【必学收藏】[特殊字符] LangChain框架全解析:Why What How + 5分钟实战带RAG的ChatBot,小白也能轻松上手!
本文从Why、What、How三方面解析LangChain框架,详细介绍了为何需要LangChain解决大模型应用开发中的prompt管理、多模型集成、工具对接等问题,拆解了其核心架构与模块,并通过实战项目展示了如何基于LangChain+Ollama+Qwen2.5构建带RAG能力的智能聊天机器人,实现文档解析、向量化、查询检索等功能,为开发者提供大模型应用开发的完整解决方案。
本文从Why、What、How三方面解析LangChain框架,详细介绍了为何需要LangChain解决大模型应用开发中的prompt管理、多模型集成、工具对接等问题,拆解了其核心架构与模块,并通过实战项目展示了如何基于LangChain+Ollama+Qwen2.5构建带RAG能力的智能聊天机器人,实现文档解析、向量化、查询检索等功能,为开发者提供大模型应用开发的完整解决方案。
一、Why:为啥会有LangChain
假如从OpenAI 的API开始构建大模型应用的话,那么就得需要考虑这些问题。
- Prompt 管理:不同的场景需要手写不同的提示词(Prompt**),**还要维护多个 prompt 的版本和结构,很容易混乱。
- 调用逻辑的组织: 如果你想让模型先问用户问题,然后再去查资料,再回答——你得自己写一整套逻辑流程。
- 多模型集成: 假如你不想用OpenAI的大模型,想尝试下HuggingFace上的其他大模型,就得需要自己封装和管理它们的接口。
- 与外部工具对接: 想要模型查数据库、搜索引擎、文件系统?你要自己写代码去连接、格式化、处理这些数据。
- 内存管理(聊天上下文): 比如:让 AI 记住用户之前说过什么,你要自己存储这些对话记录,并加到 prompt 里。
- 调试 & 追踪: 如果模型表现不对,你很难知道是哪一步出了问题。没有自动化的 trace 系统。
现在,有了LangChain,你可以不用特别关注那些底层的工作,专注在你的业务即可。比如你想基于LLM开发一个问答系统,几行代码就可以完成最内核的功能:
from langchain_community.chat_models import ChatOllama
from langchain_core.messages import HumanMessage
# 初始化模型
model = ChatOllama(
model="qwen2.5:1.5b",
base_url="http://localhost:11434"# Ollama 服务地址
)
# 发送请求
response = model.invoke([
HumanMessage(content="用中文写一首关于秋天的短诗")
])
print(response.content)
对,就是这么简洁。
二、What:LangChain框架拆解
官网的定义是,LangChain是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。想要理解LangChain的封装逻辑,就得先理解LLM的技术堆栈思路。
2.1 LLM技术栈设计思路
当你想开发一款大模型应用的时候,直接使用其已经封装好的组件就可以。甚至针对常规的应用流程,它利用链(LangChain中Chain的由来)这个概念已经内置标准化方案了。
这里我们从新兴的大语言模型(LLM)技术栈的角度来看看为何它的理念这么受欢迎。
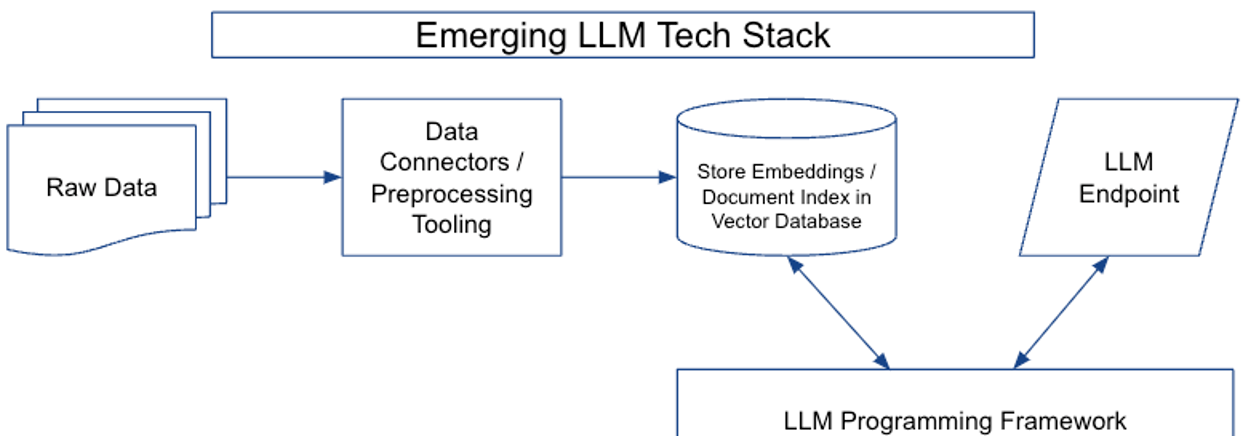
LLM技术栈主要由四个主要部分组成:
数据预处理(data preprocessing pipeline):主要包括了数据源连接、数据转化、下游连接器(如向量数据库),特别是对于繁杂的数据源,如数千个PDF、PPTX、聊天记录、抓取的HTML等,这里需要大量的数据提取、清理、转换工作,这点上跟大数据分析任务的前期步骤很类似,不同的是大模型的数据处理可能会用到OCR模型、Python脚本和正则表达式等方式,并以API方式向外部提供JSON数据,以便嵌入终端和存储在向量数据库中。
嵌入与向量存储(embeddings +vector store ):以往嵌入主要用于如文档聚类之类的特定任务,新的架构中,直接将文档及其嵌入存储在向量数据库中,可以通过LLM端点实现关键的交互模式。直接存储原始嵌入,意味着数据可以以其自然格式存储,从而实现更快的处理时间和更高效的数据检索。
LLM 终端(LLM endpoints):LLM终端负责管理模型的资源,包括内存和计算资源,并提供可扩展和容错的接口,用于向下游应用程序提供LLM输出。
LLM 编程框架(LLM programming framework):LLM编程框架提供了一套工具和抽象,用于使用语言模型构建应用程序。在现代技术栈中出现了各种类型的组件,包括:LLM提供商、嵌入模型、向量存储、文档加载器、其他外部工具(谷歌搜索等),这些框架的一个重要功能是协调各种组件。
2.2 LangChain框架核心模块
langchain-core:聊天模型和其他组件的基础抽象。
Integration packages:负责维护不同厂家的大模型,由轻量级的包组成,例如 langchain-openai、langchain-anthropic 等。
langchain:构成应用程序认知架构的链、代理和检索策略。
langchain-community:由社区维护的第三方集成工具。
langgraph:编排框架,用于将 LangChain 组件组合成具有持久化、流式处理和其他关键功能的生产就绪型应用程序。
完整的框架如:
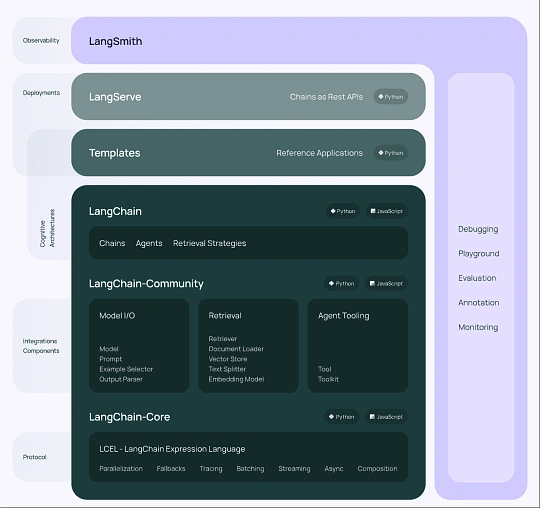
这里补充框架中的两个组成:
- LangGraph:是一个基于 LangChain 的扩展库,用于构建有状态、多角色的智能体(Agents)应用。它通过将任务流程建模为状态图(StateGraph),实现对复杂任务的精细控制和管理。
- LangSmith:通俗一点来说,LangSmith 是一个用于开发、调试、测试和监控基于大语言模型(LLM)应用的平台,它有点像你写 LLM 应用时的 “全能开发调试仪表盘”。
三、How:基于LangChain开发带RAG能力的ChatBot项目
3.1 项目效果
先直接看下项目效果。
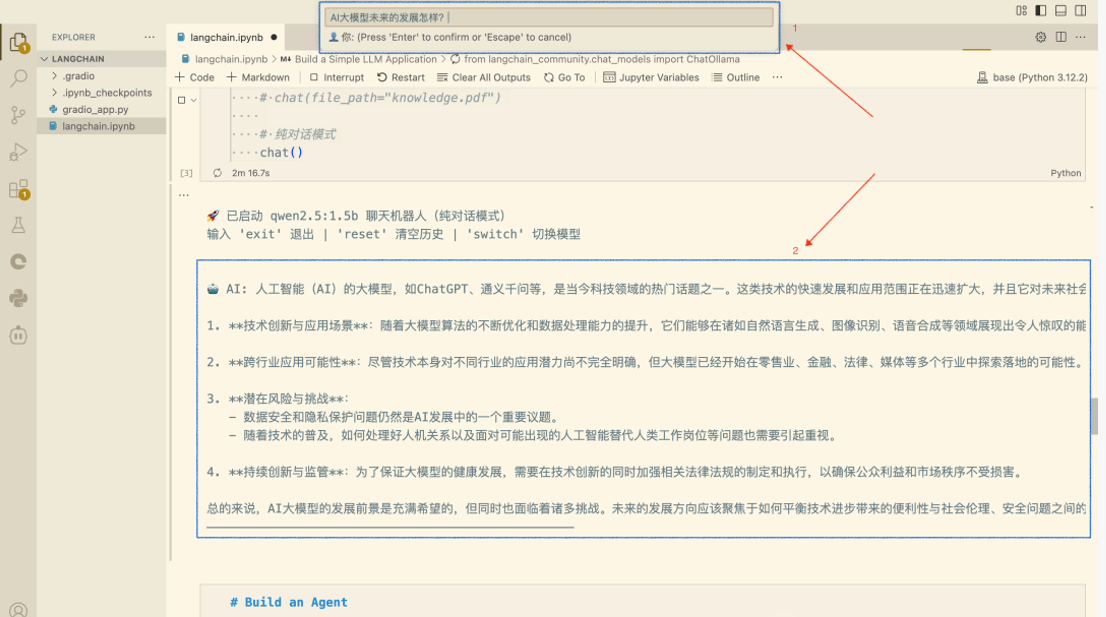
注:用户在位置1进行输入,在位置2 Jupyter的Cell底部,可以看到大模型回复的结果。
3.2 关键步骤解析
项目技术开发环境:LangChain+Ollama+Qwen2.5+Jupyter
1. 基础构建
可以看到这里主要引用了LangChain框架中的langchain_core、langchain_community,并进行了模型初始化和文件的加载处理。
import os
from typing import List, Optional
from langchain_community.chat_models import ChatOllama
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.document_loaders import PyPDFLoader, TextLoader
# 配置常量
DEFAULT_MODEL = "qwen2.5:1.5b"
OLLAMA_BASE_URL = "http://localhost:11434"
# 初始化模型
def init_model(model_name: str = DEFAULT_MODEL) -> ChatOllama:
return ChatOllama(
model=model_name,
base_url=OLLAMA_BASE_URL,
temperature=0.7,
num_ctx=4096,
stream=True,
stop=["<|im_end|>"] # 防止模型无限生成
)
# 加载文档(支持PDF/TXT)
def load_documents(file_path: str) -> Optional[List]:
ifnot os.path.exists(file_path):
print(f"⚠️ 文件不存在: {file_path}")
returnNone
try:
if file_path.endswith(".pdf"):
loader = PyPDFLoader(file_path)
elif file_path.endswith(".txt"):
loader = TextLoader(file_path)
else:
print("❌ 不支持的文件格式(仅支持PDF/TXT)")
returnNone
return loader.load()
except Exception as e:
print(f"❌ 文档加载失败: {str(e)}")
returnNone
2. 构建智能链
这一步是整个应用的核心。在这一步中完成应用的,文件解析、向量化、查询检索。并结合用户输入完成对LLM的交互。
def build_chain(model: ChatOllama, documents: Optional[List] = None):
# ===== 提示模板设计 =====
base_prompt = ChatPromptTemplate.from_messages([
("system", "你是{persona},请用{language}回答。对话历史:{history}"),
("human", "{input}")
])
doc_prompt = ChatPromptTemplate.from_messages([
("system", """
根据以下上下文和对话历史回答问题:
---上下文---
{context}
---历史记录---
{history}
请用{language}以{persona}的身份回答:
"""),
("human", "{input}")
])
# ===== 链式逻辑 =====
if documents:
# 文档处理流程
embeddings = OllamaEmbeddings(model="nomic-embed-text")
splits = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
).split_documents(documents)
vectorstore = FAISS.from_documents(splits, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
chain = (
RunnablePassthrough.assign(
context=lambda x: "\n".join(
f"[来源{i+1}]: {doc.page_content}"
for i, doc in enumerate(retriever.get_relevant_documents(x["input"]))
),
persona=lambda _: "专业AI助手",
language=lambda _: "中文",
history=lambda x: "\n".join(
f"{msg.type}: {msg.content}"
for msg in x.get("history", [])
)
)
| doc_prompt
| model
| StrOutputParser()
)
else:
# 基础对话流程
chain = (
RunnablePassthrough.assign(
persona=lambda _: "友好AI伙伴",
language=lambda _: "中文",
history=lambda x: "\n".join(
f"{msg.type}: {msg.content}"
for msg in x.get("history", [])
)
)
| base_prompt
| model
| StrOutputParser()
)
return chain
3.构建交互式聊天框架
这一步主要构建起用于与大模型聊天的用户界面。可以看到从用户输入到LLM相应,以及保留最近10轮的对话上下文信息。
def chat(model_name: str = DEFAULT_MODEL, file_path: Optional[str] = None):
# 初始化
model = init_model(model_name)
documents = load_documents(file_path) if file_path elseNone
chain = build_chain(model, documents)
history = []
print(f"\n🚀 已启动 {model_name} 聊天机器人({'文档模式' if documents else '纯对话模式'})")
print("输入 'exit' 退出 | 'reset' 清空历史 | 'switch' 切换模型\n")
whileTrue:
try:
# 用户输入
user_input = input("👤 你: ")
if user_input.lower() == 'exit':
break
elif user_input.lower() == 'reset':
history = []
print("🔄 历史已清空")
continue
elif user_input.lower() == 'switch':
new_model = input(f"当前模型: {model_name} → 输入新模型名(如 deepseek-r1:7b): ")
model_name = new_model.strip()
model = init_model(model_name)
chain = build_chain(model, documents)
print(f"🔄 已切换至模型: {model_name}")
continue
# 流式输出
print("\n🤖 AI: ", end="", flush=True)
full_response = ""
for chunk in chain.stream({"input": user_input, "history": history}):
print(chunk, end="", flush=True)
full_response += chunk
# 更新历史(限制最大长度)
history.extend([
HumanMessage(content=user_input),
AIMessage(content=full_response)
])
history = history[-10:] # 保留最近10轮对话
print("\n" + "─" * 50 + "\n")
except KeyboardInterrupt:
print("\n⏹️ 对话已终止")
break
except Exception as e:
print(f"\n❌ 错误: {str(e)}")
4.运行应用程序
这个应用不仅支持纯LLM对话的,还支持RAG的方式进行对话。
if __name__ == "__main__":
# 示例:带PDF文档的聊天
# chat(file_path="knowledge.pdf")
# 纯对话模式
chat()
参考:LangChain官网
普通人如何抓住AI大模型的风口?
为什么要学习大模型?
在DeepSeek大模型热潮带动下,“人工智能+”赋能各产业升级提速。随着人工智能技术加速渗透产业,AI人才争夺战正进入白热化阶段。如今近**60%的高科技企业已将AI人才纳入核心招聘目标,**其创新驱动发展的特性决定了对AI人才的刚性需求,远超金融(40.1%)和专业服务业(26.7%)。餐饮/酒店/旅游业核心岗位以人工服务为主,多数企业更倾向于维持现有服务模式,对AI人才吸纳能力相对有限。
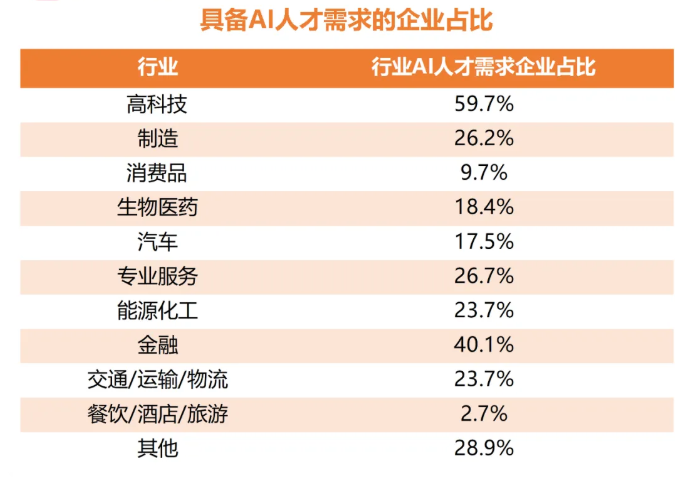
这些数字背后,是产业对AI能力的迫切渴求:互联网企业用大模型优化推荐算法,制造业靠AI提升生产效率,医疗行业借助大模型辅助诊断……而餐饮、酒店等以人工服务为核心的领域,因业务特性更依赖线下体验,对AI人才的吸纳能力相对有限。显然,AI技能已成为职场“加分项”乃至“必需品”,越早掌握,越能占据职业竞争的主动权
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
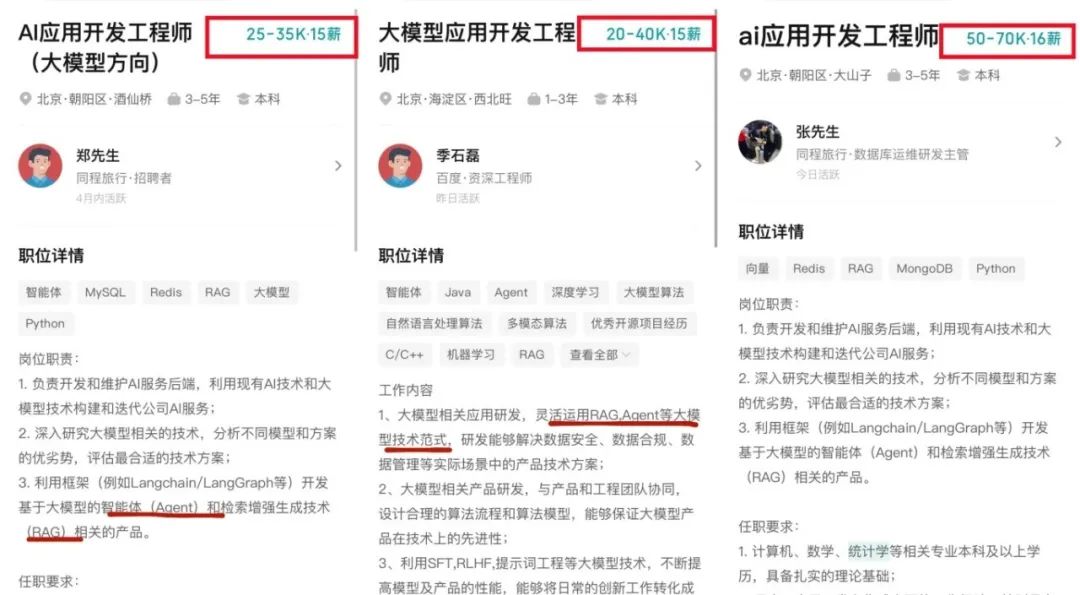
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可

部分资料展示
一、 AI大模型学习路线图
这份路线图以“阶段性目标+重点突破方向”为核心,从基础认知(AI大模型核心概念)到技能进阶(模型应用开发),再到实战落地(行业解决方案),每一步都标注了学习周期和核心资源,帮你清晰规划成长路径。

二、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

三、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

四、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)