为什么LangChain不是最佳选择?深度解析!
本文探讨了LangChain框架的使用价值与局限性。文章首先区分了广义和狭义的LangChain定义,指出框架存在的根本意义在于封装重复劳动、沉淀最佳实践和统一代码风格。通过对比原生OpenAI SDK和LangChain实现fewshot提示工程的代码示例,作者揭示了LangChain API设计存在的冗长、不一致等问题,导致开发效率反而降低。文章引用Thoughtworks技术雷达对LangC
需要提前说明,存在广义和狭义两类对LangChain的定义。狭义上的LangChain即等同于在本章中我们使用到的LangChain框架,而广义上的LangChain代指的是LangChain技术厂牌,旗下包含 LangChain、LangSmith(一个用于调试、测试、监控大模型应用的平台)、LangGraph(一款用于制作包含管理复杂工作流的大模型应用的框架) 等多种产品。本小节所谈论到各种问题仅限于LangChain 框架本身而非代指所有与它有关的产品。
为什么我们需要框架
既然在第4章中我们已经借助OpenAI SDK完成了想要实现的功能,为什么还需要引入额外的代码库?在我看来框架以及类库存在最根本的意义,是对重复劳动的封装。
Loadsh是所有前端项目内必不可或缺的类库,它之所以被广泛采用并非因为其中的某个高精尖的技术特性,而是提供了许多常用开箱即用的功能,例如对数组去重、合并,对数据类型进行判断等等。去实现这类工具类函数并非什么难事,那为什么我们选择直接使用一款第三方类库而非是亲自去实现它?很简单,因为这能够帮助你节省大量的时间精力——对于此类功能你我的代码实现,乃至 Lodash 的代码实现不会有太大差异,在最终效果一致的情况下,考虑到专业的开源团队有足够的精力对代码提供稳定的持续保障,选择它们自然也就是顺理成章的事情。另一方面绝大部分的开发者在实际工作中承担的是以业务向导开发任务,能够编写工具代码的时间精力有限,市面上开箱即用的现成工具也就成了我们的不二之选。这便是是大多数框架之所以存在的底层逻辑。
除此之外,框架的另一层价值在于它代表对经验的沉淀,对模式的封装。
平心而论,在任何编程语言之下去实现一整套API服务并非难事,但为什么倾向去选择既有的API服务框架,例如Node.js里Express.js或者Python中的FastAPI?一分部原因来自于上述所说对时间精力的节省,更重要的是,尊循框架本身也等同于尊循最佳实践。
代码是有好坏之分的,我们所常常听到的可读性、时间效率、可拓展性等等便是区分好与坏的重要指标。那些能够带来好结果的行为通常被人们逐渐整理为最佳实践,而那些带来坏影响的行为则被称之为反模式或者坏味道。遗憾的是这类知识点的习得大部分来自于开发经验的积累,可如果团队中不同的成员水平参差不齐怎么办?那么很可能具有坏味道的代码便被不小心的注入代码库中——而框架则通过将开发者的代码限制在既定的约束内,杜绝了部分该类问题的发生。MVC(Model-View-Controller) 框架便是一个再合适不过的例子,你也许并不清楚 MVC 模式解决了什么样的问题,但该知识盲点并不妨碍你可以将代码拆分为不同的Model、View和Controller组件。如果你好奇 MVC 是否真的相比其他开发方式更加优秀,不妨尝试摒弃MVC框架并利用原生代码实现同样的一组功能,并不断的优化它。我相信在几个迭代之后,你摸索出来的最优解会与MVC不谋而合。
为什么我们需要推崇最佳实践?因为上面所说的种种关于代码“好”的指标,都指向软件工程的最终目的:提升代码的可维护性。倘若你继续探究,会发现它代表的不过是最朴素的降本增效思想,通过使代码变得易于修改,来降低维护的维护成本以及提升其交付速率。而最佳实践是达成这个目标的重要途径。
提升代码可维护性的另一个手段也同样是框架带来的第三类优势:统一团队代码风格。如果你让十位来自不同背景不同经验的程序员来实现同一组功能,你会得到十套不同类型的代码。虽然独一无二的代码对于个体来说代表着他颇具个性的一面,但来对于由一个团队集体维护的项目来说却是噩梦,因为这意味着其中的每一位团队成员为了理解他人所写的代码,都要提前了解其他团队成员的代码风格和流派,这会给项目的开发过程带来不小的负担。所以让团队站在同一起跑线上,对尽可能能多的问题达成一致,有助于将代码知识传递下去。最理想的情况便是由不同成员的产出的代码都犹如同一人所写。框架是解决此类问题的一个手段,另一类常见实践便是在代码库甚至IDE中内置格式检查工具。
综上所述,节省开发成本、封装最佳实践、统一代码风格是我们优先选择框架的原因,其旨在提升代码的可维护性。扩展到更广的层面,这套逻辑同样适用于我们依赖的各类云服务。从无服务计算(Serverless Computing)再到低代码平台(Low Code Platform)——技术并非凭空被发明出来,他们是经验的化身。
何谓好的框架
GitHub上的收藏数量、代码库的更新频率、版本的发布速度等等显性指标,当然都可以成为判断的开源框架的好坏标准。而在数值之外还有什么是我们值得关注的?这里给出两点我的建议。 首先,最好的框架理应是没有框架。
许多项目在搭建之初出于惯性,优先想要回答的问题是选择哪一款框架而不是我们是否需要框架,这给项目带来了不必要的负担。许多人忽略了框架的引入是存在代价的,学习成本便是其中之一。回想一下你第一次熟悉某个技术框架时的经历,肯定充满坎坷:去学习定义不同类型的组件,学习如何进行组件间的通信,在论坛上提问如何实现你想实现的功能等等。问题不在于代价本身,而在于付出与收益是否等价。在我的工作经历中,框架带来的负面影响的事例不在少数,例如团队经理盲目选择了某个时髦框架,却因为没有团队成员精通该框架的缘故,导致开发中总是有代码被分配到了错误的职责,或者采用了官方不推荐的反模式。又例如开发人员还需定期对框架进行升级。注意此类升级并非是对开发者无感的,因为框架自身升级过程中难免会引入破坏性修改,这会导致项目代码与框架的集成失效。因此由框架升级而引发的项目本身的代码改动和小范围的回归测试都在所难免。这些都应该计算在引入框架的成本中。
其次,好的框架应该容易让人们把事情做对,难以把事情做错。
如果你选择的框架团队内鲜有人能够理解它的概念,更很少有人难把它按照最佳实践写对,这并非是一个好兆头。无论它号称能够提升多少倍性能或者减少多少人天的成本,显而易见至少在你的团队是可望不可及的。项目说到底是由一群人来维护,我们应该尽可能的降低项目的门槛用于容纳不同层次的开发者。如果项目的绝大部分问题都依赖团队的某个明星程序员来解决,亦或是项目质量完全依靠团队经理来把控,你应该为对此感到警惕。
前端领域中的Redux就是一个很好的反面例子,如果你有兴趣将Redux文档与当下同样流行的 Flux 框架文档进行比较(例如 Mobx,Zustand,Akita),就会发现学习Redux需要掌握的概念相比其他竞品来说复杂的令人发指,稍不小心便会踏入官方不推荐的反模式中。这也是Redux Toolkit诞生的原因,它旨在解决原生Redux高度的抽象以及缺少最佳实践的问题,通过丰富模板代码来帮助开发者迅速找到常规问题的解决方案。如今官方早已将Redux Toolkit作为学习和使用Redux的首选平替。
你也许会疑惑为什么我们要花如此长的篇幅聊框架决策中的种种考量,因为接下来你将看到我是如何运用这些原则来选择出我们心仪的大模型框架的。
你也许不需要框架
在回答选 A 还是选 B 之前,我还是想不厌其烦的提醒各位:也许你并不需要框架。我们不妨回顾以一下第四章中借助OpenAI SDK实现与大模型进行对话的代码示例,代码如下所示
from openai import OpenAIfrom dotenv import load_dotenvload_dotenv()client = OpenAI()completion = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user","content": "What's your name?",}])
我们可以轻松的将这段代码使用其他框架进行改写,使用 LangChain重写之后的代码如下所示:from langchain.prompts \import SystemMessagePromptTemplate, \HumanMessagePromptTemplate, \ChatPromptTemplatefrom langchain_openai import ChatOpenAIllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.5)prompt = ChatPromptTemplate.from_messages([SystemMessagePromptTemplate.from_template("You are a helpful assistant."),HumanMessagePromptTemplate.from_template("What's your name?")])chain = prompt | llm
即使你从未学习过LangChain,也不妨碍你理解这段代码的逻辑。与原版相比其最大的不同在于将传递给 大模型的消息使用模板组件进行了封装,原代码中的SystemMessage与HumanMessage被工整的替换为了SystemMessagePromptTemplate和HumanMessagePromptTemplate。在LangChain中使用 Template组件的好处是可以通过将提示语句中常用部分提取出来,将其抽象为模板。
例如在实际的使用场景中,”You are a helpful assistant” 这类用于指定角色的提示语通常是固定的,我们便可以选择利用模板固化下来,将用户的输入提取为变量。依据上述思路修改之后的代码如下所示:
prompt = ChatPromptTemplate.from_messages([SystemMessagePromptTemplate.from_template("You are a helpful assistant"),HumanMessagePromptTemplate.from_template("{user_input}")])
注意上述代码中用户的提问内容已经被替换为了变量user_input,当后续我们想要与大模型进行对话时,仅需要向模板传递变量值即可,如代码如下所示:
chain = prompt | llmres = chain.invoke({"user_input": "Explain LLM like I'm 5"})
在这个例子里,我展示了LangChain在提示语生成方面能够提供的能力,但我想提出的问题是,这个特性真的是你需要的吗?所有OpenAPI中的概念被平移到了LangChain当中被再次定义,以|符号为代表的新的编程范式被引入,最终结果没有任何变化但代码的复杂度却显著提升了。
我的建议是,如果你的应用针对的是单一场景,无需灵活多变的提示语句,便不必将提示语句封装为模板。即使你想将提示语句抽象为模板,框架并非是唯一的方式。Python 原生自带的 f-string 语法据支持将表达式内嵌于子符串中,如下所示,人名被提取为变量。
user_name = "Alice"greeting = f"""Hello {user_name}, welcome to the data science tutorial!"""
如果你不确定框架会给你带来何种优势,盲目的将其引入便会产生我在上一小节中提到的那些弊端。在上述代码中你已经看到,种种大模型概念在LangChain中被再次封装,却看不到由此带来的额外收益。事实上OpenAI作为开放平台,它本身就已经提供了足够多的接口来完成大部分常见需求。考虑到OpenAI SDK作为官方出品的类库,它们更新频率和更新质量肯定会比由社区维护的开源类库更加稳定,因此优先使用第一方类库也是项目质量的无形保障。我越来越多的在有关大模型应用开发的论坛中,在Hacker News社区里看到开发者们在逐渐达成此类共识:大多数时候你无需依赖框架来开发大模型应用。框架的优势体现原型的搭建、任务的调度与编排上。
为什么不推荐 LangChain
无论是OpenAI还是Google Gemini,官方自身提供的能力始终存在着上限,我们需要在社区中寻找突破点。
毋庸置疑LangChain是时下风头最劲的框架之一,我相信在你能够搜索到的有关大模型应用开发的教程中,与LangChain有关的课程一定占据了相当大的比例。但你可能没有留意到的是,近些年业内对于LangChain的批评声音却变得越来越多,LangChain的颓势在愈发显现。
最直观的便是Thoughtworks技术雷达(Technology Radar)对于 LangChain 态度的变化。技术雷达是科技领域咨询公司Thoughtworks每年两次定期发布的技术趋势指南。在每一期发布的指南中他们会对新兴技术的成熟度与潜力进行打分,读者可以将技术所属的成熟度状态(如试验、评估、采纳、淘汰)来作为技术选型的参考之一。LangChain于2023年4月入选第28期技术雷达,成熟度状态为“评估”;在2024年4月第30期技术雷达中成熟度则被降至“暂缓”,即不推荐在项目上引入;在2024年10月第31期技术雷达中 LangChain被彻底移除。LangChain 被淘汰的理由在它的评级被降至“暂缓”时给出了充分的说明:
……然而,我们还发现其存在 API 设计不一致且冗长的情况。因此,它经常会掩盖底层实际发生的情况,使得开发者难以理解和控制 LLMs 及其周围的各种模式在背后实际是如何工作的……
这里所说的API并非是狭义上的HTTP API,而是指广义上代码间的通信接口。考虑到API是代码与框架的主要沟通方式,欠佳的 API 设计意味对开发者而言项目与框架集成之路将变得困难重重。这里的批评也并非空穴来风,接下来我用一个例子来说明 LangChain API 存在的问题。
在提示工程中有一类技巧叫做few shot,即在编写的提示语句中有意包含一些范例,便于大模型更好的推测我们的意图以给出更为精准的答案。例如在向模型询问“big”的反义词之前,在提示语句中提前给出反义词的相关事例,具体提示如下:
Give the antonym of every input
Input: happy
Output: sad
Input: tall
Output: short
Input: energetic
Output: lethargic
Input: sunny
Output: gloomy
Input: windy
Output: calm
Input: big
Output:
大模型在读到诸多事例之后,即刻就会领悟到我们想要简短直接的回答,并且答案必须契合“Input/Output”这类格式。用原生的Python将上述的提示语抽象为代码实现也非难事,实现代码如下所示:
def generate_few_shot_prompt(pairs):prompt = "Give the antonym of every input\n\n"for pair in pairs:input_word = pair['input']output_word = pair['output']prompt += f"Input: {input_word}\nOutput: {output_word}\n\n"return prompt
在调用该方法时,只需要将所有事例的input和ouput值组装成字典结构,然后以成数组形式传入函数中即可,代码如下所示:pairs = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},{"input": "big", "output": ""}]few_shot_prompt = generate_few_shot_prompt(pairs)
那现在不妨看看在LangChain框架之下应该如何实现上述功能。LangChain few shot这类业务场景提供了名为FewShotPromptTemplate的提示模板,借助模板的代码实现如下所示:
from langchain_core.example_selectors \import LengthBasedExampleSelectorfrom langchain_core.prompts \import FewShotPromptTemplate, PromptTemplateexamples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},]example_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",)prompt = FewShotPromptTemplate(examples=examples,example_prompt=example_prompt,prefix="Give the antonym of every input",suffix="Input: {adjective}\nOutput:",input_variables=["adjective"],)print(prompt.format(adjective="big"))
我们对上述代码稍作分析,来理解在 LangChain 中是如何实现上述功能的:-
需要在代码库中同时引入
PromptTemplate和FewShotPromptTemplate模板组件。 PromptTemplate用于创建常规提示,包含模板内容与变量定义,它与few shot场景无关。
FewShotPromptTemplate虽然从名称上同为“模板”,但实际上它去更像是原模版的“封装”或者“改善”工具。因为从使用方式上看,它不仅为原模版补充了前缀部分(prefix)和提问部分(suffix),还负责将诸多事例(examples)注入进提示语中。
也就是说为了生成出一个带有特定模式的提示语句,在LangChain中我们需要引入两个模板组件(PromptTemplate和FewShotPromptTemplate),定义三个模板变量(PromptTemplate中的input 与output,FewShotPromptTemplate中的adjective),还需要保证事例中数据格式与模板的变量格式相匹配。
很显然这么做过于复杂了,别忘了我们只是想生成一个具有特定模式的字符串而已。在更早的代码中看到我已经展示了如何在无需学习额外知识的情况下,用更短的代码达成同样的效果。
将few shot固化在代码中的做法本来就有待商榷,因为包括few shot、chain of thought、least to most 等等各类提示语技巧,本质上是解决问题的种种思路,它们为代码实现提供了无数种可能性。而将思路固化在框架中的做法似乎是反其道而行之,反而给这个技巧的发挥套上了枷锁。
更可怕的是 LangChain还提供了几乎一模一样的兄弟组件FewShotPromptWithTemplates,仅仅是为了支持将模板作为参数传入,例如我可以将原子符串类型的prefix和suffix变量替换为模板,代码如下所示:
# 在这里 prefix 与suffix 不再是上段代码中简单的子符串,# 而是被定义为可以用于生成提示语的模板prefix_template = PromptTemplate(input_variables=["say_hi"],template="{say_hi}, Give the antonym of every input\n\n")suffix_template = PromptTemplate(input_variables=["adjective"],template="Input: {adjective}\nOutput:")few_shot_prompt_with_templates = FewShotPromptWithTemplates(# ......input_variables=["adjective", "say_hi"],prefix=prefix_template,suffix=suffix_template)new_input = {"adjective": "big","say_hi": "Hello"}prompt = few_shot_prompt_with_templates.format(**new_input)
在我看来这是一处明显的API设计失误,正确的做法应该是让组件去兼容更多种可能性(例如前端的DOM 选择器querySelecor方法),而非为不同的可能性提供不同的接口。后一种做法会让框架的维护者和使用者都变得狼狈,因为对于维护者而言者,这意味着他需要更频繁及更大面积的对框架进行更新(所以这也是为什么LangChain的API文档更新总是不够及时的原因,诸多的API你只可能在官网上找到参数说明,而找不到如何使用的事例);同时对使用者而言,这也提高了他使用框架的难度,因为他也务必精准找到适用于他的API 。这其实变相降低了框架的容错性,也与我们之前所说的“容易让人们把事情做对”的原则相违背。
有几篇对 LangChain 批评的文章影响力颇大,比如 why we no longer use LangChain for building our AI agents 以及 The Problem With LangChain,前者在 Hacker News 上引起了广泛的讨论,后者也被技术雷达所引用。如果大家有兴趣可以通过这些材料来更进一步的理解 LangChain 当前所存在的其他问题。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接👇👇

为什么我要说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
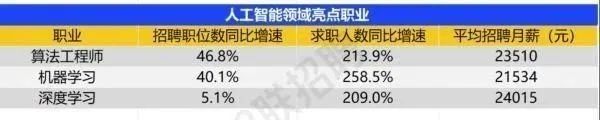
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献647条内容
已为社区贡献647条内容

所有评论(0)