AI如何理解我们的世界?- Embedding
摘要: 嵌入(Embeddings)是AI理解复杂世界的关键技术,它将文字、图像等对象转换为数字向量,捕捉其内在关系。通过降维处理,嵌入技术高效压缩高维数据,保留核心语义。相比传统的独热编码,嵌入能识别相似性(如“鸟巢”和“狮穴”)和反义关系(如“昼夜”)。现代模型(如BERT)更进一步,结合语境动态调整词义表示。嵌入通过机器学习不断优化,驱动推荐系统、大语言模型等AI应用,成为机器理解人类语言与
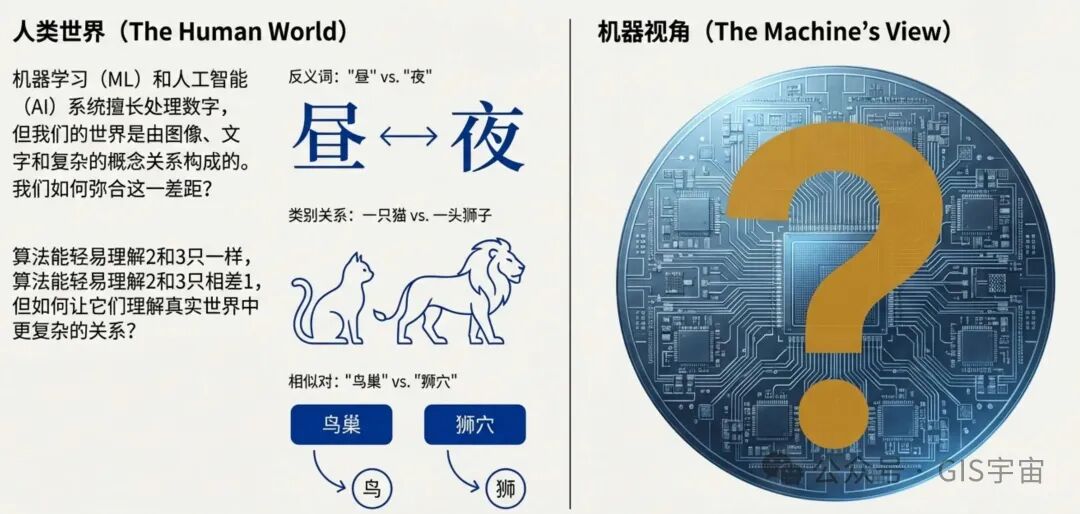
计算机如何能理解“鸟巢”和“狮穴”是相似的对偶关系,而“白天”和“黑夜”却是反义词?这些看似简单的常识,对机器来说却是一个巨大的挑战。答案就隐藏在机器学习的一个核心概念中——嵌入(Embeddings)。你可以把它想象成AI的“翻译官”或“解码器”,它能将我们复杂的真实世界翻译成机器可以理解的语言,从而揭示事物之间隐藏的深刻联系。
1. AI也懂“类比”?嵌入让机器像人一样思考关系
嵌入的核心功能,就是将真实世界的对象(如文字、图片、声音)转换成由数字组成的向量(Vector)——一种复杂的数学表示形式。这种表示并非随机的数字,而是精心设计用来捕捉对象之间固有的属性和关系。 例如,AI通过嵌入技术可以理解“鸟巢和狮穴是相似对”,因为它们都是动物的居所;同时也能明白“昼夜是相反词”。它将这些抽象的关系,转化成了可以在数学空间中衡量和比较的距离与方向。
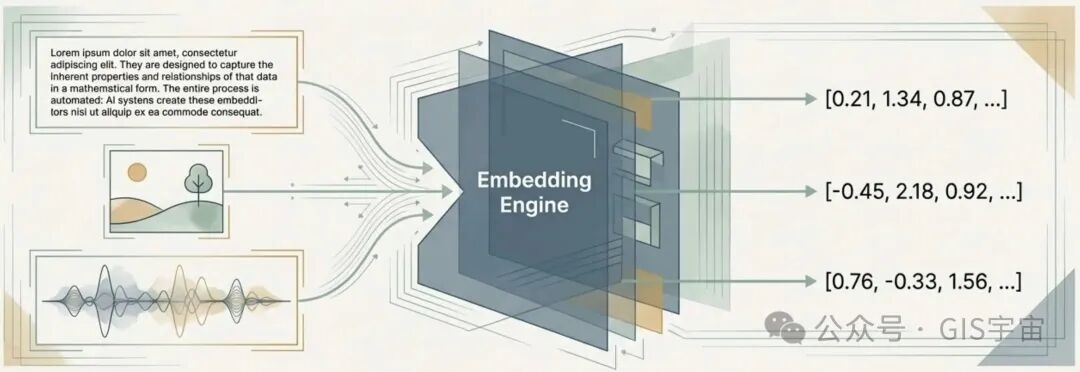
嵌入是真实世界对象的数字表示,机器学习(ML)和人工智能(AI)系统利用它来像人类一样理解复杂的知识领域。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
2. AI的数据“瘦身”魔法:成千上万的特征如何被压缩成精华
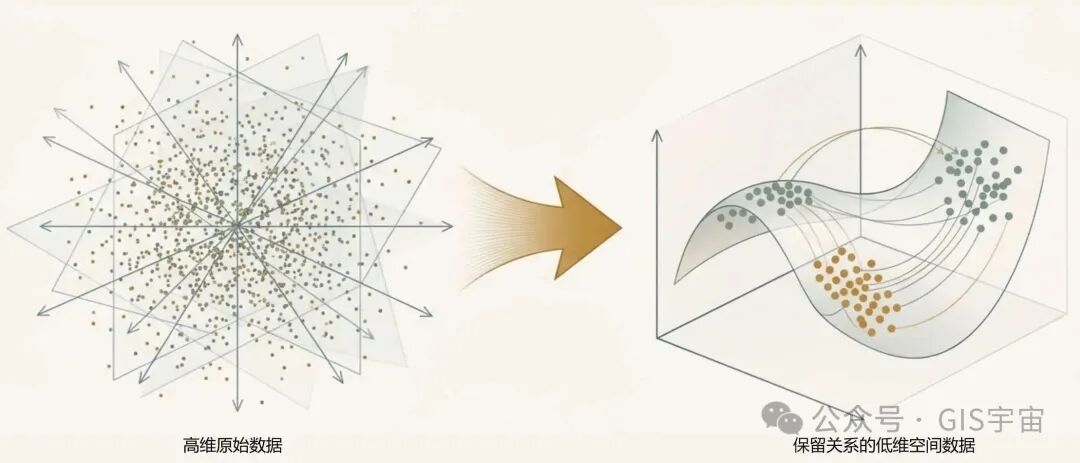
我们生活在一个数据爆炸的时代,而很多数据都是“高维”的。所谓高维数据,就是指描述一个事物需要非常多的特征或属性。例如,一张图片可以被视为高维数据,因为其中每一个像素的颜色值都是一个独立的维度。
处理这类数据对计算机来说是一个巨大的负担,需要海量的计算能力和时间。而嵌入技术就像一个高效的数据“浓缩”大师。它通过识别不同特征之间的共同点和模式,将数据从数百甚至数千个维度压缩到更低的维度空间。这个过程被称为“降维”,它极大地减少了AI处理数据所需的计算资源和时间,同时巧妙地保留了数据中最重要的语义和语法关系,确保“浓缩”后的信息依然富有意义。
3. 告别“贴标签”:从独热编码到嵌入的巨大飞跃
在嵌入技术普及之前,机器学习通常使用一种叫做“独热编码”(one-hot encoding)的方法来处理分类型数据。这本质上就是一种机械的“贴标签”,系统只知道有这些标签,却不理解标签之间的任何内在联系。想象一下下面这张表格:
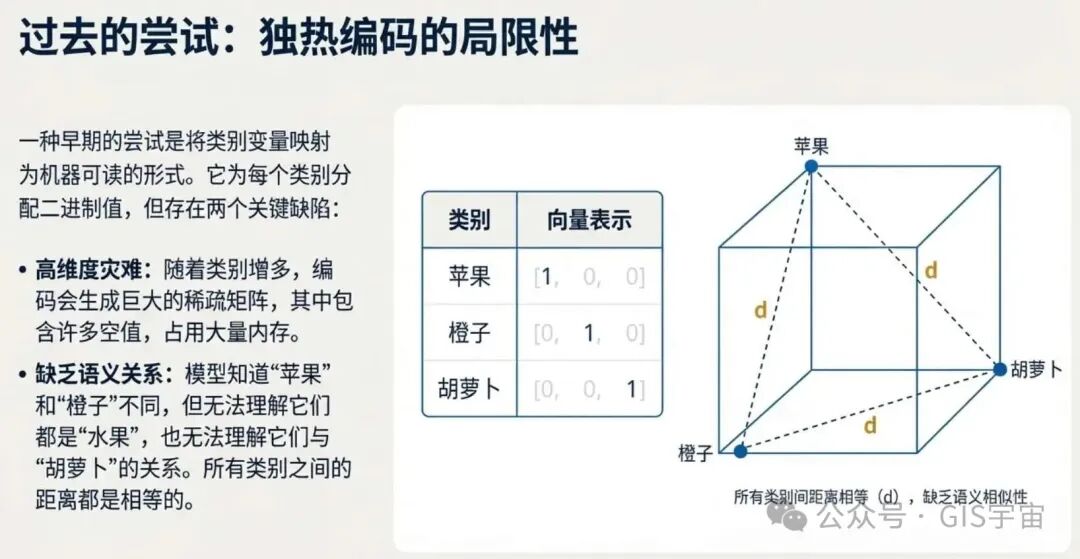
独热编码会为每个类别创建一个独立的二进制维度,比如苹果是 [1, 0, 0],橙子是 [0, 1, 0]。这种方法的致命弱点在于,它无法告诉模型对象之间的任何关系。此外,当类别非常多时,这种编码会产生大量稀疏数据,极其浪费内存空间。
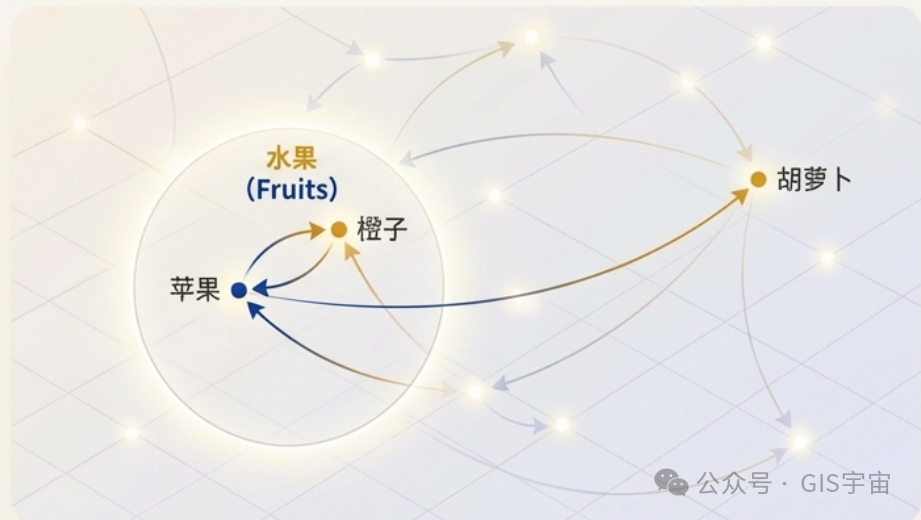
嵌入技术则完美地解决了这个问题。在独热编码的数学世界里,“苹果”和“橙子”的距离与“苹果”和“胡萝卜”的距离毫无区别。
而在嵌入空间中,“苹果”和“橙子”的向量会紧密相邻,这才是真正的理解。这标志着AI从简单的分类标记,迈向了对事物关系更深刻的洞察。
4. 语境为王:为什么同一个词在AI眼中有不同“身份”
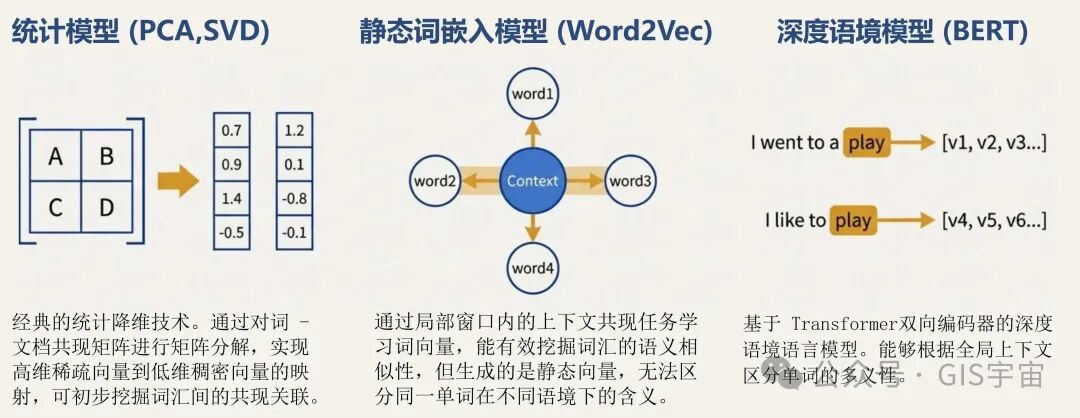
早期的嵌入模型(如Word2Vec)已经能够通过分析大量文本,发现单词之间的相似之处。但它们有一个局限:无法区分同一个词在不同语境下的含义。
更先进的模型,如基于转换器(Transformer)的BERT,则带来了革命性的突破。它能够真正理解“语境”。例如,在下面这两个句子中:
• “I went to a play” (我去看了一场戏剧)
• “I like to play” (我喜欢玩)
BERT模型会为单词“play”创建两个完全不同的嵌入表示。第一个嵌入会与“剧院”、“表演”等词的嵌入更接近,而第二个则会与“游戏”、“运动”等词的嵌入更接近。这一点至关重要,因为它标志着AI在真正理解复杂而微妙的人类自然语言方面取得了巨大的飞跃。
5. 嵌入并非“天生”,而是“后天习得”
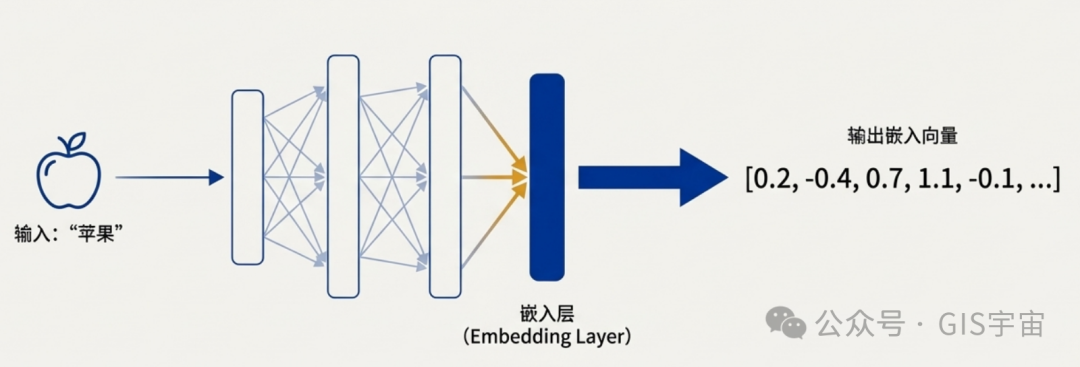
嵌入表示并不是由工程师手动设定的固定转换规则,而是一个由人类专家监督、神经网络通过数据训练“学习”到的动态能力。这个过程更像是一场持续的调优,而非一次性的转换:
- 首先,工程师向神经网络提供一些手动准备好的、已经矢量化的样本数据。
- 神经网络从这些样本中学习,发现其中隐藏的模式和关系。
- 工程师可能需要对模型进行微调,以确保其将输入特征合理地分布到适当的维度空间中。
- 随着时间的推移,嵌入会独立运行,使模型能够根据矢量化表示来生成预测或推荐。
- 这是一个持续的过程,工程师会继续监控嵌入的性能,并使用新数据对其进行微调和优化。 这个“学习”过程完美体现了机器学习的本质:不是被动地执行指令,而是在人类的引导下,主动地从数据中发现知识和规律。
结论
从推荐你可能喜欢的电影,到大型语言模型(LLM)与你对答如流,嵌入技术已经成为驱动现代AI应用不可或缺的基石。它赋予了机器一种前所未有的能力,去理解我们这个充满复杂关系和微妙语境的世界。

好啦,关于Embedding就介绍到这里,这也是我们LLM系列的开篇。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)