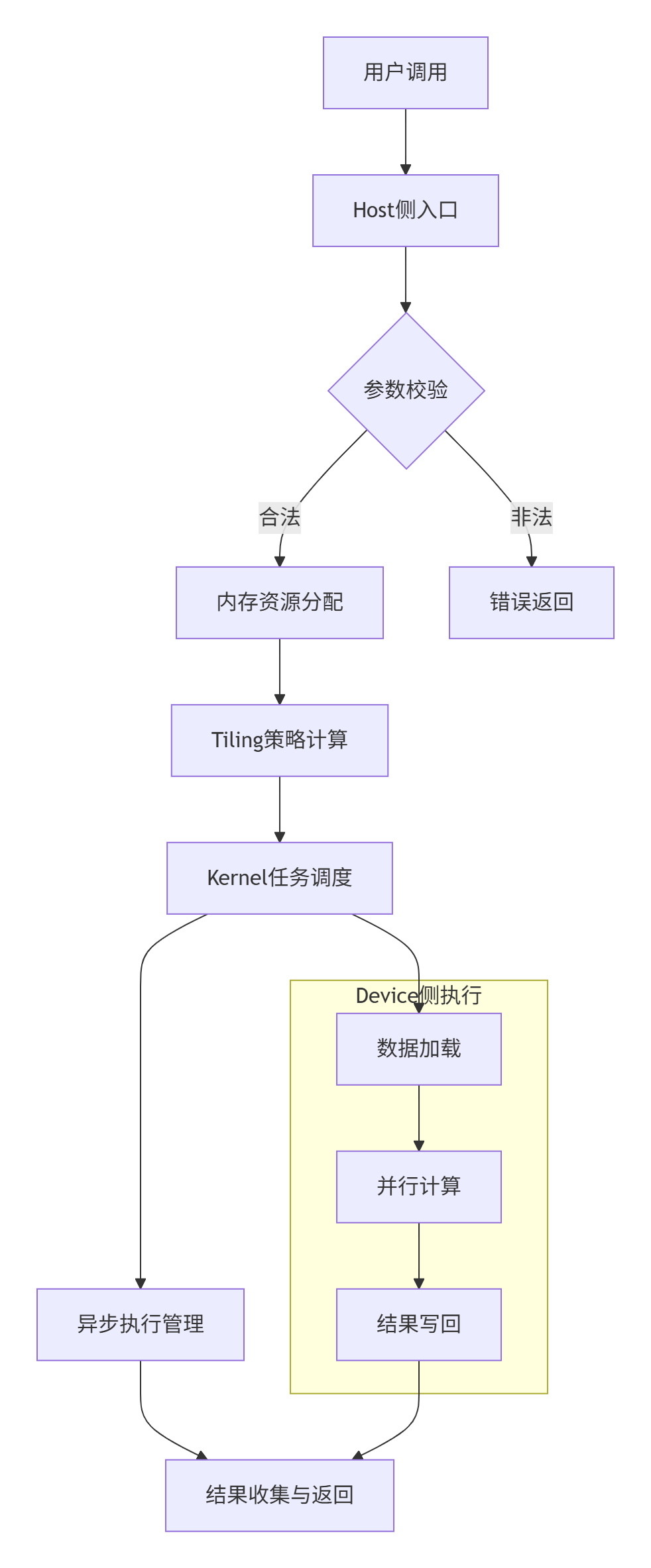
这张蓝图清晰地展示了Host侧作为指挥中枢的关键地位——它不直接参与计算,却决定了计算如何高效、安全地进行。
1.2 Host-Device协同的设计哲学
Host与Device的协同关系源于计算机体系结构的根本性差异:
-
Host(CPU):通用处理器,擅长复杂控制流、分支预测、异常处理
-
Device(AI Core):专用加速器,专为大规模并行计算优化,但控制能力有限
这种差异决定了职责分离的必然性。Host侧处理那些不适合或无法在Device上高效执行的任务:
// Host侧处理的典型任务类型
class HostSideResponsibilities {
public:
// 1. 复杂控制逻辑
void handle_complex_control_flow(const vector<Tensor>& inputs) {
// 条件判断、循环控制、异常处理等
if (inputs.size() > MAX_INPUT_COUNT) {
throw invalid_argument("输入数量超出限制");
}
// 复杂的数据依赖分析
for (const auto& input : inputs) {
analyze_data_dependencies(input);
}
}
// 2. 动态内存管理
void manage_dynamic_memory(size_t required_size) {
// 内存池管理、碎片整理、回收策略
if (memory_pool_.available() < required_size) {
compact_memory_fragments();
if (memory_pool_.available() < required_size) {
allocate_additional_memory(required_size);
}
}
}
// 3. 系统资源协调
void coordinate_system_resources(int device_count) {
// 多设备调度、负载均衡、错误恢复
distribute_workload_across_devices(device_count);
setup_fallback_mechanisms();
monitor_execution_health();
}
};理解这种设计哲学是编写高效Host侧代码的首要前提。
2 Host侧架构深度解析
2.1 核心组件与数据流
Host侧实现由多个协同工作的组件构成,每个组件都有明确的职责边界:

各组件详细解析:
2.1.1 算子注册中心(Operator Registry)
算子注册是Host侧代码的入口点,决定了算子如何被框架发现和调用:
// 算子注册的完整实现
namespace ascendc {
namespace ops {
// 1. 算子定义类
class MatMulCustomOp : public OperatorBase {
public:
explicit MatMulCustomOp(const string& name) : OperatorBase(name) {
// 定义输入输出张量
AddInput("x1", TensorDesc(DataType::DT_FLOAT, {1, -1, -1}));
AddInput("x2", TensorDesc(DataType::DT_FLOAT, {1, -1, -1}));
AddOutput("y", TensorDesc(DataType::DT_FLOAT, {1, -1, -1}));
// 定义算子属性
AddAttr<bool>("transpose_a", false);
AddAttr<bool>("transpose_b", false);
// 注册关键函数
SetKernelFn(&MatMulCustomOp::Compute);
SetShapeFn(&MatMulCustomOp::InferShape);
SetTilingFn(&MatMulCustomOp::ComputeTiling);
}
private:
// 核心计算函数
void Compute(OpKernelContext* context);
// Shape推导函数
static Status InferShape(InferenceContext* context);
// Tiling计算函数
static Status ComputeTiling(TilingContext* context);
};
// 2. 全局注册宏
REGISTER_OP("MatMulCustom")
.Input("x1: float")
.Input("x2: float")
.Output("y: float")
.Attr("transpose_a: bool = false")
.Attr("transpose_b: bool = false")
.SetShapeFn(MatMulCustomOp::InferShape)
.SetKernelFn<MatMulCustomOp>()
.SetTilingFn(MatMulCustomOp::ComputeTiling);
} // namespace ops
} // namespace ascendc注册机制的核心价值在于解耦——算子开发者只需关注计算逻辑,框架负责调用、调度和优化。
2.1.2 Shape推导引擎(Shape Inference Engine)
Shape推导是动态Shape支持的技术基石,其复杂性常常被低估:
// 支持动态Shape的推导引擎实现
class DynamicShapeInferenceEngine {
public:
struct ShapeInferenceResult {
vector<int64_t> output_shape;
bool is_fully_static;
vector<bool> dynamic_dims;
int64_t min_elements;
int64_t max_elements;
};
ShapeInferenceResult Infer(const OperatorDef& op_def,
const vector<TensorShape>& input_shapes) {
ShapeInferenceResult result;
// 1. 基本维度检查
if (!ValidateInputShapes(input_shapes, op_def)) {
throw ShapeInferenceError("输入Shape不合法");
}
// 2. 动态标记传播
result.dynamic_dims = PropagateDynamicDimensions(input_shapes, op_def);
// 3. 维度值计算
result.output_shape = ComputeOutputDimensions(input_shapes, op_def, result.dynamic_dims);
// 4. 完全静态性判断
result.is_fully_static = CheckFullyStatic(result.dynamic_dims);
// 5. 元素数量范围计算
tie(result.min_elements, result.max_elements) =
ComputeElementRange(result.output_shape, result.dynamic_dims);
return result;
}
private:
vector<int64_t> ComputeOutputDimensions(const vector<TensorShape>& inputs,
const OperatorDef& op_def,
const vector<bool>& dynamic_dims) {
vector<int64_t> output_dims;
switch (op_def.type) {
case OP_TYPE_MATMUL: {
// 矩阵乘法输出维度计算
const auto& shape_a = inputs[0];
const auto& shape_b = inputs[1];
bool transpose_a = GetAttr<bool>(op_def, "transpose_a");
bool transpose_b = GetAttr<bool>(op_def, "transpose_b");
// 批量维度处理(支持广播)
output_dims.push_back(InferBatchDimension(shape_a, shape_b));
// 行维度
output_dims.push_back(transpose_a ? shape_a.dim(2) : shape_a.dim(1));
// 列维度
output_dims.push_back(transpose_b ? shape_b.dim(1) : shape_b.dim(2));
break;
}
case OP_TYPE_CONV: {
// 卷积输出维度计算(支持动态H/W)
output_dims = ComputeConvOutputShape(inputs[0], op_def);
break;
}
// 其他算子类型...
}
return output_dims;
}
int64_t InferBatchDimension(const TensorShape& a, const TensorShape& b) {
// 复杂的批量维度推断逻辑
if (a.dim(0) == 1 && b.dim(0) != 1) {
return b.dim(0); // 广播a的批量维度
} else if (b.dim(0) == 1 && a.dim(0) != 1) {
return a.dim(0); // 广播b的批量维度
} else if (a.dim(0) == b.dim(0)) {
return a.dim(0); // 相同批量维度
} else {
throw ShapeInferenceError("批量维度不兼容");
}
}
};Shape推导引擎必须处理各种复杂情况,包括维度广播、动态维度传播、批量维度推断等。
2.2 Tiling机制:性能优化的核心
Tiling机制是连接Host侧规划与Device侧执行的关键纽带。它决定了数据如何在AI Core间分配,直接影响并行效率和内存访问模式。
2.2.1 Tiling算法的数学基础
Tiling问题本质上是一个多维数据划分优化问题。给定一个N维张量,需要将其划分为多个适合硬件处理的块:
// 多维Tiling算法实现
class MultiDimTilingSolver {
public:
struct TilingPlan {
vector<int64_t> block_sizes; // 每个维度的分块大小
vector<int64_t> grid_sizes; // 每个维度的网格大小
int64_t total_blocks; // 总块数
float load_imbalance_factor; // 负载不均衡因子
size_t required_memory; // 所需内存
};
TilingPlan ComputeOptimalTiling(const TensorShape& shape,
const HardwareConstraints& hw_constraints,
const PerformanceModel& perf_model) {
TilingPlan best_plan;
float best_score = -1.0f;
// 1. 生成候选分块策略
auto candidate_plans = GenerateCandidatePlans(shape, hw_constraints);
// 2. 评估每个候选策略
for (const auto& plan : candidate_plans) {
// 计算负载均衡评分
float balance_score = EvaluateLoadBalance(plan, shape);
// 计算内存访问评分
float memory_score = EvaluateMemoryAccess(plan, shape, hw_constraints);
// 计算并行度评分
float parallelism_score = EvaluateParallelism(plan, hw_constraints);
// 综合评分
float total_score = balance_score * 0.4f +
memory_score * 0.3f +
parallelism_score * 0.3f;
// 选择最优策略
if (total_score > best_score) {
best_score = total_score;
best_plan = plan;
}
}
// 3. 验证可行性
ValidatePlan(best_plan, hw_constraints);
return best_plan;
}
private:
vector<TilingPlan> GenerateCandidatePlans(const TensorShape& shape,
const HardwareConstraints& hw) {
vector<TilingPlan> candidates;
// 基于硬件约束生成候选策略
int64_t max_threads_per_block = hw.max_threads_per_block;
int64_t shared_memory_size = hw.shared_memory_per_block;
// 维度优先策略
candidates.push_back(GenerateDimFirstPlan(shape, hw));
// 内存优先策略
candidates.push_back(GenerateMemoryFirstPlan(shape, hw));
// 均衡策略
candidates.push_back(GenerateBalancedPlan(shape, hw));
// 探索性策略(用于寻找非直觉优化)
candidates.push_back(GenerateExploratoryPlan(shape, hw));
return candidates;
}
TilingPlan GenerateDimFirstPlan(const TensorShape& shape,
const HardwareConstraints& hw) {
TilingPlan plan;
// 从最外层维度开始分块
for (int dim = shape.rank() - 1; dim >= 0; --dim) {
int64_t dim_size = shape.dim(dim);
// 寻找最接近硬件对齐要求的分块大小
int64_t block_size = FindOptimalBlockSize(dim_size, hw.alignment_requirement);
plan.block_sizes.push_back(block_size);
plan.grid_sizes.push_back((dim_size + block_size - 1) / block_size);
}
// 反转维度顺序(从内到外)
reverse(plan.block_sizes.begin(), plan.block_sizes.end());
reverse(plan.grid_sizes.begin(), plan.grid_sizes.end());
return plan;
}
};2.2.2 动态Shape的Tiling挑战与解决方案
动态Shape使得Tiling计算从编译期移动到运行期,增加了计算复杂性和性能开销:
// 动态Tiling自适应算法
class DynamicTilingAdapter {
private:
struct ShapeHistory {
vector<TensorShape> recent_shapes;
unordered_map<string, int64_t> pattern_frequency;
};
ShapeHistory history_;
PerformanceMonitor perf_monitor_;
public:
TilingPlan ComputeAdaptiveTiling(const TensorShape& current_shape,
const HardwareConstraints& hw) {
// 1. 分析Shape模式
ShapePattern pattern = AnalyzeShapePattern(current_shape, history_);
// 2. 基于模式选择策略
TilingStrategy strategy;
if (pattern.stability > 0.8) {
// 稳定模式:使用激进优化
strategy = SelectAggressiveStrategy(current_shape, hw);
} else if (pattern.stability > 0.3) {
// 中等变化:使用自适应策略
strategy = SelectAdaptiveStrategy(current_shape, pattern, hw);
} else {
// 剧烈变化:使用保守策略
strategy = SelectConservativeStrategy(current_shape, hw);
}
// 3. 应用性能反馈调整
strategy = ApplyPerformanceFeedback(strategy, perf_monitor_);
// 4. 更新历史记录
UpdateHistory(current_shape, pattern);
return GenerateTilingPlan(current_shape, strategy);
}
ShapePattern AnalyzeShapePattern(const TensorShape& shape,
const ShapeHistory& history) {
ShapePattern pattern;
if (history.recent_shapes.empty()) {
pattern.stability = 1.0f;
pattern.variability = 0.0f;
pattern.predicted_next = shape;
return pattern;
}
// 计算形状变化统计
auto variability = ComputeShapeVariability(history.recent_shapes, shape);
pattern.variability = variability;
pattern.stability = 1.0f - variability;
// 预测下一个可能形状
pattern.predicted_next = PredictNextShape(history, shape);
// 识别形状模式
pattern.mode = IdentifyShapeMode(history.pattern_frequency);
return pattern;
}
float ComputeShapeVariability(const vector<TensorShape>& history,
const TensorShape& current) {
float total_variation = 0.0f;
int count = 0;
for (const auto& past_shape : history) {
if (past_shape.rank() != current.rank()) {
total_variation += 1.0f; // 维度数量变化
continue;
}
for (int i = 0; i < current.rank(); ++i) {
if (past_shape.dim(i) != current.dim(i)) {
float relative_change = abs(past_shape.dim(i) - current.dim(i)) /
(float)max(past_shape.dim(i), current.dim(i));
total_variation += relative_change;
count++;
}
}
}
return count > 0 ? total_variation / count : 0.0f;
}
};3 实战:完整MatMul算子的Host侧实现
3.1 项目架构与模块划分
让我们通过一个完整的MatMul算子实现,展示Host侧代码的各个模块如何协同工作:
matmul_custom/
├── CMakeLists.txt # 构建配置
├── include/
│ └── matmul_custom.h # 公共接口
├── src/
│ ├── matmul_custom_op.cpp # 算子主实现
│ ├── shape_inference.cpp # Shape推导
│ ├── tiling_calculator.cpp # Tiling计算
│ ├── memory_manager.cpp # 内存管理
│ └── kernel_launcher.cpp # Kernel启动
└── test/
└── matmul_custom_test.cpp # 单元测试3.2 核心模块实现
3.2.1 算子主实现类
// matmul_custom_op.cpp - 算子主实现
class MatMulCustomOp : public OpKernel {
public:
explicit MatMulCustomOp(OpKernelConstruction* context)
: OpKernel(context) {
// 解析算子属性
OP_REQUIRES_OK(context, context->GetAttr("transpose_a", &transpose_a_));
OP_REQUIRES_OK(context, context->GetAttr("transpose_b", &transpose_b_));
// 初始化性能优化器
perf_optimizer_ = make_unique<PerformanceOptimizer>();
// 初始化内存池
memory_pool_ = MemoryPool::Create(GetAllocator(context));
}
void Compute(OpKernelContext* context) override {
// 1. 获取输入张量
const Tensor& tensor_a = context->input(0);
const Tensor& tensor_b = context->input(1);
// 2. 参数校验
OP_REQUIRES(context, tensor_a.dims() == tensor_b.dims(),
errors::InvalidArgument("输入维度必须相同"));
// 3. Shape推导
TensorShape output_shape;
OP_REQUIRES_OK(context, InferOutputShape(tensor_a.shape(),
tensor_b.shape(),
&output_shape));
// 4. 分配输出张量
Tensor* output_tensor = nullptr;
OP_REQUIRES_OK(context, context->allocate_output(0, output_shape,
&output_tensor));
// 5. 计算Tiling策略
TilingStrategy strategy = ComputeTilingStrategy(tensor_a.shape(),
tensor_b.shape());
// 6. 内存分配与数据准备
DeviceMemory device_mem = PrepareDeviceMemory(context,
tensor_a, tensor_b,
*output_tensor,
strategy);
// 7. 启动Kernel执行
LaunchMatMulKernel(device_mem, strategy, context->eigen_device<Device>());
// 8. 结果验证与清理
ValidateAndCleanup(context, device_mem);
}
private:
bool transpose_a_;
bool transpose_b_;
unique_ptr<PerformanceOptimizer> perf_optimizer_;
shared_ptr<MemoryPool> memory_pool_;
Status InferOutputShape(const TensorShape& shape_a,
const TensorShape& shape_b,
TensorShape* output_shape) {
// 处理转置逻辑的Shape推导
int64_t m = transpose_a_ ? shape_a.dim(1) : shape_a.dim(0);
int64_t k = transpose_a_ ? shape_a.dim(0) : shape_a.dim(1);
int64_t n = transpose_b_ ? shape_b.dim(0) : shape_b.dim(1);
// 检查K维度是否匹配
int64_t k2 = transpose_b_ ? shape_b.dim(1) : shape_b.dim(0);
if (k != k2) {
return errors::InvalidArgument(
"矩阵维度不匹配: ", k, " != ", k2);
}
output_shape->AddDim(m);
output_shape->AddDim(n);
return Status::OK();
}
};3.2.2 Tiling计算器实现
// tiling_calculator.cpp - Tiling策略计算
class MatMulTilingCalculator {
public:
struct MatMulTilingPlan {
int64_t tile_m; // M维度分块大小
int64_t tile_n; // N维度分块大小
int64_t tile_k; // K维度分块大小
int64_t grid_m; // M维度网格大小
int64_t grid_n; // N维度网格大小
int64_t total_blocks; // 总块数
size_t workspace_size; // 工作空间大小
};
MatMulTilingPlan ComputePlan(const TensorShape& shape_a,
const TensorShape& shape_b,
bool transpose_a,
bool transpose_b,
const DeviceInfo& device_info) {
MatMulTilingPlan plan;
// 提取矩阵维度
int64_t M = transpose_a ? shape_a.dim(1) : shape_a.dim(0);
int64_t K = transpose_a ? shape_a.dim(0) : shape_a.dim(1);
int64_t N = transpose_b ? shape_b.dim(0) : shape_b.dim(1);
// 基于硬件特性选择分块策略
if (device_info.sm_count >= 80) {
// Ampere架构优化策略
plan = ComputePlanForAmpere(M, N, K, device_info);
} else {
// 通用架构策略
plan = ComputePlanGeneric(M, N, K, device_info);
}
// 调整分块大小以满足硬件约束
AdjustForHardwareConstraints(plan, device_info);
// 计算工作空间需求
plan.workspace_size = CalculateWorkspaceSize(plan);
return plan;
}
private:
MatMulTilingPlan ComputePlanForAmpere(int64_t M, int64_t N, int64_t K,
const DeviceInfo& device_info) {
MatMulTilingPlan plan;
// Ampere架构的特定优化
// 利用Tensor Core和更大共享内存
plan.tile_m = 128; // 适合Tensor Core的尺寸
plan.tile_n = 128;
plan.tile_k = 32; // K维度分块考虑数据复用
// 计算网格大小
plan.grid_m = (M + plan.tile_m - 1) / plan.tile_m;
plan.grid_n = (N + plan.tile_n - 1) / plan.tile_n;
plan.total_blocks = plan.grid_m * plan.grid_n;
// 确保不超过硬件限制
if (plan.total_blocks > device_info.max_blocks_per_sm * device_info.sm_count) {
AdjustBlockSizeForLimits(plan, device_info);
}
return plan;
}
void AdjustForHardwareConstraints(MatMulTilingPlan& plan,
const DeviceInfo& device_info) {
// 调整分块大小以满足共享内存限制
size_t shared_mem_per_block = CalculateSharedMemoryUsage(plan);
while (shared_mem_per_block > device_info.shared_memory_per_block) {
// 减少K维度分块以减少共享内存使用
plan.tile_k = max(16LL, plan.tile_k / 2);
shared_mem_per_block = CalculateSharedMemoryUsage(plan);
}
// 调整分块大小以满足寄存器限制
size_t register_usage = EstimateRegisterUsage(plan);
while (register_usage > device_info.registers_per_block) {
// 调整分块策略
AdjustBlockSizeForRegisterLimit(plan);
register_usage = EstimateRegisterUsage(plan);
}
}
size_t CalculateWorkspaceSize(const MatMulTilingPlan& plan) {
// 计算所需工作空间大小
size_t workspace = 0;
// 双缓冲需要的额外空间
workspace += plan.tile_m * plan.tile_k * sizeof(float) * 2; // 输入A的缓冲
workspace += plan.tile_k * plan.tile_n * sizeof(float) * 2; // 输入B的缓冲
// 累加器空间
workspace += plan.tile_m * plan.tile_n * sizeof(float);
// 对齐到内存对齐边界
workspace = AlignUp(workspace, 128);
return workspace;
}
};3.2.3 内存管理器实现
// memory_manager.cpp - 高级内存管理
class MatMulMemoryManager {
public:
struct DeviceMemoryHandles {
void* d_a; // 设备内存输入A
void* d_b; // 设备内存输入B
void* d_c; // 设备内存输出C
void* workspace; // 工作空间
void* tiling; // Tiling参数
};
DeviceMemoryHandles AllocateAndPrepare(
OpKernelContext* context,
const Tensor& tensor_a,
const Tensor& tensor_b,
Tensor* tensor_c,
const MatMulTilingPlan& plan) {
DeviceMemoryHandles handles;
// 1. 计算内存需求
size_t size_a = tensor_a.TotalBytes();
size_t size_b = tensor_b.TotalBytes();
size_t size_c = tensor_c->TotalBytes();
// 2. 分配设备内存
auto* allocator = context->device()->GetAllocator(context->op_device_context());
OP_REQUIRES_OK(context,
allocator->AllocateRaw(32, size_a, &handles.d_a));
OP_REQUIRES_OK(context,
allocator->AllocateRaw(32, size_b, &handles.d_b));
OP_REQUIRES_OK(context,
allocator->AllocateRaw(32, size_c, &handles.d_c));
OP_REQUIRES_OK(context,
allocator->AllocateRaw(32, plan.workspace_size, &handles.workspace));
OP_REQUIRES_OK(context,
allocator->AllocateRaw(32, sizeof(plan), &handles.tiling));
// 3. 数据拷贝(异步)
auto* stream = context->op_device_context()->stream();
OP_REQUIRES_OK(context,
stream->MemcpyH2D(handles.d_a, tensor_a.tensor_data().data(), size_a));
OP_REQUIRES_OK(context,
stream->MemcpyH2D(handles.d_b, tensor_b.tensor_data().data(), size_b));
// 4. 拷贝Tiling参数
OP_REQUIRES_OK(context,
stream->MemcpyH2D(handles.tiling, &plan, sizeof(plan)));
// 5. 设置内存提示(优化数据局部性)
if (context->device()->tensorflow_gpu_device_info()) {
SetMemoryAdvise(handles.d_a, size_a, MEM_ADVISE_SET_READ_MOSTLY);
SetMemoryAdvise(handles.d_b, size_b, MEM_ADVISE_SET_READ_MOSTLY);
}
return handles;
}
void Release(OpKernelContext* context, DeviceMemoryHandles& handles) {
auto* allocator = context->device()->GetAllocator(context->op_device_context());
// 异步释放内存(等待计算完成)
auto* stream = context->op_device_context()->stream();
stream->ThenDeallocate(handles.d_a);
stream->ThenDeallocate(handles.d_b);
stream->ThenDeallocate(handles.d_c);
stream->ThenDeallocate(handles.workspace);
stream->ThenDeallocate(handles.tiling);
// 清空句柄
memset(&handles, 0, sizeof(handles));
}
private:
void SetMemoryAdvise(void* ptr, size_t size, int advise) {
// 设置内存访问建议
if (cudaMemAdvise(ptr, size, (cudaMemoryAdvise)advise, 0) != cudaSuccess) {
LOG(WARNING) << "Failed to set memory advise";
}
}
};4 高级优化策略与企业级实践
4.1 性能优化技术矩阵
根据13年实战经验,我总结了Host侧优化的四维技术矩阵:
|
优化维度 |
具体技术 |
适用场景 |
预期收益 |
实现复杂度 |
|---|---|---|---|---|
|
内存优化 |
内存池技术、异步拷贝、内存对齐 |
内存密集型算子 |
20-40%带宽提升 |
中等 |
|
调度优化 |
流并行、动态负载均衡、任务窃取 |
多Kernel并行 |
30-60%吞吐提升 |
高 |
|
计算优化 |
Tiling优化、向量化、指令选择 |
计算密集型算子 |
15-35%计算加速 |
中等 |
|
通信优化 |
RDMA、零拷贝、流水线通信 |
多设备协同 |
40-70%延迟降低 |
高 |
4.2 企业级内存管理实践
在大规模生产环境中,内存管理需要更加精细的策略:
// 企业级内存管理器
class EnterpriseMemoryManager {
private:
struct MemoryBlock {
void* ptr;
size_t size;
MemoryType type;
int device_id;
time_t last_used;
bool is_pinned;
};
unordered_map<size_t, vector<MemoryBlock>> size_buckets_;
mutex mutex_;
size_t total_allocated_;
size_t max_memory_;
public:
EnterpriseMemoryManager(size_t max_memory)
: total_allocated_(0), max_memory_(max_memory) {}
void* Allocate(size_t size, MemoryType type, int device_id) {
lock_guard<mutex> lock(mutex_);
// 1. 尝试从内存池复用
auto& bucket = size_buckets_[AlignSize(size)];
for (auto it = bucket.begin(); it != bucket.end(); ++it) {
if (it->type == type && it->device_id == device_id && !it->is_pinned) {
void* ptr = it->ptr;
it->last_used = time(nullptr);
bucket.erase(it);
return ptr;
}
}
// 2. 检查内存限制
if (total_allocated_ + size > max_memory_) {
EvictOldBlocks(size);
}
// 3. 新分配
void* ptr = nullptr;
if (type == MEMORY_PINNED) {
cudaMallocHost(&ptr, size);
} else {
cudaMalloc(&ptr, size);
}
if (ptr) {
total_allocated_ += size;
// 4. 记录分配信息(用于调试和优化)
MemoryBlock block{ptr, size, type, device_id, time(nullptr), false};
RecordAllocation(block);
}
return ptr;
}
void Free(void* ptr) {
lock_guard<mutex> lock(mutex_);
// 查找内存块
auto block = FindBlock(ptr);
if (!block) return;
// 不是立即释放,而是放入内存池等待复用
block->last_used = time(nullptr);
size_buckets_[AlignSize(block->size)].push_back(*block);
// 定期清理过期块
CleanupExpiredBlocks();
}
private:
void EvictOldBlocks(size_t required_size) {
// LRU策略回收内存
vector<MemoryBlock*> candidates;
for (auto& bucket : size_buckets_) {
for (auto& block : bucket.second) {
if (!block.is_pinned) {
candidates.push_back(&block);
}
}
}
// 按最近使用时间排序
sort(candidates.begin(), candidates.end(),
[](const MemoryBlock* a, const MemoryBlock* b) {
return a->last_used < b->last_used;
});
// 回收直到满足需求
size_t freed = 0;
for (auto block : candidates) {
if (freed >= required_size) break;
if (block->type == MEMORY_PINNED) {
cudaFreeHost(block->ptr);
} else {
cudaFree(block->ptr);
}
freed += block->size;
total_allocated_ -= block->size;
RemoveBlock(block);
}
}
void CleanupExpiredBlocks() {
time_t now = time(nullptr);
const time_t EXPIRY_SECONDS = 60; // 60秒未使用则释放
for (auto& bucket_pair : size_buckets_) {
auto& bucket = bucket_pair.second;
auto it = bucket.begin();
while (it != bucket.end()) {
if (now - it->last_used > EXPIRY_SECONDS) {
if (it->type == MEMORY_PINNED) {
cudaFreeHost(it->ptr);
} else {
cudaFree(it->ptr);
}
total_allocated_ -= it->size;
it = bucket.erase(it);
} else {
++it;
}
}
}
}
};4.3 动态性能调优框架
// 运行时性能调优器
class RuntimePerformanceTuner {
private:
struct TuningHistory {
vector<PerformanceRecord> records;
unordered_map<string, TuningStrategy> best_strategies;
time_t last_tuning_time;
};
TuningHistory history_;
PerformanceMonitor monitor_;
StrategyPredictor predictor_;
public:
TuningStrategy Tune(OperatorContext* context, const TensorShape& shape) {
// 1. 检查是否有缓存策略
string shape_key = ShapeToKey(shape);
if (auto it = history_.best_strategies.find(shape_key);
it != history_.best_strategies.end()) {
return it->second;
}
// 2. 基于历史数据预测最佳策略
TuningStrategy predicted = predictor_.Predict(shape, history_.records);
// 3. 快速基准测试验证
PerformanceMetrics metrics = RunQuickBenchmark(context, shape, predicted);
// 4. 如果需要,进行更详细的调优
if (metrics.efficiency < 0.7) { // 效率低于70%
predicted = PerformDeepTuning(context, shape, predicted);
}
// 5. 记录调优结果
history_.best_strategies[shape_key] = predicted;
history_.records.push_back({shape, predicted, metrics});
// 6. 定期清理历史记录
CleanupOldRecords();
return predicted;
}
private:
TuningStrategy PerformDeepTuning(OperatorContext* context,
const TensorShape& shape,
const TuningStrategy& baseline) {
vector<TuningStrategy> candidates = GenerateCandidateStrategies(baseline);
TuningStrategy best_strategy = baseline;
float best_efficiency = 0.0f;
// 并行测试候选策略
vector<future<PerformanceMetrics>> futures;
for (const auto& strategy : candidates) {
futures.push_back(async(launch::async, [&]() {
return RunBenchmark(context, shape, strategy);
}));
}
// 收集结果
for (size_t i = 0; i < candidates.size(); ++i) {
PerformanceMetrics metrics = futures[i].get();
if (metrics.efficiency > best_efficiency) {
best_efficiency = metrics.efficiency;
best_strategy = candidates[i];
}
}
return best_strategy;
}
vector<TuningStrategy> GenerateCandidateStrategies(const TuningStrategy& baseline) {
vector<TuningStrategy> candidates;
candidates.push_back(baseline);
// 基于baseline生成变体
TuningStrategy variant;
// 变体1:增加分块大小
variant = baseline;
variant.tile_size *= 2;
candidates.push_back(variant);
// 变体2:减少分块大小
variant = baseline;
variant.tile_size = max(32, variant.tile_size / 2);
candidates.push_back(variant);
// 变体3:调整流水线深度
variant = baseline;
variant.pipeline_depth = min(4, variant.pipeline_depth + 1);
candidates.push_back(variant);
// 变体4:使用不同的内存布局
variant = baseline;
variant.memory_layout = (variant.memory_layout == ROW_MAJOR) ?
COLUMN_MAJOR : ROW_MAJOR;
candidates.push_back(variant);
return candidates;
}
};5 故障排查与调试指南
5.1 常见问题诊断矩阵
基于大量实战经验,我总结了Host侧开发的常见问题模式:
|
问题类型 |
症状表现 |
根本原因 |
解决方案 |
|---|---|---|---|
|
内存泄漏 |
内存使用持续增长,最终OOM |
未正确释放设备内存 |
使用RAII包装器,启用内存检查工具 |
|
数据竞争 |
结果非确定性变化 |
多Stream访问冲突 |
添加适当同步,使用原子操作 |
|
性能下降 |
吞吐量突然降低 |
内存碎片、缓存失效 |
内存池优化,调整访问模式 |
|
死锁 |
程序卡死无响应 |
资源竞争循环等待 |
超时检测,死锁预防算法 |
5.2 高级调试框架
// 生产级调试框架
class ProductionDebugFramework {
private:
struct DebugContext {
atomic<bool> enabled{false};
atomic<int> log_level{0};
vector<DebugHook*> hooks;
PerformanceCounter counters;
};
DebugContext context_;
thread_local static DebugSession* current_session_;
public:
class DebugSession {
public:
DebugSession(const string& op_name) : op_name_(op_name) {
StartProfiling();
}
~DebugSession() {
StopProfiling();
GenerateReport();
}
void CheckInvariants() {
// 检查关键不变量
CheckMemoryInvariants();
CheckPerformanceInvariants();
CheckNumericalInvariants();
}
private:
string op_name_;
time_point<high_resolution_clock> start_time_;
PerformanceSnapshot start_snapshot_;
void CheckMemoryInvariants() {
size_t current_usage = GetMemoryUsage();
if (current_usage > context_.counters.max_memory_usage * 1.5) {
LOG(WARNING) << "内存使用异常增长: " << op_name_;
DumpMemoryState();
}
}
};
void EnableDebugging(const string& config_path) {
// 从配置文件加载调试设置
auto config = LoadConfig(config_path);
context_.enabled = config.enable_debug;
context_.log_level = config.log_level;
// 安装调试钩子
if (config.enable_memory_check) {
InstallMemoryHook();
}
if (config.enable_perf_monitor) {
InstallPerfHook();
}
if (config.enable_assertion) {
InstallAssertionHook();
}
LOG(INFO) << "调试框架已启动,级别: " << context_.log_level;
}
void InstallMemoryHook() {
auto hook = make_unique<MemoryDebugHook>();
hook->SetCheckpointCallback([this](const MemoryCheckpoint& checkpoint) {
if (checkpoint.leak_size > 0) {
LOG(ERROR) << "检测到内存泄漏: " << checkpoint.leak_size << " bytes";
DumpLeakReport(checkpoint);
}
});
context_.hooks.push_back(hook.release());
}
void DumpLeakReport(const MemoryCheckpoint& checkpoint) {
ofstream report("memory_leak_report_" +
to_string(time(nullptr)) + ".txt");
report << "内存泄漏报告\n";
report << "============\n";
report << "时间: " << checkpoint.timestamp << "\n";
report << "泄漏大小: " << checkpoint.leak_size << " bytes\n";
report << "分配栈跟踪:\n";
for (const auto& stack : checkpoint.allocation_stacks) {
report << " 分配 " << stack.size << " bytes at:\n";
for (const auto& frame : stack.frames) {
report << " " << frame << "\n";
}
}
report.close();
}
};5.3 性能分析与优化指南
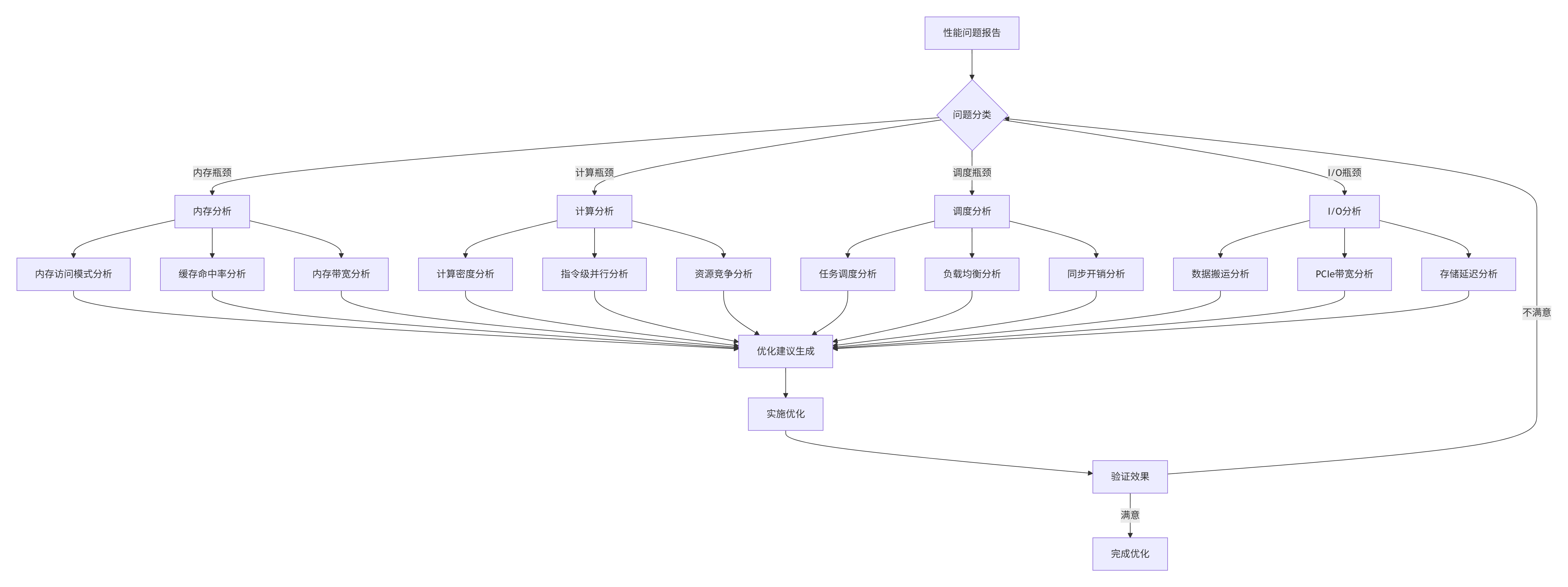
6 未来展望与行业趋势
6.1 技术发展趋势
基于13年的行业观察,我认为Host侧技术将向以下方向发展:
1. 智能化自动优化
// 未来的AI驱动优化系统
class AIOptimizationSystem {
public:
OptimizationPlan GenerateOptimalPlan(const OperatorGraph& graph,
const HardwareProfile& hw,
const PerformanceGoals& goals) {
// 使用强化学习自动寻找最优配置
ReinforcementLearningAgent rl_agent;
// 状态空间:硬件状态 + 算子特性 + 数据特征
State current_state = EncodeState(graph, hw);
// 动作空间:优化策略组合
vector<Action> candidate_actions = GenerateCandidateActions();
// 使用训练好的策略网络选择动作
Action best_action = rl_agent.SelectAction(current_state, candidate_actions);
return DecodeActionToPlan(best_action);
}
};2. 跨平台统一抽象
-
编译期优化:基于LLVM的跨平台IR优化
-
运行时适配:自动适配不同硬件后端的执行策略
-
性能可移植性:保证在不同硬件上都能获得良好性能
3. 确定性调试支持
-
全链路追踪:从框架调用到硬件执行的完整调用链
-
确定性重放:支持bug的确定性和复现
-
智能诊断:自动分析性能瓶颈和错误根源
6.2 对开发者的建议
对于不同阶段的开发者,我建议:
初学者:
-
深入理解Host-Device协同的基本原理
-
掌握Tiling、Shape推导等核心概念
-
从简单算子开始,逐步增加复杂性
进阶开发者:
-
学习性能分析工具的使用
-
理解内存层次结构对性能的影响
-
掌握异步编程和并发控制
专家级开发者:
-
参与编译器优化和运行时开发
-
研究新硬件特性的利用方法
-
贡献优化策略和算法回馈社区
总结
Host侧算子实现是Ascend C开发中技术深度与工程复杂度并重的领域。它要求开发者不仅理解计算本身,更要掌握资源管理、任务调度、性能优化等系统级知识。
关键要点回顾:
-
🎯 Host侧是指挥中心:决定整个算子执行的效率和质量
-
🏗️ 分层架构是关键:清晰的职责分离提高可维护性和性能
-
⚡ 动态自适应是趋势:能适应不同场景的算子才有生命力
-
🔧 工具链是生产力:强大的调试和优化工具事半功倍
未来已来:随着AI计算需求的爆炸式增长,Host侧优化的重要性将日益凸显。只有深入理解这一层次,才能开发出真正高性能、高可靠的AI算子,在激烈的技术竞争中保持领先。
参考链接
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)