深度学习实验——YOLOv5-C3模块实现
这次实验感觉是第一次在模型的理解上就开始出现困难,之前听说过YOLO模型,这次在搭建C3模块的过程中其实对各种参数并不是很理解,还是借助ai帮我分析每段代码是如何实现该功能的,另外就是每个模块当中数据的维度非常重要,决定了实验能否正常运行,其余部分其实没什么大问题。训练过程中保存的最佳模型也非常重要,在进行预测的时候可以用到这个文件。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
一、实验
1、实验目的
①利用YOLOv5算法当中的C3模块搭建网络
②了解Bottleneck模块如何实现及其作用是什么
③学会查看模型评估
2、相关知识点
① data_paths=list(data_dir.glob("*"))这句代码的意思
由于data_dir已经被转换为Path对象,用glob方法对将这个根目录data_dir(Path对象)去匹配直接子项
比如:实验中的data_dir变量代表根目录data文件夹,通过data_dir.glob("*")方法直接匹配子目录的四个文件夹sunrise、rain、cloudy、shine(也是Path对象),这个*是通配符
然后通过list方法将这四个Path对象放进列表变量data_paths中
②classeNames=[str(path).split("\\")[1] for path in data_paths]这句代码的意思
通过遍历data_paths列表,将四个子文件夹Path变量强制转换为字符串,再通过split方法按照“\”进行分割,取索引为1的变量放进列表中
比如:假设data_paths是包含一系列图片路径的列表(如[dataset\cat\img1.jpg, dataset\cat\img2.jpg, dataset\dog\img1.jpg, ...]),执行这句代码后:classeNames会变成["cat", "cat", "dog", ...]—— 即每个路径对应的类别目录名列表。
③Autopad函数详解
这段代码定义了一个名为autopad的自动计算填充(padding)值的函数,常用于卷积神经网络(CNN)中,目的是根据卷积核(kernel)大小自动计算合适的填充值,以实现 “Same Padding”(即卷积操作后特征图尺寸与输入一致)。
K是卷积核大小,p默认为None,表示需要自动计算填充
如果k是整数,返回k//2,如果k不是整数,则遍历整个序列计算每个位置的k//2
在 CNN 中,卷积操作会改变特征图的尺寸,而这个函数能让输出尺寸与输入一致。这个函数通过卷积核大小自动计算所需的填充值,无需手动指定,简化了代码
3、错误及解决方案
跑代码上好像没遇上什么错,重点还是要放在模型是如何搭建,参数都表示些什么上面
4、总结
这次实验感觉是第一次在模型的理解上就开始出现困难,之前听说过YOLO模型,这次在搭建C3模块的过程中其实对各种参数并不是很理解,还是借助ai帮我分析每段代码是如何实现该功能的,另外就是每个模块当中数据的维度非常重要,决定了实验能否正常运行,其余部分其实没什么大问题。训练过程中保存的最佳模型也非常重要,在进行预测的时候可以用到这个文件。
本实验的网络结构
YOLOv5中的C3模块是一个关键的网络结构组件,它在特征提取和模型性能提升方面起着重要作用。以下是C3模块的主要特点和功能:
结构组成:C3模块由三个卷积层(Conv)和多个Bottleneck模块组成。这些Bottleneck模块的数量由配置文件(.yaml)中的n和depth_multiple参数决定。
功能作用:C3模块的主要作用是增加网络的深度和感受野,提高特征提取的能力。它通过残差连接和特征融合,进一步增强了网络的特征提取能力。
残差连接:C3模块包含两个分支,一个分支通过多个Bottleneck层进行深层次特征提取,另一个分支仅经过一个基本卷积模块,最后将两支进行concat操作,实现特征的融合。
激活函数变化:与BottleneckCSP模块相比,C3模块在concat后的标准卷积模块中的激活函数由LeakyRelu变为了SiLU(也称为Hardswish)。
实验结果
二、代码实现
1、前期准备
①导入库并设置GPU
import pathlib
from tempfile import template
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torchvision import transforms,datasets
import os,PIL,random,warnings,pathlib
warnings.filterwarnings("ignore")
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device②导入并测试数据集
#开始导入数据
data_dir="./data/"
data_dir=pathlib.Path(data_dir)
data_paths=list(data_dir.glob("*"))
classeNames=[str(path).split("\\")[1] for path in data_paths]
classeNames对数据进行处理
#对数据进行处理
train_transforms=transforms.Compose([
transforms.RandomResizedCrop([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
test_transforms=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
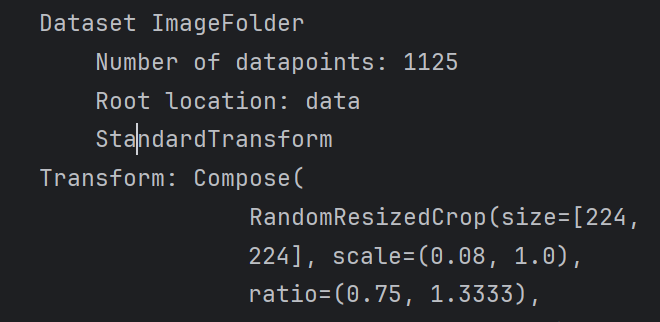
total_data=datasets.ImageFolder(root=data_dir, transform=train_transforms)
total_data可以看到对数据集的操作如下(仅显示部分)
划分数据集,还是训练集80%,测试集20%
划分完数据集之后用dataloader将数据加载进来,遍历dataloader查看数据形状
*和前几次实验一样,这里省略代码只放结果

2、构建网络
①了解网络架构(为YOLOv5当中的C3模块)
②实现模型
为了让图像大小不变化,设计如下模块
#自动填充,使得卷积之后图的尺寸不会变化
def autopad(k,p=None):
if p is None:
p=k//2 if isinstance(k,int) else [x//2 for x in k]
return p定义卷积块
#首先定义卷积模块,包括一个conv2d操作,一个batchnorm操作和一个SiLu操作
class Conv(nn.Module):
def __init__(self,c1,c2,k=1,s=1,p=None,g=1,act=True):
super().__init__()
self.conv=nn.Conv2d(c1,c2,k,s,autopad(k,p),groups=g,bias=False)
self.bn=nn.BatchNorm2d(c2)
self.act=nn.SiLU() if act is True else (act if isinstance(act,nn.Module) else nn.Identity())
def forward(self,x):
return self.act(self.bn(self.conv(x)))定义Bottleneck模块
class Bottleneck(nn.Module):
def __init__(self,c1,c2,shortcut=True,g=1,e=0.5):
super().__init__()
c_=int(c2*e)
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c_,c2,3,1,g=g)
self.add=shortcut and c1==c2
def forward(self,x):
return x+self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))定义C3模块
class C3(nn.Module):
def __init__(self,c1,c2,n=1,shortcut=True,g=1,e=0.5):
super().__init__()
c_=int(c2*e)
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c1,c_,1,1)
self.cv3=Conv(2*c_,c2,1)
self.m=nn.Sequential(*(Bottleneck(c_,c_,shortcut,g,e=1.0) for _ in range(n)))
def forward(self,x):
return self.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),dim=1))最后对整个大模块进行搭建
#%%
#开始搭建模型
import torch.nn.functional as F
#自动填充,使得卷积之后图的尺寸不会变化
def autopad(k,p=None):
if p is None:
p=k//2 if isinstance(k,int) else [x//2 for x in k]
return p
#首先定义卷积模块,包括一个conv2d操作,一个batchnorm操作和一个SiLu操作
class Conv(nn.Module):
def __init__(self,c1,c2,k=1,s=1,p=None,g=1,act=True):
super().__init__()
self.conv=nn.Conv2d(c1,c2,k,s,autopad(k,p),groups=g,bias=False)
self.bn=nn.BatchNorm2d(c2)
self.act=nn.SiLU() if act is True else (act if isinstance(act,nn.Module) else nn.Identity())
def forward(self,x):
return self.act(self.bn(self.conv(x)))
#定义Bottleneck模块
class Bottleneck(nn.Module):
def __init__(self,c1,c2,shortcut=True,g=1,e=0.5):
super().__init__()
c_=int(c2*e)
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c_,c2,3,1,g=g)
self.add=shortcut and c1==c2
def forward(self,x):
return x+self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
def __init__(self,c1,c2,n=1,shortcut=True,g=1,e=0.5):
super().__init__()
c_=int(c2*e)
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c1,c_,1,1)
self.cv3=Conv(2*c_,c2,1)
self.m=nn.Sequential(*(Bottleneck(c_,c_,shortcut,g,e=1.0) for _ in range(n)))
def forward(self,x):
return self.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),dim=1))
class model_K(nn.Module):
def __init__(self):
super(model_K, self).__init__()
#卷积模块
self.Conv=Conv(3,32,3,2)
#C3模块1
self.C3_1=C3(32,64,3,2)
#全连接层,主要用于分类
self.classifer=nn.Sequential(
nn.Linear(in_features=802816,out_features=100),
nn.ReLU(),
nn.Linear(in_features=100,out_features=4)
)
def forward(self,x):
x=self.Conv(x)
x=self.C3_1(x)
x=torch.flatten(x,start_dim=1)
x=self.classifer(x)
return x
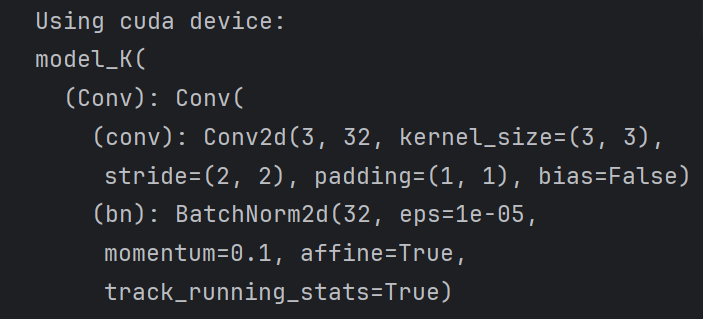
device="cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device:".format(device))
model=model_K().to(device)
model③打印模型(注意这里的参数量可以根据上文知识点当中的公式进行计算)
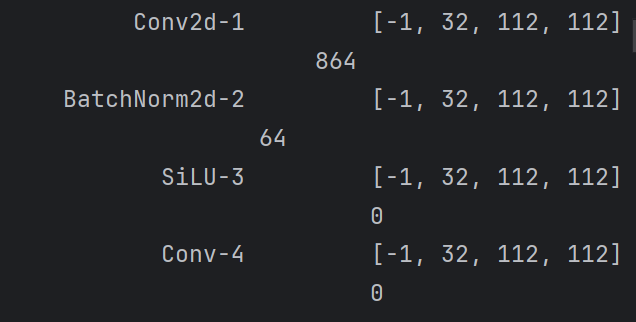
3、训练模型(三步走:梯度清零、反向传播、更新权重)
*原理及其实现都与前几次实验一样,这里不再展示代码
得到的每个epoch训练结果如下
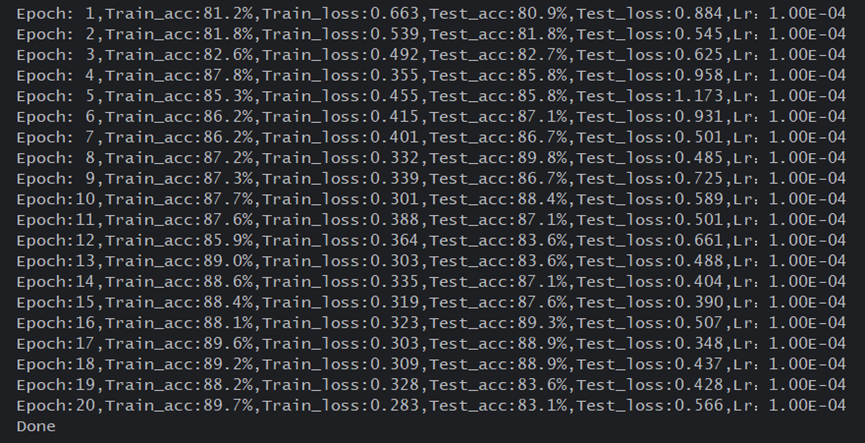
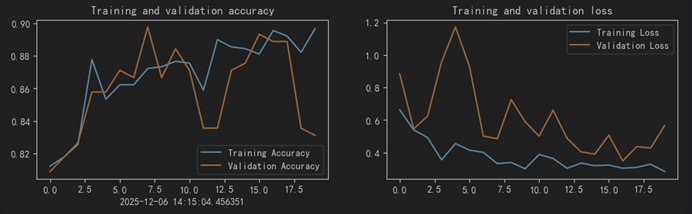
4、结果可视化
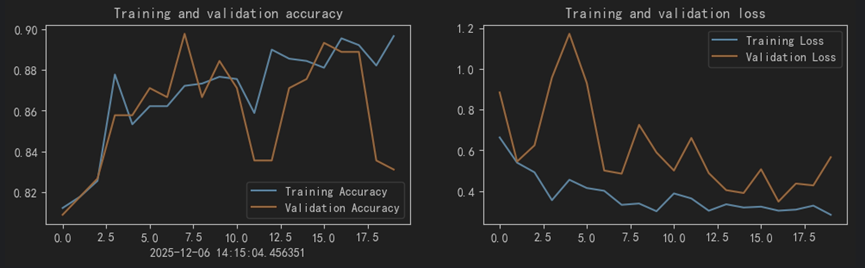
5、对模型进行评估
#模型评估
best_model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,best_model,loss_fn)
epoch_test_acc,epoch_test_loss可以看到准确率和损失如下
![]()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)