一句话生成全栈应用?AI 操控浏览器?这几个项目太硬核了
2025年AI Agent技术迎来大爆发,本文为您深度挖掘3个近期GitHub热榜上的颠覆性开源项目:**Bolt.diy**,作为Bolt.new的开源平替,支持本地模型,能一句话生成全栈应用;**Browser Use**,基于视觉大模型,让AI拥有“手”和“眼”,自动操控浏览器完成订票、填表等复杂任务;**Crawl4AI**,专为LLM设计的极速爬虫,能将杂乱网页一键提取为干净的Markd
01.Bolt.diy
一句话生成全栈应用(开源版 Bolt.new)
你可能听说过 V0.dev 或 Bolt.new,那种“输入一句话,直接生成完整网页应用”的体验确实震撼。但高昂的订阅费和闭源限制让人望而却步。
Bolt.diy 就是为了打破这个局面而生的。它是 Bolt.new 的开源平替,让你在本地也能体验“提示词编程”的快乐。
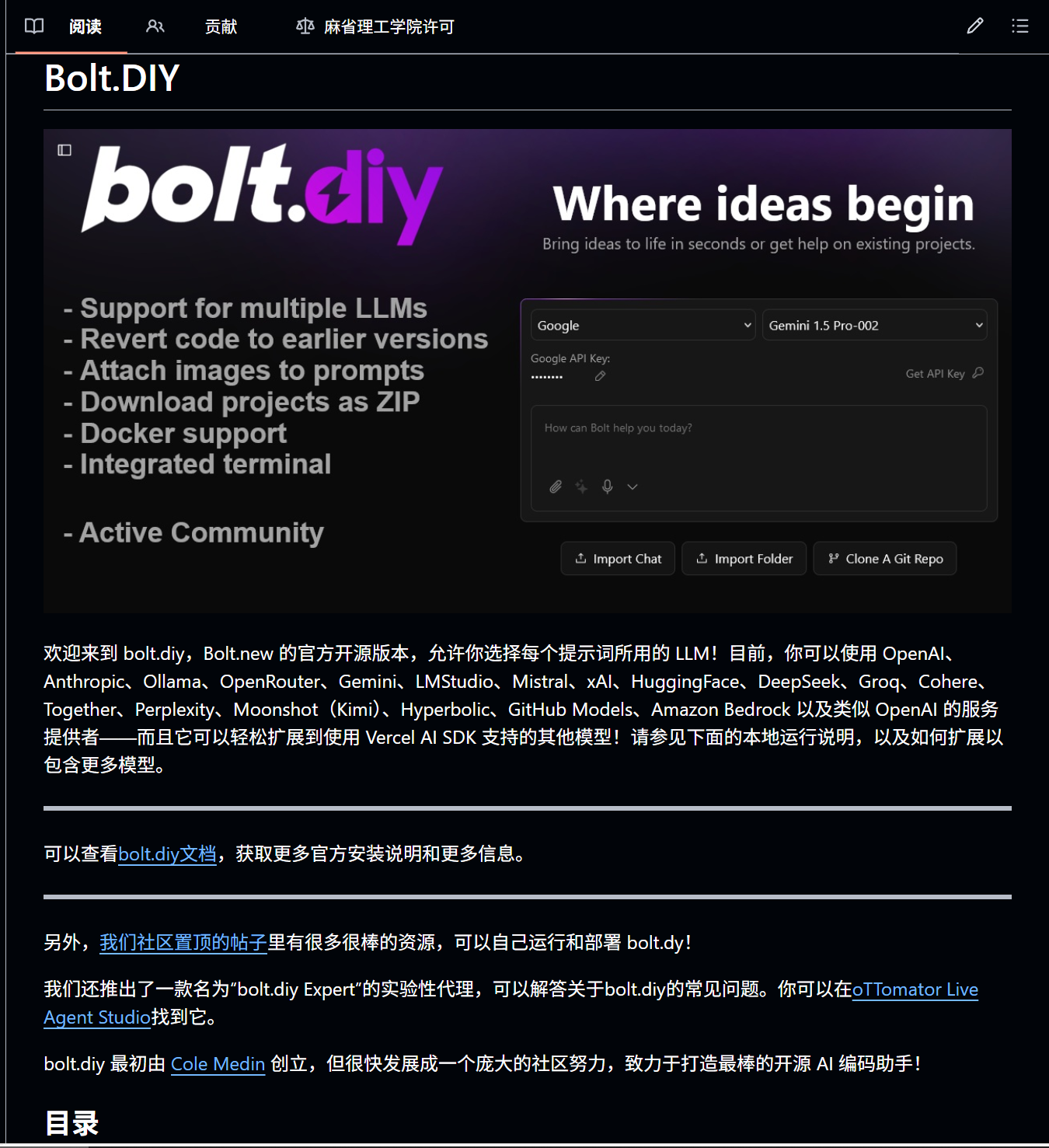
它不仅仅是生成代码,它在浏览器里跑了一个完整的 WebContainer。这意味着你可以直接在网页上安装 npm 包、运行 Node.js 服务器,实时预览修改结果。
主要功能:
① 全模型支持: 不想花钱?支持通过 Ollama 调用本地 DeepSeek、Llama 3;想更强?支持接入 OpenAI、Anthropic 等 API;
② 所见即所得: 左边提要求,右边立马出页面,支持 React、Vue、Svelte 等主流框架;
③ 完全控制: 生成的代码可以直接下载,项目完全掌握在自己手里;
④ Docker 部署: 提供 Docker 镜像,一键部署在自己的服务器上,打造私有的开发助手。
不管是做原型验证,还是快速搭建后台面板,它都是绝对的效率神器。
开源地址: https://github.com/stackblitz-labs/bolt.diy
02.Browser Use
让 AI 替你操控浏览器
现在的大模型很聪明,但它们通常被困在对话框里。如果 AI 能长出“手”和“眼睛”,直接去操作浏览器,帮我订票、填表、查数据,那该多好?
Browser Use 就是目前 GitHub 上最火的实现这一愿景的库。它能让 AI 像人类一样浏览网页。
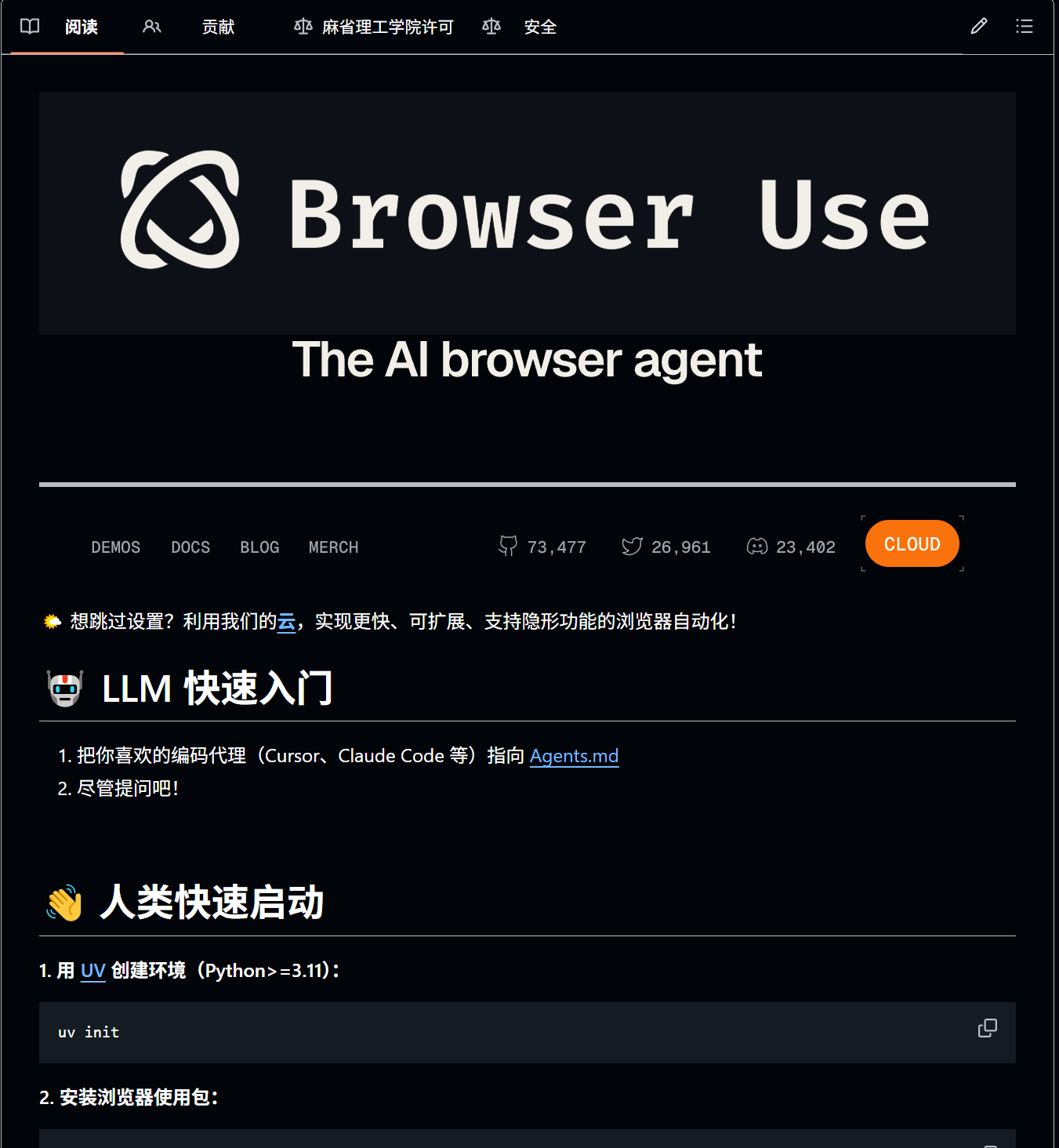
它基于 LangChain 和 Playwright,通过视觉大模型(Vision LLM)来“看”网页,然后自动规划行动。你只需要给它一个指令,比如“帮我查一下明天飞往东京最便宜的机票并添加到购物车”,它就会自己去操作。
主要功能:
① 视觉操控: 利用 GPT-4o 或其他多模态模型识别网页元素,点击准确率极高;
② 自动抗干扰: 能够处理弹窗、Cookie 确认框等常见的网页干扰;
③ 多标签页管理: 支持同时打开多个页面进行比对和操作;
④ 简单易用: 几行 Python 代码就能启动一个能上网的 Agent。
想象一下,把繁琐的重复性网页操作交给它,这才是真正的自动化。
开源地址: https://github.com/browser-use/browser-use
03.Crawl4AI
专为 LLM 设计的爬虫
做过 RAG(检索增强生成)或者训练过模型的都知道,网页上的数据虽然多,但格式乱七八糟(广告、侧边栏、弹窗),直接喂给大模型效果很差。
Crawl4AI 就是专为 LLM 时代设计的爬虫工具。它的目标只有一个:把乱七八糟的网页,变成大模型最爱吃的 Markdown 格式。
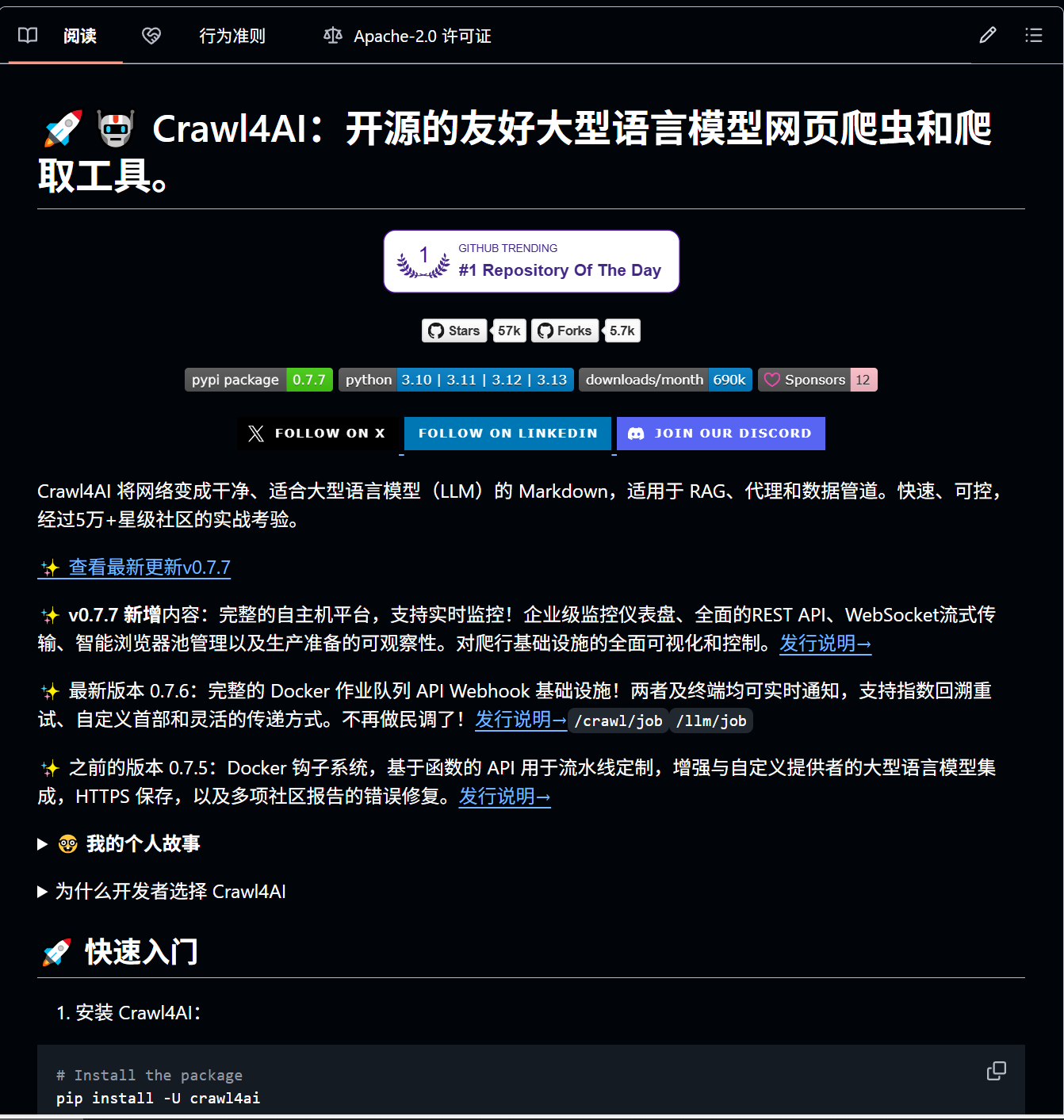
它的速度极快,且内置了强大的清洗逻辑。不需要复杂的配置,就能抓取高质量的数据。
主要功能:
① LLM 友好: 输出干净、结构化的 Markdown 或 JSON,直接就能丢进向量数据库;
② 免费且开源: 相比 FireCrawl 等收费服务,Crawl4AI 完全开源免费;
③ 反爬攻坚: 能够模拟真实浏览器行为,处理动态加载(JS)页面,甚至能绕过部分反爬策略;
④ 极速提取: 支持提取页面中的元数据、链接、媒体资源,还能自动去除页眉页脚等噪音。
如果你在做 AI 应用开发,需要从网上抓取数据作为知识库,这个库绝对是首选。
开源地址: https://github.com/unclecode/crawl4ai
💡 总结
-
开发想偷懒? 用 Bolt.diy,一句话生成应用。
-
操作想托管? 用 Browser Use,让 AI 替你上网。
-
数据要清洗? 用 Crawl4AI,专为 LLM 喂饭。
这三个项目代表了 2025 年开源界的最新趋势:AI 正在从“生成内容”转向“执行任务”。
🔥 关注我,每周为你挖掘更多 GitHub 宝藏项目!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)