系列教程九 | LLaMA Factory框架微调GLM-4大模型
本项目旨在借助LLaMA Factory 框架,在 BitaHub 平台上,运用 LoRA 微调方法对 GLM-4-9B-Chat 模型进行针对性训练。该项目的目标是让模型在广告文案生成任务中,能够深度理解不同的产品特点和风格需求,生成极具吸引力且风格独特的广告文案,实现精准的风格迁移,进而提升在广告营销、内容创作等领域的应用价值。在模型训练完成后,将基础模型(GLM-4-9B-Chat )与经过
一.项目介绍
在广告文案生成和风格迁移等场景中,模型的生成能力和对特定风格的把控能力至关重要。当前市面上的许多模型在处理复杂多样的风格需求时,生成的内容难以精准匹配要求,导致生成效果不佳。本项目旨在借助LLaMA Factory 框架,在 BitaHub 平台上,运用 LoRA 微调方法对 GLM-4-9B-Chat 模型进行针对性训练。该项目的目标是让模型在广告文案生成任务中,能够深度理解不同的产品特点和风格需求,生成极具吸引力且风格独特的广告文案,实现精准的风格迁移,进而提升在广告营销、内容创作等领域的应用价值。
二.创建Bitahub项目
1.进入BitaHub官网,完成注册后点击右上角进入工作台。

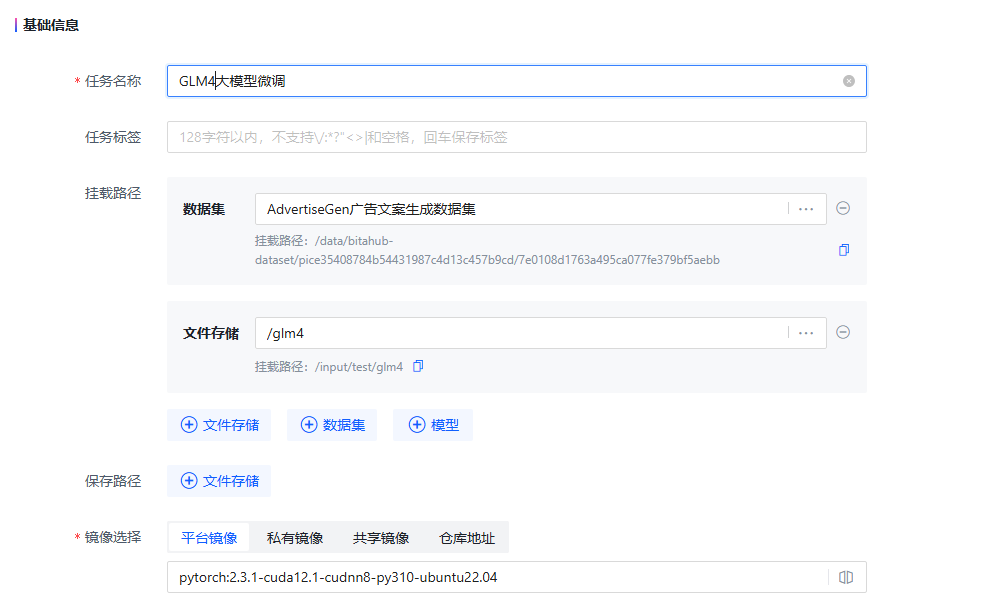
2.在「模型开发和训练」中,创建新的开发环境。
-
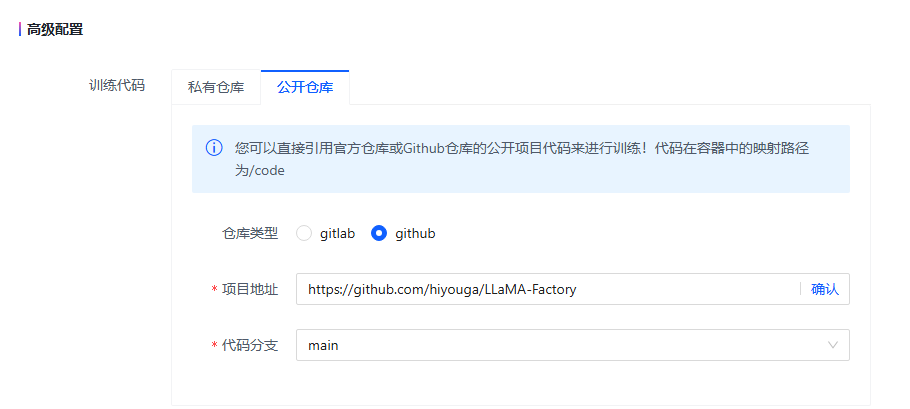
在平台中选择 AdvertiseGen 广告文案生成数据集,设置从 github 拉取 llamafactory 代码(项目地址:https://github.com/hiyouga/LLaMA-Factory,代码分支:main)。
-
选择pytorch:2.3.1-cuda12.1-cudnn8-py310-ubuntu22.04 系统镜像。
三.项目步骤详解
1.环境准备
将当前路径切换到项目根目录,安装包含 torch 和 metrics 的依赖包,为项目运行搭建环境。
cd /code/LLaMA-Factorypip install -e '.[torch,metrics]'
在data/dataset_info.json文件中添加数据集信息,是为了让模型训练程序能够准确识别、读取和处理用于训练的数据。
{"alpaca_zh_demo": {"file_name": "alpaca_zh_demo.json"},"AdvertiseGen": {"file_name": "AdvertiseGen/train.json","columns": {"prompt": "content","response": "summary"}}}
2.模型训练
执行训练命令:
--model:指定要微调的预训练模型。
--data_path:指定微调数据集的路径。
--output_dir:指定输出目录,用于保存微调后的模型和日志。
--lora_rank:指定 LoRA 的低秩矩阵的秩。
--batch_size:指定批量大小。
--learning_rate:指定学习率。
--num_epochs:指定训练的轮数。
--save_steps:每多少步保存一次模型。
--logging_steps:每多少步记录一次日志。
--fp16:使用混合精度训练,以减少显存占用和加快训练速度。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \--stage sft \--do_train \--model_name_or_path /input/test/glm4 \--dataset AdvertiseGen \--dataset_dir ./data \--template glm4 \--finetuning_type lora \--output_dir ./saves/glm4/lora/sft \--overwrite_cache \--overwrite_output_dir \--cutoff_len 1024 \--preprocessing_num_workers 16 \--per_device_train_batch_size 2 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 8 \--lr_scheduler_type cosine \--logging_steps 50 \--warmup_steps 20 \--save_steps 100 \--eval_steps 50 \--evaluation_strategy steps \--load_best_model_at_end \--learning_rate 5e-5 \--max_samples 2000 \--num_train_epochs 3.0 \--val_size 0.1 \--plot_loss \--fp16
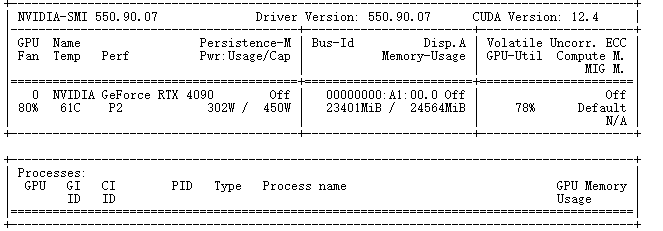
查看模型训练对显存的占用。
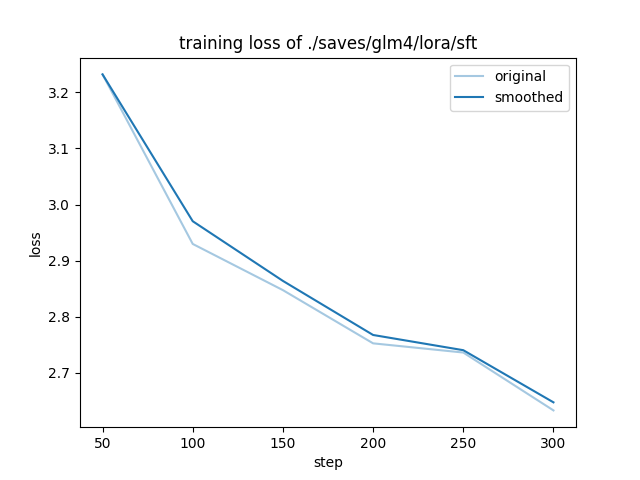
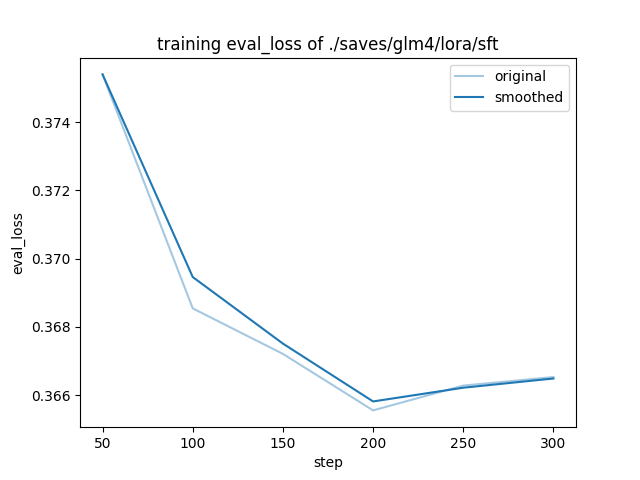
使用单卡大概 1h 完成了训练,查看模型微调训练损失情况。短时间训练能使损失下降,但后期模型泛化能力有变差趋势,需进一步调整训练策略进行优化。
3.模型合并
在模型训练完成后,将基础模型(GLM-4-9B-Chat )与经过微调的模型部分进行整合,并按照指定要求导出合并后的模型,方便后续使用和部署。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \--model_name_or_path /input/test/glm4 \--adapter_name_or_path ./saves/glm4/lora/sft \--template glm4 \--finetuning_type lora \--export_dir megred-model-path \--export_size 2 \--export_device cpu \--export_legacy_format False
4.模型预测
在完成模型训练和合并后,我们可以使用以下命令开启与模型的交互,并用 dev 数据集来测试模型效果:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \--model_name_or_path /input/test/glm4 \--adapter_name_or_path /root/code/LLaMA-Factory/saves/glm4/lora/sft \--template glm4 \--finetuning_type lora
在交互状态下,输入 dev 数据集中的一条样本,例如:
User: 类型#裙*材质#针织*颜色#纯色*风格#复古*风格#文艺*风格#简约*图案#格子*图案#纯色*图案#复古*裙型#背带裙*裙长#连衣裙*裙领型#半高领Assistant: 这款针织连衣裙以纯色设计,简约大方。衣身采用背带设计,充满了学院风。半高领的设计,显得复古文艺。格纹背带裙,优雅别致。
从上述输入和输出结果可以看出,模型实现了一定的风格迁移。输入是一系列裙子的属性描述,而输出是一段独特风格的文案,将裙子的属性信息转化为了富有特色的文字描述。
四.总结
本文档介绍了基于 LLaMA Factory 框架对 GLM - 4 大模型进行微调、合并及测试的完整流程。采用 LoRA 微调方法,在 BitaHub 平台借助特定数据集开展模型训练工作,仅用单卡约 1 小时完成训练。训练完成后,通过执行合并命令将基础模型与微调后的部分进行整合。最后,使用 dev 数据对模型进行测试,结果表明模型成功实现了风格迁移,能够将输入的商品属性描述转化为富有特色的文案输出。后续可进一步考虑使用 vllm 等框架进行模型部署,以投入实际应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)