高通自推测解码(SSD)技术解析(1): 单模型加速推理的新方案
引言
在大语言模型(LLM)推理加速领域,传统的推测解码(Speculative Decoding)技术因其需要同时运行目标模型(Target Model)和草稿模型(Draft Model)而带来显著的显存开销与系统复杂度。高通的 自推测解码Self-Speculative Decoding(SSD) 的方案,它摒弃了独立的草稿模型,仅通过在目标模型内部添加极少量可学习参数,即可实现高效的多令牌预测与验证,极大降低了部署成本与资源消耗。本文将深入解析 SSD 的核心原理、关键参数及其在实际推理中的应用。
一、什么是 Self-Speculative Decoding?
传统推测解码的瓶颈
传统的推测解码通常采用“一大一小”双模型架构:
- 目标模型(Target Model):原始大模型,负责验证。
- 草稿模型(Draft Model):轻量级小模型,快速生成候选令牌序列。
虽然该方法能显著提升推理速度,但维护两个模型会带来:
- 显存占用翻倍
- 系统复杂度过高
- 部署与调优困难
SSD 的核心思想
SSD 的核心在于 “Self”,即无需独立草稿模型。它通过在目标模型内部添加一个轻量级 Forecast 模块,使模型在一次前向传播中就能预测未来多个令牌。其优势包括:
- ✅ 轻量级:仅增加少量可学习参数(主要是 Embedding Tensor)。
- ✅ 易部署:训练后可直接集成到 Qualcomm Genie 推理引擎。
- ✅ 低资源消耗:显存占用几乎不变,适合端侧与边缘部署。
二、SSD 原理与 Forecast 模块
SSD 在标准 Transformer 模型基础上引入了 Forecast 模块,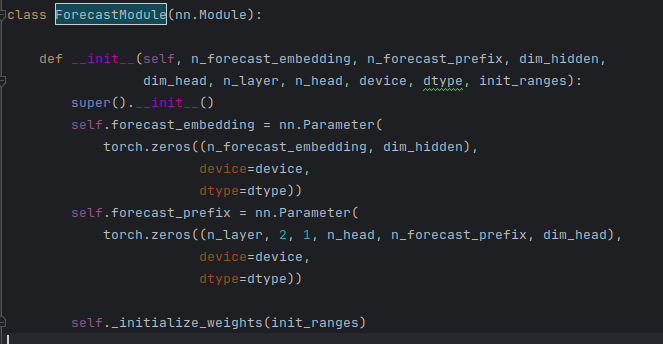
通过在大模型的结构上增加两个辅助模块来使得大模型可以预测多个token ,因为本身其是靠大模型自己的输出预测分布来实现的。
结构示意如下:
[输入序列] → [Transformer + Forecast 模块] → [预测输出 + 验证]
Forecast 模块通过两个辅助组件实现多令牌预测:
- Forecast Embedding:可学习的嵌入向量,用于表示预测位置。
- Prefix KV Cache:在推理初期提供上下文信息,提升首次预测命中率。
该机制完全基于大模型自身的输出分布进行预测,无需外部模型参与。
三、关键参数解析
以下是 SSD 训练与推理中的几个核心参数: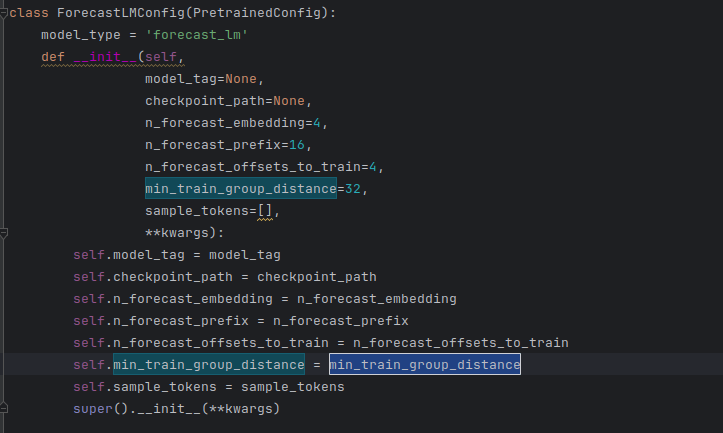
| 参数名 | 说明 | 示例值 |
|---|---|---|
n_forecast_embedding |
每个预测点预测的令牌数 | 4 |
n_forecast_prefix |
预测时所需的前缀长度(历史视野) | 16 |
n_forecast_offsets_to_train |
每个训练样本中插入的预测点数量 | 4 |
min_train_group_distance |
训练时预测点之间的最小间隔 | 32 |
四、Forecast 机制运行示例
假设输入序列长度为 56,参数如下:
n_forecast_embedding = 4n_forecast_prefix = 16n_forecast_offsets_to_train = 4
4.1 训练阶段
原始输入:
[T1][T2][T3]...[T56]
插入预测嵌入后:
[T1][T2][F1][F2][F3][F4][T7][T8]...[T20][F1][F2][F3][F4][T25]...[T56]
预测任务举例:
- 预测点1(位置3-6):
输入:[T1][T2] + [F1][F2][F3][F4]
目标:[T3][T4][T5][T6] - 预测点2(位置20-23):
输入:[T1]...[T19] + [F1][F2][F3][F4]
目标:[T20][T21][T22][T23]
损失掩码:
仅对预测位置的令牌计算损失,其余位置掩码为0。
4.2 推理阶段
已生成序列:
[T1][T2]...[T56]
插入预测嵌入:
在位置57插入 [F1][F2][F3][F4],输出4个候选令牌 [C1][C2][C3][C4]。
候选验证:
基础模型并行验证多个候选分支,选择命中率最高的分支继续生成。
五、导出至 Qualcomm Genie 推理引擎
Qualcomm Genie 是高通生成式人工智能推理扩展工具。
5.1 参数导出
Forecast 模块仅有两个可学习参数:
- Forecast Embedding Tensor:附加到模型 Embedding Table 末尾。
- Prefix KV Cache:仅在首次推理时使用,后续推理复用已有缓存。
5.2 推理流程
在 Genie 中:
- 模型接收
input_ids + 4个预测令牌作为输入。 - 通过 AR32 推理结构 构建预测树,实现多步前瞻。
- 随着树深度增加,子节点命中率逐渐下降,系统自动剪枝低概率分支。
5.3 配置文件示例
高通提供了详细的 SSD 配置示例,可通过以下链接查看:
https://docs.qualcomm.com/doc/80-63442-10/topic/json.html#ssd-q1-configuration-example
六、总结
Self-Speculative Decoding(SSD)是一种高效、轻量的大模型推理加速方案,通过在大模型内部嵌入 Forecast 模块,实现了:
- 🚀 单模型多令牌预测,免去双模型开销。
- 🧠 极低参数增量,训练与部署成本低。
- ⚙️ 无缝集成 Genie 引擎,适用于端侧与边缘设备。
SSD 为 LLM 在资源受限环境中的落地提供了新的技术路径,值得开发者与研究人员进一步关注与实践。
下一篇预告:我们将通过代码实战,演示如何在高通预优化AI模型库Hugging Face 模型上实现 SSD 训练与推理集成,敬请期待!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)