大模型 langchain-组件学习(上)
LangChain 是一个用于开发由大型语言模型 (LLM) 驱动的应用程序的。它并非一个单独的软件或服务,而是一个开源 Python(和 JavaScript)库,其核心价值在于简化构建复杂 LLM 应用的过程,让开发者能够将 LLM 与外部数据源和计算工具连接起来,创造出功能强大、可交互的智能应用。而在langchain中,组件是关键功能,在构建大模型时会运用各种功能(比如调用模型、管理提示、
目录
LangChain 是一个用于开发由大型语言模型 (LLM) 驱动的应用程序的框架。它并非一个单独的软件或服务,而是一个开源 Python(和 JavaScript)库,其核心价值在于简化构建复杂 LLM 应用的过程,让开发者能够将 LLM 与外部数据源和计算工具连接起来,创造出功能强大、可交互的智能应用。
而在langchain中,组件是关键功能,在构建大模型时会运用各种功能(比如调用模型、管理提示、处理文档等),把这些功能封装后形成的一个个独立的、可复用的“标准件”就是组件。在langchain中有以下六个重要的组件,下面依次来介绍:
一、Models(模型)
“大脑”和“理解力”。它代表了与各种大语言模型(如GPT-4)和文本嵌入模型交互的能力。这是整个应用智能的来源,且提供了统一的接口(llm)来使用不同类型的模型,简化了模型集成过程。
Models 组件里呢又有两个类,一个是LLM类(大语言模型),它的工作模式就是“输入一段文本,它帮你把文本补全”,适用于单轮的文本生成、翻译、摘要等任务,代码示例如下:
LLM 类:
from langchain_openai import OpenAI # 从llms模块导入OpenAI类,它继承自基类LLM
def test1():
# 基本初始化
llm = OpenAI (
# api的地址来源
base_url="https://api.siliconflow.cn/v1",
api_key="sk-lbspitkzqatuamosanwpnazrsvpqkzbnddoxfynhwjvjdhmr", # 可选,默认从环境变量 OPENAI_API_KEY 读取
model="Tongyi-Zhiwen/QwenLong-L1-32B", # 指定模型
temperature=0.7, # 获得精确回答
max_tokens=1000 # 生成的最大 token 数
)
rs = llm.invoke("中国的首都是")
print(rs)
if __name__ == "__main__":
test1()这里的 temperature 的参数用于控制生成文本的随机性和创造性,下面是一个不听取值效果的对比:
| 取值区间 | 生成文本特点 | 适用场景 |
|---|---|---|
| 0.0 | 完全确定性输出,每次选择概率最高的 token(结果可重复但可能呆板)。 | 需要精确答案的场景(如数学计算、事实问答)。 |
| 0.1~0.5 | 轻度随机性,输出稳定但仍有一定变化。 | 技术文档生成、标准化回复(客服场景)。 |
| 0.5~1.0 | 平衡随机性和合理性(OpenAI 推荐默认范围)。 | 通用对话、创意写作。 |
| >1.0 | 高随机性,可能产生不连贯或荒谬的内容(部分模型限制最大值)。 | 探索性实验、艺术创作 |
顺便说一下,因为在每次调用模型时都会用到 api 和调用网址,所以干脆把这些东西都放在环境变量文件里了,即在项目根目录下创一个 叫.env 的文档,直接在pycharm里建,在文件资源器中建的话是以 txt 结尾的(vscode没试过),比如:
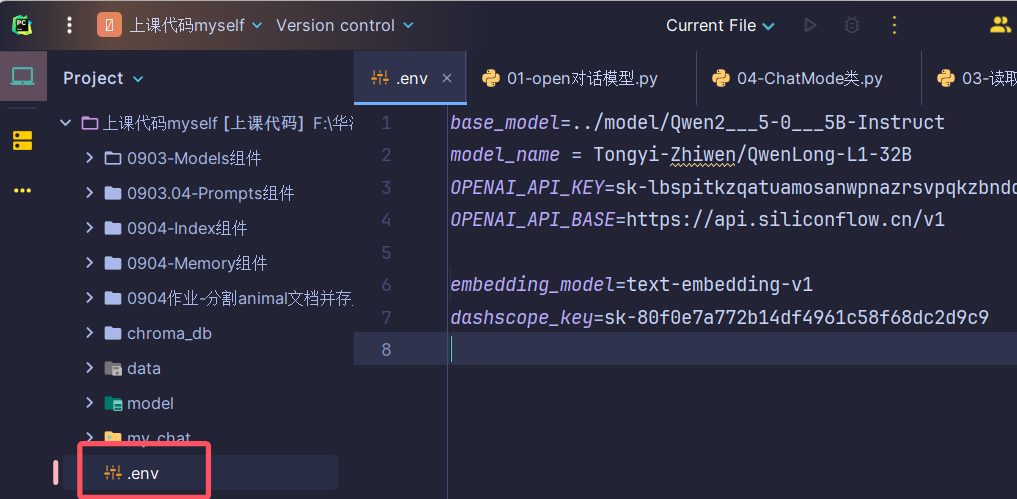
读取这个文件的话就是:
读取env文件:
from dotenv import load_dotenv
import os
from langchain_openai import OpenAI
load_dotenv()
print(os.getenv("my_url")) #测试
llm = OpenAI(model=os.getenv("model_name"))
rs = llm.invoke("你好哇")
print(rs)可以在 .env 文件里加一句 my_url 测试是否正确读入
接下来是第二种类: ChatOpenAI 类(聊天模型),代表的是专为多轮对话优化过的模型,有三种消息角色:SystemMessage、HumanMessage、AIMessage,分别代表系统消息(用于设定AI的身份指令等)、用户消息(代表用户说的话或提的问题)、AI消息(代表AI的回复),代码示例如下:
ChatOpenAI 类:
from langchain_openai import OpenAI, ChatOpenAI
from dotenv import load_dotenv
import os
from langchain.schema import SystemMessage, HumanMessage, AIMessage
load_dotenv()
def test1():
llm = ChatOpenAI(model=os.getenv("model_name"))
rs = llm.invoke([
SystemMessage("你是一个温柔的助手"),
HumanMessage("给我讲个故事")
])
print(rs.content)
#多轮对话
def test2():
llm = ChatOpenAI(model=os.getenv("model_name"))
rs = llm.invoke([
SystemMessage(content="你是一位物理学教授"),
HumanMessage(content="请用简单语言解释相对论"),
AIMessage(content="相对论是关于时空和引力的理论..."),
HumanMessage(content="这与量子力学有什么不同?")
])
print(rs.content)
if __name__ == '__main__':
# test1()
test2()
接下来就可以部署大模型,这里先部署本地模型:
加载本地大模型:
首先要下载以下库,版本就自行选择了(cpu版本的最好去官网下载,AI给出的命令下载后运行可能会报错):
pip install transformers==4.54.1 -i https://mirrors.aliyun.com/pypi/simple/
pip install langchain-huggingface==0.3.1 -i https://mirrors.aliyun.com/pypi/simple/
pip install torch==2.5.1 -i https://mirrors.aliyun.com/pypi/simple/
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain_huggingface import HuggingFacePipeline
import torch
def get_model():
#加载模型
model_path = "../model/Qwen2___5-0___5B-Instruct"
#加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
#加载权重
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32 # 确保使用CPU兼容的数据类型 GPU不用加这一句
)
#创建管道
pipe = pipeline(
"text-generation", # 表示文本生成任务
model=model,
tokenizer=tokenizer,
max_new_tokens=512, # 生成的最大 token 数量(控制输出长度)
temperature=0.7 # 控制随机性(值越高,输出越多样;值越低,输出越确定)
)
#创建HuggingFacePipeline对象 即openai适合的模型
hf_pipe = HuggingFacePipeline(pipeline=pipe)
#返回llm模型
return hf_pipe
if __name__ == '__main__':
rs = get_model()
print(rs.invoke("讲个故事"))
本地模型和在线模型都可以调用之后,因为每用一次大模型就要写一次很麻烦,所以也可以封装成一个类:
封装模型类:
首先在项目根目录下新建一个Python包,注意命名不能有中文因为一会儿要导入,然后再在这个包下面新建一个 py 文件写我们的模型类,比如:
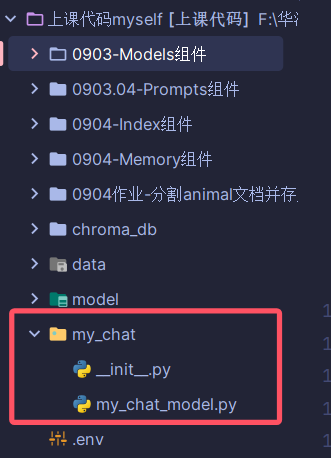
在 my_chat_model 中的代码如下:
from langchain_openai import OpenAI, ChatOpenAI
from dotenv import load_dotenv
import os
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain_huggingface import HuggingFacePipeline
import torch
from langchain_community.embeddings import DashScopeEmbeddings
#创建一个聊天模型类
class ChatModel:
#定义初始化函数
def __init__(self):
# 获取环境变量
load_dotenv()
#获取在线模型
def get_online_model(self):
return ChatOpenAI(model=os.getenv("model_name"), temperature=0.7)
#获取本地模型
def get_local_model(self):
# 加载模型
model_path = os.getenv("base_model")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载权重
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32 # 确保使用CPU兼容的数据类型 GPU不用加这一句
)
# 创建管道
pipe = pipeline(
"text-generation", # 表示文本生成任务
model=model,
tokenizer=tokenizer,
max_new_tokens=512, # 生成的最大 token 数量(控制输出长度)
temperature=0.7 # 控制随机性(值越高,输出越多样;值越低,输出越确定)
)
# 创建HuggingFacePipeline对象 即openai适合的模型
hf_pipe = HuggingFacePipeline(pipeline=pipe)
# 返回llm模型
return hf_pipe
接下来我们测试一下:
测试封装的模型类:
from my_chat.my_chat_model import ChatModel
if __name__ == '__main__':
chat = ChatModel()
# 在线模型返回的是对象
llm = chat.get_online_model()
rs = llm.invoke("你好哇")
print(rs.content)
print("------------------------------------")
#本地模型返回的是字符串 要蠢一点
llm1 = chat.get_local_model()
res = llm1.invoke("你好哇")
print(res)如果能成功运行就说明封装成功了୧(๑•̀◡•́๑)૭
二、Prompt (提示)
Prompt(提示) 是我们与大语言模型(LLM)沟通的指令、问题和上下文信息的总和。它的质量直接决定了模型输出结果的质量,而他的作用:LangChain 的 Prompt 模块提供了工具来科学地管理和构造这些提示,而不是在代码中手动拼接杂乱的字符串。它让提示变得可复用、可动态化、可管理。
这个组件提供了以下两种模版:PromptTemplate 类和 ChatPromptTemplate 类,下面用代码示例:
PromptTemplate 类基本用法:
from langchain.prompts import PromptTemplate
from my_chat.my_chat_model import ChatModel
def test1():
#定义一个提示模版
temple = "你是一个{type}"
#设置模版的输入变量
prompt = PromptTemplate(
input_variables=["type"], #输入变量
template=temple, #设置模版
)
#格式化模版
res = prompt.format_prompt(type="翻译")
print(res.to_string()) #你是一个翻译
#代入模型应用
def test2():
# temple = "你是一个{type}, 请用韩语翻译一下你好"
temple = "你是一个影视测评博主,请给我推荐一下{type}"
# 设置模版的输入变量
prompt = PromptTemplate(
input_variables=["type"], # 输入变量
template=temple, # 设置模版
)
# 格式化模版
# res = prompt.format_prompt(type="翻译")
#创建模型
chat=ChatModel()
model = chat.get_online_model()
#构建一个链式组件
chain = prompt | model
#提问
rs = chain.invoke({"type": "韩剧"})
print(rs.content)
#聊天模型应用
def test3():
temple = '''
你是一个有趣的聊天机器人,要回答用户的问题
{question}
'''
# 设置模版的输入变量
prompt = PromptTemplate(
input_variables=["question"], # 输入变量
template=temple, # 设置模版
)
# 格式化模版
# res = prompt.format_prompt(type="翻译")
# 创建模型
chat = ChatModel()
model = chat.get_online_model()
# 构建一个链式组件
chain = prompt | model
# 提问
rs = chain.invoke({"question": "黑暗荣耀好不好看"})
print(rs.content)
if __name__ == '__main__':
# test1()
# test2()
test3()
PromptTemplate 是用于格式化一个单一的、连续的文本提示的模板。它主要与上面提到的 LLM(补全模型)配合使用,那这段代码首先是定义了一个提示模版,展示了一下最基础的应用,然后是代入模型应用,当然在test2 里提前用到了链式组件这个后面会讲,当然在test2 里还是只有单轮对话,所以在test3 中就应用到了聊天模型,用户的输入就成了一个变量可以随意更改
ChatPromptTemplate 类基本用法:
from langchain.prompts import ChatPromptTemplate
from my_chat.my_chat_model import ChatModel
#基础用法
def test1():
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{type}"), #定义系统角色
("human", "请推荐好看的{text}") #定义客户角色
])
#调用在线模型
chat = ChatModel()
model = chat.get_online_model()
info = prompt.format_prompt(type="影视剧测评博主", text="韩剧")
print(type(info)) #打印类型: <class 'langchain_core.prompt_values.ChatPromptValue'>
res = model.invoke(info)
print(res)
#多轮对话
def test2():
prompt = ChatPromptTemplate.from_messages([
#对话放模版里面写
("system", "你是一个物理教授"), # 定义系统角色
("human", "请解释一下相对论是什么"), # 定义客户角色
("ai", "相对论是什么。。。"), #模拟回复
("human", "这和量子力学有什么不同")
])
# 调用在线模型
chat = ChatModel()
model = chat.get_online_model()
info = prompt.format_prompt()
print(type(info)) # 打印类型
res = model.invoke(info)
print(res)
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
# from langchain.prompts import HumanMessagePromptTemplate
#chatprompt第二种写法
def test3():
prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="你是一个物理教授"),
HumanMessage(content="请解释一下相对论是什么"),
# HumanMessagePromptTemplate.from_template("{text}"), #自定义变量
AIMessage(content="相对论是什么。。。"),
HumanMessage(content="这和量子力学有什么不同")
])
chat = ChatModel()
model = chat.get_online_model()
info = prompt.format_prompt()
# info = prompt.format_prompt(text="请解释一下相对论是什么")
print(type(info)) # 打印类型
res = model.invoke(info)
print(res)
if __name__ == '__main__':
# test1()
# test2()
test3()
ChatPromptTemplate 类是用于格式化一个消息列表的模板。它专门与 ChatModel(聊天模型,如ChatOpenAI)配合使用,是当前最主流和强大的方式。
那这段代码首先也是在 test1 里展示了基础用法,先定义模版,再调用模型,把对话传给模型后拿到返回值;然后在 test2 里就是用的多轮对话方法,用的字符串形式,主要是写了一段对话历史,相当于模拟了多轮聊天,test3 里是同样的方法,只不过显试地用了 SystemMessage、HumanMessage、AIMessage 类,更直观,类型更安全
两者的核心区别在于输出格式和配合的类型,前者的输出格式是一个单一的、长的字符串,后者是一个由多条消息(ChatMessage)组成的列表,以及前者的配合模型通常是LLM模型,而后者可以接入各种聊天模型,比较起来的话,ChatPromptTemplate 类更强大,因为它利用了聊天模型的设计优势,SystemMessage 是一个非常强大的工具,可以用它来设定角色和身份、定义回答的规则和限制以及提供思维链,这种结构化的、分角色的提示方式,比把所有指令都塞进一个杂乱的长字符串里(PromptTemplate 的方式)要有效和可靠得多。
其实这篇是我好久之前写的了,因为拖太久所以不得不分上下。。以上有问题可以指出 (๑´ㅂ`๑)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 31
31 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)