AI测试、大模型测试(三)AI语音产品测试&AI测试边界
攻击测试是通过特定方法揭露软件系统漏洞的测试手段,其核心思路基于软件错误成因的系统性分析形成针对性策略,覆盖软件系统、AI模型、自动驾驶等领域,包括沙箱逃逸、提示注入、GNSS信号欺骗等攻击类型。美国佛罗里达州技术学院的学生通过一个学年的手工精确测试,已经确定了数十种攻击软件的办法,以达到发现软件中错误的目的。AI测试的重心往往不在于重复验证这些已知的、确定性的程序行为,而在于评估AI模型本身在处
目录
一、AI语音产品(如智能音箱)测试整体方案
1.1 测试数据集多样性、量级
语音类产品整体关注以下分类下产品的表现:
1、语言种类: 普通话、地方方言、英语、混合语言
2、声音来源: 人声、录音、广播、麦克风等等
3、语音内容:日常对话、某专业人士对话等等
不同语音场景: 教学、电话通话、庭审、短视频等等
4、音色: 比如,男女、假音
5、环境:室内室外,安静噪杂,不同的背景音(雨声、回声、杂声)
6、音量: 不同分贝
7、语音方式: 喘气,唱,吐字不清等等
8、语速: 快慢中等
9、录音时长 :
10、对话方式: 连续、间断、单人、多人、不同语言混杂等
11、 特殊场景: 如敏感话题、反讽语言
12、多模态场景: 既有语音,又有文字
比如:
- 普通话(使用公开标注数据集如 AISHELL-1 ,其包含 178小时中文普通话语音,涵盖日常对话、指令控制等多种场景。)
- 各种地方方言和口音(覆盖南北方言区,粤语)
- 不同的语速;
- 多种噪音环境下(不同种类噪音、不同强度噪音)的语音;
- 各种语法错误、不完整语句和口语化的文本;
- 不同种类语音、文本的量级(引流、公开数据集)
- 不同场景下,开玩笑、反讽等等
1.2 模型评估指标(用于评估模型产品的 准确率、实时性、稳定性与资源消耗)
- 模型效果指标: 识别准确率、识别错误率、召回率、F1值、音素准确率、超音段特征评估、整体发音评分、语义理解准确率、语法纠错准确率、对话管理流畅度等等;
- 响应时间:研究表明,人类对语音反馈的心理容忍阈值约为800ms;超过此值会明显感知“卡顿”。
- 稳定性:比如,语音唤醒时,喊了3次都没反应(未唤醒或无响应)
- 性能压力下指标 : CPU/内存等指标消耗
- 抗噪能力(如吸尘器、洗衣机、电视对话)
1.3 工程质量方向测试
功能测试 + 多模态测试 + 异常测试 + 兼容性测试 + 易用性测试 + 用户界面(UI)测试 + 稳定性测试 + 安全性测试 + 性能测试 + 对抗性攻击测试
1.4 测试手段
- 自动化对比测试(多轮对话中,需确保话题的多样性和深度,避免因偶然因素误导结论)
- 大流量测试
- 专项测试(资损测试、多模态测试)
- 人工评估
- 专家评估
- 用户反馈(用户参与测试)
- 国家或业内标准。 例如国家数字音视频及多媒体产品质量监督检验中心对人工智能电视语音识别操控体验进行评价时,就采用了特定的测试参照标准和多个测试项目来进行评估,其中语音识别操控属于AI语音产品应用的一种场景,该评价涉及远场语音、声纹识别、语义理解准确率、模糊检索准确率、语音识别时间等测试项目。
- A/B测试
- 测试左移、测试右移/线上线下自动化流水线
注: 整体质量保障方案 + 多种测试技术 + 自动化流水线 + 专项测试(资损测试、多模态测试)
二、当前AI测试通常不重点关注的方面
关于当前AI测试的边界,即“不测试什么”。
2.1 纯粹的传统软件功能逻辑(在AI产品中作为基础组件时)
在AI产品的测试中,会明确区分“工程逻辑”和“AI逻辑”,即会区分工程质量、模型效果质量。 工程质量的测试与保障通常会沿用成熟的传统软件测试方法进行验证。
AI测试的重心往往不在于重复验证这些已知的、确定性的程序行为,而在于评估AI模型本身在处理不确定性任务上的表现(即模型效果质量)。
2.2 AI模型的内部机理与决策过程
当前主流的AI测试方法,特别是基于评估的测试,通常将模型视为一个整体的“黑箱”或“服务”。测试关注的是输入与输出之间的关系是否符合预期,而很少深入探究模型内部的决策机制、权重变化等。这意味着对模型内部可能存在的偏见、脆弱性等深层次问题的检测是有限的。
注: 本质上,把AI模型当成黑箱进行测试的方式,类似于AI界的黑盒测试。
2.3 长期运行的伦理影响与社会效应
AI测试主要聚焦于短期的、可量化的指标,如功能正确性、响应质量、安全合规等。
AI系统在真实世界长期运行后可能产生的广泛社会影响、伦理悖论或系统性风险,通常超出了常规测试的范围,更多地需要依赖伦理审查、持续监控和治理框架来管理。
注: 这类似于传统软件产品。
2.4 “完美”或“绝对”的性能指标
由于AI模型(尤其是大语言模型)本身具有概率性和不确定性,测试通常不追求像传统软件那样“零缺陷”的绝对功能和性能。
测试会接受一定程度的响应延迟和输出波动,来判断输出是否在「可接受的范围」,并持续对输出进行「闭环优化」,而不是期望一次性输出完美结果。
三、警惕AI测试中的盲区或误区
3.1 测试数据集的偏差:如果测试所用的数据集本身存在偏差,测试数据集本身并不能很好评估模型的结果公平性
3.2 对边界和对抗性输入的覆盖不足:模型在处理模糊、多意图或刻意诱导的输入时可能表现不佳,但这些场景在常规测试中可能未被充分覆盖
3.3 过度依赖自动化指标:单纯依赖相关性、准确率等量化指标,可能忽略输出的深层质量,如逻辑连贯性、用户意图满足度等,需要人工评估进行补充
当前AI测试的核心在于评估AI模型在处理不确定性、理解复杂意图和生成高质量输出方面的表现,而非重复传统软件的功能测试。
四、AI测试中对抗性攻击测试
4.1 百度百科对于攻击测试的定义:
攻击测试是通过特定方法揭露软件系统漏洞的测试手段,其核心思路基于软件错误成因的系统性分析形成针对性策略,覆盖软件系统、AI模型、自动驾驶等领域,包括沙箱逃逸、提示注入、GNSS信号欺骗等攻击类型。
背景:
通过手工的、探索性的测试设计,可以飞快的执行而花费很少或者根本没有开销。这些攻击是通过学习了大量实际的软件错误,将这些错误的原因和症状进行了归纳之后形成的。美国佛罗里达州技术学院的学生通过一个学年的手工精确测试,已经确定了数十种攻击软件的办法,以达到发现软件中错误的目的。这些方法已获得成功,在很短的时间内在几乎不熟悉软件的情况下,发现了大量的额外的错误。
4.2 实践与目标:
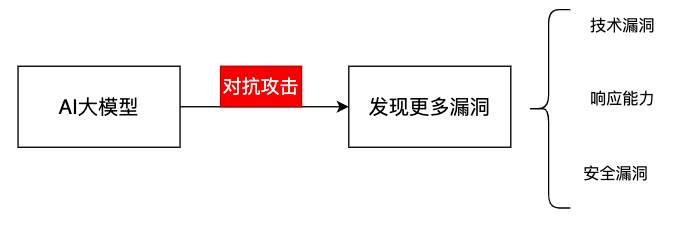
- 红队测试是一种模拟对抗性攻击的实践。通常由一组专业人员(即红队)执行,他们使用各种攻击技术和策略来模拟真实攻击者的行为,以发现潜在的安全漏洞和安全问题。 红队测试的目的 = 发现技术漏洞 + 评估组织对安全威胁的响应能力和恢复力
- 对抗攻击: 通过对输入添加微小的扰动使得分类器分类错误,包括用到热门的NLP中。
比如,对图像添加微小的噪声让分类错误;
又比如, 对句子中词语进行同义词替换让分类错误等等;
4.3 对抗攻击分类
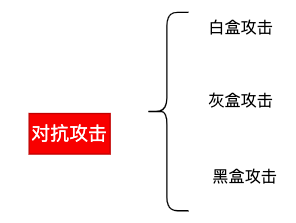
白盒攻击: 了解目标模型的结构、参数、算法和训练数据前提下,攻击者可以直接分析和修改模型的内部元素来进行攻击。白盒攻击的常见方法包括梯度攻击、模型逆向和模型篡改等。 比如,可以对图像加入预先设置的噪声来模糊图像。
黑盒攻击: 对模型内部实现一无所知,把模型当成一个黑盒子进行攻击。只能通过输入和输出来观察模型的行为。在黑盒攻击中,攻击者通常通过试探和分析来推断模型的行为,并生成特定的输入以欺骗或破坏目标模型。比如,可以随机地对图像加入噪声来模糊图像,直到模糊图像分类错误。
灰盒攻击: 介于白盒攻击和黑盒攻击之间。 只能获得部分神经网络模型的参数,可以根据这些参数对神经网络发起攻击。
参考
https://blog.csdn.net/weixin_42418754/article/details/154214444

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)