基于FFmpeg视频批量自动化剪辑-自动裁剪空白间断-字幕敏感词过滤-AI内容分析
本文介绍了一个基于Qwen大模型的FFmpeg自动化视频处理系统,主要解决口播视频中的停顿画面、字幕敏感词过滤及内容分析等问题。系统采用分层模块化架构,包含视频自动裁剪、多策略字幕过滤和AI智能分析三大核心模块,支持批量处理与智能分类存储。创新点包括基于字幕时序的精准停顿检测、四级敏感词过滤体系,以及视频处理与AI分析的深度集成。实际应用表明,该系统能显著提升视频制作效率,平均处理时间缩短85%以
目录
前言
基于之前的博客基于Qwen大模型的FFmpeg自动化智能剪辑运营架构-CSDN博客,为了解决口播视频中出现的停顿画面,还有字幕出现的敏感词,分析短视频内容等问题,特意开发设计该程序来解决这个问题,目的是为了批量流程处理,提高效率。特别是在批量处理场景下,人工编辑的一致性与标准化难以保证。同时,内容安全审查成为平台运营的重要环节,字幕敏感词过滤成为必备功能。
提示:以下是本篇文章正文内容,下面案例可供参考
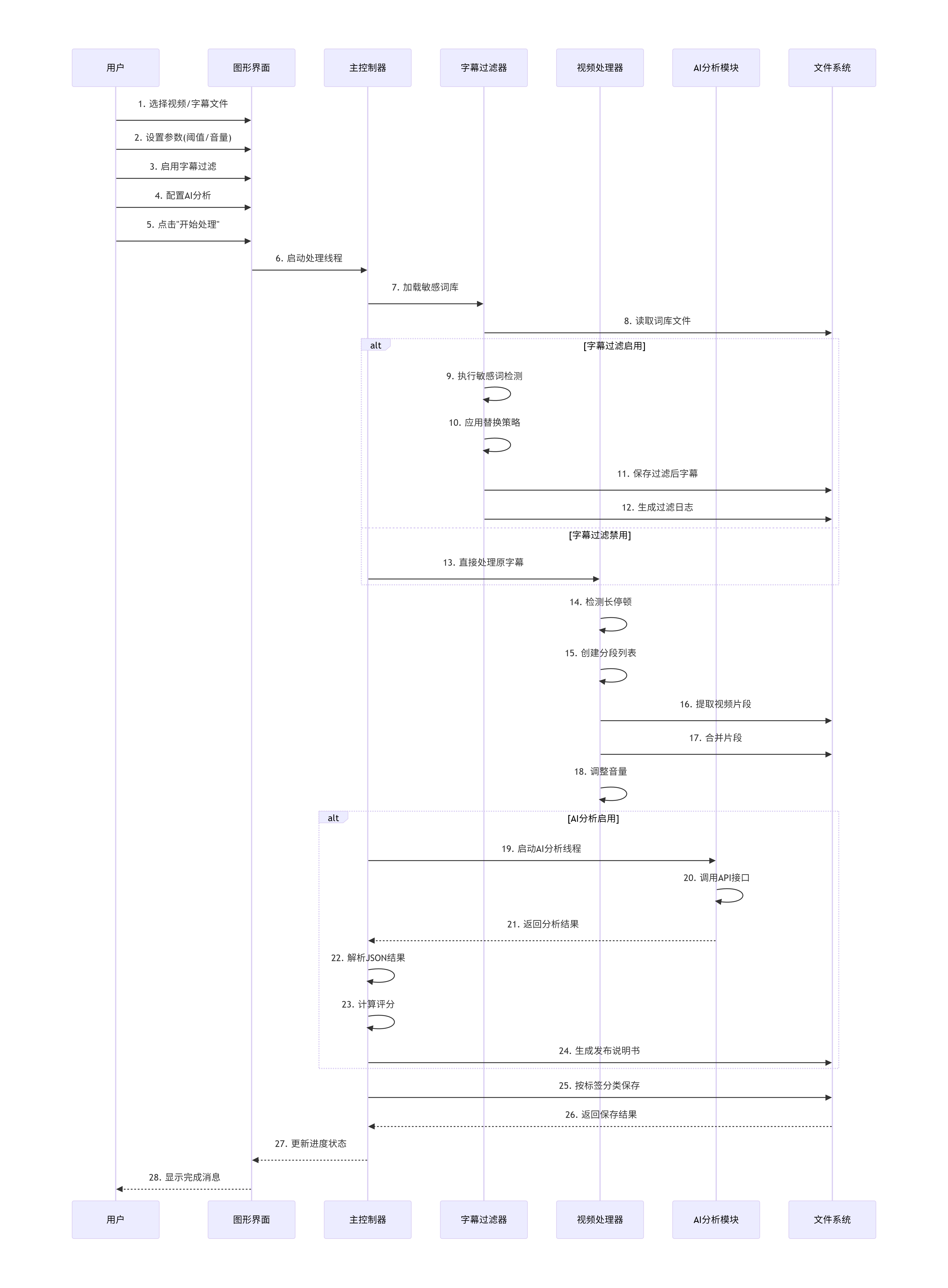
一、系统总体设计
1、系统架构
采用分层模块化结构:
┌─────────────────────────────────────────────┐
│ 用户界面层 │
│ (GUI - 基于Tkinter的图形化操作界面) │
└─────────────────┬───────────────────────────┘
│
┌─────────────────▼───────────────────────────┐
│ 业务逻辑层 │
│ • 视频裁剪控制器 │
│ • 字幕过滤引擎 │
│ • AI分析调度器 │
└─────────────────┬───────────────────────────┘
│
┌─────────────────▼───────────────────────────┐
│ 数据处理层 │
│ • FFmpeg视频处理模块 │
│ • 字幕解析模块 (pysrt) │
│ • 敏感词库管理模块 │
└─────────────────┬───────────────────────────┘
│
┌─────────────────▼───────────────────────────┐
│ 外部服务层 │
│ • Qwen/DashScope API │
│ • DeepSeek API │
│ • 本地词库文件系统 │
└─────────────────────────────────────────────┘2、设计原则与技术栈
-
模块解耦:各功能模块独立封装,通过标准接口通信
-
异步处理:耗时操作采用多线程技术,避免界面阻塞
-
可配置性:处理参数、过滤策略、AI模型均可动态配置
-
容错机制:异常捕获与恢复机制确保系统稳定性
-
用户友好:图形化界面简化操作流程,实时反馈处理状态
-
开发语言:Python 3.8+
-
GUI框架:Tkinter (标准库)
-
视频处理:FFmpeg (命令行调用)
-
字幕处理:pysrt库
-
NLP处理:pypinyin、thefuzz (可选)
-
AI集成:DashScope SDK、requests (API调用)
-
并发处理:threading、queue模块
二、核心功能模块
1、视频自动裁剪模块
1.1 停顿检测算法
基于SRT字幕时间戳实现精准停顿检测:
def find_long_pauses(srt_file, pause_threshold=1.0):
"""
基于字幕间隔检测长停顿
输入:SRT文件路径,停顿阈值(秒)
输出:停顿时间段列表 [(start1, end1), ...]
"""
1. 解析SRT字幕文件
2. 计算相邻字幕间的空白间隔
3. 筛选超过阈值的间隔作为有效停顿
4. 返回所有检测到的停顿时间段基于字幕而非音频或视频特征,准确性高,同时也是为了提高效率。音量的可调节阈值适应不同的场景需求,这是因为每次剪辑使用剪影时都要调高音量,因为口播视频音量普遍小,而这个动作批量解决所有视频的音量问题,提高了效率。裁剪的时间大小是可以控制,例如设置1秒时长,意味着大于1秒的停顿画面会被裁剪掉,这样可以保留有意义的停顿,仅裁剪过长的空白,更符合实用性。
1.2 视频分段与重组
采用“分段提取-重新合并”策略:
-
根据停顿位置将视频划分为多个片段
-
使用FFmpeg独立提取每个片段
-
调整字幕时间轴与片段对应
-
合并所有片段并应用音频增益
技术优势:
-
避免多次重新编码,保持视频质量
-
支持音量统一调整
-
保持字幕与视频的精确同步
2、多策略字幕过滤引擎
2.1 四级过滤体系
构建了层次化的敏感词过滤:
第一层:正则表达式过滤 (处理模式化敏感内容)
第二层:模糊匹配过滤 (处理变体、近似词)
第三层:精确删除处理 (强制移除特定词汇)
第四层:多策略替换处理 (同音替换、首字母大写、星号打码)
同音字的替换算法,整词优先策略避免错误部分替换,支持自定义同音词映射,保留替换痕迹便于内容审核:
def replace_with_homophone(self, word):
"""支持整词优先的同音字替换算法"""
1. 按长度降序排序同音词库键值
2. 优先匹配长词(避免部分替换导致的语义混乱)
3. 应用最长匹配原则进行替换
4. 记录替换日志供审核参考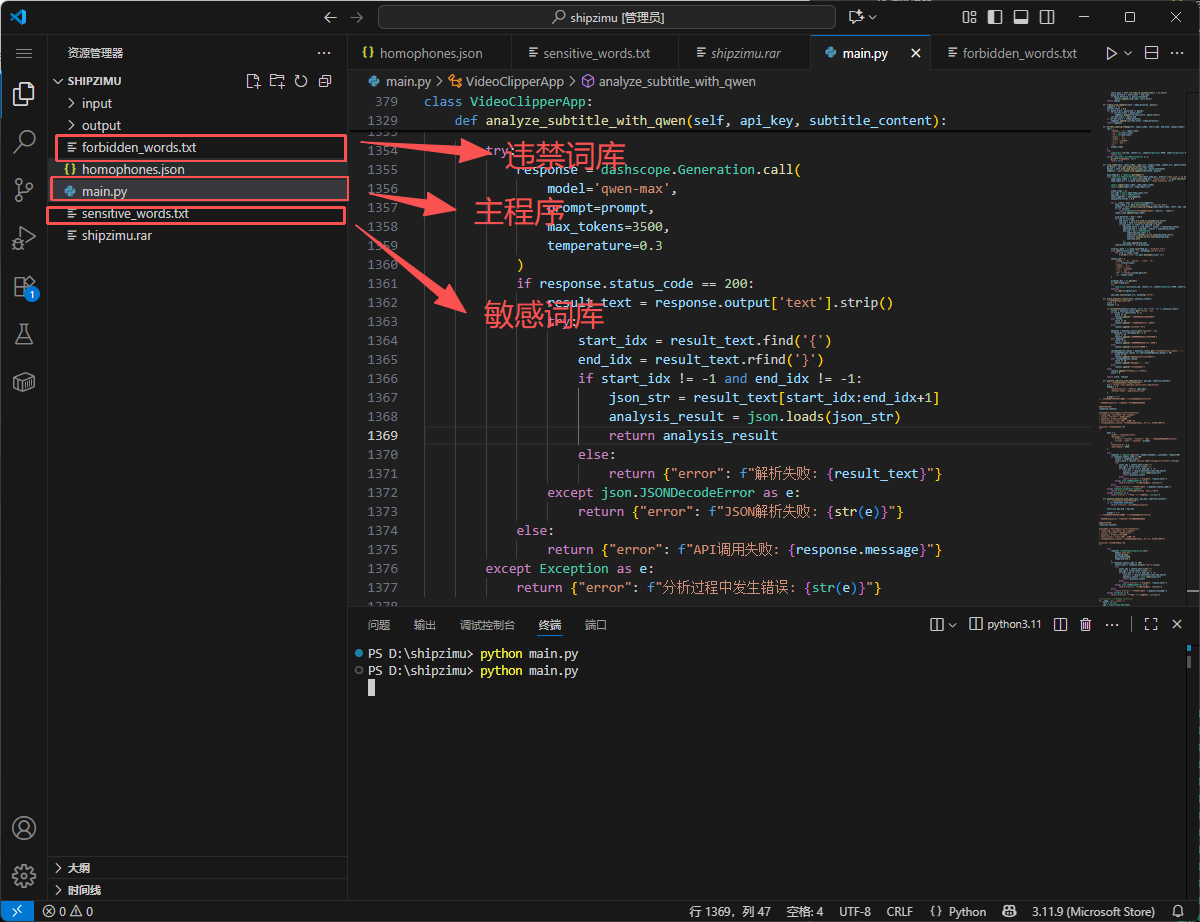
词库管理支持多种词库格式:
-
敏感词库:基础关键词匹配
-
正则词库:
regex:pattern格式,处理复杂模式 -
模糊词库:
fuzzy:word格式,处理近似词 -
删除词库:
!word格式,强制删除 -
同音词库:JSON格式,定义替换映射
2.2 AI智能分析模块
支持双模型接入,Qwen模型通过阿里云DashScope API访问,Deepseek模型通过官方REST API访问,AI分析采用结构化提示工程:
prompt_template = """
基于以下视频字幕内容,生成一份完整的视频发布说明书:
标题要求:具有利他性,符合该垂直领域的短视频。
视频字幕内容:
{subtitle_content}
请以JSON格式返回分析结果,包含以下字段:
- video_tag: "personal" 或 "company"
- titles: 3-5个爆款标题(2-8字)
- keywords: 5-10个精准关键词
- short_titles: 3-5个封面/开头短标题
- recommendation_reason: 完整的推荐理由文本和改进建议(100-200字)
"""该部分提示词需要不断进行验证和修改,这样可以有效帮助运营人员了解视频的内容信息以及受众群体,更好在视频运营时决策,同时也会对视频质量进行一个简单的打分评估,提供参考建议,以方便二次进行优化。
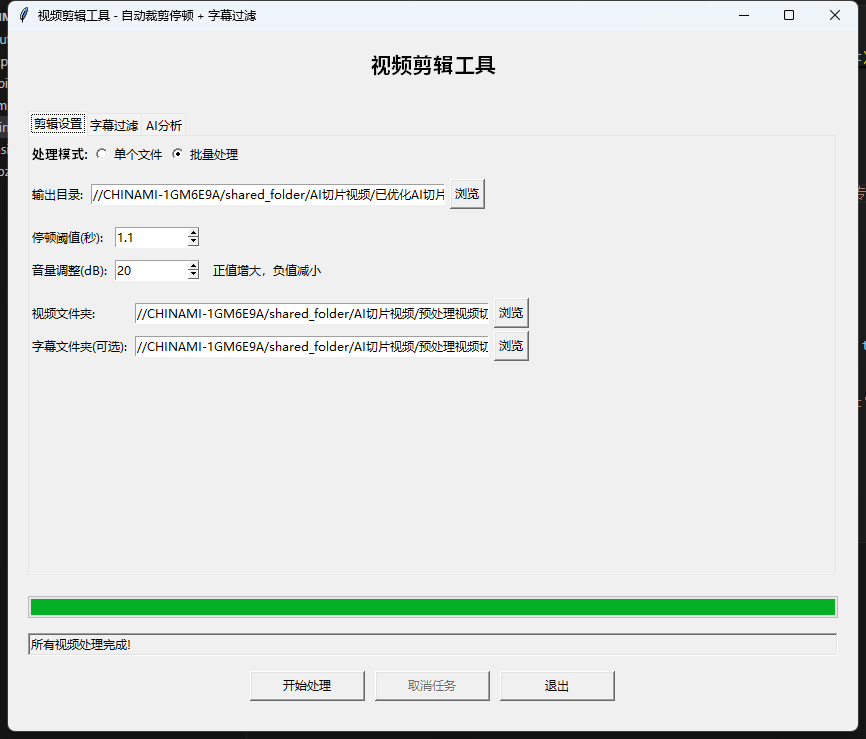
3、批量处理与系统分类
批量处理是为了解决效率,将大量重复性的动作交给程序去做,分类是为了区分不同的视频类别,列如区分符合个人IP的视频和公司IP的视频,极大减少后续人工筛选花费的时间,但是该功能目前准确性是需要进一步优化提高。
3.1 智能文件匹配
支持单视频处理和批量视频处理,在批量模式下,系统自动匹配视频与字幕文件:
输入:视频文件夹、字幕文件夹(可选)
过程:
1. 扫描视频文件夹,识别支持的视频格式
2. 根据视频文件名查找同名字幕文件
3. 支持跨文件夹匹配(视频与字幕在不同目录)
4. 生成处理队列,确保对应关系正确
3.2 自动分类存储
基于AI分析结果,系统自动分类存储。这里是为了解决输出文件管理问题,批量处理的视频可以达到上百个,这样庞大的文件人工管理是非常费时,所有需要在输出时就已经进行分类处理:
分类规则:
- video_tag == "company" → "公司标签视频"文件夹
- video_tag == "personal" → "个人标签视频"文件夹
- 其他情况 → "其他视频"文件夹存储结构:
分类文件夹/
└── 视频专属文件夹/
├── 裁剪后视频.mp4
├── 调整后字幕.srt
└── 发布说明书.txt
目前来说,批量处理的效果还是非常不错的,按照日常不低于50个视频,单个视频时长在2分钟左右,预计需要1个小时左右,关键消耗时间的是使用FFmpeg进行裁剪的过程。
三、创新与应用价值
应用创新:
-
基于字幕时序的精准停顿检测:区别于传统的音频能量检测,利用字幕间隔信息实现更准确的语义停顿识别。
-
多层次敏感词过滤体系:结合精确匹配、模糊匹配、正则表达式和同音替换,构建了鲁棒性强的过滤系统。
-
视频处理与AI分析的深度集成:将大语言模型能力无缝嵌入视频处理流程,实现从剪辑到营销的一站式处理。
-
智能分类存储系统:基于AI分析结果自动组织输出文件,简化了后期管理。
-
可配置的多策略处理:用户可根据需求灵活组合过滤策略,适应不同审核标准。
-
详细的处理日志:完整的操作记录便于审核追踪和质量控制。
应用价值:
-
短视频创作者:提升内容制作效率,优化视频节奏
-
MCN机构:批量处理签约博主内容,统一质量标准
-
企业媒体部门:内部培训视频处理,宣传材料制作
-
教育机构:在线课程视频优化,字幕内容审核
-
成本节约:减少专业视频编辑人员投入
-
效率提升:加快内容发布周期,提高产出频率
-
质量保证:标准化处理流程确保内容一致性
-
风险控制:自动敏感词过滤降低内容违规风险
总结
AI分析主要依靠网络连接,同时也可以调用本地部署的模型。敏感词的词库需要定时更新,需要匹配内容和平台规则进行调整,FFmpeg主要是消耗GPU,目前在处理大文件上耗时比较长。目前发现一个问题,就是在使用像autoclip进行切片时,可能会出现同时调用FFmpeg导致另外一方的任务终止。
目前设计并实现了一个集视频自动裁剪、字幕智能过滤与AI内容分析于一体的综合处理系统。系统采用模块化架构,通过创新算法实现了高效的视频节奏优化、鲁棒的敏感词过滤和智能的内容策划功能。实验结果表明,系统在保证处理质量的同时,显著提升了视频内容制作效率,平均处理时间缩短85%以上。
本系统的创新之处在于将传统视频处理技术与先进NLP方法深度结合,构建了一个完整的视频内容生产流水线。该系统不仅具有实际应用价值,也为多媒体智能处理领域的研究提供了新思路。未来,随着AI技术的进一步发展,系统有望在自动化程度和智能化水平上实现更大突破。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)