了解视觉语言大模型(VLM),你需要知道哪些内容?
摘要: 视觉语言模型(VLM)融合计算机视觉与自然语言处理,具备跨模态理解能力,支持图像分类、视觉问答等任务。相比传统CV模型,VLM泛化性强,无需针对特定任务重新训练。其核心组件包括视觉编码器和语言编码器,通过多阶段训练实现文本与图像的语义对齐。应用场景涵盖图像生成、搜索、分割及视觉问答等。随着AI大模型快速发展,VLM成为新兴领域的重要方向,人才需求激增。学习VLM需系统化路径,现有资源可助力
为什么需要了解VLM?
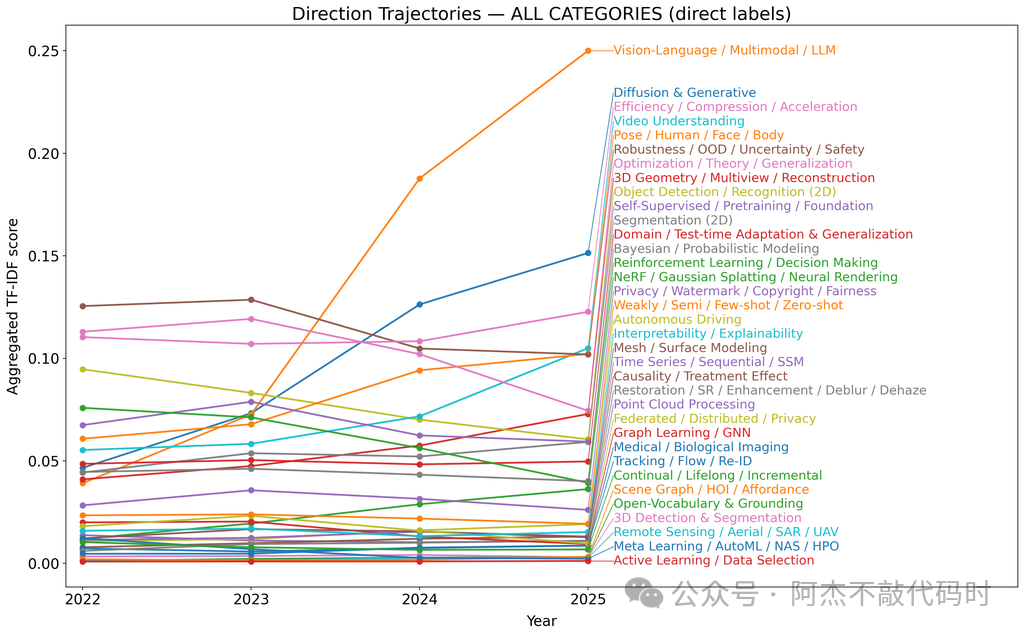
据不完全统计,截止到2025年10月份VLM的论文在持续上升,应用也更广泛,而传统CV模型热点下降许多。主要原因在于:这些基于卷积神经网络 (CNN) 的 CV 模型针对一组有界类上的特定任务进行了训练。如:
1、识别图像是否包含猫或狗的分类模型
2、种光学字符检测和识别 CV 模型,可读取图像中的文本,但不解释文档中的格式或任何视觉数据。
以前的 CV 模型是为特定目的而训练的,没有能力超越它们为其开发和训练的任务或一组类。如果用例发生了根本变化或需要向模型添加新类,开发人员将不得不收集和标记大量图像并重新训练模型。这是一个昂贵且耗时的过程。此外,CV模型没有任何自然语言理解能力。
VLM 通过结合基础模型 (如 CLIP) 和 LLM 的强大功能,带来了一类新的功能,从而同时具有视觉和语言功能。开箱即用,VLM 在各种视觉任务(如视觉问答、分类和光学字符识别)上具有强大的零样本性能。它们也非常灵活,不仅可以在一组固定的类上使用,还可以通过简单地更改文本提示来用于几乎任何训练用例的场景。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
什么是视觉语言模型以及概述?
现在Huggingface上面开发了许多VLLM模型。
IBM给出了一个很好的解释:视觉语言模型 (VLM) 是一种人工智能 (AI) 模型,其融合了计算机视觉和自然语言处理 (NLP) 功能。它被广泛定义为可以从图像和文本中学习的多模态模型。它们是一种生成模型,接受图像和文本输入并生成文本输出。大型视觉语言模型具有良好的零样本功能,泛化能力好,并且可以处理多种类型的图像,包括文档、网页等。用例包括谈论图像、通过指令进行图像识别、视觉问答、文档理解、图像标题等。一些视觉语言模型还可以捕获图像中的空间属。
VLM 学习文本数据与图像或视频等视觉数据之间的关系,从而允许这些模型从视觉输入生成文本或在视觉信息的上下文中理解自然语言提示。
VLM 也称为可视语言模型,它将大型语言模型 (LLM) 与视觉模型或视觉机器学习 (ML) 算法相结合。
作为多模式 AI 系统,VLM 以文本和图像或视频作为输入,并产生文本作为输出,通常以图像或视频描述的形式,回答有关图像的问题或识别图像的某些部分或视频中的对象。
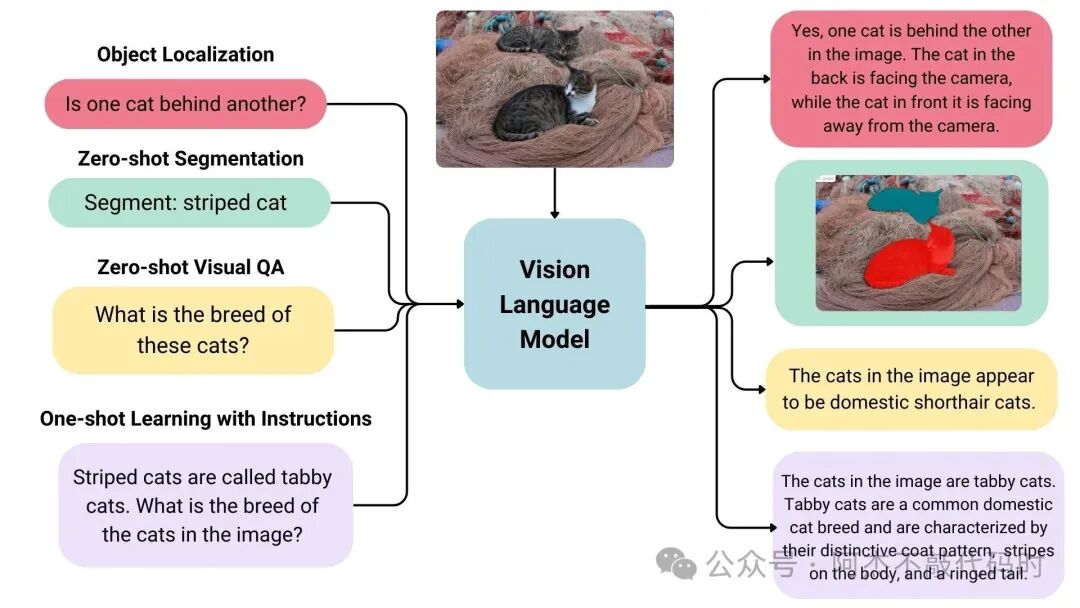
视觉语言模型有哪些部分?
视觉语言模型是一种人工智能系统,将大型语言模型 (LLM)与视觉编码器相结合,赋予VLLM “看” 的能力。因此VLM 通常由两个关键组件组成:语言编码器、视觉编码器。
语言编码器(Language encoder)
语言编码器捕获单词和短语之间的语义和上下文关联,并将其转换为文本嵌入,以供 AI 模型处理。
大多数 VLM 使用一种特定的神经网络架构,称为转换器模型,作为其语言编码器。转换器的示例包括 Google 的 BERT(基于转换器的双向编码器表示),这是支持当今许多 LLM 的最早的基础模型之一,以及 OpenAI 的生成式预训练转换器 (GPT)。
以下是转换器架构的简要概述:
a) 编码器将输入序列转换为称为嵌入的数字表示,以捕捉输入序列中词元的语义和位置。
b) 自注意力机制允许转换器将注意力“集中”在输入序列中最重要的词元上,而不管这些词元的位置如何。
c) 解码器利用这种自注意力机制和编码器的嵌入来生成统计上最可能的输出序列。
视觉编码器(Vision encoder)
视觉编码器从图像或视频输入中提取颜色、形状和纹理等重要视觉属性,并将它们转换为机器学习模型可以处理的向量嵌入。
早期版本的 VLM 使用深度学习算法(例如卷积神经网络)进行特征提取。更现代的 VLM 采用视觉转换器 (ViT),它应用了基于转换器的语言模型元素。
ViT 将图像处理成图块并将它们视为序列,类似于语言转换器中的词元。然后,视觉转换器会在这些图块上执行自注意力机制,从而创建一个基于转换器的输入图像表征。
应用这两项功能,VLM 可以处理并提供对提示中提供的视频、图像和文本输入的高级理解,以生成文本响应。
与传统的计算机视觉 (CV) 模型不同,VLM 不受一组固定的类或特定任务(如分类或检测)的约束。VLM 在大量文本和图像/视频字幕对的语料库上进行重新训练,可以用自然语言进行指导,并用于处理许多经典视觉任务,以及新的生成式 AI 驱动的任务,例如摘要和视觉问答。
视觉模型怎么工作、如何训练?
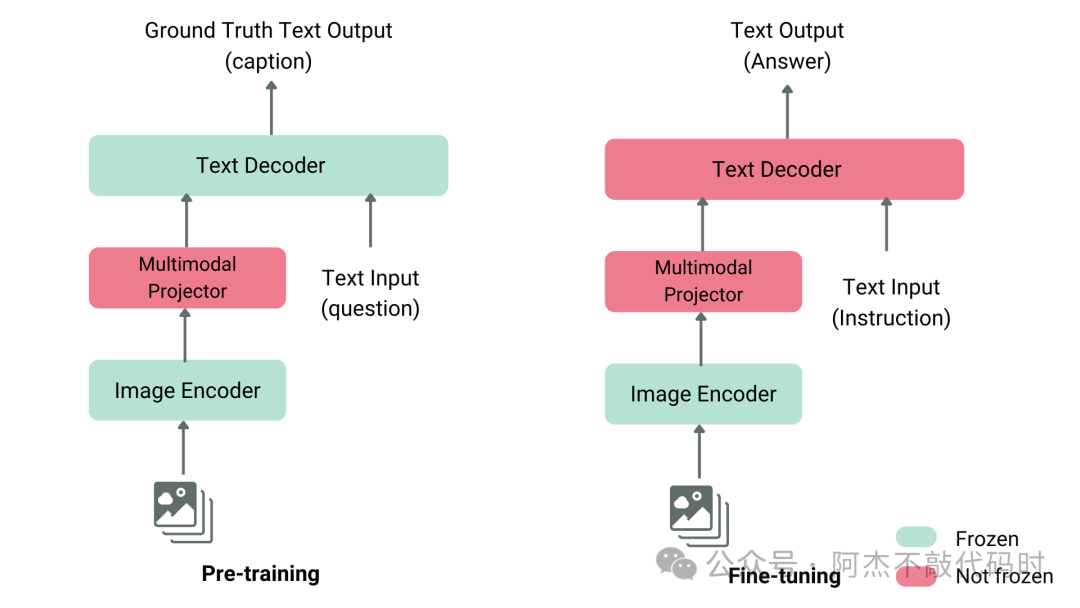
VLM 训练需要在几个阶段进行,包括预训练,然后是监督微调。或者,可以将参数高效微调 (PEFT) 作为最后阶段应用,在自定义数据上创建特定于域的 VLM。
预训练(PT)阶段使视觉编码器、投影仪和 LLM 在解释文本和图像输入时基本上使用相同的语言。这是使用具有图像标题对和交错图像文本数据的大型文本和图像语料库来完成的。一旦通过预训练对齐了这三个组件,VLM 就会经历一个有监督的微调阶段,以帮助它了解如何响应用户提示。
如下图所示,一个VLM模型需要进行了三阶段训练。第一阶段为投影器(Projector)训练,冻结视觉编码(VE)和大语言模型(LLM),第二阶段为投影器(Projector)和大语言模型(LLM)训练,第三阶段为针对自定义的数据进行指令微调,主要也是针对投影器(Projector)和大语言模型(LLM)训练。
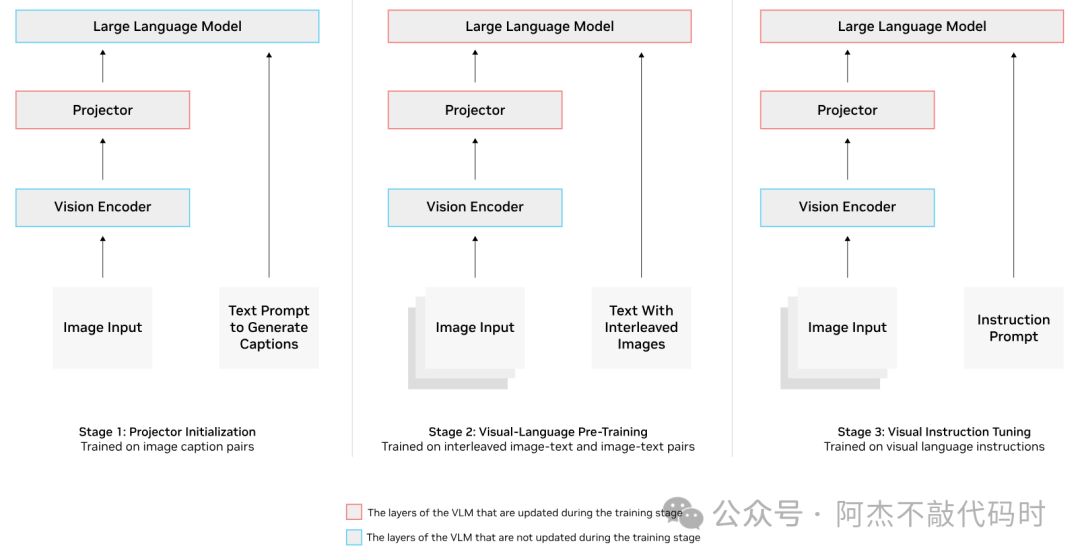
第三阶段阶段使用的数据是示例提示与文本和/或图像输入以及模型的预期响应的混合。例如,这些数据可以是提示,告诉模型描述图像或计算帧中的所有对象,并具有预期的正确响应。经过这一轮训练,VLM 将了解如何最好地解释图像并响应用户提示。
VLM 经过训练后,可以通过提供还可以包含文本中交错的图像的提示来以与 LLM 相同的方式使用它。VLM 将根据输入生成文本响应。VLM 通常使用 OpenAI 风格的 REST API 接口进行部署,以便轻松与模型交互。
VLM使用场景有哪些?
以前要做文本生成和视觉检测,需要 2 个独立的 AI 模型,现在可以合并为 1 个模型,而VLM 弥合了视觉和语言信息之间的差距。
VLM 可用于一系列视觉语言任务:字幕和摘要(Captioning and summarization)、 图像生成(Image generation)、 图像搜索和检索(Image search and retrieval)、图像分割(Image segmentation)、物体检测(Object detection)、视觉问题解答(Visual question answering) (VQA),详细介绍如下:
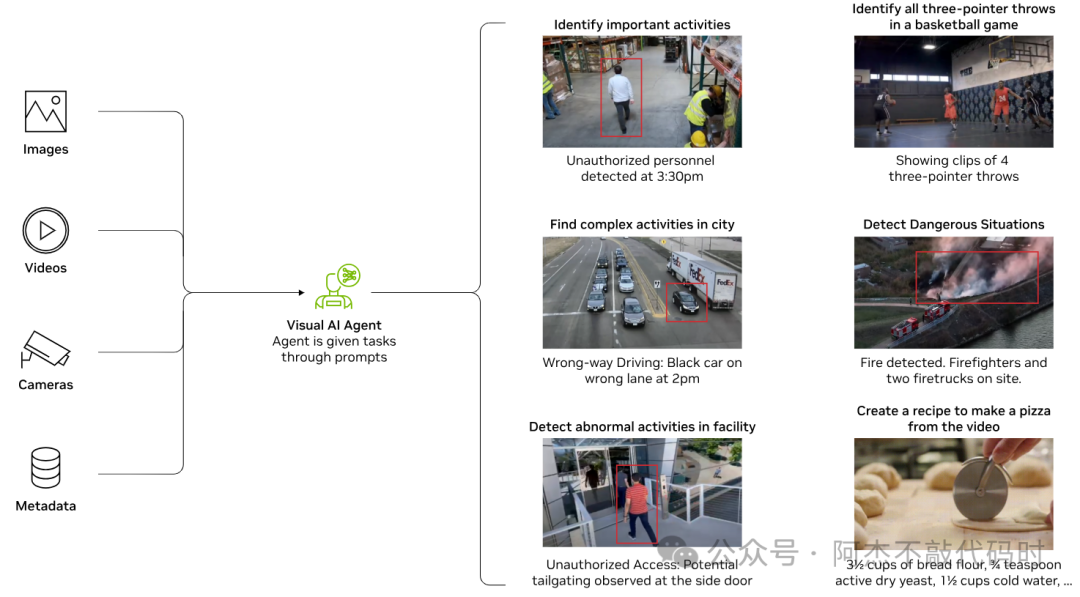
字幕添加和摘要(Captioning and summarization)
VLM 可以生成详细的图像字幕或描述。它们还可以汇总文档中的视频和视觉信息,例如医疗装置中的医学图像或制造设施中的设备维修图表。
图像生成(Image generation)
DAL-E、Imagen、Midjourney 和 Stable Diffusion 等文本到图像生成器可以帮助创作与书面内容相匹配的美术作品或图像。企业还可以在设计和原型制作阶段使用这些工具,帮助可视化产品创意。
图像搜索和检索(Image search and retrieval)
VLM 可以搜索大型图片库或视频数据库,并根据自然语言查询检索相关照片或视频。这可以改善电子商务网站上购物者的用户体验,例如,帮助他们查找特定商品或在庞大的目录中浏览。
图像分割(Image segmentation)
VLM 可以根据其从图像中学习到并提取的空间特征将图像划分为多个片段。然后,VLM 可以提供这些分段的文本描述。
它还可以生成边界框来定位对象,或提供其他形式的注释,如标签或彩色高亮,以指定与查询相关的图像部分。
这对于预测性维护非常有价值,例如,帮助分析工厂车间的图像或视频以实时检测潜在的设备缺陷。
物体检测(Object detection)
VLM 可以识别和分类图像中的对象,并提供上下文描述,例如对象相对于其他视觉元素的位置。例如,物体检测可用于机器人技术,使机器人更好地了解其环境并理解视觉指令。
视觉问题解答 (VQA)
VLM 可以回答有关图像或视频的问题,展示视觉推理能力。这可以帮助进行图像或视频分析,甚至可以扩展到智能体式 AI 应用程序。例如,在运输领域,AI 智能体的任务可以是分析道路检查视频和识别道路标志损坏、交通信号灯故障和路面坑洼等危险。
基准测试
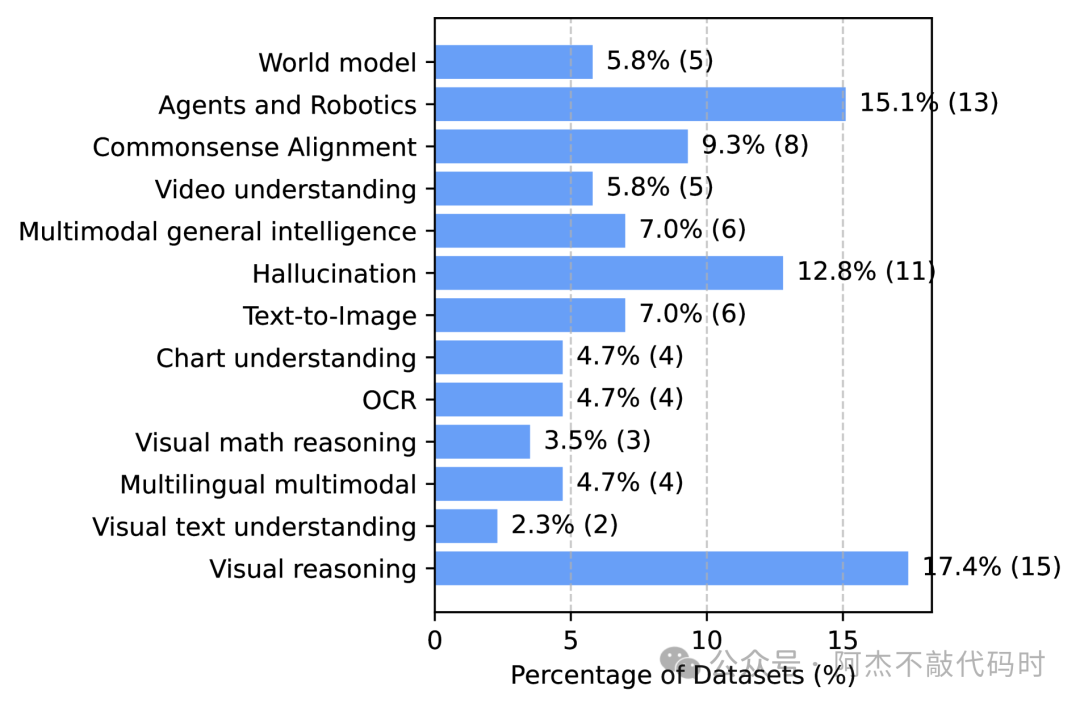
存在几个常见的基准测试,例如 MMMU、MMBench、Video-MME、 MathVista、 ChartQA 和 DocVQA,用于确定视觉语言模型在各种任务上的表现。
大多数基准测试由一组图像和多个相关问题组成,通常以多项选择题的形式提出。多项选择格式是一致地对 VLM 进行基准测试和比较的最简单方法。这些问题测试 VLM 的感知、知识和推理能力。运行这些基准测试时,VLM 会提供图像、问题和它必须从中选择的几个多项选择答案。
VLM 的准确性是一组多项选择题的正确选择数。一些基准测试还包括数字问题,其中 VLM 必须执行特定计算并且在答案的一定百分比内才能被视为正确。这些问题和图像通常来自学术来源,例如大学水平的教科书。
MMMU
针对专家型 AGI 的海量、多学科、多模态理解与推理基准 (A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI,MMMU) 是评估视觉语言模型的最全面的基准。它包含 11.5K 个多模态问题,这些问题需要大学水平的学科知识以及跨学科 (如艺术和工程) 推理能力。
MMBench
由涵盖超过 20 种不同技能的 3000 道单选题组成,包括 OCR、目标定位等。论文还介绍了一种名为 CircularEval 的评估策略,其每轮都会对问题的选项进行不同的组合及洗牌,并期望模型每轮都能给出正确答案。
另外,针对不同的应用领域还有其他更有针对性的基准,如 MathVista (视觉数学推理) 、AI2D (图表理解) 、ScienceQA (科学问答) 以及 OCRBench (文档理解)
这两个评测基准比较通用,也是所有vlm必须要去做得基准测试。当然,很多人可能需要的不是一个基准测试库,而是一个可以对大模型进行评测的工具,这里介绍一下Open compass开源的一个vlm评测工具VLMEvalKit。
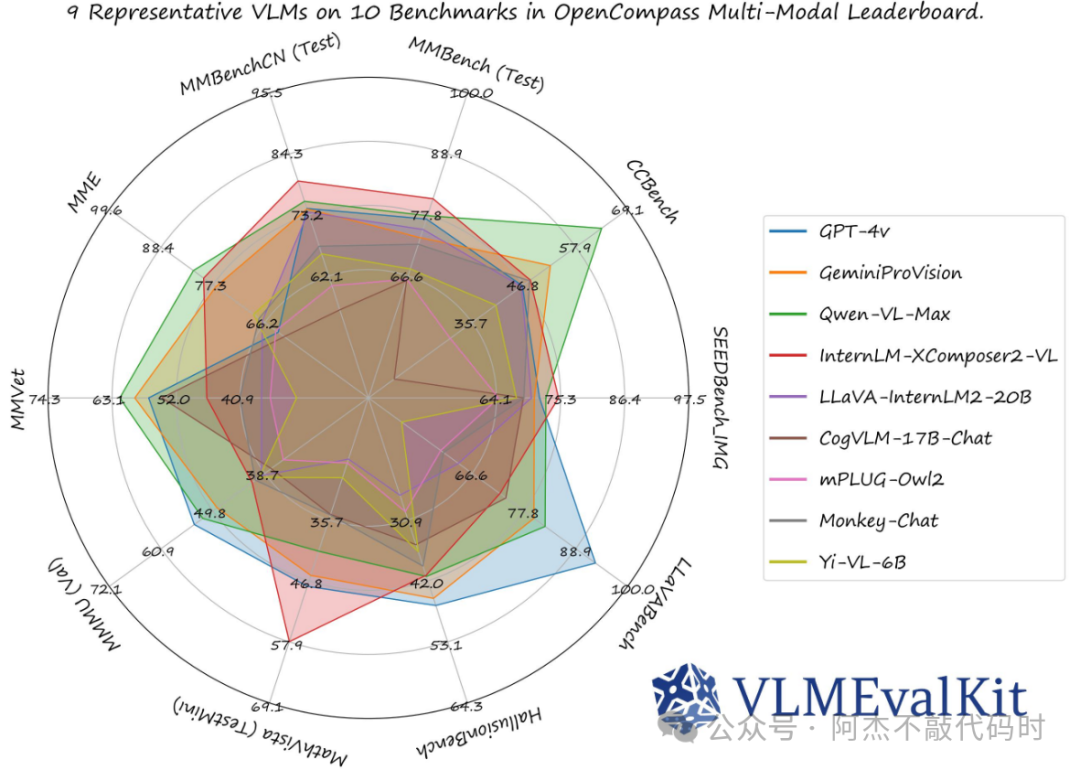
VLMEvalKit
VLMEvalKit(python 包名 vlmeval)是一个开源的视觉语言模型(LVLM) 评估工具包 。它可以在各种基准测试上对 LVLM 进行一键评估 ,而无需在多个存储库下进行繁重的数据准备工作。在 VLMEvalKit 中,我们对所有 LVLM 采用基于生成的评估 ,并提供精确匹配和基于 LLM 的答案提取获得的评估结果。
VLM微调案例
这里以llava模型为例,如果想微调其他得模型,替换模型即可。
首先,解析参数,这里包含两个参数:sft参数和训练参数。
from trl.commands.cli_utils import SftScriptArguments, TrlParser
parser = TrlParser((SftScriptArguments, TrainingArguments))
args, training_args = parser.parse_args_and_config()
其次,设置prompt聊天模板
LLAVA_CHAT_TEMPLATE = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. {% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<image>{% endif %}{% endfor %}{% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"""
初始化模型和分词器,这里以llava-1.5-7b模型为例。
from transformers import AutoTokenizer, AutoProcessor, TrainingArguments, LlavaForConditionalGeneration
import torch
model_id = "llava-hf/llava-1.5-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.chat_template = LLAVA_CHAT_TEMPLATE
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer = tokenizer
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)
然后,加载数据集并对数据集进行处理
class LLavaDataCollator:
def __init__(self, processor):
self.processor = processor
def __call__(self, examples):
texts = []
images = []
for example in examples:
messages = example["messages"]
text = self.processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
texts.append(text)
images.append(example["images"][0])
batch = self.processor(texts, images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
if self.processor.tokenizer.pad_token_id is not None:
labels[labels == self.processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
data_collator = LLavaDataCollator(processor)
from datasets import load_dataset
raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft")
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
最后,初始化 SFTTrainer ,传入模型、数据子集、PEFT 配置以及数据整理器,然后调用 train()进行训练 。
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text", # need a dummy field
tokenizer=tokenizer,
data_collator=data_collator,
dataset_kwargs={"skip_prepare_dataset": True},
)
trainer.train()
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)