从零深入Ascend C:融合算子编程范式与核函数设计精要
本文为昇腾Ascend C算子开发的深度入门指南。文章从AI Core的达芬奇架构入手,深入解析了核函数(Kernel Function)与SPMD(Single Program, Multiple Data)并行模型的设计哲学。核心内容聚焦于融合算子(Fusion Operator)的“搬运-计算-搬运”三级流水线范式,通过TPipe/TQue机制、Double Buffer技术以及Cube/V
目录
4 实战:实现一个Matmul + LeakyRelu融合算子
4.2.3 Compute阶段:Cube与Vector的协同
摘要
本文为昇腾Ascend C算子开发的深度入门指南。文章从AI Core的达芬奇架构入手,深入解析了核函数(Kernel Function)与SPMD(Single Program, Multiple Data)并行模型的设计哲学。核心内容聚焦于融合算子(Fusion Operator)的“搬运-计算-搬运”三级流水线范式,通过TPipe/TQue机制、Double Buffer技术以及Cube/Vector单元协同工作的实战代码,详尽展示了如何构建高性能算子。本文不仅提供了完整的Matmul+LeakyRelu融合算子实现案例,更分享了性能优化、故障排查及企业级实践的真知灼见,旨在帮助开发者从本质理解并掌握Ascend C编程的精髓。
1 引言:为何需要专属的NPU编程模型?
在AI算力需求爆炸式增长的今天,通用GPU(GPGPU)在能效上面临着巨大挑战。专用的神经网络处理器(NPU, Neural Processing Unit)如同为AI计算量身定制的“赛车”,但其极致的性能发挥,严重依赖一套能充分释放其硬件潜力的编程模型。华为昇腾(Ascend)AI处理器的达芬奇架构(Da Vinci Architecture) 及其专用编程语言Ascend C,正是这一思想的产物。
与CUDA的“隐式并行”不同,Ascend C采用了一种更“显式”的并行编程哲学。它将数据搬运、计算、任务同步等控制权更大程度地交还给开发者,其核心理念是:通过精细的手动控制,换取对硬件资源极致的利用率和可预测的性能。这种模式初期学习曲线更陡峭,但一旦掌握,对于性能敏感算子的优化上限也更高。
本文将引领您深入Ascend C的世界,从核函数的基石开始,逐步构建起对融合算子编程范式的完整认知体系。
2 Ascend C核函数:并行计算的执行入口
2.1 核函数的基本结构
在Ascend C中,所有在AI Core上执行的代码都以核函数(Kernel Function) 为入口。这类似于CUDA中的__global__函数,是主机(Host)调用设备(Device)的桥梁。
一个标准的核函数声明如下所示:
extern "C" __global__ __aicore__ void my_custom_kernel(
GM_ADDR x, // 输入指针,GM_ADDR本质是__gm__ uint8_t*
GM_ADDR y,
GM_ADDR z, // 输出指针
int32_t total_length // 自定义参数
) {
// ... 核函数体
}-
extern "C":防止C++的名称修饰(Name Mangling),确保编译器能正确找到函数符号。 -
__global__:标识该函数为一个核函数。 -
__aicore__:指明该函数在AI Core上执行。 -
GM_ADDR:用于修饰指向全局内存(Global Memory)的指针参数,是一种良好的编程习惯。
2.2 SPMD并行模型:单程序多数据
Ascend C并行计算的核心是SPMD(Single Program, Multiple Data, 单程序多数据) 模型。其核心思想是:一份相同的核函数代码,会在多个AI Core上同时启动,每个核心处理总数据的不同部分。
系统会为每个运行的核函数实例分配一个唯一的逻辑ID,即block_idx。开发者通过GetBlockIdx()接口获取当前实例的ID,进而确定自己需要处理的数据片段。
// 在核函数或初始化函数中:
int32_t task_id = GetBlockIdx(); // 当前是第几个核心?
int32_t task_num = GetBlockDim(); // 总共启动了多少个核心?
// 计算当前核心负责的数据偏移量
int64_t data_offset = (total_length / task_num) * task_id;
int64_t data_length = (total_length / task_num);图1:SPMD模型数据分片示意图。一份数据被均匀分给多个AI Core并行处理。
这种模型非常契合深度学习算子的特性(如矩阵乘、卷积),能够轻松地将计算任务分摊到数十甚至上百个计算核心上,实现近乎线性的性能提升。
3 Ascend C融合算子编程范式:性能优化的艺术
融合算子的核心目标是将多个计算操作(如Matmul + Activation)融合在一个核函数内,避免中间结果写回和读取慢速的全局内存(Global Memory),从而极大降低访存开销,提升性能。
3.1 核心思想:三级流水线与任务并行
Ascend C将单个核函数内的计算流程抽象为三个经典阶段,并使其形成流水线:
-
CopyIn(搬运入):将计算所需的数据从全局内存(Global Memory)搬运至片上高速缓冲区(Unified Buffer, UB)。
-
Compute(计算):在UB上的数据就绪后,调用Cube或Vector单元进行计算。
-
CopyOut(搬运出):将计算结果从UB搬回全局内存。
最朴素的实现是串行执行:CopyIn一块数据 -> Compute -> CopyOut,然后再处理下一块。但这种方式计算单元大量时间在等待数据搬运,效率极低。
Ascend C的范式鼓励流水线并行。如图2所示,当计算单元在处理第N块数据时,搬运单元可以同时为第N+1块数据执行CopyIn,并为第N-1块数据执行CopyOut。这使得数据搬运和计算可以重叠进行,充分压榨硬件性能。
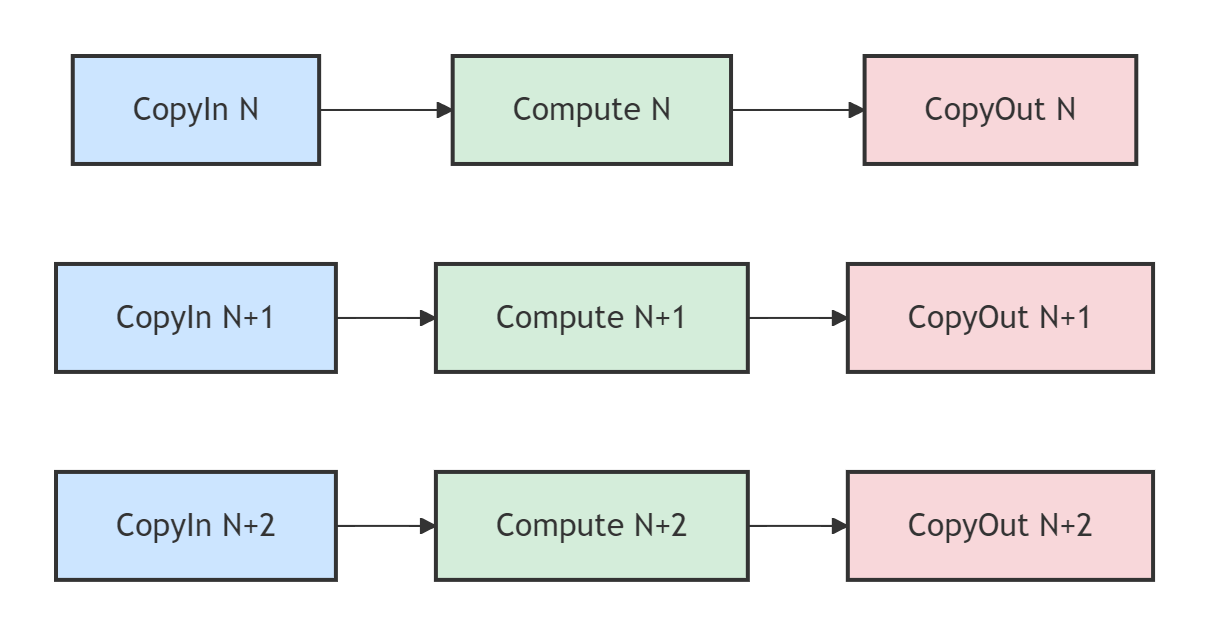
图2:流水线并行示意图。不同颜色的任务代表处理不同数据块,理想情况下,搬运和计算单元始终处于繁忙状态。
3.2 关键技术组件
为了实现上述流水线,Ascend C提供了两个关键的抽象工具:
3.2.1 TPipe:统一的资源管理者
TPipe 是一个用于管理核函数内内存和同步资源的对象。它在算子初始化阶段,统一为后续要用到的队列(TQue)分配片上缓冲区(UB)内存。
// 在算子类的 Init 函数中
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z) {
// ... 设置GlobalTensor ...
// 为队列分配内存。BUFFER_NUM为缓冲区个数,TILE_LENGTH * sizeof(half)为每个缓冲区大小
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}3.2.2 TQue:任务间的通信通道
TQue 是一个队列,作为流水线各阶段间传递数据的通道。CopyIn阶段将数据放入队列,Compute阶段从队列取出数据计算后再放入另一个队列,CopyOut阶段再从队列取出数据写回。TPosition模板参数(如VECIN, VECOUT)是一个逻辑位置,用于指示队列的用途,编译器会根据其值将队列分配到合适的存储层次,开发者无需关心底层物理地址。
// 在算子类中定义队列
AscendC::TPipe pipe;
// 定义输入队列,位置为VECIN
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX, inQueueY;
// 定义输出队列,位置为VECOUT
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueZ;3.3 性能倍增器:Double Buffer技术
Double Buffer(双缓冲) 是提升流水线效率的关键技术。它的原理是为每个队列分配两块缓冲区(例如BUFFER_NUM = 2)。当计算单元正在使用A缓冲区进行计算时,搬运单元可以同时向B缓冲区搬运下一块数据。两块缓冲区交替使用,使得数据搬运和计算的并行更加彻底,有效隐藏了数据搬运的延迟。
在代码实现上,只需在InitBuffer时将BUFFER_NUM设为2,并在循环处理数据块时,奇偶次循环会自动交替使用这两块缓冲区。
pipe.InitBuffer(inQueueX, 2, TILE_LENGTH * sizeof(half)); // BUFFER_NUM = 24 实战:实现一个Matmul + LeakyRelu融合算子
下面我们以矩阵乘法(Matmul)后接LeakyRelu激活函数的融合算子为例,完整展示开发流程。
4.1 算子分析与Tiling策略
首先,我们需要明确算子的计算逻辑和输入输出。
-
数学表达式:
C = LeakyRelu(A * B + bias, alpha) -
输入:矩阵A, B, 偏置bias, 超参数alpha。
-
输出:矩阵C。
Tiling(分块)策略是算子高性能实现的核心。由于AI Core的片上缓存(UB)容量有限,无法一次性将大矩阵全部加载进来,因此需要将大矩阵拆分成许多小块(Tile),分批在UB上进行计算。
-
多核切分:根据启动的核心数量(如8个),将输出矩阵C的M维度平均分给每个核心。
-
核内切分:每个核心根据UB容量,将自己负责的M*N大小进一步切分成更小的
baseM * baseN块,并沿K维度循环累加。
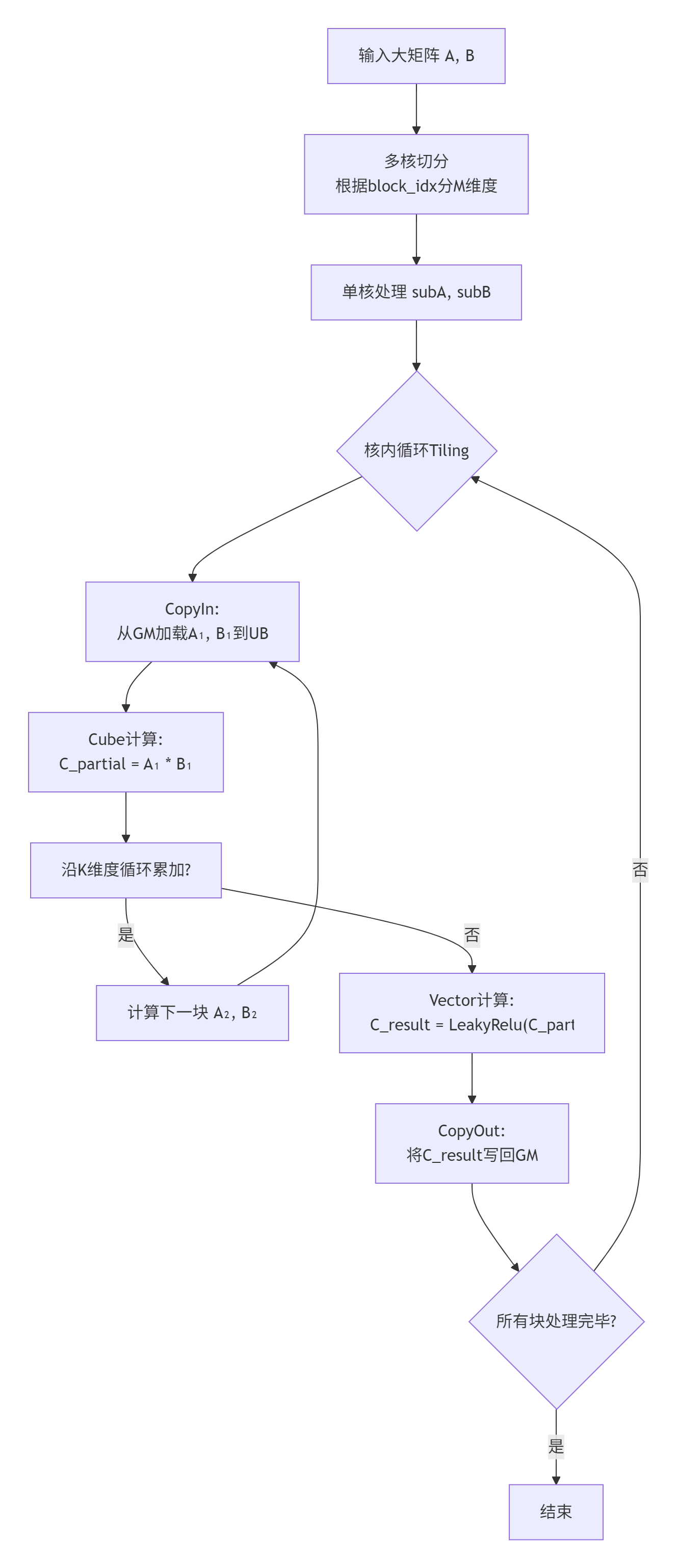
图3:Matmul+LeakyRelu融合算子的核心计算流程,包含了多核并行与核内Tiling。
4.2 代码实现详解
4.2.1 核函数与算子类定义
// 核函数定义
extern "C" __global__ __aicore__ void matmul_leakyrelu_custom(
GM_ADDR a, GM_ADDR b, GM_ADDR bias, GM_ADDR alpha, GM_ADDR c,
int32_t M, int32_t N, int32_t K) {
KernelMatmulLeakyRelu op;
op.Init(a, b, bias, alpha, c, M, N, K);
op.Process();
}
// 算子类定义
class KernelMatmulLeakyRelu {
public:
__aicore__ inline void Init(GM_ADDR a, GM_ADDR b, GM_ADDR bias, GM_ADDR alpha, GM_ADDR c,
int32_t M, int32_t N, int32_t K) {
// 1. 设置Global Tensor
// 2. 根据block_idx计算数据偏移(SPMD)
// 3. 通过pipe.InitBuffer为所有Queue分配Double Buffer内存
}
__aicore__ inline void Process() {
constexpr int32_t loopCount = TILE_NUM * 2; // 考虑Double Buffer,循环次数翻倍
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress);
__aicore__ inline void Compute(int32_t progress);
__aicore__ inline void CopyOut(int32_t progress);
AscendC::TPipe pipe;
// 定义Matmul需要的Queue,以及LeakyRelu输出Queue
AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueA, inQueueB;
AscendC::TQue<AscendC::QuePosition::VECOUT, 1> mmOutQueue, reluOutQueue;
// ... 定义GlobalTensor ...
};4.2.2 CopyIn阶段:数据搬运
__aicore__ inline void CopyIn(int32_t progress) {
// 1. 为输入数据分配Local Tensor
AscendC::LocalTensor<half> aLocal = inQueueA.AllocTensor<half>();
AscendC::LocalTensor<half> bLocal = inQueueB.AllocTensor<half>();
// 2. 根据progress和Tiling策略,计算当前数据块在Global Memory的偏移量
// ... 计算offsetA, offsetB ...
// 3. 执行数据搬运
AscendC::DataCopy(aLocal, aGm[offsetA], TILE_LENGTH);
AscendC::DataCopy(bLocal, bGm[offsetB], TILE_LENGTH);
// 4. 将数据Tensor入队
inQueueA.EnQue(aLocal);
inQueueB.EnQue(bLocal);
}4.2.3 Compute阶段:Cube与Vector的协同
这是融合算子的核心。我们使用CANN提供的Matmul高阶API来简化复杂的Cube单元操作,然后在其输出上直接进行Vector计算。
__aicore__ inline void Compute(int32_t progress) {
// 1. 从队列中取出输入数据
AscendC::LocalTensor<half> aLocal = inQueueA.DeQue<half>();
AscendC::LocalTensor<half> bLocal = inQueueB.DeQue<half>();
// 2. 为Matmul结果分配Local Tensor
AscendC::LocalTensor<float> mmOutLocal = mmOutQueue.AllocTensor<float>();
// 3. 使用Matmul高阶API (关键步骤)
// 该API内部封装了Cube指令、数据搬运和偏置相加
matmulObj.SetTensorA(aLocal);
matmulObj.SetTensorB(bLocal);
matmulObj.SetBias(biasLocal); // 设置偏置
if (matmulObj.Iterate()) { // 执行一次矩阵乘计算块
matmulObj.GetTensorC(mmOutLocal); // 获取结果,结果已在UB中
}
// 4. 立即进行LeakyRelu矢量计算,实现融合
AscendC::LocalTensor<float> reluOutLocal = reluOutQueue.AllocTensor<float>();
AscendC::LeakyRelu(reluOutLocal, mmOutLocal, alpha, TILE_LENGTH);
// 5. 将最终结果入队,并释放输入Tensor
reluOutQueue.EnQue(reluOutLocal);
mmOutQueue.FreeTensor(mmOutLocal);
inQueueA.FreeTensor(aLocal);
inQueueB.FreeTensor(bLocal);
}代码1:Compute阶段核心代码。展示了如何将Matmul API的输出直接喂给LeakyRelu,避免中间结果写回GM。
4.2.4 CopyOut阶段:结果写回
__aicore__ inline void CopyOut(int32_t progress) {
// 1. 从队列中取出计算结果
AscendC::LocalTensor<float> reluOutLocal = reluOutQueue.DeQue<float>();
// 2. 计算在Global Memory中的目标偏移量
// ... 计算offsetC ...
// 3. 将结果写回全局内存
AscendC::DataCopy(cGm[offsetC], reluOutLocal, TILE_LENGTH);
// 4. 释放Local Tensor
reluOutQueue.FreeTensor(reluOutLocal);
}5 高级优化与企业级实践
5.1 性能优化技巧
-
精准Tiling:UB的大小是宝贵资源。Tiling的目标是让每个数据块尽可能大,以减少循环次数,同时又要保证能放进UB。需要仔细计算每个Tensor所需空间,并考虑Double Buffer的开销。
-
内存对齐:
DataCopy操作务必保证源地址和目标地址是32字节对齐的。非对齐的访问会引起性能劣化。使用__builtin_acl_ub_malloc等接口分配内存时可以指定对齐大小。 -
流水线饱和度分析:使用Profiling工具(如msProf)分析流水线的时间线,如果发现计算单元存在大量空白(Bubble),说明CopyIn速度跟不上,可以尝试调整Tiling大小或检查对齐情况。
5.2 常见问题(FAQ)与排查指南
|
问题现象 |
可能原因 |
排查建议 |
|---|---|---|
|
结果不正确 |
数据竞争、Tiling计算错误 |
检查多核偏移计算是否正确;使用 |
|
性能不达预期 |
非对齐访问、流水线不饱和 |
使用Profiler检查流水线时间线;确认所有拷贝地址均已对齐。 |
|
编译错误或运行崩溃 |
UB溢出、地址越界 |
复核所有Queue申请的内存总量是否超出UB限制;检查所有内存访问是否在合法范围内。 |
笔者的经验之谈:在开发复杂融合算子时,建议采用“渐进式”实现。先实现一个单核、单缓冲区的、功能正确的版本,然后再逐步引入多核、Double Buffer、以及更复杂的融合逻辑。这样能极大地降低调试难度。
5.3 企业级实践:以InternVL大模型适配为例
如在Atlas 300I/V Pro上适配InternVL这类大模型时,算子的性能至关重要。通过将模型中的Matmul -> BiasAdd -> LeakyRelu模式识别出来,并替换为我们自定义的融合算子,可以带来显著的性能收益。其主要优势在于:
-
减少带宽压力:避免了中间矩阵的写回和读取,对于大矩阵而言,节省的传输时间非常可观。
-
提升计算密度:Cube和Vector单元连续工作,减少了空等,提升了硬件利用率。
6 总结与展望
Ascend C的融合算子编程范式是一种“工匠式”的编程艺术,它要求开发者对硬件架构(存储层次、计算单元)有深入的理解。通过SPMD并行模型、三级流水线、TPipe/TQue抽象和Double Buffer等核心技术,开发者能够精细地控制数据流和计算流,最终实现极致的算子性能。
尽管入门门槛较高,但CANN社区正在不断进步。更高层次的抽象接口(如Matmul高阶API)正在降低特定算子的开发难度。未来,我们期待出现更智能的编译优化技术和更完善的自动化工具链,让开发者能更专注于算法逻辑本身,而将性能优化更多地交给底层系统。
官方参考链接
-
昇腾社区首页:获取CANN、驱动等最新软件包和公告。
-
AscendC算子开发指南 - 昇腾社区:最权威的官方开发文档。
-
矢量编程-算子实现-自定义算子开发-AscendC算子开发-CANN:矢量算子的官方实现流程。
-
华为云社区-CANN:包含大量优质的技术博客和实践案例。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)