聊透CAD Coder:SFT和GRPO怎么让AI写对CAD代码?
对!参数完全不变,靠大模型的 “概率采样”,从同一个输出分布里抽不同写法 —— 就像同一个学生做同一道题,试不同解法。CAD Coder 的逻辑其实很简单:SFT 教 AI “会写 CAD 代码”,GRPO 教 AI “写好 CAD 代码”。整个框架最妙的就是 GRPO 的 “多组对比 + 领域奖励”—— 不搞虚的,只盯着 “能运行、形状准” 这两个核心需求优化。
AI 写 CAD 代码,核心就靠 “两步走”
之前聊过,传统 CAD 建模得手动写代码或拖拽,又麻烦又有门槛。CAD Coder 的目标特简单:你用文字描述需求(比如 “画个 20×15×10mm 的长方体”),AI 直接输出能运行的 CADQuery 脚本,还得形状精准、不报错。
这背后其实就两个关键步骤:SFT 让 AI “会写”,GRPO 让 AI “写好”。咱们顺着之前的疑问,一步步拆明白,不搞复杂术语~
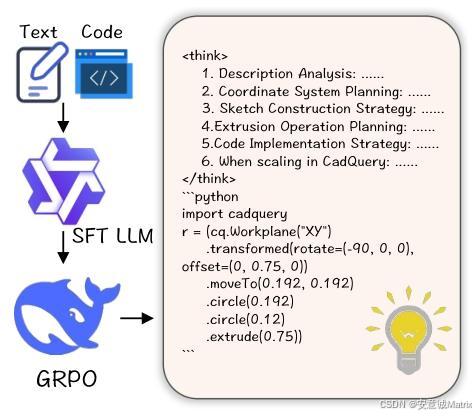
一、SFT:先给 AI 打基础,让它 “看得懂需求、写得出代码”
SFT 说白了就是 “监督微调”,相当于给预训练大模型(LLM)上 “CAD 代码入门课”,核心是教它 “文字需求→CAD 代码” 的对应关系。
1. 具体怎么做?就 3 步:
-
先攒数据:找一堆 “文字描述 + 对应 CADQuery 代码” 的配对(比如 “生成长方体”→ 对应的 box () 代码);
-
训练目标:让模型学 “猜下一个代码单词”—— 比如前面写了
cq.Workplane("XY").,模型得猜到下一个是box(20,15,10),猜错了就扣分(用的是交叉熵损失,不用记名字,知道是 “猜词扣分” 就行); -
结果:模型学会后,输入文字能生成语法正确、能运行的 CAD 代码,但可能有小问题 —— 比如尺寸差一点,或者代码写得冗余(能跑但不最优)。
2. 为啥要有 SFT?
就是给后续优化打地基!如果直接让模型上强化学习(GRPO),它连 CAD 语法都不懂,生成的全是错代码,后续优化根本没法搞。SFT 先让模型 “入门”,保证输出的代码 “能跑”,GRPO 再负责 “跑好”。
二、GRPO:给 AI “挑错改进”,从 “能跑” 到 “跑好”
SFT 的问题很明显:只学了 “文字→代码” 的表面映射,不管几何形状对不对、代码优不优。GRPO 就是来解决这个的,它是强化学习的一种,核心逻辑是 “多试几种方案,选最好的,让模型记下来”。
1. GRPO 完整流程(咱们结合之前的疑问拆):
咱们拿 “画 20×15×10mm 长方体” 这个需求举例,一步步看它怎么运作:
步骤 1:写提示词(不用复杂,说清需求就行)
直接说清楚 “要啥 + 要求”:
“用 CADQuery 语法画个长方体,长 20mm、宽 15mm、高 10mm,脚本要能运行,尺寸别错,代码越简单越好”
步骤 2:同一模型生成多组脚本(重点回应你的疑问!)
这里关键是:用的是 SFT 训练后的同一个模型,参数没改!
-
为啥能生成多组不同的?因为大模型生成时是 “概率采样”(比如调个 temperature=0.7),不是固定输出 —— 就像同一个人做同一道题,可能用不同解法,模型参数不变,也能从 “可能的代码分布” 里抽不同写法;
-
生成多少组?论文里是 8 组,比如其中两组:
# 一组简洁的(最优)
import cadquery as cq
result = cq.Workplane("XY").box(20,15,10)
show_object(result)
# 一组冗余的(能跑但麻烦)
import cadquery as cq
sketch = cq.Workplane("XY").rect(20,15) # 先画矩形
result = sketch.extrude(10) # 再拉伸
show_object(result)
步骤 3:跑脚本、生成几何模型
把 8 组脚本逐一带入 CADQuery 运行:
-
能跑的:生成对应的 3D 模型(输出点云 / 网格数据);
-
跑不了的(语法错、参数错):直接淘汰,奖励分 0 分。
步骤 4:给每组脚本打分(按 CAD 的需求来)
打分不看 “代码顺不顺”,只看 3 个实用维度,总分加起来:
-
几何保真度(最关键):生成的模型和目标形状差多少?用 Chamfer 距离算,差得越少分越高(比如完美匹配得 0.7 分,差一点得 0.5 分);
-
可执行性:能跑就加 0.2 分,跑不了 0 分;
-
格式合规:代码简洁、符合 CADQuery 语法加 0.1 分,冗余啰嗦扣 0.1 分。
步骤 5:算 “相对优势” 和 “不跑偏” 的约束
-
优势值:比如 8 组的平均得分是 0.8 分,某组得 1.0 分,它的优势值就是 0.2(比平均好);某组得 0.6 分,优势值就是 - 0.2(比平均差)—— 核心是让模型知道 “和自己的其他方案比,哪个更好”;
-
KL 散度:简单说就是 “不让模型忘本”—— 优化时不能偏离 SFT 教的基础语法,比如不能为了追求高分,生成语法错误的代码(权重 β=0.01,轻微约束就行)。
步骤 6:调整模型参数(还是同一个模型!)
把优势值、KL 散度代入 GRPO 的损失函数,核心逻辑是:
-
给 “优势值高” 的脚本加权:让模型以后更愿意生成这类优质代码(比如之前生成简洁版的概率 20%,优化后涨到 50%);
-
限制更新幅度:用 clip (1-ε,1+ε)(ε=0.2),避免模型一下子跑偏;
-
最终:反向传播更新模型参数,把 “选出来的好方案” 记到模型里。
步骤 7:重复迭代
用批量的提示词(比如画圆柱、正方体、复杂零件)重复上面 1-6 步,直到模型生成的代码,大部分都能精准跑对几何形状。
2. GRPO 到底牛在哪?
-
用 “多组对比” 代替 “单组评判”:避免奖励函数有误差(比如某组代码刚好踩中高分点),让模型知道 “同需求下哪个方案真的好”;
-
贴合 CAD 的实际需求:不纠结代码 “通不通顺”,只在乎 “能不能跑、形状对不对”;
-
不丢基础:KL 散度约束让模型不忘 SFT 教的语法,不会为了高分乱生成。
三、之前的核心疑问,再总结一遍
1. 生成多组用的是同一模型参数吗?
对!参数完全不变,靠大模型的 “概率采样”,从同一个输出分布里抽不同写法 —— 就像同一个学生做同一道题,试不同解法。
2. 无论哪组胜出,调整的都是同一个模型?
没错!GRPO 的目标是优化模型的 “输出概率”:让优质代码的生成概率变高,劣质的变低,相当于把 “好解法” 固化到模型里,以后再遇到类似需求,优先输出优质代码。
3. 为啥非要生成多组,不能单组优化?
-
没对比就没好坏:单组代码不知道自己是优是劣,多组才能算 “相对优势”;
-
过滤误差:绝对评分(比如 Chamfer 距离)可能不准,多组对比能抵消误差;
-
覆盖更多方案:CAD 建模有多种合法写法,多组能让模型学到 “哪种写法更靠谱”。
最后说两句
CAD Coder 的逻辑其实很简单:SFT 教 AI “会写 CAD 代码”,GRPO 教 AI “写好 CAD 代码”。整个框架最妙的就是 GRPO 的 “多组对比 + 领域奖励”—— 不搞虚的,只盯着 “能运行、形状准” 这两个核心需求优化。
如果想复现这个逻辑,重点抓 3 个点:多组采样的参数(比如生成 8 组、temperature=0.7)、奖励函数的设计(几何保真度占比最高)、KL 惩罚的权重(β=0.01 差不多),这三个直接影响最终效果~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)