数据库的 failure recovery 是怎么进行的?
问题背景
关系型数据库最核心的功能是支持事务,这一特性使得其故障后的恢复处理过程会比较复杂。通常来说,事务会遇到三类故障:
- 事务级别的故障
比如死锁、超时,数据库可以通过 rollback 来保证事务数据的一致性。 - 系统级别的故障
比如进程被 killed、服务器故障,数据库需要通过 failure recovery 机制来恢复数据一致。 - 存储级别的故障
这需要数据备份、日志归档、灾备来保证事务数据的一致性。
这其中的 failure recovery 机制,在不同的数据库中有不同的叫法,比如 Informix 称之为 fast recovery,而 Db2 称之为 crash recovery,但不管怎么叫,指的都是数据库重启后,如何根据事务 ACID 属性(主要是原子性 A 和持久性 D)给用户的承诺,将事务数据恢复到一个正确的状态。
业界 failure recovery 算法的开山鼻祖来自于 IBM 1992 年的论文“ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging”,从名字可以知道,这个算法结合了提前写日志、行级锁、部分回滚等特性。
目前主流数据库的 failure recovery 中,有的完全采用了这个算法,有的则借鉴了它的思想。
基本概念
在理解 ARIES 算法前先要先介绍几个概念
WAL
WAL 指的是 write-ahead logging,一言蔽之,就是要求事务在提交前,其日志必须写到磁盘。也就是事务提交是日志落盘的充分非必要条件。
steal 和 force
这两个是 buffer 管理的策略。
如果事务提交前,允许 buffer 中该事务的 page 持久化到磁盘上,则称之为 steal 策略,否则称之为 no-steal 策略。所以 steal 策略暗示了:failure recovery 的时候 undo 是必须的,因为没有提交的事务,其数据可能已经写到了磁盘上。显然 steal 是一种更加灵活的策略,使得在某个情况下(比如 buffer 写满了)可以将 buffer 中的脏页(dirty page)flush 到磁盘。
如果事务提交前,buffer 中该事务的 page 必须全部持久化到磁盘上,则称之为 force 策略,否则称之为 no-force 策略,所以 force 策略暗示了:failure recovery 的时候是不需要 redo 的,因为事务一旦提交,其数据必然已经在磁盘上持久化。显然 no-force 是一种对性能更有利的策略。
所以主流数据库都使用 steal + no-force 的策略组合,也就暗示了:failure recovery 必须要考虑 redo 和 undo 两个过程。
日志记录
在一条数据库日志中,和 ARIES 相关的字段包含如下:
- LSN
每一条日志记录的地址,单调递增,可以用来方便定序。 - Type
日志记录类型,比如 update 表示 DML 操作;compensation 表示补偿日志,用于 failure recovery 的 undo 阶段再次发生 failure 时可以继续 recovery;prepare 和 rollbck 表示事务相关操作;OSfile_return 表示脏页写回磁盘。 - TransID
事务 ID - PrevLSN
同一个事务的前序 LSN - PageID
如果 Type 是 update 或者 compensation,PageID 表示这条日志记录修改了哪些磁盘上的 page - UndoNxtLSN
只在补偿日志(CLR)才有用,表示该事务中下一条需要 rollback 的 LSN,相当于是普通 update 日志的 PrevLSN - Data
这条日志的数据部分,包含 redo 和 undo 信息。
物理页
物理页 page 会记录 page_LSN,表示最近一次更新这个 page 的 LSN
事务表
事务表记录了当前所有的活动事务(未提交的)
- TransID
事务 ID - State
事务的提交状态,比如 P 表示 prepare,U 表示非 prepare - LastLSN
该事务写的最后一个 LSN - UndoNxtLSN
如果该事务的最近一次 LSN 是非 CLR 日志,则是 LastSCN,如果是 CLR 日志,则是这条 CLR 日志记录的 UndoNxtLSN
脏页表
脏页表记录了所有 buffer 中的脏页(dirty page,在 buffer 中发生了修改但还没有写回磁盘)。
- PageID
脏页 ID - RecLSN
该 page 第一次从 nondirty 转为 dirty 的 LSN,也就是如果这个 page 被多次修改,那么脏页表里记录的是最早修改这个 page 的 LSN。
checkpoint
数据库会周期性的执行 checkpoint,checkpoint 可以缩短 failure recovery 的进程。比如在某个时间点,所有的脏页都刷到磁盘上。当后续发生 failure recovery 时,这个 checkpoint 就会被作为起点,根据 LSN 进行后续的 redo 和 undo。但是这样的 checkpoint 为了保证数据一致,会阻止用户线程访问敏感区域,对系统可用性或性能有较大的影响,因此实际会采用名为“fuzzy checkpoint”的做法,fuzzy checkpoint 是异步发生的,意味着在 fuzzy checkpoint 进行时,事务可以同步进行,fuzzy checkpoint 不要求将所有的脏页都刷到磁盘上,仅仅要求事务表和脏页表落盘(还有一些其他的映射信息)。fuzzy checkpoint 动作的 begin 和 end 也会写入事务日志。
算法描述
ARIES 算法中 failure recovery 分为三部分:Analysis、Redo 和 Undo。Analysis 找到日志中最近一次完整的 checkpoint,分析之后的日志,并恢复出事务表、脏页表。脏页表用于 Redo,事务表用于 Undo。
大致的示意图如下: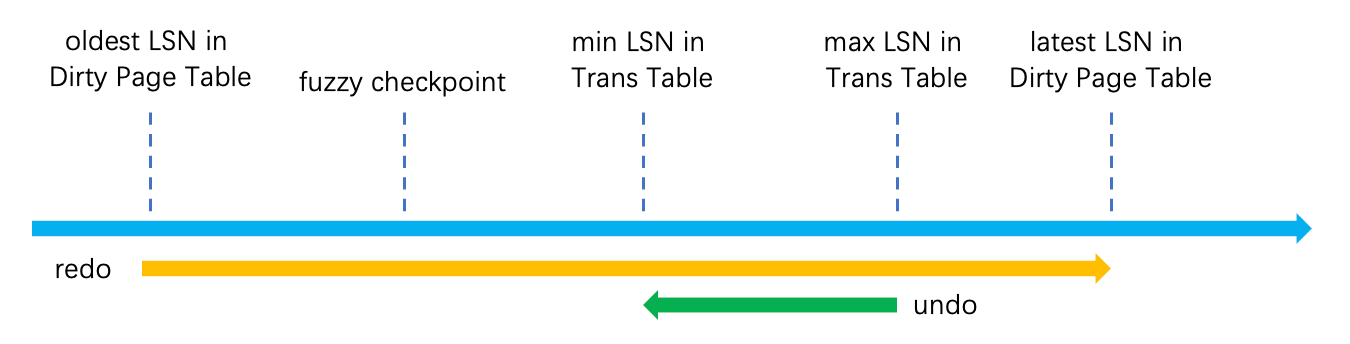
Analysis
在 Analysis 的过程中,输入是最近一次完成的 checkpoint 的 LSN(也就是 Master Addr),经过 Analysis,输出则是自从这个 checkpoint 以来的事务表、脏页表,以及 Redo 的起点(RedoLSN)。注意这个最近一次完成的 checkpoint 意味着在日志中存在成对的 begin_chkpt 和对应的 end_chkpt。如果没有 end_chkpt 只有 begin_chkpt,那么就是一个未完成的 checkpoint,是不能作为 Master Addr 的。
具体算法是这样的(灰色字体加了注释):
RESTART_ANALYSIS(Master_Addr, Trans_Table, Dirty_Pages, RedoLSN);
initialize the tables Trans_Table and Dirty_Pages to empty;
Master_Rec := Read_Disk(Master_Addr);
/* 找最近一次 checkpoint */
Open_Log_Scan(Master_Rec.ChkptLSN);
/* 读 Begin_Chkpt 日志 */
LogRec := Next_Log();
/* 读 Begin_Chkpt 的下一条日志 */
LogRec := Next_Log();
WHILE NOT(End_of_Log) DO;
/* 如果是事务相关日志记录,并且不在事务表中 */
IF trans related record & LogRec.TransID NOT in Trans_Table THEN
/* 写入事务表 */
insert (LogRec.Trans_ID, 'U' ,LogRec.LSN, LogRec.PrevLSN) into Trans_Table;
SELECT (LogRec.Type)
WHEN('update' | 'compensation') DO;
/* 更新事务表事务记录的 LastLSN 为最新的 LSN */
Trans_Table[LogRec.TransID].LastLSN := LogRec.LSN;
IF LogRec.Type = 'update' THEN
/* 按照事务表的定义,如果是 update 则 UndoNxtLSN = LastLSN */
IF LogRec is undoable THEN Trans_Table[LogRec.TransIO].UndoNxtLSN := LogRec.LSN;
/* 同样按照事务表的定义,如果是 CLR 则 UndoNxtLSN = 日志记录的 UndoNxtLSN */
ELSE Trans_Table[LogRec.Trans_ID].UndoNxtLSN := LogRec.UndoNxtLSN;
IF LogRec is redoable & LogRec.PageID NOT IN Dirty_Pages THEN
/* 如果脏页表里没有这个记录 LSN 对应的 PageID,则插入脏页表,
注意如果有这个 PageID,是不会更新 LSN 的,这是因为因为脏页表的定义是 Page 的最早修改 LSN,也就是 redo 的起点 */
insert (LogRec.PageID, LogRec.LSN) into Dirty_Pages;
END; /* WHEN( 'update' | 'compensation') */
/* 如果发现了 begin_chkpt,说明有可能是未完成的 checkpoint,什么都不用做 */
WHEN('Begin_Chkpt');
/* 如果发现了 end_chkpt,则其就是 Master Addr,说明其一定是这次 failure recovery 的起点,
那么这个 checkpoint 所持久化的事务表和脏页表需要写到当前 failure recovery 的事务表和脏页表中 */
WHEN('End_Chkpt') DO;
FOR each entry in LogRec.Tran_Table DO;
IF TransID NOT IN Trans_Table THEN DO;
/* 如果 analysis 的事务表中没有这个事务,则添加这个事务 */
insert entry(TransID, State, LastLSN, UndoNxtLSN) In Trans_Table;
END;
END; /* FOR */
FOR each entry in LogRec.Dirty_PagLst DO;
/* 如果 checkpoint 的脏页表不在 analysis 的脏页表中,则插入这条记录*/
IF PagelID NOT IN Dirty_Pages THEN insert entry (PageID, RecLSN) in Dirty_Pages;
/* 如果 checkpoint 的脏页表对应的 pageid 在 analysis 的脏页表的 pageid 中,则将其 RecLSN 更新为 checkpoint 中的 LSN
这是因为 checkpoint 一定是 analysis 的起点,也是 analysis 最早开始分析的 */
ELSE set RecLSN of Dirty_Pages entry to RecLSN in Dirty_PagLst;
END; /* FOR */
END; /* WHEN('End Chkpt') */
/* 如果日志记录是 prepare,rollback 的处理,修改事务表的 state 和 LastLSN 信息 */
WHEN('prepare' | 'rollback') DO;
IF LogRec.Type = 'prepare' THEN Trans_Table[LogRec.TransID].State := 'P';
ELSE Trans_Table[LogRec.TransID].State := 'U';
Trans_Table[LogRec.TransID].LastLSN := LogRec.LSN;
END; /* WHEN( 'prepare' | 'roll back') */
/* 如果日志记录是 commit,则从事务表中删除这条记录 */
WHEN('end') delete Trans_Table entry for which TransID = LogRec.Trans ID;
/* 如果日志记录是 OSfile_return,表示脏页刷到了磁盘上,就从脏页表中删除这条记录 */
WHEN('OSfile_return') delete from Dirty_Pages all pages of returned file;
END; /* SELECT */
LogRec := Next_Log();
END; /* WHILE */
/* 回滚刚开始的,没有写入的事务 */
FOR EACH Trans_Table entry with (State = 'U') & (UndoNxtLSN = O) DO;
write end record and remove entry from Trans_Table;
END; /* FOR */
/* 返回 Redo 的起点,也就是脏页表中所有脏页最早修改的 LSN */
RedoLSN := minimum(Dirty_Pages.RecLSN) ;
RETURN;
Redo
Redo 阶段简单来说就是要把故障前还在内存中,没来得及写到磁盘的数据写到磁盘,不论这个事务是否提交。主要思路是根据 analysis 得到的 RedoLSN,逐条分析日志,并依据脏页表来确定是否需要修改磁盘 page。
具体算法是这样的(灰色字体加了注释):
/* Redo 只需要用到脏页表 */
RESTART_REDO(RedoLSN, Dirty_Pages);
/* 以 analysis 阶段得到的 RedoLSN 作为 Redo 阶段的起点 */
Open_Log_Scan(RedoLSN);
/* 定位到 redo point,读日志 */
LogRec := Next_Log();
/* 处理每一条日志直到日志结尾 */
WHILE NOT(End_of_Log) DO;
IF LogRec.Type = ('update' | 'compensation') & LogRec is redoable &
LogRec.PageID IN Dirty_Pages &
LogRec.LSN >= Dirty_Pages[LogRec.PageID].RecLSN
/* 如果这条日志记录是个更新或者补偿,并且涉及的 page 在脏页表,
并且 LSN 大于脏页表中 page 的最早 LSN,则将脏页写回磁盘*/
THEN DO;
/* 给这个 page 加上 latch */
Page := fix&latch(LogRec. PageID, 'X');
/* 如果磁盘上的 page LSN 小于日志记录中的 LSN,也说明是脏页*/
IF Page.LSN < LogRec.LSN THEN DO
/* 写回磁盘 */
Redo_Update(Page, LogRec);
/* 更新磁盘 page 的 LSN 为日志的 LSN */
Page.LSN := LogRec.LSN;
END;
/* 如果脏页已经写回磁盘了,则将脏页表中的对应 page 的 RecLSN 更新为磁盘 page LSN 的后续 LSN */
ELSE Dirty_Pages[LogRec.PageID].RecLSN := Page.LSN+1;
unfix&unlatch(Page);
END;
LogRec := Next_Log();
END;
RETURN;
Undo
Undo 阶段是把未提交事务所做的数据变化回退掉。主要思路是根据事务表中的记录,结合日志,倒序处理需要回退的数据修改。需要注意的是,undo 一条记录也会记录一条 compensation 日志,以防在 undo 阶段发生 failure 也可以继续 undo。
具体算法是这样的(灰色字体加了注释):
RESTART_UNDO(Trans_Table);
WHILE EXISTS (Trans with State = 'U' in Trans_Table) DO;
/* Undo 的起点是事务表中所有未提交事务中最晚的那个 LSN */
UndoLSN := maximum(UndoNxtLSN) from Trans_Table entries with State = 'U' ;
/* 读 Undo 起点的 LSN */
LogRec := Log_Read(UndoLSN);
SELECT(LogRec.Type)
/* 对 update 日志记录进行回滚处理 */
WHEN( 'update') DO;
IF LogRec is undoable THEN DO;
/* 对相关 page 加锁 */
Page := fix&latch(LogRec.PageID, 'X');
/* 回滚数据 */
Undo_Update(Page, LogRec);
/* 写下一条 compensation 日志,以防在回滚阶段发生 failure */
/* 注意这条 CLR 日志中,LSN 是新序号 LgLSN */
/* PrevLSN 是回滚原始 update 的 LSN */
/* UndoNxtLSN 是回滚原始 update 的 PrevLSN */
Log_Write('compensation', LogRec.TransID,
Trans_Table[LogRec.TransID].LastLSN, LogRec.PageID, LogRec.PrevLSN,
..., LgLSN, Data);
/* 将回滚 page LSN 设置为 CLR LSN */
Page.LSN := LgLSN;
/* 将事务表该事务的 LastLSN 设置为 CLR LSN */
Trans_Table[LogRec.TransID].LastLSN := LgLSN;
unfix&unlatch(Page);
END;
/* 如果是不可 undo 的,则忽略 */
ELSE;
/* 在事务表中,将这个事务的 UndoNxtLSN 设置为日志记录的 PrevLSN */
/* 因为外部 while 循环是按照事务表的 UndoNxtLSN 来的,相当于是说,undo 完这一条 undo 这个事务的前一条语句 */
Trans_Table[LogRec.TransID].UndoNxtLSN := LogRec.PrevLSN;
/* 如果当前记录的 PrevLSN 是 0,则意味着这个事务的 undo 已经结束了 */
IF LogRec.PrevLSN = O THEN DO;
/* 在日志记录里写下一条事务结束的记录 */
Log_Write('end', LogRec.TransID,
Trans_Table[LogRec.TransID].LastLSN, ...);
/* 从事务表里删除这个事务 */
delete Trans_Table entry where TransID.LogRec.TransID;
END;
END; /* WHEN('update') */
/* 如果这是一条 CLR 日志,处理这条记录意味着在 undo 阶段发生过 failure */
/* 所以什么都不用做,直接将事务表的 UndoNxtLSN 设置为 CLR 记录的 UndoNxtLSN */
/* 其实也就是原始事务的 Prev.LSN */
WHEN('compensation')
Trans_Table[LogRec.TransID].UndoNxtLSN := LogRec.UndoNxtLSN;
/* 如果这是一条 rollback 或者 prepare,直接将事务表 UndoNxtLSN 设置为日志的同事务前一条日志 */
WHEN('rollback'|'prepare')
Trans_Table[LogRec.TransIO].UndoNxtLSN := LogRec.PrevLSN;
END; /* SELECT */
END; /* WHILE */
RETURN ;
实例
最后通过一个实例来演示下 ARIES 是如何工作的。假设某个时间段数据库产生了如下事务(交错执行):
- T1 更新了 Page1,Page3 并提交
- T2 更新了 Page2,Page5,Page7
- T3 更新了 Page4,Page3 并提交
- T4 更新了 Page6 并提交
之后数据库发生 failure(并假设在 failure recovery 过程中又发生了 failure),也就是 failure 时候日志的顺序如下:
| LSN | Type | TransID | PrevLSN | PageID | UndoNxtLSN |
|---|---|---|---|---|---|
| LSN1 | update | T1 | 0 | P1 | |
| LSN2 | update | T2 | 0 | P2 | |
| LSN3 | update | T1 | LSN1 | P3 | |
| LSN4 | end | T1 | 0 | ||
| LSN5 | update | T3 | 0 | P4 | |
| LSN6 | checkpoint | ||||
| LSN7 | update | T3 | LSN5 | P3 | |
| LSN8 | update | T2 | LSN2 | P5 | |
| LSN9 | update | T4 | 0 | P6 | |
| LSN10 | end | T4 | LSN9 | ||
| LSN11 | end | T3 | LSN7 | ||
| LSN12 | update | T2 | LSN8 | P7 |
此时数据库重启时,其 failure recovery 的过程是这样的。
Analysis
- 先将最近一次完整的 checkpoint 的 LSN6 作为 Master Address,开始分析
- 根据 ARIES 的机制,fuzzy checkpoint 的时候会持久化事务表和脏页表,因此分析 LSN6 的 checkpoint 可以得到如下结果:
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN2 | LSN2 |
| T3 | U | LSN5 | LSN5 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
- 依次读取 checkpoint 之后的 LSN7 - LSN12
分析 LSN7(红色字体表示更新的部分)
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN2 | LSN2 |
| T3 | U | LSN7 | LSN7 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
- 分析 LSN8
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN8 | LSN8 |
| T3 | U | LSN7 | LSN7 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
| P5 | LSN8 |
- 分析 LSN9
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN8 | LSN8 |
| T3 | U | LSN7 | LSN7 |
| T4 | U | LSN9 | LSN9 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
| P5 | LSN8 |
| P6 | LSN9 |
- 分析 LSN10
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN8 | LSN8 |
| T3 | U | LSN7 | LSN7 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
| P5 | LSN8 |
| P6 | LSN9 |
- 分析 LSN11
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN8 | LSN8 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
| P5 | LSN8 |
| P6 | LSN9 |
- 分析 LSN12
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN12 | LSN12 |
| PageID | RecLSN |
|---|---|
| P1 | LSN1 |
| P2 | LSN2 |
| P3 | LSN3 |
| P4 | LSN5 |
| P5 | LSN8 |
| P6 | LSN9 |
| P7 | LSN12 |
至此 Analysis 完成,输出了事务表和脏页表,已经 Redo 的起点是 LSN1,下一步开始 Redo
Redo
根据 Analysis 的结果,Redo 从 LSN1 开始,依次将脏页表中的 Page1,Page2,Page3,Page4,Page5,Page6,Page7,写的过程中,会判断 Page.LSN 和 LogRec.LSN,如果Page.LSN 更大,则说明某些 page 因为 steal 机制已经写到磁盘,这时就不用写入磁盘,而是更新脏页表对应 PageID.RecLSN 为 Page.LSN + 1。
T2 更新了 Page2,Page5,Page7,但没有最终提交,因此需要在下一阶段 Undo。
Undo
Undo 是根据事务表倒序来做的,先找到事务表中 maximum LSN,在本例中是 LSN12,根据日志中记录的 data 回滚这个 LSN12,也就是回写 Page7 并更新 PageLSN,同时写入一条 compensation 日志(为了防止 Undo 阶段发生 failure),最后更新其 UndoNxtLsn 为 LSN8。因此回滚完 LSN12 后,
事务表是这样的:
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN12 | LSN8 |
日志记录添加一条:
| LSN | Type | TransID | PrevLSN | PageID | UndoNxtLSN |
|---|---|---|---|---|---|
| LSN13 | compensation | T2 | LSN12 | P7 | LSN8 |
如果当磁盘上的 Page 已经被回滚修改,但是事务表的 UndoNxtLSN 还没有被修改为 LSN8(还是 LSN12)的时候,数据库又发生了 failure,就会遇到再次 Undo 会重复执行回滚 LSN12,这是不希望发生的,但有了 compensation 日志,再次 Analysis 的时候根据上述算法,会将事务表更新为:
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN13 | LSN8 |
也就是加入新的 compensation LSN。
根据 Undo 的逻辑,现在事务表中 maximum LSN 是 LSN8,也就是从 LSN8 开始回滚,回写 Page5 并更新 PageLSN。
事务表更新为:
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN8 | LSN2 |
日志记录添加一条:
| LSN | Type | TransID | PrevLSN | PageID | UndoNxtLSN |
|---|---|---|---|---|---|
| LSN14 | compensation | T2 | LSN13 | P5 | LSN2 |
下一步,事务表中 maximum LSN 是 LSN2,也就是从 LSN2 开始回滚,回写 Page2 并更新 PageLSN。
事务表更新为:
| TransID | State | LastLSN | UndoNxtLSN |
|---|---|---|---|
| T2 | U | LSN2 | 0 |
日志记录添加一条:
| LSN | Type | TransID | PrevLSN | PageID | UndoNxtLSN |
|---|---|---|---|---|---|
| LSN15 | compensation | T2 | LSN8 | P5 | 0 |
至此,Page7,Page5,Page2 的数据修改都被回滚了。整个 failure recovery 过程结束,数据恢复到了故障前最新的一致点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)